






技术价值:Transformer 让模型像人类一样,既能把握全局(长距离依赖),又能快速学习(并行计算),成为大模型时代的“发动机”。
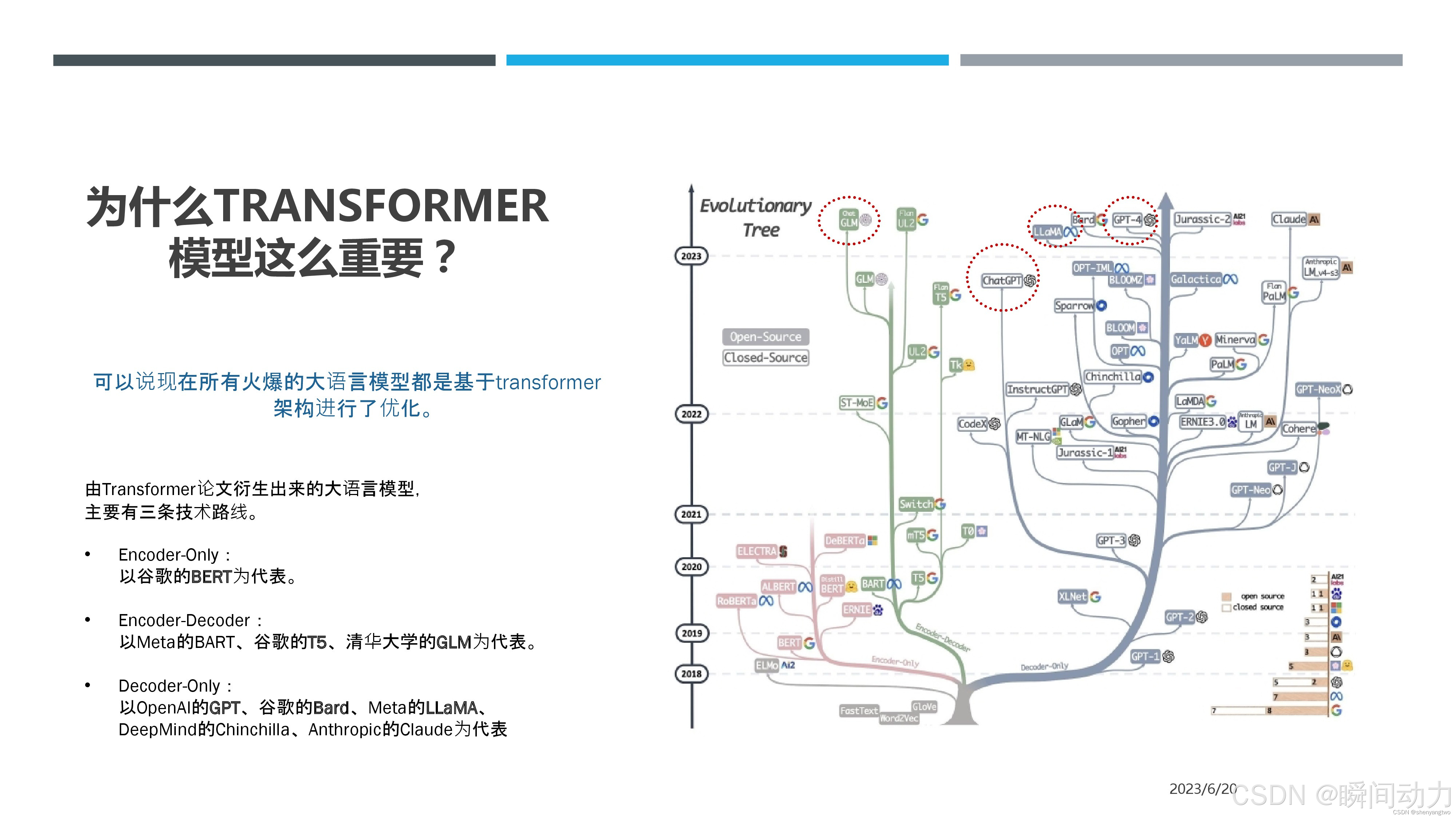
一、Transformer 的核心结构
Transformer 架构由 编码器(Encoder) 和 解码器(Decoder) 组成,核心模块包括 自注意力机制(Self-Attention)、位置编码(Positional Encoding) 和 前馈神经网络(Feed-Forward Network)。以下通过一个简单的 “机器翻译” 场景(如将英文翻译为中文)逐步解析:
1. 自注意力机制(Self-Attention)
作用:让模型在处理一个词时,动态关注输入中所有相关的词。
例子:
输入句子:“The cat sat on the mat.”
翻译目标:模型需要知道“cat”是动作“sat”的主语,“mat”是位置。
具体步骤:
- 生成 Q、K、V 向量:
每个词(如“cat”)会被映射为三个向量:
-
- Query(Q):表示当前词需要查询的信息。
- Key(K):表示其他词的“身份标识”。
- Value(V):表示其他词的实际内容。
- 计算注意力分数:
通过 Q 和 K 的点积,计算每个词对其他词的关注程度。
例如,“cat”的 Q 会与“sat”“mat”等词的 K 相乘,得到“cat”与这些词的相关性分数。 - Softmax 归一化:
将分数转换为概率分布,确定每个词的重要性权重。 - 加权求和:
用权重对 V 向量加权求和,得到当前词的最终表示。
结果:通过自注意力,“cat”的表示会包含“sat”和“mat”的信息。
2. 位置编码(Positional Encoding)
问题:自注意力机制本身无法感知词的位置顺序。
例子:
“狗咬人”和“人咬狗”意义相反,但传统注意力无法区分顺序。
解决方案:
- 为每个词添加位置编码向量(如正弦函数生成):
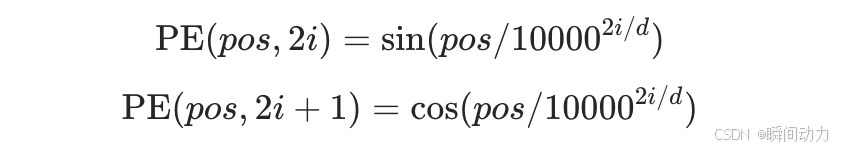
- 输入 = 词嵌入(Word Embedding) + 位置编码。
效果:模型明确知道“狗”在第1位,“人”在第3位。
3. 前馈神经网络(Feed-Forward Network)
作用:对自注意力后的表示进行非线性变换,增强模型表达能力。
结构:
每个位置的向量独立通过两层全连接网络(如 ReLU 激活):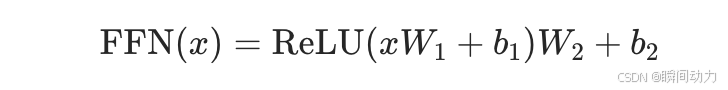 例子:
例子:
自注意力后的“cat”向量经过 FFN,可能被映射为更抽象的语义表示(如“动物-主语”)。
4. 编码器-解码器架构
- 编码器:
将输入序列(如英文句子)转换为高维语义表示(包含所有词的关系)。 - 解码器:
逐步生成输出序列(如中文),每一步通过 交叉注意力(Cross-Attention) 关注编码器的输出。
例子:
翻译“I love you”为“我爱你”:
- 编码器将“I”“love”“you”编码为上下文向量。
- 解码器生成“我”时,关注编码器的“I”;生成“爱”时,关注“love”;生成“你”时,关注“you”。
二、Transformer 的设计思路
1. 完全摒弃循环结构(RNN/LSTM)
传统问题:RNN 必须逐词处理,无法并行计算,且长距离依赖难以捕捉。
Transformer 方案:
- 自注意力机制可并行计算所有位置的关联性。
- 长距离依赖直接通过注意力解决(如第1个词和第100个词的关联)。
2. 模块化堆叠
- 编码器和解码器均由多个相同层(如6层)堆叠而成。
- 每层包含自注意力、前馈网络、残差连接(Residual Connection)和层归一化(LayerNorm)。
优势:模型深度可控,易于扩展(如 GPT-3 有96层)。
3. 位置编码替代时序处理
- 通过数学公式直接注入位置信息,无需依赖顺序计算。
三、Transformer 如何提升大模型推理能力?
1. 并行计算加速训练
- 传统 RNN 需逐步计算,Transformer 可同时处理所有词。
- 例子:训练时,GPU 可并行计算整句的注意力权重,速度提升10倍以上。
2. 长距离依赖建模
- 自注意力机制直接关联任意距离的词。
- 例子:在生成“The animal didn’t cross the street because it was too tired.”时,模型能明确“it”指代“animal”。
3. 可扩展性支撑大模型
- 通过增加层数和注意力头数,模型可轻松扩展至千亿参数(如 GPT-4)。
- 例子:每层新增一个注意力头,模型可学习更细粒度的特征(如区分“bank”是“银行”还是“河岸”)。
四、Transformer 的技术意义与价值
1. 推动预训练范式革命
- BERT:通过掩码语言模型(MLM)预训练,利用 Transformer 编码器学习双向上下文表示。
- GPT:通过自回归生成预训练,利用 Transformer 解码器实现文本生成。
2. 跨模态通用架构
- 不仅用于 NLP,还可处理图像(ViT)、语音(Conformer)等多模态数据。
- 例子:DALL·E 用 Transformer 生成图像时,将像素序列视为“词”处理。
3. 工业化落地的基石
- 支持分布式训练、模型压缩(如蒸馏)、高效推理(如 KV Cache)。
- 例子:ChatGPT 通过 Transformer 的 KV Cache 技术,将生成速度优化10倍。
五、通俗总结
Transformer 就像一台“超级关联机器”:
- 自注意力:每个词举起一块牌子,写下自己是谁(Key),然后根据问题(Query)找到最相关的牌子(Value)。
- 位置编码:给每个词发一个座位号,避免它们坐错位置。
- 多层堆叠:第一层学会“词与词的关系”,第二层学会“句子的结构”,第三层学会“语义的逻辑”……
- 结果:模型既能看懂“猫坐在垫子上”,也能写出“垫子上坐着一只猫”。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











