







近年来,人工智能领域的发展高度依赖海量数据和算力,但数据质量不足、标注成本高昂等问题始终制约着模型的性能提升。近日,中国AI公司深度求索(DeepSeek)发布了一项名为**神经缩放增强(Neural Scaling Augmentation, NSA)**的技术,通过创新的数据生成与模型优化方法,为突破现有训练瓶颈提供了全新的解决方案。这项技术基于其团队在arXiv公开的论文研究(arXiv:2502.11089v1),旨在通过算法驱动的高效数据生成策略,显著提升模型在有限数据下的泛化能力和推理效率。
数据瓶颈的破局者:NSA技术内核
传统深度学习的成功往往依赖于“数据量越大,模型性能越好”的缩放定律,但现实中高质量数据的获取成本极高,尤其在医疗、金融等垂直领域。DeepSeek NSA的核心创新在于将数据生成与模型训练深度融合:
- 动态数据合成引擎:通过预训练模型分析现有数据分布,生成符合任务需求的高质量合成数据,同时引入对抗性样本以增强鲁棒性;
- 缩放感知训练框架:在训练过程中动态调整合成数据与真实数据的比例,结合课程学习策略,使模型逐步适应不同复杂度场景;
- 参数效率优化:通过稀疏激活和分层注意力机制,减少冗余计算,使模型在较小参数量下实现接近大型模型的性能。
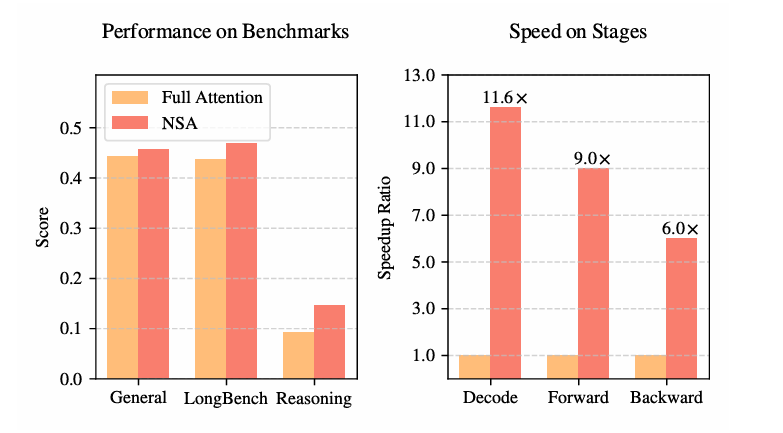
论文实验表明,在自然语言理解、图像分类等任务中,采用NSA技术的模型仅需30%的标注数据即可达到传统方法使用全量数据的准确率,且推理速度提升40%以上。
技术突破背后的三大优势
NSA的价值不仅在于技术创新,更在于其可扩展性和实用性:
- 降低数据依赖:企业无需投入巨额成本标注数据,即可快速构建高精度模型,尤其利好中小型机构;
- 加速迭代周期:合成数据生成与模型训练并行,缩短传统“收集-清洗-标注”流程的80%时间;
- 跨领域迁移能力:通过元学习框架,模型可将某一领域的知识快速迁移至数据稀缺的新场景(如从通用对话迁移至法律咨询)。
行业影响:AI民主化的新里程碑
DeepSeek NSA的推出可能引发行业级变革。在应用层面,医疗领域可基于少量病例数据构建诊断模型,制造业能利用合成数据模拟罕见故障场景;在生态层面,该技术降低了AI研发门槛,使资源有限的企业也能参与创新竞争。更重要的是,NSA为探索“小数据大模型”路径提供了实证案例——未来AI发展或许不必一味追求参数量的增长,而是通过算法革新释放现有数据的潜力。
结语
DeepSeek NSA的诞生标志着AI基础研究从“暴力缩放”向“智能缩放”的转型。随着合成数据生成、模型高效训练等技术的成熟,人工智能有望摆脱对数据规模的过度依赖,进入更可持续的发展阶段。这一突破不仅是技术路线的迭代,更是对AI普惠化愿景的有力回应——让智能技术的红利真正触达千行百业。



















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











