







有幸在发布会前拿到了开发板,可以提前对开发板测试,感受下新品AIoT的魅力。(我这个是体验装,不花钱,需要啥设备他们还得给我买→_→)

下面我将以自己的科研项目经历来对这款芯片进行评估,简单来说,就是将自己的项目套用在这个芯片上,来评估其可适用性
首先,要明确一点芯片,不是一定要分出个谁好谁不好,都是根据需求来的。比如:在笔记本上开发的程序,移植到通用芯片上的难度就会低很多,但是功耗和所需频率就会高很多。而移植到专用芯片上,功耗和速度会提升不少,但是移植难度相当高。一切,都是根据需求来选择的,所以平常一定要多多调研各种芯片。

干了这么多年的项目,用过研华、Jetson系列等开发板,下面对这些芯片进行对比分析:
研华芯片:CPU直接是Intel芯片,windows或linux系统都行,在不用显卡开发程序的前提下,几乎不存在任何移植困难,而且是工业界的老牌子,性能相当稳定,有硬件相关的bug,给技术打电话,很快就能反馈修复,在其面向的应用里面,性能、售后都是最佳的。但是,同样具有一些应用局限性:散热板沉、功耗稍大,导致无法有效部署在无人机等应用;仅有CPU,无GPU等加速模块;价格是真的贵… →_→。
Jetson系列芯片:Jetson系列最大的优势在于,它几乎把CUDA相关的一切都搬到了嵌入式板子上。简单来说,你所开发的深度学习相关算法,几乎可以无缝用在这个板子上,只要你的内存够。

我用过Jetson TX2, NX,调研过Xavier Nano,有个项目也是基于这些,每次设计新算法都要在这个平台上测试。这个开发板发布初期,确实不方面,缺少一大堆工具,但是目前,几乎已经不存在移植难度。除了仅能用于Ubuntu平台、且CPU性能不高。真的找不到任何其他的一些缺点,我个人觉得,这也是市面上为什么这么多公司围绕着Jetson核心来做小型主机(比如我关注的阿木实验室,无人机和机载视觉平台几乎都是Jetson,做的很专业),甚至,大量的自动驾驶公司都以NVIDIA芯片为主。
各位,看到这里,是不是觉得,有这么多成熟的产品,为什么还要介绍新的芯片,高不成低不就,我为什么要将自己的项目从一个成熟的NVIDIA芯片转到一个新的不成熟的平台。
有没有注意到,我用的这些好用的开发板,都是国外的,从学生角度来说,用arduino或树莓派,已经能做一些很多的小项目了,但是对于一个大项目来说,arduino或树莓派真的远远不够用,他们的性能真的太低了。我目前,没有看到那个工业嵌入式应用,大量使用了国产的嵌入式芯片。特别是做科研做到最后,我真的很害怕,我每天都在惊呼“Jetson真的是太好用了”,每天都在感叹“我所有的项目都放在这个平台上,真的安全吗?”。
我比较欣慰的一点,据我所知,航天领域,目前大量芯片都是自主研发,阵地还没有被占领。很多工程师,都在想办法在极小的处理能力里发挥算法的最大性能。4月24日,“思源计划”蓝皮书发布,已经明确要尝试将人工智能应用在航天领域中,我真的很不希望最后迫不得已,用了大量的国外的芯片,不可控的东西往往是最危险的。

下面,我要说说,刚刚拿到的地平线旭日X3派,本年发布的新开发板。说它拳打脚踢Jetson全系列太扯了,这个旭日3派目前对标Jetson Nano,三点大优势算力/功耗比高、重量轻、价格低,这些后面细说,是一款深度学习嵌入式开发板。我与该板的主要负责人徐国晟大神聊了一些对嵌入式开发板的一切期望,以及目前整体环境存在的一些问题。越聊越激动,所以我要把自己对这款开发板的评测、期望都要完全的写出来,抒发自己的感慨之情。

下面,我将带各位从硬件到软件、从外部到内部,来充分欣赏这款开发板:旭日X3派(Sunrise x3 Pi) 。

开发板体验流程
一 整体结构
下面给出了这个开发板的整体的一个接口示意图,固定孔位、尺寸和整体结构的布局与树莓派是极为相似的。个人感觉,旭日3派最想拉过来树莓派用户,希望吸引更多Jetson Nano用户。

如何去理解这个开发板,最直观的比方,可以说是:旭日3派≈树莓派+神经计算棒。它不像NVIDIA那样有nvcc来开发CUDA相关程序,没有那么高的灵活度。但是它相比于树莓派,多了5TOPS的深度学习计算能力。这对Jetson用户来说可能有点幼稚,但对树莓派用户来说刚刚好(✿◡‿◡)。

旭日X3派开发板,为SoC系统级芯片,中心处理器采用的是ARM A53,其他ISP(图像信号处理器)和BPU(人工智能处理器单元)均为自研,2GB的内存,存储使用TF卡,其他的一些参数去官网查看具体配置即可。

前面已介绍,该开发板三点大优势算力/功耗比高、重量轻、价格低。对于算力/功耗比,2.5W的基础功耗提供了5TOPS的算力,下表给出一些同类型的一些边缘计算设备的一些配置。值得注意的是,神经计算棒必须搭配其他开发板使用。
| 型号 | 树莓派3B | Intel NCS2 神经计算棒(仅模块) | Jetson Nano | 旭日X3派 |
|---|---|---|---|---|
| 算力(INT8) | - | 4TOPS | 7TOPS | 5TOPS |
| 功耗 | 1.4W | 2W | 10W | 2.5W |
| 算力/功耗 | - | 2 | 0.7 | 2 |
| 重量 | 42g | 77.80g | 249.47 | 52.5 |
| 价格 | 850 | 900 | 1500 | 500 |

这个表有几点需要说明下:
- Jetson Nano查不到TOPS数据,考虑到Nano的核心数是NX的1/3,因此根据NX的数据除以3作为Nano的TOPS数据。
- 功耗一般为基础功耗,非峰值功耗。
- 价格为参考价。
- 具体参数细节以个人使用为主哈,这里只是参考。
在项目应用中,如果其中检测识别等相关处理算法,对实时要求不高,且对CPU要求不大的话,非常可以试一下旭日开发板。
下面给出主要接口的说明:
- Type C电源口:该开发板可接入USB Type C线来供电,实际使用时可使用5V/2A的手机充电头来用(充电头功率高点能稳定使用,低功率头似乎无法提供稳定的5V电压)。
- TF卡:开发板系统需要从TF卡加载并运行,用户在使用开发板前,需要先完成TF卡镜像制作。推荐使用至少8GB容量的TF存储卡,以便满足Ubuntu操作系统及相关功能包的安装要求。
- HDMI接口:这个接口主要用于查看可视化结果,无鼠标,因为系统不具有桌面可视化能力,系统自己开发了个功能,可以通过代码将图像数据输出到HDMI方便查看。
- 串口(用于登录):接入串口线,即可直接用远程的方式进行登录。
- USB2.0/3.0:开发板通过USB Hub、硬件开关电路扩展了多路USB接口,满足用户多路USB设备接入的需求。无法确定是否全部来自于一个USB,对于高吞吐量的设备比如Intel Realsense深度相机,可能存在丢帧问题,有待后续适配测试。
- MIPI接口:开发板提供1路MIPI CSI接口,可实现MIPI摄像头的接入
- 有线网口:千兆以太网接口,需要用命令行配置
- 40PIN标准接口:开发板提供40PIN标准接口,方便进行外围扩展,其中数字IO采用3.3V电平设计。40PIN接口定义如下,有相关需求的可以测试一下。

二 启动系统
下面,将完成系统的配置,完成系统的启动。
2.1 制作系统镜像
开发板目前支持Ubuntu 20.04 Server、Desktop两个版本。注意,由于X3芯片不支持GPU硬件加速,因此使用Ubuntu Desktop版本时,可能会因CPU渲染图形桌面而造成系统负载过大,如对系统性能有较高要求,推荐使用不带图形桌面的Ubuntu Server版本,下面我就带各位来使用Server版本的系统。
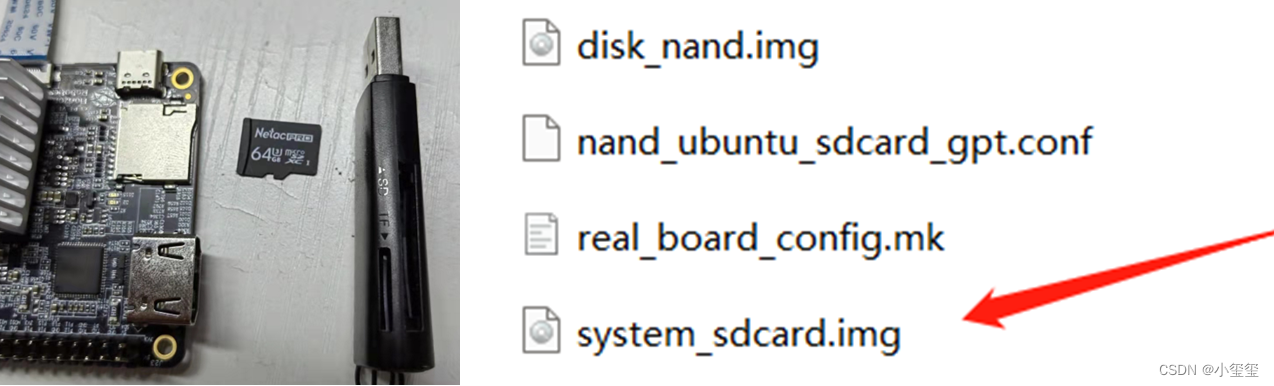
首先,准备好一个TF卡(16G以上),和一个读卡器,插到自己的笔记本上。我试用时候,提供了一个镜像包x3pi_ubuntu_disk.tar.gz,解压它得到一组文件,其中system_sdcard.img就是我们要刷的系统文件镜像。
镜像刷录我使用的是balenaEtcher工具,它是一款支持Windows/Mac/Linux等多平台的启动盘制作工具,官方链接:https://www.balena.io/etcher/。下载安装好就可以进行刷录啦。
※第一步:选择镜像

※第二步:选择TF卡。

※第三步:刷机!!
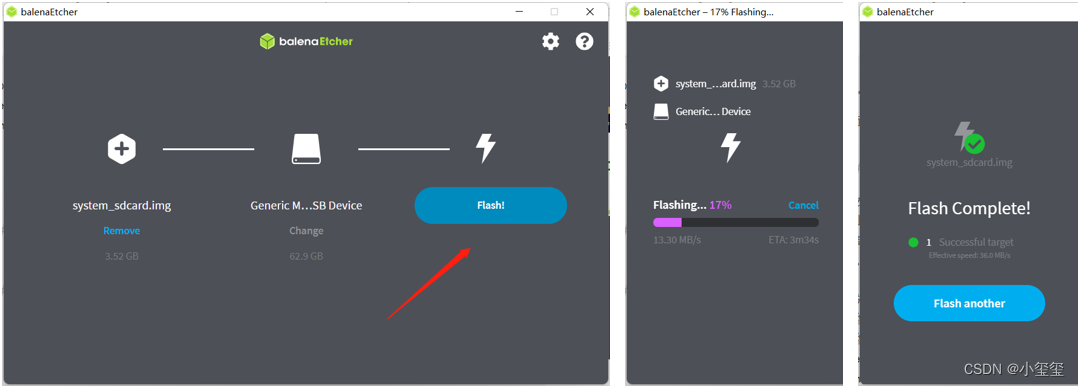
这几步完成后,我们就完成了刷机工作,相当简单吧φ(゜▽゜*)♪。
2.2 进入系统
刷完系统后,我们就可以把这张TF卡插回开发板里面了。下面,我们要尝试进入系统。
如果是刷机后第一次进入系统,一定要利用开发板自带的串口连接开发板,配置好网络后,后续可以不再利用串口登录(如果网络IP变了,那就重新用串口连接,查看下IP地址)。
※第零步:基础准备.
- 将HDMI连接到一个1080P显示器上(仅用于显示图像,无用户操作)。我在实验中,使用了一个HDMI采集卡,可通过USB接到笔记本上,利用VLC来查看输出图像信息。
- 将MIPI相机连接到开发板上。
- 将串口线的一段插在开发板上。

※第一步:串口连接系统
将串口线的另一端连接到笔记本上,看下设备管理器,若提示未知USB设备时,说明PC机未安装串口驱动,驱动程序可从地平线开发者社区发布页面https://developer.horizon.ai/resource获取。驱动安装完成后,设备管理器可正常识别串口板端口。

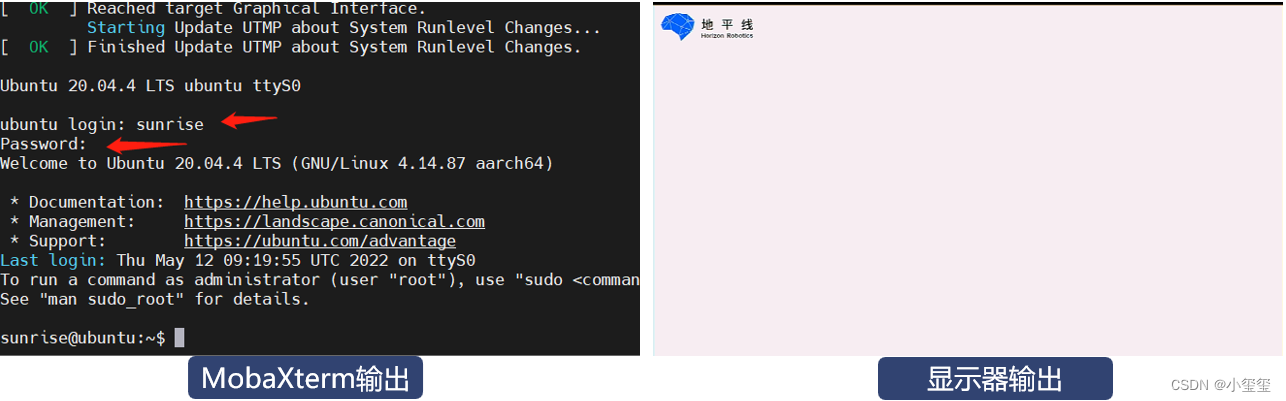
使用 MobaXterm 工具按照如下方式进行配置,打开后,由于设备没插电,所以空白。
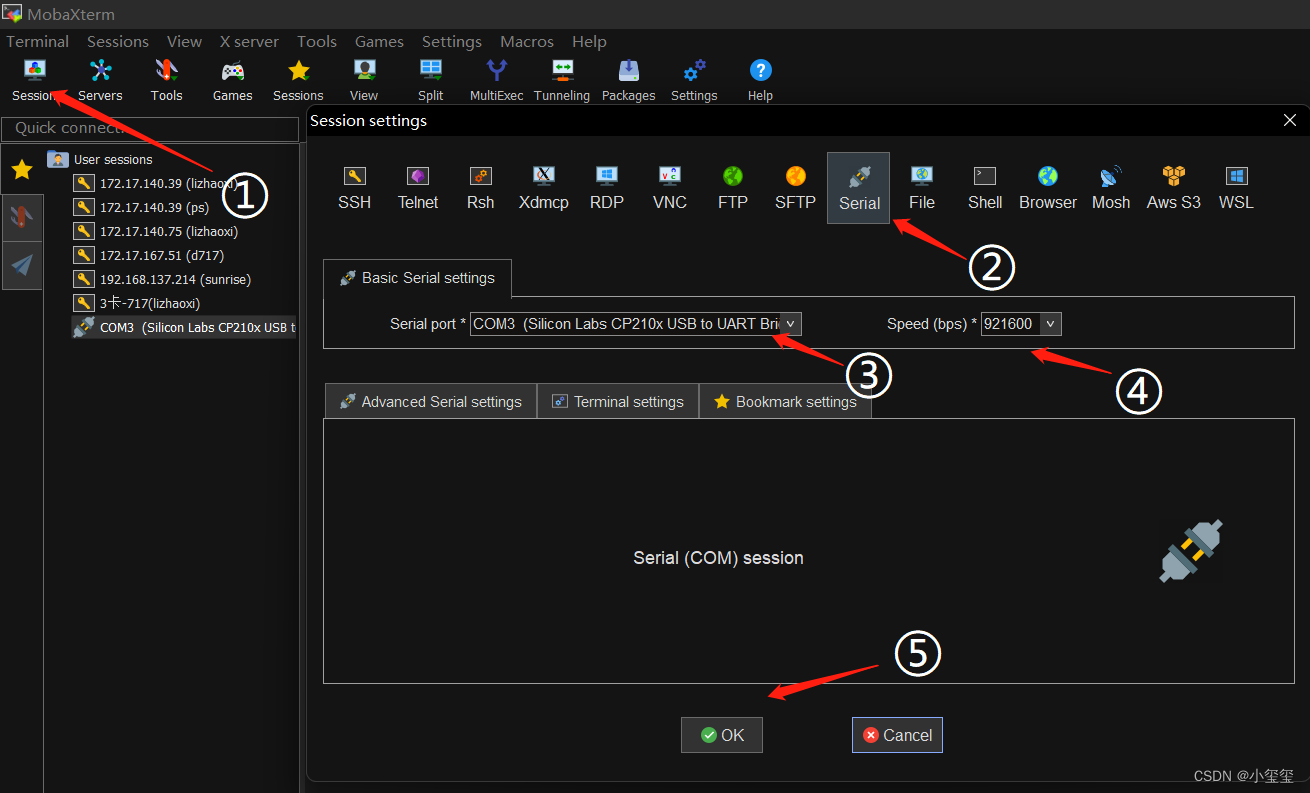
下面,将USB Type C电源线,插入开发板。这时候,控制台就会输出一堆文件,到最后,会需要输入用户名和密码,默认账户和密码均为sunrise。如果开发板HDMI正常显示开机画面(Server系统显示地平线logo、Desktop版本显示系统桌面),说明TF卡系统制作正确。
※第二步:BPU测试
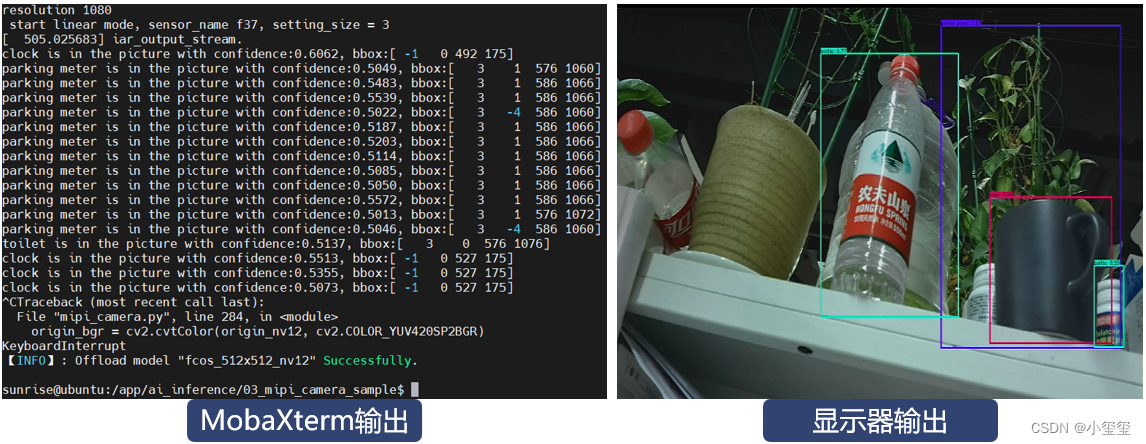
开发板已经连接了一个MIPI相机,下面使用官方示例来测试BPU模块是否有效。先进入示例程序文件夹cd /app/ai_inference/03_mipi_camera_sample/,然后输入sudo python3 mipi_camera.py,注意一定要加sudo,调用BPU模块需要管理员权限。
这时候,控制台就会输出一些检测信息,对应可视化效果由显示器显示。
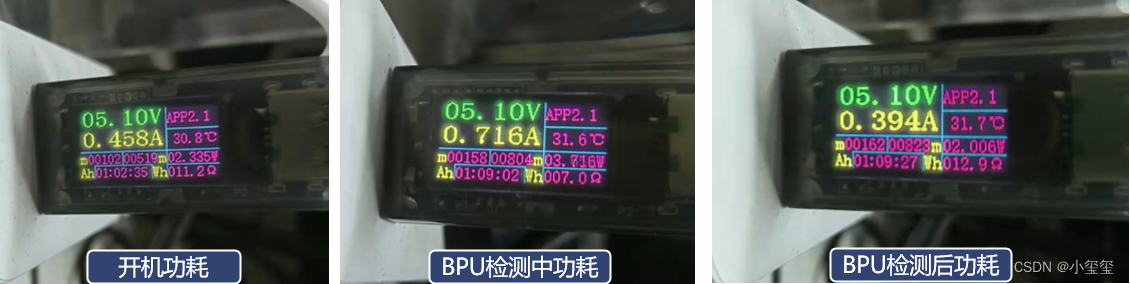
※后话:功耗分析
我分别对开机时,BPU检测中,和检测后的功耗进行了分析。开机后的功率在2.3W左右,利用BPU执行了一个检测示例,功耗升到3.6左右,结束后,功耗降为2.0W,这个原因比较诡异,可能是中止项目后,关闭了显示输出使得功耗下降。
至此,开发板启动起来了,我们happy的进行使用了。

2.3 网络配置
用串口来操作开发板的话,有几个致命问题:无法传文件、命令过长有bug、Vim使用不方便。因此,非常有必要把网络配置好来进行后续的调试开发。
开发板本身自带无线模块,同时也可以插网线以获得更快的速度。下面给出这两种模式的一个配置。
2.3.1 以太网配置
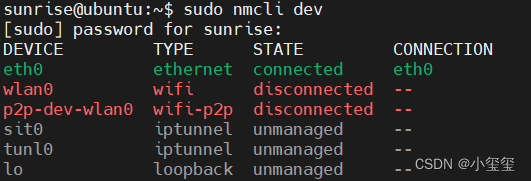
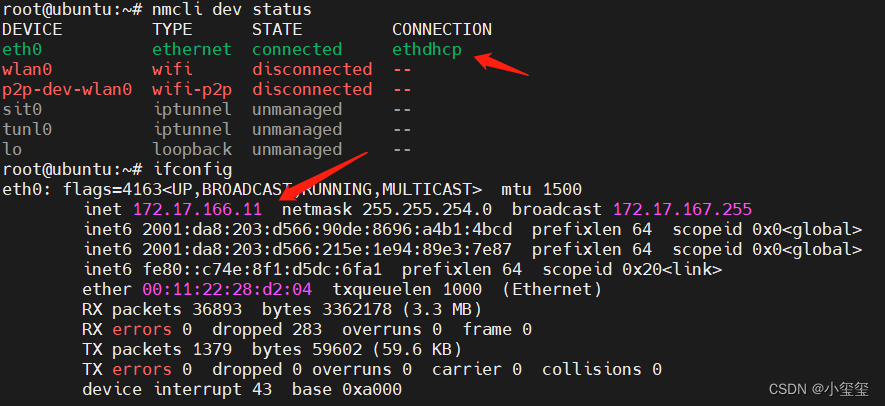
① 利用sudo nmcli dev查看网络设备。输入ifconfig发现IP地址是192.168.1.10,翻阅手册发现开发板以太网默认采用静态IP地址(192.168.1.10),以方便固定网络环境下的使用,例如开发板与PC机直连场景。但是,对于我来说,我需要动态分配,因为校园网整体就是局域网,不需要网络环境仅局限在电脑、开发板之间。
以下的配置,是想让开发板的IP地址由学校路由器分配得到,不需要静态IP
② 创建一个新的以太网链接
考虑到串口连接,输入的命令不能过长,则先利用sudo -i切换为root(操作完后利用su sunrise切换回去),然后在命令行中输入nmcli con add con-name "ethdhcp" type ethernet ifname eth0,这样可以使用dhcp获取网络,其中"ethdhcp"为网络名,用户可以自定义。这时候,我们发现,CONNECTION部分已经变了,且IP地址变为自动分配的了。
以太网有个大问题,就是连接校园网时候,由于没有用户界面,因此账号的登录,可能需要利用Python脚本去完成,或者让校园网插在路由器上完成中转,如果是个人路由器的话,这种问题一般不存在。
2.3.2 无线网配置
无线网络的连接参考博客《Linux命令行连接WiFi(全网最简单的方法)》。
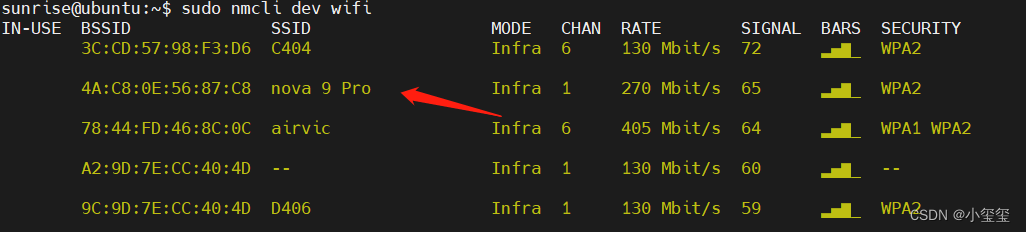
① 利用sudo nmcli radio wifi on开启wifi。
② 利用sudo nmcli dev wifi扫描wifi。其中,nova 9 Pro 为个人用手机开的热点
③ 利用sudo nmcli dev wifi connect "wifi名" password "密码"连接WIFI。将wifi的账号密码套在这个命令里,即可成功连接上Wifi。
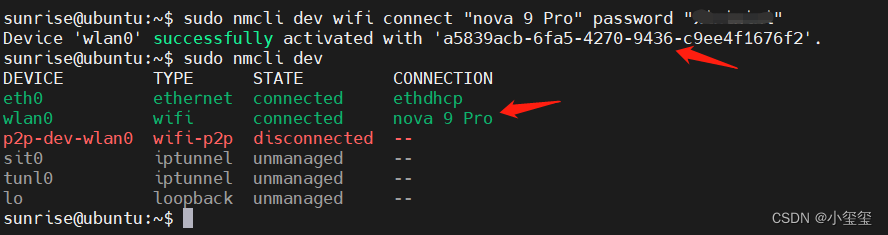
无线网最大的问题就是它的速度真的太慢了,我手上的这个版本速度约为300KB/s,自己外加个天线能够减低远程操作的延迟,这个问题已反馈,据说发布后的板子不存在这个问题。
三 CPU项目测试
无论什么开发板,基于CPU相关的程序的稳定性至关重要。因此,非常有必要去测试USB、串口、Wifi等相关的有效性以及稳定性。该部分的测试,一是测试项目的一些基本功能,其次是测试自己做项目中使用的一些算法,来分析整体系统的一个性能。
由于刷机时选择的是Ubuntu Server,所以带有界面相关的程序均无法使用。如果想在Server上部署界面端,40PIN接口上有SPI接口,可以购置SPI液晶屏来开发。
3.1 使用注意事项
- 第一次使用记得要
sudo apt-get update,默认清华源速度还是可以的。 - VSCode可以使用但不建议(占用600M左右的内存,总共内存在2G)。
- 通过
arch指令,可查得当前系统的架构为aarch64。 - 系统自带了个轻量版OpenCV但不够用,还是得通过指令
sudo apt-get install libopencv-dev安装个完整的OpenCV。 - 通过指令
sudo apt-get install mlocate安装locate,方便用来查找某些文件的地址。 - 系统默认没有git,通过
sudo apt-get install git来方便下载代码 - 利用
htop可以查看CPU和内存的利用情况
3.2 HDMI可视化图像数据
由于系统里面并不包含图形界面,因此如果动态地看算法的检测效果的话,就需要将图像数据输出到HDMI来显示,系统自带的python包里面有个类libsrcampy.Display就是来完成这样的工作的。
为了方便各位后续可视化自己的算法,我将这个功能封装为一个class

class ImageShow(object):
# 初始化,screen_w和screen_h表示HDMI输出支持的显示器分辨率
def __init__(self, screen_w = 1920, screen_h = 1080):
super().__init__()
self.screen_w = screen_w
self.screen_h = screen_h
self.disp = srcampy.Display()
self.disp.display(0, screen_w, screen_h)
# 结束显示
def close(self):
self.disp.close()
# 显示图像,输入image即可
def show(self, image, wait_time=0):
imgShow = self.putImage(image, self.screen_w, self.screen_h)
imgShow_nv12 = self.bgr2nv12_opencv(imgShow)
self.disp.set_img(imgShow_nv12.tobytes())
# 私有函数,将图像数据转换为用于HDMI输出的数据
@classmethod
def bgr2nv12_opencv(cls, image):
height, width = image.shape[0], image.shape[1]
area = height * width
yuv420p = cv2.cvtColor(image, cv2.COLOR_BGR2YUV_I420).reshape((area * 3 // 2,))
y = yuv420p[:area]
uv_planar = yuv420p[area:].reshape((2, area // 4))
uv_packed = uv_planar.transpose((1, 0)).reshape((area // 2,))
nv12 = np.zeros_like(yuv420p)
nv12[:height * width] = y
nv12[height * width:] = uv_packed
return nv12
# 图像数据在显示器最大化居中
@classmethod
def putImage(cls, img, screen_width, screen_height):
if len(img.shape) == 2:
imgT = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
else:
imgT = img
irows, icols = imgT.shape[0:2]
scale_w = screen_width * 1.0/ icols
scale_h = screen_height * 1.0/ irows
final_scale = min([scale_h, scale_w])
final_rows = int(irows * final_scale)
final_cols = int(icols * final_scale)
print(final_rows, final_cols)
imgT = cv2.resize(imgT, (final_cols, final_rows))
diff_rows = screen_height - final_rows
diff_cols = screen_width - final_cols
img_show = np.zeros((screen_height, screen_width, 3), dtype=np.uint8)
img_show[diff_rows//2:(diff_rows//2+final_rows), diff_cols//2:(diff_cols//2+final_cols), :] = imgT
return img_show
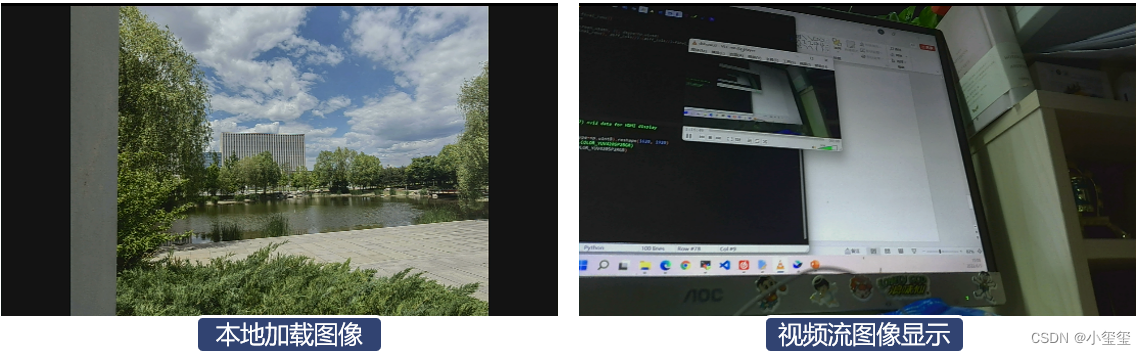
下面给出视频和图像的测试方法,相机用的是MIPI相机
def test_show_image():
img = cv2.imread('00000160.png') # 加载本地图片
im_show = ImageShow() # 初始化显示
im_show.show(img) # 显示图像
time.sleep(1)
im_show.close()
def test_mipi_camera():
im_show = ImageShow()
cam = srcampy.Camera() # 定义相机类型
cam.open_cam(0, 1, 30, 1920, 1080) # 设置相机采集所用的参数
while True:
origin_image = cam.get_img(2, 1920, 1080) # 获取相机数据流
origin_nv12 = np.frombuffer(origin_image, dtype=np.uint8).reshape(1620, 1920)
# origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2BGR)
# 图像虽然是RGB实际上是BGR,问题已反馈
origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2RGB)
im_show.show(origin_bgr)
im_show.close()
对这两个函数分别测试,这时候显示屏就会出现对应可视化结果,这样就完成数据可视化所需的一些工作(视频流图像显示这部分,功耗占了1W,CPU占用30%左右,显示这部分的代码还是有点冗余)。
3.3 QT项目测试——串口转Wifi
之前有个项目,要求无人机与地面站直接的通信由之前的数传改为wifi,搜了一圈,很多都属于手工调试,而且包含复杂的界面。然而实际需求要求稳定,自动化。因此为了满足这个需求只能是自己开发一个小工具。该项目的细节部分参考博客串口转wifi —— 两个串口之间通过网络进行通信。
该工具可测试板子的串口模块和Wifi模块的稳定性。
① 利用minicom测试串口。第一次使用可利用命令sudo apt-get install minicom安装相关工具,将开发板的4-5针头,也就是串口的收发接头短接。这样接收到的信息又会发送出去。

② 编译uart2net工具。按顺序执行以下相关代码:
sudo apt-get install qt5-default
sudo apt-get install libqt5serialport5-dev
git clone https://github.com/Li-Zhaoxi/uart2net
cd uart2net
qmake uart2net.pro
make all -j4
③ 配置uart2net.ini文件。注意串口和IP地址的相关配置。

④ 启动uart2net。
- 服务端为个人笔记本,使用了串口调试助手+虚拟串口模拟串口数据的输入。
- 客户端为旭日3派板子,由于
/dev/ttyS3收发已短接,因此,接收到什么数据就会发送出去。
最后测试数据的输出与博客串口转wifi —— 两个串口之间通过网络进行通信是一样的这里就不再进行叙述了。
测试时候发现个问题,由于Wifi传输有一定的延迟,如果每10ms就发送几十个字节的数据的话,会造成大量数据的阻塞,后续在应用时候注意数据传输不要过快,过多,否则会造成几秒的延迟。
3.4 C++项目测试——圆形结构检测
部分项目应用中需要检测场景中的椭圆目标,因此将算法移植到这个板子上,以方便测试检测效果与实时性,通过命令git clone https://github.com/Li-Zhaoxi/AAMED下载椭圆检测代码。
① 编译python代码模块aamed.so。按照下面的方式配置好setup.py文件之后,cd python进入python文件夹,执行python3 setup.py build_ext --inplace编译算法模块。需要修改代码的部分如下所示,直接替换即可。
opencv_include = "/usr/include/opencv4/"
opencv_lib_dirs = "/usr/lib/aarch64-linux-gnu/"
ext_modules = [
Extension(
"pyAAMED",
["../src/adaptApproximateContours.cpp",
"../src/adaptApproxPolyDP.cpp",
"../src/Contours.cpp",
"../src/EllipseNonMaximumSuppression.cpp",
"../src/FLED.cpp",
"../src/FLED_drawAndWriteFunctions.cpp",
"../src/FLED_Initialization.cpp",
"../src/FLED_PrivateFunctions.cpp",
"../src/Group.cpp",
"../src/LinkMatrix.cpp",
"../src/Node_FC.cpp",
"../src/Segmentation.cpp",
"../src/Validation.cpp",
"aamed.pyx"],
include_dirs = [numpy_include,'FLED', opencv_include],
language='c++',
libraries=['opencv_core', 'opencv_highgui', 'opencv_imgproc', 'opencv_imgcodecs', 'opencv_flann'],
library_dirs=[opencv_lib_dirs]
),
]
② 调用MIPI摄像头实现检测。我在测试时候出现了一个错误cannot allocate memory in static TLS block Python,把python头文件的顺序调整了下就OK了。下面给出我的测试代码。
我在显示屏上放上了待检测的照片,让mipi相机去拍显示器完成检测过程
from hobot_vio import libsrcampy as srcampy
import cv2
import numpy as np
import time
from pyAAMED import pyAAMED
# 这里把前面的HDMI可视化部分的代码贴上
# 复制类class ImageShow(object)
# 检测主程序
def test_mipi_camera():
im_show = ImageShow()
cam = srcampy.Camera()
cam.open_cam(0, 1, 30, 1920, 1080)
aamed = pyAAMED(550, 970)
aamed.setParameters(3.1415926/3, 3.4,0.77) # 阈值设置,如果假椭圆过多,可适当调高0.77
while True:
origin_image = cam.get_img(2, 1920, 1080)
origin_nv12 = np.frombuffer(origin_image, dtype=np.uint8).reshape(1620, 1920)
origin_bgr = cv2.cvtColor(origin_nv12, cv2.COLOR_YUV420SP2RGB)
imgG = cv2.resize(cv2.cvtColor(origin_bgr, cv2.COLOR_BGR2GRAY), (960, 540))
imgGC = cv2.cvtColor(imgG, cv2.COLOR_GRAY2BGR)
t1 = cv2.getTickCount()
res = aamed.run_AAMED(imgG) # 检测部分代码
t2 = cv2.getTickCount()
print('time consumption(ms):', (t2 - t1) * 1000 / cv2.getTickFrequency())
for each_elp in res:
cv2.ellipse(imgGC, ((each_elp[1], each_elp[0]), (each_elp[3], each_elp[2]), -each_elp[4]), (0, 0, 255), 2)
im_show.show(imgGC)
im_show.close()
test_mipi_camera()
下面是检测耗时和效果图,检测的图像分辨率为 960 × 540 960\times 540 960×540,这个时耗几乎在37ms左右,也能满足一些基本的算法需求。
time consumption(ms): 36.989471
time consumption(ms): 37.507962
time consumption(ms): 36.99551
time consumption(ms): 43.346158
time consumption(ms): 37.378966
time consumption(ms): 38.764665
time consumption(ms): 38.915905
time consumption(ms): 25.642136
time consumption(ms): 49.384246

3.5 小结
至此,开发板CPU的部分相关所需功能均已测试完毕,总体来说,基本能满足大部分轻量型算法的需求,除了Wifi部分延迟较高,其余我觉得均已经足够适应大部分的任务了。我个人非常喜欢操作HDMI显示图像的方式,降低带有桌面系统带来的性能损耗,极大的给算法留出更多的计算量。

四 BPU项目测试
开发板中的BPU部分为自研芯片,部分深度学习网络层从硬件的角度进行了加速。因此,这个开发板核心在于部署。在前文进入系统部分中,通过cd /app/ai_inference/03_mipi_camera_sample/和sudo python3 mipi_camera.py已经展示了系统自带的检测效果。
4.1 基本操作
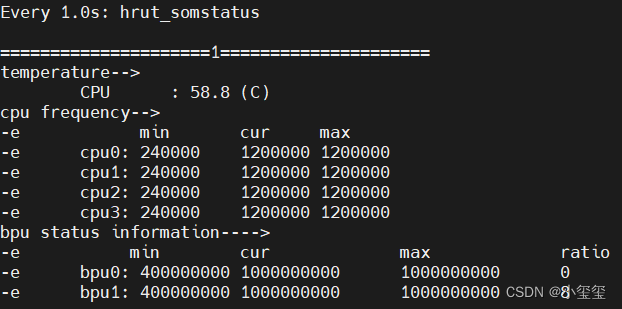
- 查看BPU使用率。使用
sudo watch -n 1 hrut_somstatus命令可以查看当前开发板的bpu使用率,在运行mipi_camera.py的时候,可执行该命令获得BPU利用情况。
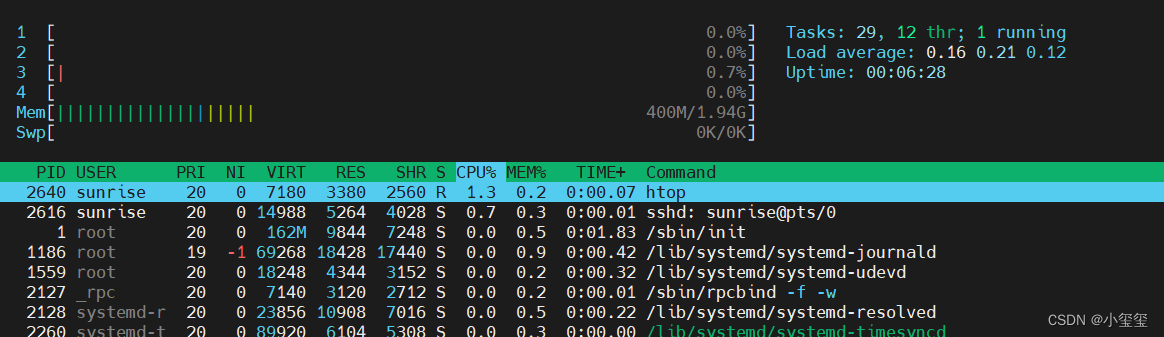
- 查看CPU使用率。尽管hrut_somstatus已经提供了CPU的利用率情况,但我还是觉得
htop效果更直观ԾㅂԾ。
这些操作,主要是用来查看算法的资源占用率的,初级功能。后续非常期待官方出一个类似jetson的jtop工具,jtop的参考链接为jetson_stats。
4.2 已有模型测试
由于开发板的特殊性,利用pytorch训练好的模型,是无法直接用在这个板子上的,官方将一堆常见的模型参数进行了转换。在装好的系统中,有两个可直接使用的模型。fcos用于目标检测,mobilenetv1用于目标分类。
在开发板的/app/ai_inference/01_basic_sample/路径下,提供了一个示例test_mobilenetv1.py,下面对其中的主函数部分进行一个介绍,部分核心功能的解释写在代码注释里面了。这部分通过opencv的cv2.getTickCount()和cv2.getTickFrequency()可测出,耗时约为9ms!!
# 主函数代码前面还包含如下子函数,用于数据转换,参数输出等。
# bgr2nv12_opencv、print_properties、get_hw
if __name__ == '__main__':
# 1. 加载模型,用于BPU加速计算的模型为一个*.bin文件,里面包含了模型的所有信息
models = dnn.load('../models/mobilenetv1_224x224_nv12.bin')
# 2. 输出模型的Input和output信息
# ========== inputs[0] properties ==========
print("=" * 10, "inputs[0] properties", "=" * 10)
# 输出模型的输入信息,输出信息如下
# tensor type: NV12_SEPARATE
# data type: uint8
# layout: NCHW
# shape: (1, 3, 224, 224)
# inputs[0] name is: data
print_properties(models[0].inputs[0].properties)
print("inputs[0] name is:", models[0].inputs[0].name)
# ========== outputs[0] properties ==========
print("=" * 10, "outputs[0] properties", "=" * 10)
# 这里输出模型的输出信息,输出内容如下:
# tensor type: float32
# data type: float32
# layout: NCHW
# shape: (1, 1000, 1, 1)
# outputs[0] name is: prob
print_properties(models[0].outputs[0].properties)
print("outputs[0] name is:", models[0].outputs[0].name)
# 3. 加载图像数据,前面已经输出了模型需要的输入数据尺寸和数据类型
# 因此,先利用cv2.resize将图像转换为目标大小尺寸
# 再利用bgr2nv12_opencv将图像数据转为NV12形式(个人理解是压缩了图像数据,减少了传输时间)。
img_file = cv2.imread('./zebra_cls.jpg')
h, w = get_hw(models[0].inputs[0].properties)
des_dim = (w, h)
resized_data = cv2.resize(img_file, des_dim, interpolation=cv2.INTER_AREA)
nv12_data = bgr2nv12_opencv(resized_data)
# 4. 将图像的NV12数据传入模型中,完成了整体的推理过程
outputs = models[0].forward(nv12_data)
# 下面将模型预测信息打印输出
# ========== Get output[0] numpy data ==========
# output[0] buffer numpy info:
# shape: (1, 1000, 1, 1)
# dtype: float32
# ========== Classification result ==========
# cls id: 340 Confidence: 0.991851
print("=" * 10, "Get output[0] numpy data", "=" * 10)
print("output[0] buffer numpy info: ")
print("shape: ", outputs[0].buffer.shape)
print("dtype: ", outputs[0].buffer.dtype)
# print("First 10 results:", outputs[0].buffer[0][:10])
print("=" * 10, "Classification result", "=" * 10)
assert np.argmax(outputs[0].buffer) == 340
print("cls id: %d Confidence: %f" % (np.argmax(outputs[0].buffer), outputs[0].buffer[0][np.argmax(outputs[0].buffer)]))
其实要把模型装板里,拢共分三步:
- 加载模型。模型格式为*.bin文件,需要利用地平线的天工开物平台转换得到。
- 加载图像数据。图像的加载利用opencv即可完成。获取数据之后,转换为目标尺寸、NV12数据即可直接输入到加载好的模型中。
- 直接推理。
outputs = models[0].forward(nv12_data)即可完成推理,这部分很简单。

4.3 个人模型部署概述
上面介绍了如何将 大象 模型装进BPU里→_→, 其实对个人来说,最难的就是如何获得*.bin文件。这里我其实无法一步步的引导各位如何部署自己的模型,因为这里的部署过程需要利用地平线开发的天工开物工具链,部署教程参考文档:Horizon AI Toolchain User Guide。对我来说,这部分东西太多,学习成本太大了,装进这个博客里有点太多了(多写个博客可以白嫖更多浏览量🤡)。
深度学习用的比较多的还是pytorch,模型可以转换为onnx模型文件,这个模型文件我觉得还是非常通用的,tensorRT和Intel的神经计算棒都利用了这个文件。
模型转换的目的就是检查模型文件中的网络层是否包含在BPU支持的层中(BPU本质上是从硬件的角度加速模型的计算,是一个专用工具),如果某些层不存在,这些层就需要利用CPU完成推理。
实际上,为了保证模型迁移的可靠性,整个上有以下几个关键过程:
① 模型准备。这些模型一般都是基于公开深度学习训练框架得到的, 需要将模型导出为开发板支持的格式,目前转换工具支持的深度学习框架如下。Caffe导出的caffemodel是直接支持的(Caffe是基于C++的,代码相当优美,非常适合硬件转换); PyTorch、TensorFlow和MXNet是通过转到ONNX实现间接支持。

② 模型验证。用来确保提出的算法模型是符合BPU要求的,开发平台提供了hb_mapper checker来完成模型的检查。 不满足迁移的层,就需要手动调整,最简单的办法就是这部分转到CPU来跑(数据传输上存在大量时间浪费),因此还是尽可能将这部分转到BPU上(😔,科研和落地还是有很大差距的)。
③ 模型转换。这个阶段会将浮点模型转为可用BPU使用的模型,利用函数hb_mapper makertbin完成转换,转换成功后,得到的模型就可以运行在开发板上了。
模型转换,不一定就能保证一定就能跑起来,精度和性能都不敢说保证与开发中的结果是一样的,因此需要进行验证和调试。NVIDIA其实也有类似的工作,就是tensorRT,加速必有一定程度的损失,这些不可避免,这些其实涉及到数值分析的内容。这部分有需要的话,可以参考模型性能分析与调优和模型精度分析与调优。
4.4 小结
这部分描述了该开发板BPU部分的使用说明,提供的例子能够轻松跑起来,还是蛮开心的。我本质上是想量化自己的模型,但是时间太紧张,没来得及完成,后续一定要搞起来!!
对这部分,我其实有两点希望后续能够改进:① 给出BPU目前的计算占用率,类似jetson的jtop;② 简化模型转换的过程,文档太多,我觉得除非是刚需,否则看到这堆文档就会被劝退🤦。

五 总结
半个月的开发板适用内容到这里就结束啦,从CPU还是BPU上,我其实对这个板子是很满意的,比较遗憾的就是天工开物量化平台内容太多啦つ﹏⊂。希望该板子能发展地越好越哈,用在更多的设备上。发布会已公布该开发板价格:2G内存版499,4G内存版549!
这里列出几点对我开发过程来说比较重要的,希望后续能够改进的点。
- 生态。地平线开发者社区似乎无法被百度和谷歌搜索到,所以遇到问题,几乎只能看文档。
- 调试。开发板有一些库是独有的,没有有效的IDE能用来在线开发。vscode调试会占用大量的内存。有几点建议:
- 将这些独有函数(比如libsrcampy )提供个windows版,后续直接移植即可。
- 提供个低内存的开发IDE或者VSCode插件
- 提供交叉编译文档,毕竟代码在线编译耗时也较高。
- 界面问题。大量项目代码都是基于界面的,编译应该没问题,但是系统无桌面,所以展示界面会出些问题。
后续针对这个板子,我还会尝试以下几个内容:
- 完成intel realsense 深度相机的应用。深度相机目前这么火,目前没有编译好的驱动,后续研究下移植问题。
- 界面程序输出。由于系统是无界面的,所以QT带界面的程序是用不了了。分析是否有可能应用上界面程序。
- 跑起来自己的模型。如果要应用自己的模型,还需要利用官方的工具进行量化,但对我来说难度稍大,有时间好好理解下开发文档。















 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









