







目录
1 Prompt-Tuning原理:

1.1 hard prompt
硬提示是通过在输入中添加预定义的自然语言提示,引导模型完成任务。假设我们有一个情感分析任务,输入是一段文本,目标是判断文本的情感是“正面”还是“负面”。
- 输入:"The sentiment of the following sentence is [MASK]: 'The movie was fantastic!'"
- 模型预测结果(例如):“positive”
优点:提示可以是人类可读的,且与任务相关。
缺点:设计提示依赖于对任务的理解,效果可能因提示的具体表达方式而异。
1.2 soft prompt
软提示则是将提示部分转换成可学习的向量,模型通过训练这些向量来理解任务。软提示通常不再是自然语言的形式,而是嵌入到模型输入的一个连续的、可训练的向量。仍然以情感分析为例。
- 输入:
<soft-prompt>+ "The movie was fantastic!" - 其中,
<soft-prompt>是一组可学习的嵌入向量,模型会根据这部分向量来调整对情感分析任务的理解。 - 模型通过训练得到的提示向量,预测结果(例如):“positive”
优点:模型可以通过训练学习到最适合任务的提示,不受自然语言表达方式的限制。
缺点:提示是抽象的,不再是人类可读的,需要通过训练来学习。
2 环境配置:
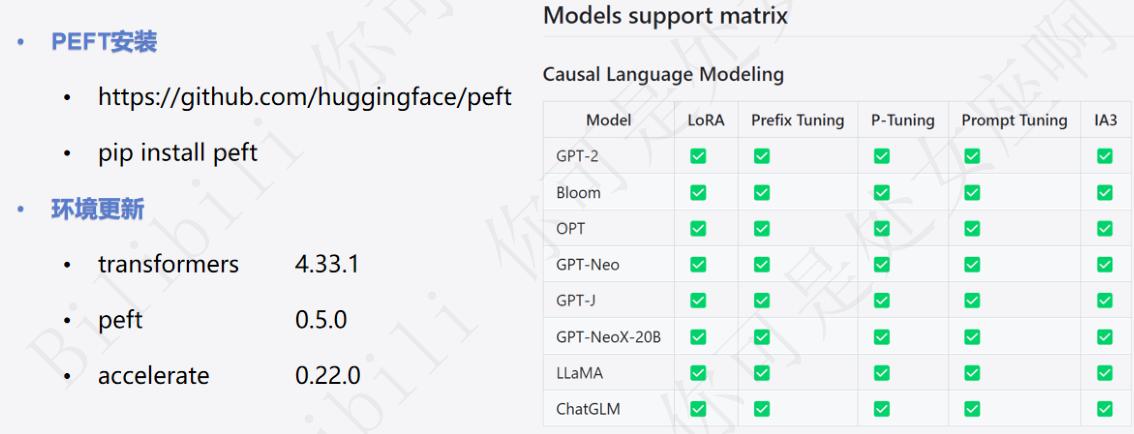
可以在PEFT methods (hf.space)中查看NLP各种任务支持的模型和对应的微调方法
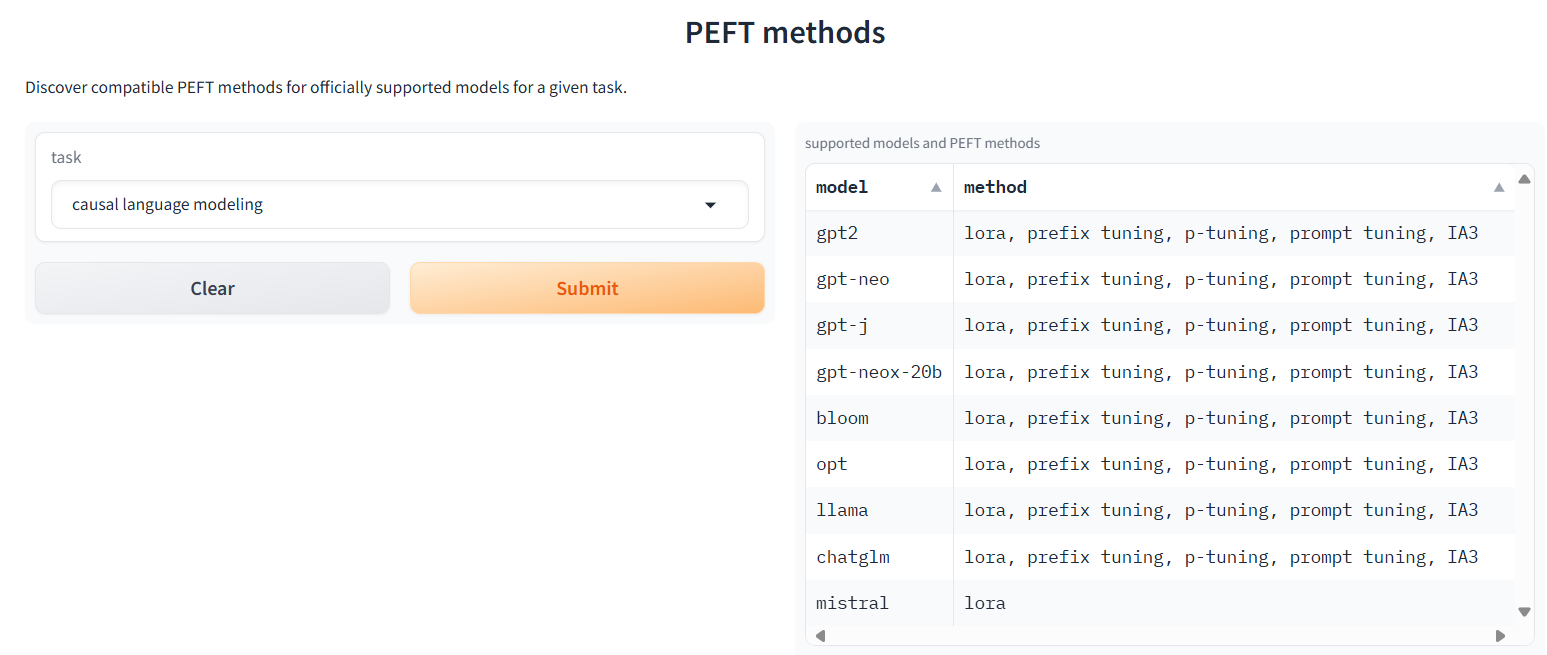
3 Prompt Tuning 代码实战演练
这块大体上我们沿用之前的代码,需要注意的是,Prompt Tuning微调是要在训练数据前加入一小段Prompt,但是这并不意味着我们要在数据处理时加入,只需要在创建模型时予以修改即可。
3.1 导包
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer3.2 加载数据集
ds = Dataset.load_from_disk("../data/alpaca_data_zh/")
ds3.3 数据集处理
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizerdef process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds3.4 创建模型
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)接下来需要分为两步走:
3.4.1 创建配置文件
3.4.1.1 导包:
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInitPromptTuningConfig是用于配置 Prompt-Tuning 的类。它定义了 Prompt-Tuning 的具体设置和超参数,控制提示(prompt)部分的长度、初始化方式等。get_peft_model是 PEFT 库中的一个函数,它根据传入的基础预训练模型和特定的配置(如 Prompt-Tuning 配置)返回一个经过 PEFT 微调后的模型。TaskType是一个枚举类型,用于指定不同的任务类型。PromptTuningInit是一个初始化策略,用于控制 Prompt-Tuning 中提示向量的初始化方式。例如是采用hard还是soft。
3.4.1.2 软提示:
# Soft Prompt
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)
configtask_type=TaskType.CAUSAL_LM表示任务类型是自回归语言模型;
num_virtual_tokens=10用于指定prompt的长度。
PromptTuningConfig(peft_type=<PeftType.PROMPT_TUNING: 'PROMPT_TUNING'>, auto_mapping=None, base_model_name_or_path=None, revision=None, task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, inference_mode=False, num_virtual_tokens=10, token_dim=None, num_transformer_submodules=None, num_attention_heads=None, num_layers=None, prompt_tuning_init=<PromptTuningInit.RANDOM: 'RANDOM'>, prompt_tuning_init_text=None, tokenizer_name_or_path=None)
prompt_tuning_init=<PromptTuningInit.RANDOM: 'RANDOM'表示初始化方式为软提示
3.4.1.3 硬提示:
# Hard Prompt
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
prompt_tuning_init_text="下面是一段人与机器人的对话。",
num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话。")["input_ids"]),
tokenizer_name_or_path="Langboat/bloom-1b4-zh")
configprompt_tuning_init=PromptTuningInit.TEXT表示采用硬提示;
prompt_tuning_init_text指定具体的prompt内容;
num_virtual_tokens用于指定长度,prompt长度超过这个会被截断,小于这个会循环增长,这里我们保持与prompt的长度一致即可;
tokenizer_name_or_path用于指定tokenizer。
3.4.2 构造模型
model = get_peft_model(model, config)
modelPeftModelForCausalLM(
(base_model): BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(46145, 2048)
(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
(0): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(1): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(2): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(3): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(4): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(5): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(6): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(7): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(8): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(9): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(10): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(11): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(12): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(13): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(14): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(15): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(16): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(17): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(18): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(19): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(20): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(21): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(22): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
(23): BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)
(prompt_encoder): ModuleDict(
(default): PromptEmbedding(
(embedding): Embedding(10, 2048)
)
)
(word_embeddings): Embedding(46145, 2048)
)可以看到最后有一个prompt_encoder,这个就是我们Prompt-Tuning要训练的模块(只训练该Embedding模块)
查看训练参数数量:
model.print_trainable_parameters()软提示:
trainable params: 20,480 || all params: 1,303,132,160 || trainable%: 0.0015715980795071467
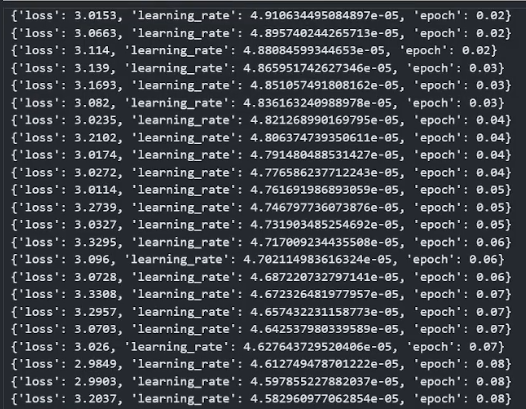
可以看到采用软提示方式虽然用于训练的参数量非常小,但是训练过程中loss降低地很缓慢,可能需要训练很多轮才有一个不错的效果。
硬提示:
trainable params: 16,384 || all params: 1,303,128,064 || trainable%: 0.0012572824154909767
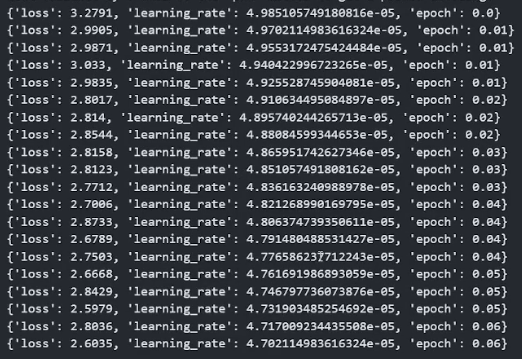
可以看到采用硬提示方式即使用于训练的参数量非常小,但是训练过程中loss降低地也还可以,至少可以说在这个模型|任务上会比soft的效果要好。
3.5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1
)3.6 创建训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)3.7 模型训练
trainer.train()在深度学习中,checkpoint(检查点) 是模型训练过程中的一种存储机制,它用于保存训练的中间状态或最终结果,方便模型恢复训练、评估或者部署。
一个典型的 checkpoint 文件通常包含以下几个部分:模型权重(Model Weights)、优化器状态(Optimizer State)、训练进度(Training Progress / Epoch Number)、模型配置文件(Model Config)。
peft_model = peft_model.cuda()
ipt = tokenizer("Human: {}\n{}".format("考试有哪些技巧?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(peft_model.device)
print(tokenizer.decode(peft_model.generate(**ipt, max_length=128, do_sample=True)[0], skip_special_tokens=True))之前我们在配置训练参数时,默认每500步存一次checkpoint,那么我们如何加载呢?
from peft import PeftModel
peft_model = PeftModel.from_pretrained(model=model, model_id="./chatbot/checkpoint-500/")这里要确保模型在同一台设备上(如果训练的时候是在GPU上,则需要重新加载),CPU上的可以按照上述方式直接加载。
3.8 模型推理
peft_model = peft_model.cuda()
ipt = tokenizer("Human: {}\n{}".format("考试有哪些技巧?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(peft_model.device)
print(tokenizer.decode(peft_model.generate(**ipt, max_length=128, do_sample=True)[0], skip_special_tokens=True))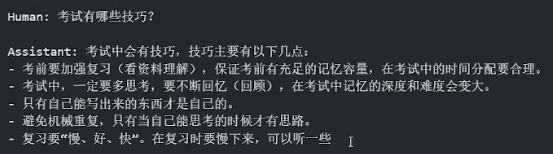
在本次课程中,hard在该任务|模型上的表现优于soft,那么soft就真的一无是处么?如何对其进行优化呢?这个我们将在下个章节中展开讨论


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









