







随机森林算法及其实现
决策树部分参考了我导师的文章,日撸 Java 三百行(61-70天,决策树与集成学习)
1. 实现连续值的处理(参考西瓜书)
由于连续值的可取值数目不像离散值那样有明确的且数量较小的数值,所以不能够根据连续属性的可取值来对节点划分。因此采用二分法的策略对连续属性进行处理。
以下是我对西瓜书上的内容的理解以及在代码上的设计:
1.1 理论
给定样本集
D
D
D 和连续属性
a
a
a, 假定
a
a
a 在
D
D
D 上出现了
n
n
n 个不同的取值,将这些值按照升序排列,记为
{
a
1
,
a
2
,
…
,
a
n
}
.
\{a^1, a^2, \dots, a^n\}.
{a1,a2,…,an}. 基于划分点
t
t
t 将
D
D
D 分为子集
D
t
−
D^-_t
Dt− 和
D
t
+
D^+_t
Dt+,其中
D
t
−
D^-_t
Dt− 表示在属性
a
a
a 上取值不大于
t
t
t 的样本,而
D
t
+
D^+_t
Dt+ 表示大于
t
t
t 的样本。 对于相邻属性的取值
a
i
a^i
ai 与
a
i
+
1
a^{i+1}
ai+1 来说,
t
t
t 在区间
[
a
i
,
a
i
+
1
)
[a^i,a^{i+1})
[ai,ai+1) 中取任意值所产生的划分结果相同. 因此,对连续属性
a
a
a ,我们可以划分
n
−
1
n-1
n−1 个元素作为划分点集合
T
n
=
{
a
i
+
a
i
+
1
2
∣
1
≤
i
≤
n
−
1
}
,
T_n = \left\{\frac{a^i+a^{i+1}}{2}|1\leq i \leq n-1\right\},
Tn={2ai+ai+1∣1≤i≤n−1},
就是把区间
a
i
,
a
i
+
1
a^i,a^{i+1}
ai,ai+1 的中位点
a
i
+
a
i
+
1
2
\frac{a^i+a^{i+1}}{2}
2ai+ai+1 作为候选划分点,然后通过对离散值划分方式一样来选择最优的划分点对样本集划分,可将用于离散值的划分选择公式加以改造:
G
a
i
n
(
D
,
a
)
=
max
t
∈
T
a
G
a
i
n
(
D
,
a
,
t
)
=
max
t
∈
T
a
E
n
t
(
D
)
−
∑
λ
∈
{
−
,
+
}
∣
D
t
λ
∣
∣
D
∣
E
n
t
(
D
t
λ
)
,
\begin{aligned} \mathrm{Gain}(D,a)&=\max_{t\in T_a}\mathrm{Gain}(D,a,t)\\ &=\max_{t\in T_a}\mathrm{Ent}(D) -\sum_{\lambda\in\{-,+\}}\frac{|D^{\lambda}_t|}{|D|}\mathrm{Ent}(D^{\lambda}_t), \end{aligned}
Gain(D,a)=t∈TamaxGain(D,a,t)=t∈TamaxEnt(D)−λ∈{−,+}∑∣D∣∣Dtλ∣Ent(Dtλ),
其中 G a i n ( D , a , t ) \mathrm{Gain}(D,a,t) Gain(D,a,t) 是样本集 D D D 基于划分点 t t t 二分后的信息增益, 我们根据每个划分点的计算结果选取最大的即可拿来作为划分点。
1.2 代码实现
/*
* Use Binary Partition to deal with continuous values.
* param@paraAttribute: The attributes that need to get the number of values.
*/
double Tree::binaryPartition(int paraAttribute)
{
// Sort.
int length = availableInstances->getLength();
double* tempValues = new double[length];
IntArray* tempIndices = new IntArray(length);
tempIndices->cloneToMe(availableInstances);
// Bubble sort.
bool flag;
double temp;
int tempIndex;
for (int i = 0; i < length; i++)
{
tempValues[i] = trainingSet->getValue(availableInstances->getValue(i), paraAttribute);
}// Of for
for (int i = 0; i < length; i++)
{
flag = true;
for (int j = length - 1; j > i; j--)
{
if (tempValues[j] < tempValues[j - 1])
{
temp = tempValues[j];
tempIndex = tempIndices->getValue(j);
tempValues[j] = tempValues[j - 1];
tempIndices->setValue(j, tempIndices->getValue(j - 1));
tempValues[j - 1] = temp;
tempIndices->setValue(j - 1, tempIndex);
flag = false;
}// Of if
}// Of for
if (flag)
{
break;
}// Of if
}// Of for
// Gain
double splitValue = 0;
double tempSplitValue;
double result = 1e100;
// Statistics, calculate the category distribution under this feature.
int tempNumValues = 2;
int tempNumInstances = length;
// The number of instances storing each value under the attribute.
IntArray* tempValueCounts = new IntArray(tempNumValues);
DoubleMatrix* tempCountMatrix = new DoubleMatrix(tempNumValues, numClasses);
for (int i = 0; i < length - 1; i++)
{
tempSplitValue = (tempValues[i] + tempValues[i + 1]) / 2;
// Store the number of label distributions for each value under the attribute.
tempValueCounts->setValue(0, i + 1);
tempValueCounts->setValue(1, length - i - 1);
tempCountMatrix->setZero();
int tempClass;
for (int j = 0; j < tempValueCounts->getValue(0); j++) {
tempClass = trainingLables->getValue(tempIndices->getValue(j));
tempCountMatrix->setValue(0, tempClass, tempCountMatrix->getValue(0, tempClass) + 1);
}// Of for
for (int j = tempValueCounts->getValue(0) + 1; j < tempNumInstances; j++) {
tempClass = trainingLables->getValue(tempIndices->getValue(j));
tempCountMatrix->setValue(1, tempClass, tempCountMatrix->getValue(1, tempClass) + 1);
}// Of for
// Calculate.
double resultEntropyT = 0;
double tempEntropyT, tempFractionT;
for (int j = 0; j < tempNumValues; j++) {
tempEntropyT = 0;
for (int k = 0; k < numClasses; k++) {
//Probability of one of the cases under this feature.
tempFractionT = tempCountMatrix->getValue(j, k) / tempValueCounts->getValue(j);
if (tempFractionT == 0) {
continue;
}// Of if
tempEntropyT += -tempFractionT * log2(tempFractionT);
}// Of for
resultEntropyT += (double)tempValueCounts->getValue(j) / tempNumInstances * tempEntropyT;
}// Of for
if (result > resultEntropyT) {
splitValue = tempSplitValue;
result = resultEntropyT;
}// Of if
}// Of for
delete[] tempValues;
delete tempIndices;
delete tempValueCounts;
delete tempCountMatrix;
continuesSplitValues->setValue(0, paraAttribute, splitValue);
return result;
}// Of binaryPartition
需要注意的一点是由于每次计算
G
a
i
n
(
D
,
a
)
=
max
t
∈
T
a
E
n
t
(
D
)
−
∑
λ
∈
{
−
,
+
}
∣
D
t
λ
∣
∣
D
∣
E
n
t
(
D
t
λ
)
\mathrm{Gain}(D,a)=\max_{t\in T_a}\mathrm{Ent}(D) -\sum_{\lambda\in\{-,+\}}\frac{|D^{\lambda}_t|}{|D|}\mathrm{Ent}(D^{\lambda}_t)
Gain(D,a)=t∈TamaxEnt(D)−λ∈{−,+}∑∣D∣∣Dtλ∣Ent(Dtλ)
其中
E
n
t
(
D
)
\mathrm{Ent}(D)
Ent(D) 都是相同的,因此直接计算
∑
λ
∈
{
−
,
+
}
∣
D
t
λ
∣
∣
D
∣
E
n
t
(
D
t
λ
)
\sum_{\lambda\in\{-,+\}}\frac{|D^{\lambda}_t|}{|D|}\mathrm{Ent}(D^{\lambda}_t)
λ∈{−,+}∑∣D∣∣Dtλ∣Ent(Dtλ)
这样每次返回的值就不是最大值了,而是上式计算得出的最小值。
2. 随机森林算法实现
2.1 先实现随机化,有放回抽取样本,以及随机抽取属性(无放回)
/*
* Random instances are obtained through sampling methods with replacement.
* Return: Available instances.
*/
IntArray* RandomForestClassifier::bootStrap()
{
int count = 0;
int tempIndex;
IntArray* resInstances;
int length = trainingSet->getRows();
int* tempIndices = new int[length];
memset(tempIndices, 0, length * sizeof(int));
for (int i = 0; i < length; i++)
{
tempIndex = rand() % length;
if (tempIndices[tempIndex] == 0) {
tempIndices[tempIndex] = 1;
count++;
}// Of if
}// Of for
resInstances = new IntArray(count);
for (int i = 0, j = 0; i < length; i++)
{
if (tempIndices[i] == 1)
{
resInstances->setValue(j++, i);
}// Of if
}// Of for
#ifdef IF_DEBUG
std::cout << "bootStrap() : " << resInstances->toString() << std::endl;
#endif // IF_DEBUG
delete[] tempIndices;
return resInstances;
}// Of bootStrap
/*
* Random attributes are obtained through sampling without replacement.
* Return: Available attributes.
*/
IntArray* RandomForestClassifier::getAttributes()
{
int tempIndex;
int numAvailableAttributes;
if (maxAttributes != -1 && maxAttributes <= numAttributes)
{
numAvailableAttributes = maxAttributes;
}
else
{
numAvailableAttributes = sqrt(numAttributes);
}
int* tempAttributes = new int[numAttributes];
memset(tempAttributes, 0, numAttributes * sizeof(int));
IntArray* resAttributes = new IntArray(numAvailableAttributes);
int count = 0;
while (count < numAvailableAttributes) {
tempIndex = rand() % numAttributes;
if (tempAttributes[tempIndex] == 1) {
continue;
}// Of while
tempAttributes[tempIndex] = 1;
count++;
}// Of while
tempIndex = 0;
for (int i = 0; i < numAttributes; i++)
{
if (tempAttributes[i] == 1) {
resAttributes->setValue(tempIndex++, i);
}// Of if
}// Of for
#ifdef IF_DEBUG
std::cout << "getAttributes() : " << resAttributes->toString() << std::endl;
#endif // IF_DEBUG
delete[] tempAttributes;
return resAttributes;
}// Of getAttributes
2.2 构造有穷颗树
/*
* Build a tree
* Return: A tree.
*/
Tree* RandomForestClassifier::buildTree()
{
IntArray* availableInstances = bootStrap();
IntArray* availableAttributes = getAttributes();
Tree* tree = new Tree(trainingSet, trainingLables, availableInstances, availableAttributes, numClasses, 0,
continuesAttributes, maxDepth, minSampleSplit, criterion);
tree->train();
delete availableInstances;
delete availableAttributes;
return tree;
}// Of buildTree
/*
* Build a given number of trees.
*/
void RandomForestClassifier::train()
{
trees = new Tree * [numTrees];
for (int i = 0; i < numTrees; i++)
{
trees[i] = buildTree();
}// Of for
}// Of train
2.3 预测以及投票
/*
* Return the most frequent label by counting the number of various labels
* param@paraLabels : The set of labels predicted by each tree.
* Return: Label.
*/
int RandomForestClassifier::vote(IntArray* paraLabels)
{
int* tempCountClasses = new int[numClasses];
memset(tempCountClasses, 0, numClasses * sizeof(int));
int max = 0;
for (int i = 0; i < paraLabels->getLength(); i++)
{
tempCountClasses[paraLabels->getValue(i)]++;
if (tempCountClasses[max] < tempCountClasses[paraLabels->getValue(i)])
{
max = paraLabels->getValue(i);
}// Of if
}// Of for
delete[] tempCountClasses;
return max;
}// Of vote
/*
* Predict.
*/
int RandomForestClassifier::predict(DoubleMatrix* paraInstance)
{
IntArray* tempLabels = new IntArray(numTrees);
for (int i = 0; i < numTrees; i++)
{
tempLabels->setValue(i, trees[i]->predict(paraInstance));
}// Of for
int resLable = vote(tempLabels);
delete tempLabels;
return resLable;
}// Of predict
3. 结果测试
3.1 采用 weather 数据测试
该数据集数量较少,且为离散值,使用随机森林算法处理如下:
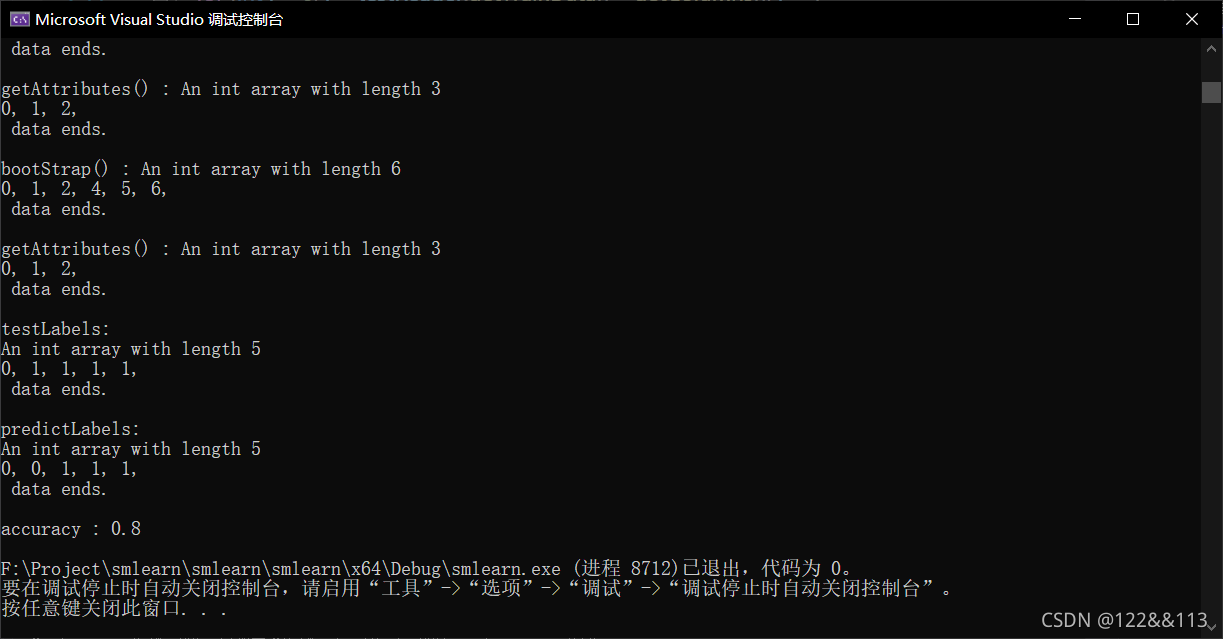
3.2 采用 iris 数据测试
由于 iris 数据中的属性值是连续的,所以随机森林需要选择连续值的处理方式,也就是在决策树中对连续值做一个二分的处理。
参数设置:
RandomForestClassifier rf(testReader.getTrainData(), testReader.getTrainLabels(), 50, 3, myContinuesAttributes, 1000, 5, 3, 1);
50 : 树的数量
3 : 表示标签种类
myContinuesAttributes : 表示哪些属性的值是连续值
1000 : 树能够形成的最大深度
5 : 能分割成节点的最小样本数量
3 : 需要抽样的属性数量
1 : 表示使用哪种划分选择方式(目前有信息增益以及基尼指数)















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









