







文章目录
论文精读-ViA: A Novel Vision-Transformer Accelerator Based on FPGA
优点:
1、针对数据依赖,使用了关键部分数据的相关性分析,利用局部性原理+分区策略解决图像数据的局部性问题,提高了整体计算和内存访问效率。
2、针对transformer中的shortcut引起的路径依赖问题,利用半层映射和吞吐量分析减少路径依赖开销,减少片上资源的开销。(感觉本质上就是对关键路径拆分,使用流水线优化)具体来说就是针对vit模型的计算流程,进行了模块拆分自关注模块NAS和多层感知器模块NMP,利用pingpong的方式计算。
3.提出了一种基于贪心策略的工作负载同质性算法进行设计空间的探索。
概述
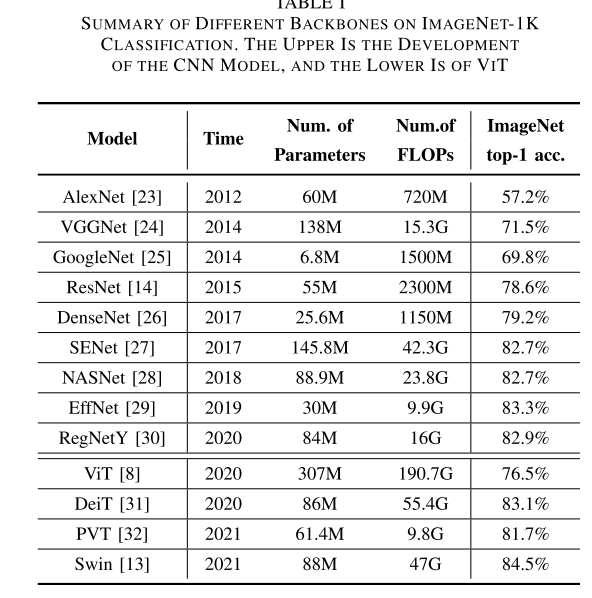
自谷歌于2017年提出Transformer以来,它在自然语言处理(NLP)方面取得了重大进展。然而,不断增加的成本是大量的计算和参数。为了有效地处理NLP任务,前人针对FPGA中的变压器模型设计并提出了一些加速器结构。现在,Transformer的发展也对计算机视觉(CV)产生了影响,并在各种图像任务中迅速超越了卷积神经网络(cnn)。CV中使用的图像数据与NLP中的序列数据存在明显差异。这两个领域中包含变压器单元的模型中的细节也有所不同。数据方面的差异带来了局部性的问题。模型结构上的差异带来了路径依赖的问题,这在现有的相关加速器设计中没有被注意到。
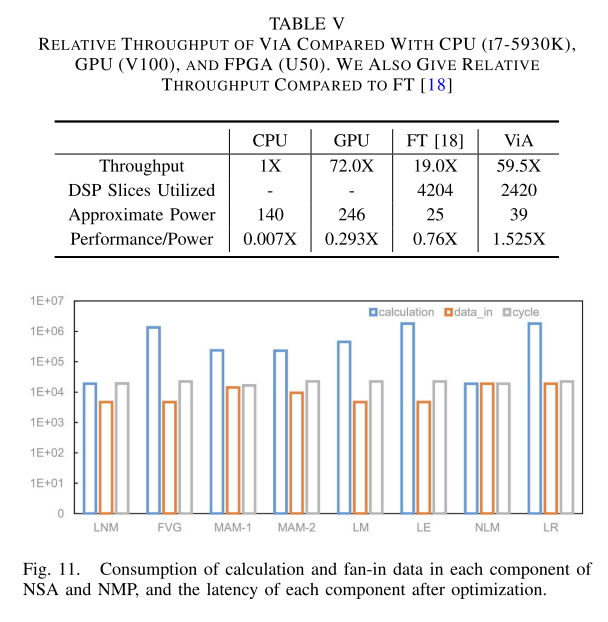
因此,在这项工作中,我们提出了ViA,一种基于FPGA的新型视觉变压器(ViT)加速器架构,以有效地执行变压器应用并避免这些挑战的成本。通过对ViT数据结构的分析,设计了合适的分区策略,减少了图像中数据局部性的影响,提高了计算效率和内存访问效率。同时,通过观察ViT的计算流程,采用半层映射和吞吐量分析,减少了捷径机制带来的路径依赖影响,充分利用硬件资源,高效执行Transformer。基于优化策略,我们设计了两个内部流的重用处理引擎,不同于以往的重叠或流设计模式。在实验阶段,我们在Xilinx Alveo U50 FPGA中实现了ViA架构,最终实现了与NVIDIA Tesla V100相比能效提高~ 5.2倍,与基于FPGA的相关加速器相比性能提高4-10倍,在peek中获得了近309.6GOP/s的计算性能。
背景介绍
transformer在cv中与cnn的差异在于它关注的是一个像素与其他像素在通道中的相似性,而不是感受野中的特征值。
目前tranformer也应用与视觉领域,并带来了显著的性能提升,性能改进的代价是基于变压器的模型有数百万到数十亿的参数和大量的计算,就像WikiText-2中使用的GPT-2有1542M的参数。基于这些原因,前人已经设计并提出了一些基于现场可编程门阵列(FPGA)的加速器结构,用于变压器有效地处理NLP任务。为了减少数据量和计算量,以前的一些研究在变压器模型中设计了不同的剪枝策略,并在硬件架构中实现,如TEC、FT和FTRANS。而且,之前的一些作品使用了不同的量化机制来减少整体的计算量。同时,在变压器模型的计算过程中,ELSA[22]和NPE[15]关注了许多非线性计算单元。这些目的性的近似计算取代了这些单元,提高了整体的计算性能。
1、在数据结构上,CV中使用的图像数据的维数为4,而NLP中使用的文本数据的表达形式为序列,维数为3。进一步,ViT将图像数据处理为一系列补丁令牌[8],并找出具有多头自关注的补丁令牌之间的关系。所以由于自注意的计算过程,图像数据的局部性与序列数据不同。与序列数据相比,图像数据具有更多的分裂维度和冗余信息。因此,当将该策略映射到硬件平台中的计算单元进行效率计算时,ViT可能在数据流中具有更高的并行度和更高的性能。
2、在计算流方面,由于变压器中的shortcut[14],整体计算中的路径依赖影响了带管道的硬件计算。为了消除这种影响,这些额外的数据需要更多的片上资源来存储[33]。然而,ViT在整个模型中只使用编码器模块,这使得shortcut的分布更加规则。因此,通过利用shortcut的规律性,修改映射到硬件上的模块大小,可以有效消除路径依赖的影响,降低片上资源的开销。
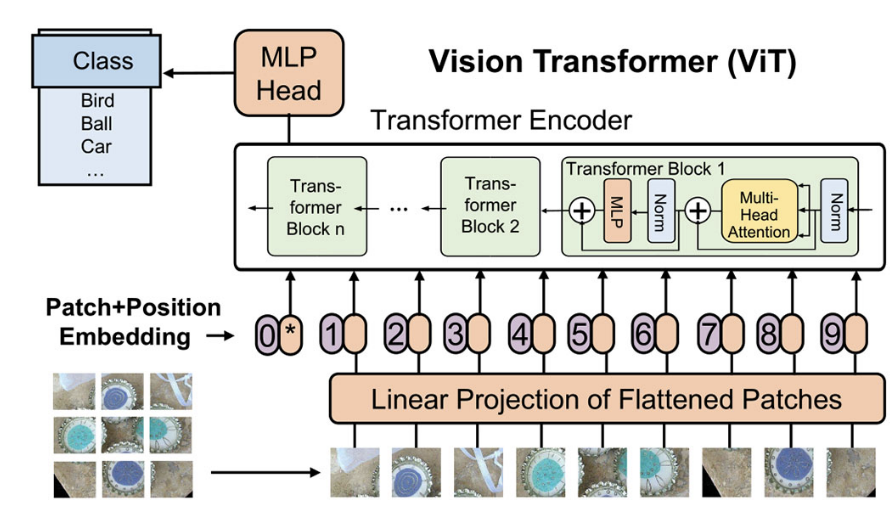
vit (vision transformer)
在NLP中设计变压器时,考虑到要面对多个一维序列数据。通过嵌入机制将每个词映射成一个特征向量。然后,当嵌入的数据通过编码器逐层到解码器时就可以得到结果。在CV中,ViT对模型整体结构进行了修改,如图1所示。首先,研究人员去掉了解码器单元,简化了模型结构。其次,将图像数据划分为固定大小的patch,以避免大量计算所有像素特征的相似性[8]。如图所示

动图演示:
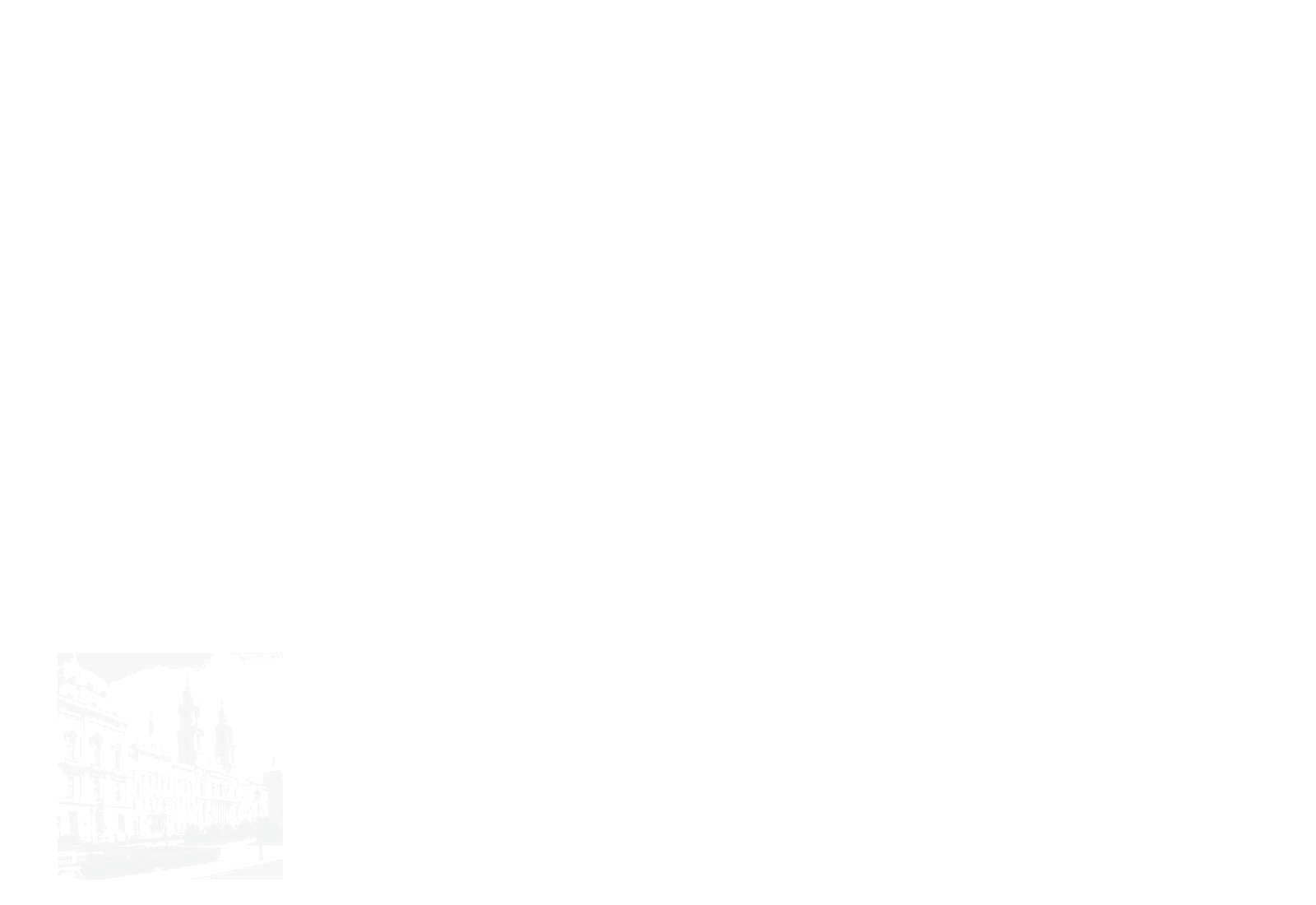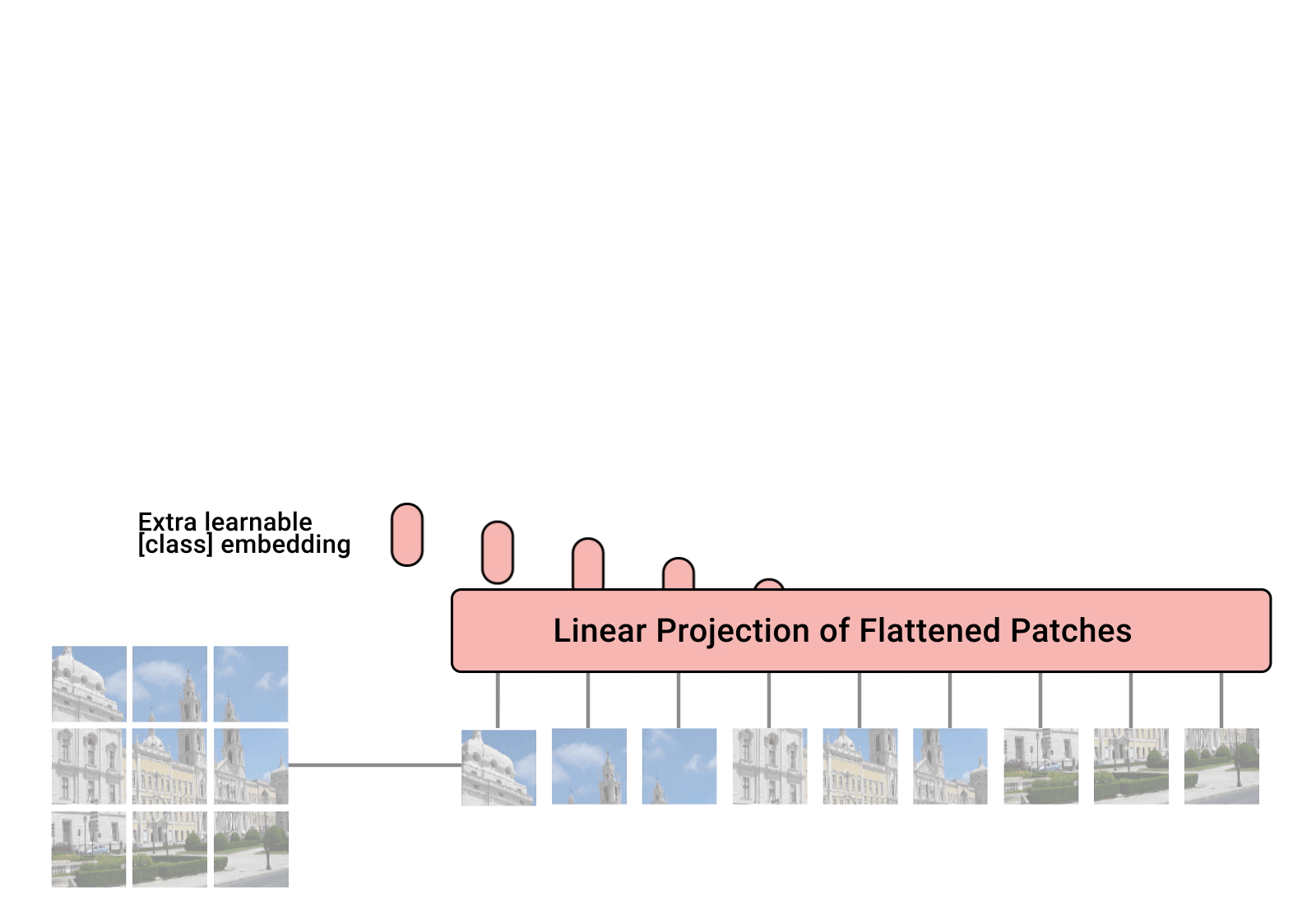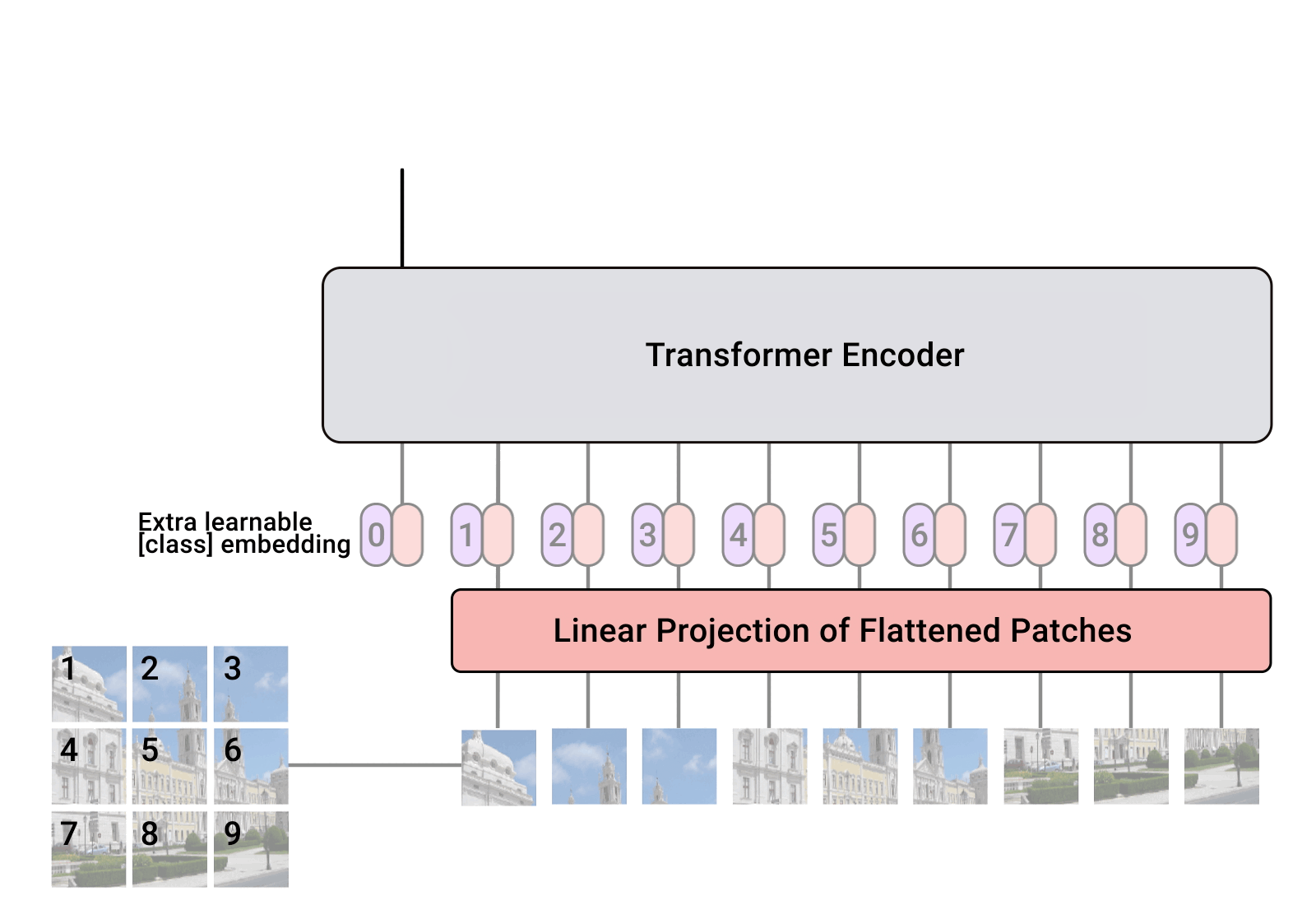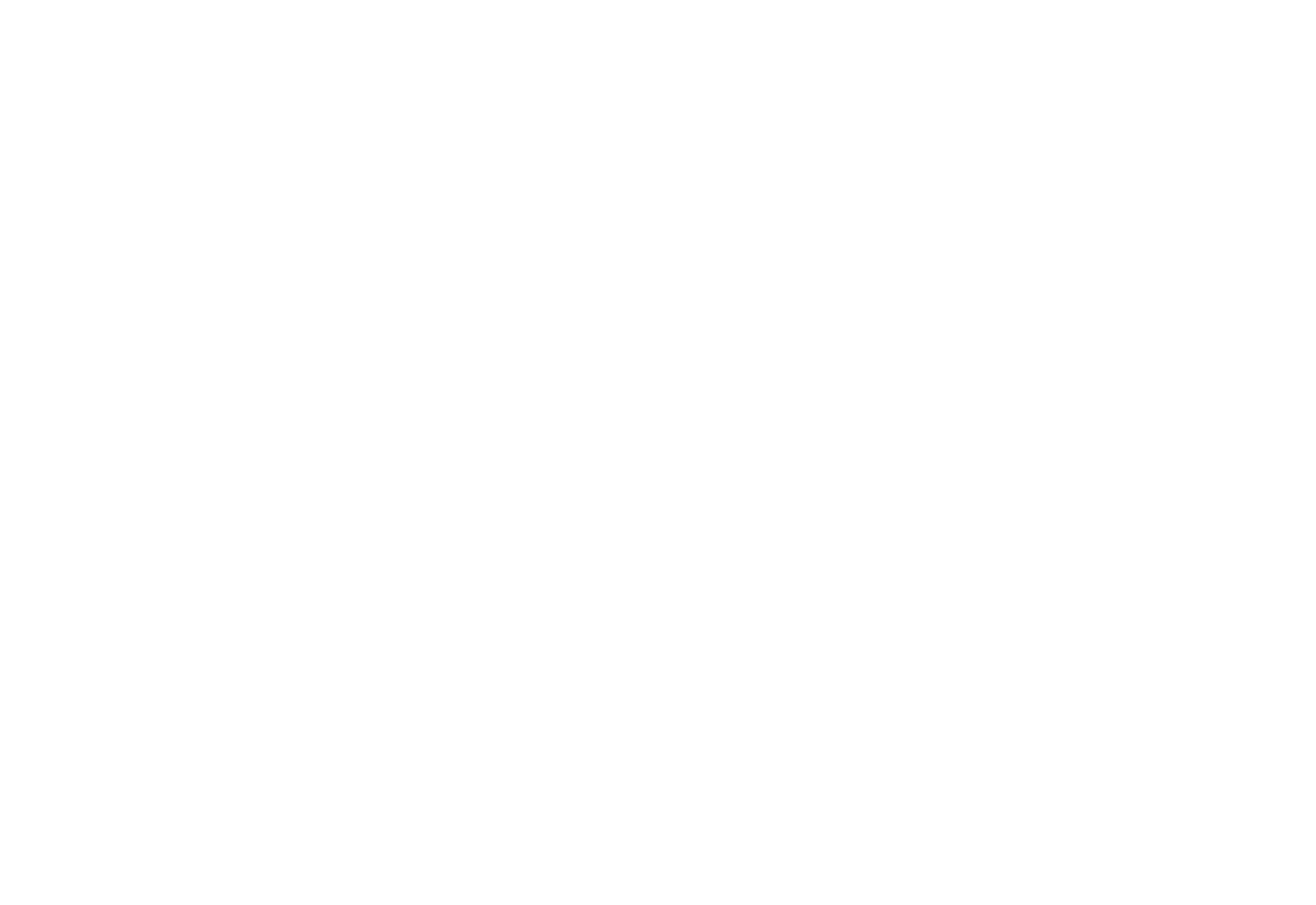
在图1中,我们可以清楚地了解整个ViT的计算过程。位置嵌入后,在变压器编码器中,数据将被n个变压器块依次处理,包括层归一化、多层感知器(MLP)、多头自关注(MSA)、GELU等。最后,通过MLP计算变压器编码器的输出,得到结果。表2为变压器块的初步计算过程,主要分为层归一化1、MSA、层归一化2、MLP四部分进行计算。进一步,整体计算过程中存在潜在的并行空间,具体细节在V-B节展开。虽然ViT通过将图像分割成固定大小的补丁作为令牌来减少总体计算量,但复杂度仍然很高,与令牌的平方成正比。为了解决这些问题,金字塔ViT (PVT)采用了CNN的金字塔结构。它通过多阶段卷积操作[32]逐层减少令牌的数量。同时,Swin Transformer不仅使用金字塔结构,而且在每个阶段之间缝合每个< 2,2 >区域的像素,通过线性映射[13]进一步减少令牌数量(类似池化)。此外,Swin Transformer增加了移位窗口,使得每个patch之间的边界信息可以在网络层之间保留,从而获得比ViT更好的图像任务性能。
vit计算过程如下:
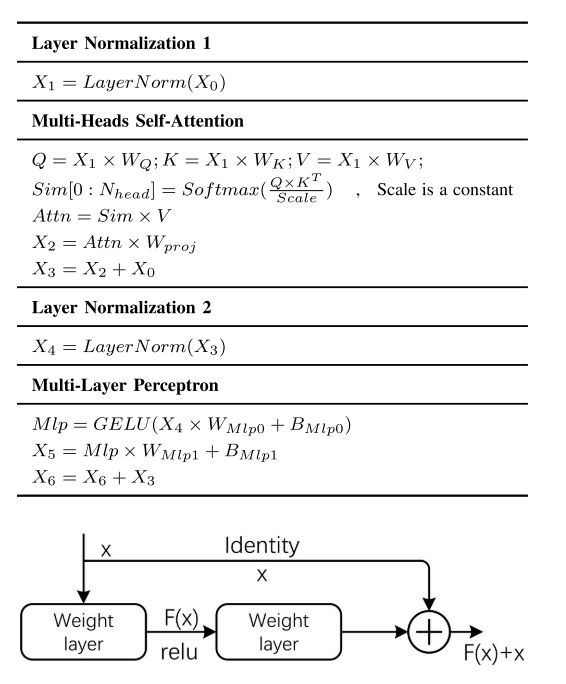
identity(shortcut)会占用p-1的存储开销(p为流水线级数)
目前加速器的设计模式
在基于FPGA的计算加速器实现中,目前设计的硬件架构分为[35]、[36]、[37]两种类型,即重叠模式和流模式。
1、重叠法的思想主要是设计一个可重用的大处理引擎来执行算法[38]的计算部分。同时,硬件控制和操作调度由上层[39]、[40]的软件执行。因此,它可根据输入模型和可用FPGA资源进行扩展,如图4上部所示。这种设计的优点是灵活,当输入模型发生变化时,我们不需要重新配置,但计算类型没有改变[41]。但是,由于控制机制类似于一般处理器,所以在计算[42]时要达到最大的效率并不容易。由于这种 一刀切(使用相同计算单元) 的方法可能导致在不同工作负载特征的网络模型[43],[44]上的最终性能不一致,因此在ViT上也会出现这种情况,并且各个计算部分之间存在多种非线性函数。因此,如果以重叠模式运行模型,实现计算单元的最优设计尺寸和处理的最优调度可能是具有挑战性的。
2、另一种设计模式流(stream)与重叠模式相反。它在目标算法的计算流中为每个计算部分实现不同的硬件单元,并分别对其进行优化,以利用块间平行等位关系[45],[46]。如图4底部所示,计算单元按照算法的顺序进行连接。数据流经每个单元后,即可完成计算并流入下一个单元[47]。因此,这种设计模式的优势在于,根据不同计算部分特性的差异,我们可以使用不同的方式来优化每个硬件内核[48]中的实现和并行方案。但缺点是 不灵活 ,我们要针对不同的网络模型设计新的硬件计算单元。ViT具有多种处理功能,更适合于流模式。然而,在计算中随处可见的shortcut,使得在加速器中难以提高性能效率。因此,我们设计了一种有效的映射策略,以减少其有害影响。
(ps:重叠模型和流模式就类似于通用处理器(only 一次设计)与专用加速器(需要根据应用定制)的区别)
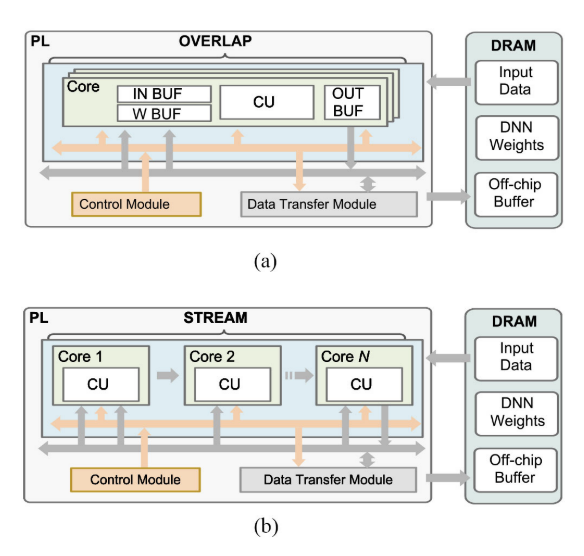
VIA加速器设计
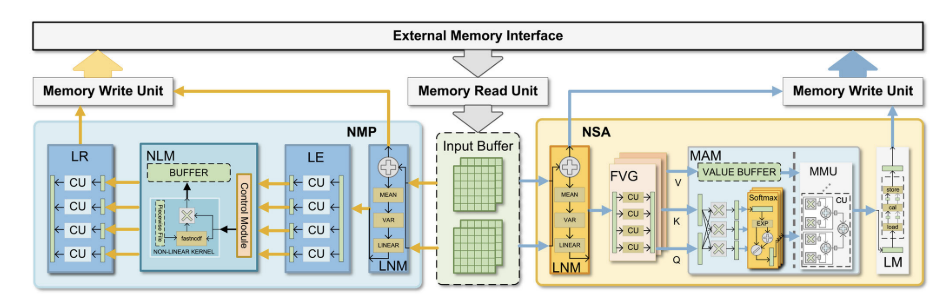
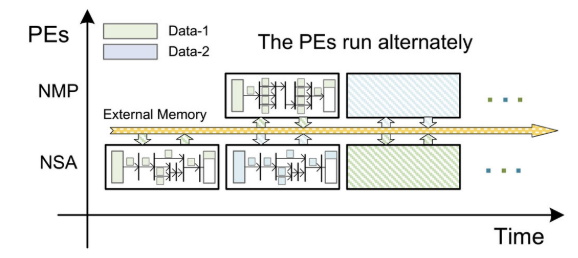
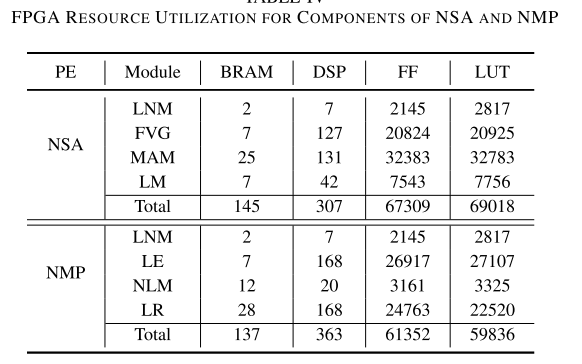
它由存储器读取单元(MRU)、存储器写入单元(MWU)、输入缓冲区和两种类型的处理元件(pe)组成,规范自关注模块(NSA)和规范MLP模块(NMP)。
(ps:典型的流模式计算,将计算过程分成了两个模块)
计算过程:
当输入数据被MRU加载到缓冲区中时,控制器将数据分别分配给NMP或NSA进行高效的本地计算。
NSA主要负责计算ViT模型中的层-范数层和多头自注意层。同时,NMP主要负责计算层范数层和MLP层。根据图1中ViT的网络结构,我们可以找到ViA中处理变压器的顺序。在计算变压器编码的结果时,ViA首先使用NSA单元计算变压器块1前半部分的输入数据-1的结果,然后将其发送回外部存储器。
NMP单元在block-1的后半部分继续计算结果。同时,NSA单元也被并行化,在变压器block-1的前半部分计算输入data-2的结果。以此类推,将数据-1和数据-2的计算结果分别在NSA和NMP两个pe中进行交叉处理,最终得到变压器-2 ~ n块的输出。
(pingpong处理)
数据流动:
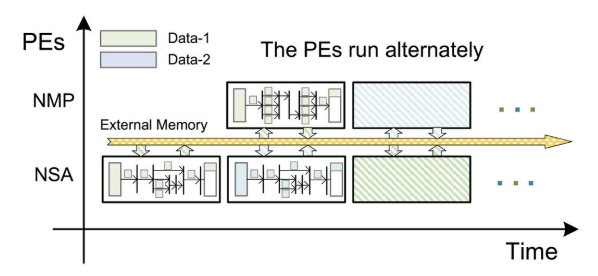
整个计算过程由NSAs和nmp协同完成。图5-7显示了NSA将输入数据从外部存储器加载到LNM上的本地缓冲区。然后,缓存的数据经过LNM和FVG后,得到查询、键和值的集合。此外,我们将设置的值缓存到MAM的本地存储中,而MAM中的计算单元计算MSA的第一阶段结果。在第一阶段之后,MAM从本地存储加载值集。它依次处理第二阶段的MSA和LM,得到中间结果并写入外部存储器。同时,当NSA运行时,NMP还将外部存储器中的数据加载到LNM上的本地缓冲区中,并通过LE、NLM、LR对输入数据进行处理,从而得到整个变压器单元的结果。通过多次重复这一操作,可以在硬件加速器上处理具有不同层数和变压器单元的模型。
ViA的总体操作顺序如图8所示。在开始阶段,首先将数据1从外部存储器加载到NSA的内部缓冲区中。内部流处理完成后,data-1在变压器的上半部分完成计算。data -1被数据写单元写回外部存储器。然后,NSA和NMP同时加载data-2和data-1,不同作品并行计算,分别写回外部内存。剩下的操作可以通过类比推导出来。NSA和NMP交替处理data-1和data-2,直到整个计算过程结束。
NAS 自关注模块
NSA的结构如图5所示,它由层归一化模块(LNM)、特征向量生成器(FVG)、多头注意模块(MAM)和线性映射模块(LM)组成。输入数据通过LNM进行计算,成为标准化数据。然后,FVG生成并行的查询、键和值特征集。然后,将数据流经MAM,得到该patch的特征相似度值矩阵。最后,我们可以通过LM(线性映射)得到输出。
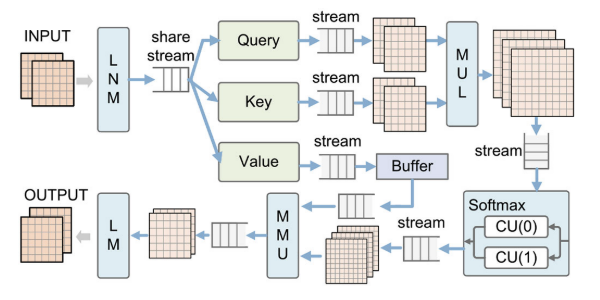
1、LNM包含三个操作:1)加载数据;2)计算统计参数;3)标准化输出。LNM将部分输入数据加载到计算单元的本地缓冲区中,计算特征维下数据的均值和方差,并将数据标准化输出。因此,LNM的总体计算时间可能在HWC*4的水平内。
2、此外,FVG还需要计算多头自关注机制的特征集。在这里,我们将输入数据三次广播到计算单元,以并行计算查询、键和值集的结果。因此,FVG的整体计算时间可能在R * c2的水平内。
3、然后,MAM被分成两个部分,MAM-1和MAM-2。MAM-1计算查询Q和关键字K^T的特征相似度结果,而MAM2计算相似度矩阵(attention score)与值(V)的乘积,得到自关注结果(attention value)。此外,这两个部分的计算次数大约是NW 2C+NW 2和NW 2*C。由于需要在MAM-2中使用FVG输出结果中设置的值,因此将处理分为两个部分。为了提高计算管道的效率,通过缓存一个阶段的值,MAM的性能可以增加到两倍,而不需要额外的计算资源开销(流水线)。最后,LM用线性映射计算输入,并输出结果。整体计算时间大概在R * C2的范围内。
(第一个MAM对应MUL+softmax,第二个MAM对应MMU)

(LN+MSA)
NMP 多层感知器模块
NMP的结构如图5所示,它由LNM、线性膨胀器(LE)、
非线性映射(NLM)和线性重定向器(LR)组成。输入数据是由NSA计算得到的输出数据,通过LNM进行标准化。我们可以在通过LE、NLM和LR后实现部分输出。
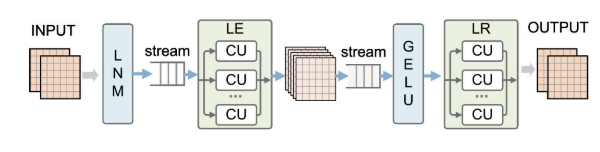
(ps:LR 线性重定向器是一种函数,它能够将一个点从一个高维空间映射到一个低维空间,同时尽量保持原始点的性质。减少参数数量,提高效率,改善性能)
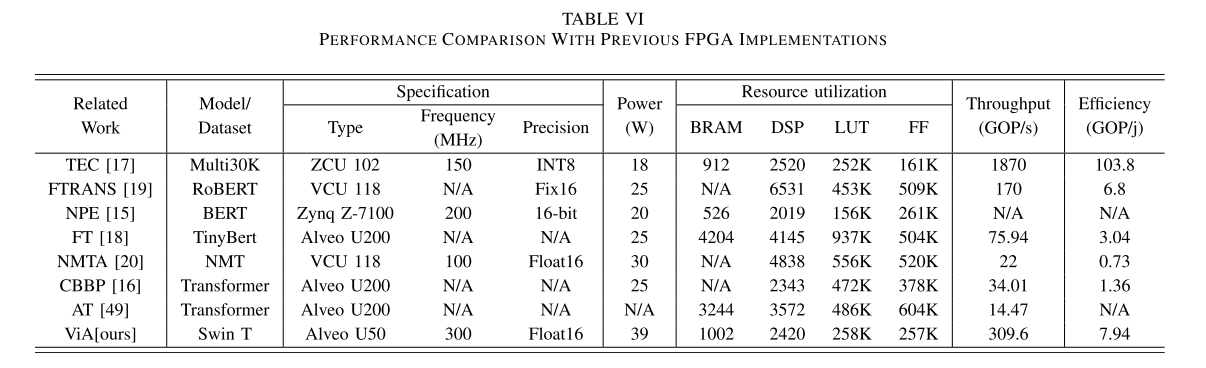
要保证在这种流计算结构中进行高效处理,就必须保证每个阶段的吞吐量是相似的。

(LN+MLP)
方法
半层映射
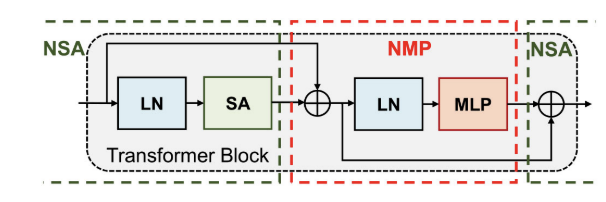
实际的网络结构是:N*(NSA+NMP),即每个输入需要经过N层Transformer块。
在每个模块开始前计算残差:(上一层的输出->最新输入)+(当前层的DRAM输入,即之前没有更新的输入)->根据结果更新dram
当然第一层没有残差计算。根据这个计算规则,实际上不分为NSA和NMP也是可行的。
避免了原来shortcut带来的路径依赖问题,同时减少了流水线缓存的存储开销(减少了寄存器或BRAM的使用)。
数据分区
整个计算过程中输入和输出数据的独立相关性分析:
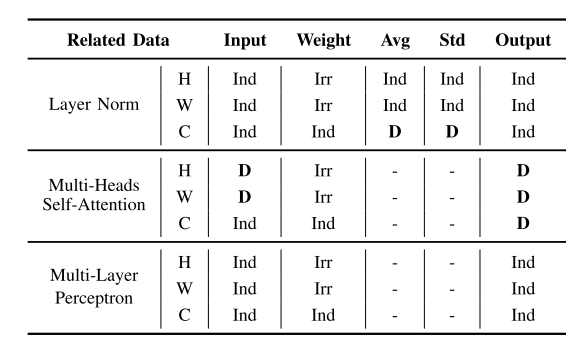
核心利用独立性,提高并行效率。
- ind表示independence,表示可以在这个维度上进行划分,并行处理不受影响。
- d表示dedependence,表示数据分割后,这个维度并行处理将涉及同步、合并或计算顺序的影响。
- irr表示irrelevant不相干,表示数据的计算过程可以在这个维度上任意分割和变换,不会影响其并行性。
希望对ViT进行计算性拆分,则需要避免拆分维度的依赖性。必须尝试沿着不相关和独立的数据维度进行分割。
从 <B, H,W, C> to <Ws,Ws, C/Nhead> (H,W,C)
1、对于N层网络,因为LN和MLP都是可并行的,且B个输入也是可并行处理的,所以整体可提升B * N * N的性能.
2、而此时每个buffer单元需要存储数据Buffer = B ∗ H ∗ W ∗ C ∗ precision − > Ws^2 ∗ C/Nhead ∗ precision.
设计空间探索

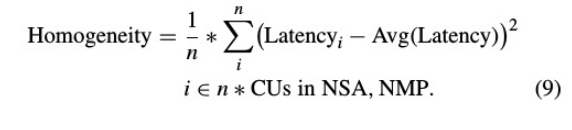
ViA的综合性能受到NSA和NMP两种pe中各计算部分最大时延的影响。
目的:为了提高计算效率和硬件资源利用率。
工作原理:
初始化参数后,我们可以从硬件模板中获得每个计算单元组件,无需并行化。
1、首先,我们在当前组件列表中找到具有巨大延迟的组件。
2、然后,确定是否组件可以根据当前情况进行加速,提高计算性能,降低延迟。经过判断,修改组件的内部配置,并行度增加1,计算单元组件随硬件模板再生。对于这个不能再加速的组件,另一部分将通过降低除该组件外的其他组件的并行度,更新整个组件列表的方式进行处理。
同时,算法会检查更新后的组件列表的资源使用情况,并更新同质性的当前值和旧值。
3、最后,我们将根据现有条件得到具有工作负载同质性的计算单元的实现。
实验结果
QA
Q:数据局部性,模型路径依赖
A:
Q:Patch Token 补丁令牌?
A:“补丁”(Patch)是指将输入图像分割成的小块,这些小块可以被视为图像的局部区域。ViT模型通过将这些补丁作为序列元素输入到Transformer架构中来进行图像分类任务。(视觉模型是patch+positional encoding,对于语言模型就是word embedding+positional encoding)
- 图像分割:在ViT模型中,输入图像首先被分割成大小相等的非重叠补丁。例如,如果输入图像的分辨率是
(H, W, C)(高度为H,宽度为W,通道数为C),可以将其分割成(N, H', W', C)大小的补丁,其中N是补丁的数量,H'和W'是每个补丁的高度和宽度。 - 线性嵌入:每个补丁通过一个线性层(通常是一个全连接层)进行嵌入,将每个补丁映射到一个固定维度的向量空间中。
- 补丁令牌:这些嵌入后的向量可以被视为类似于自然语言处理中使用的令牌。在自然语言处理中,文本被分割成单词或子词,然后转换为令牌(token)序列。在ViT中,图像补丁的嵌入向量扮演了类似的角色,因此有时也被称为补丁令牌。
- 序列化:这些补丁令牌按照原始图像中的顺序(例如,从左到右,从上到下)排列成一个序列,然后输入到Transformer模型中。
- 位置编码:由于Transformer模型本身不具备捕捉序列中元素顺序的能力,因此在输入序列之前,通常会添加位置编码(Positional Encoding),以提供每个补丁在原始图像中的位置信息。
- 分类任务:在ViT模型的最后,通常会有一个全局平均池化层(Global Average Pooling, GAP)或类似的操作(MLP),将所有补丁令牌的信息汇总起来,用于图像分类任务。
Q:CNN的金字塔结构?
A:特征金字塔FPN
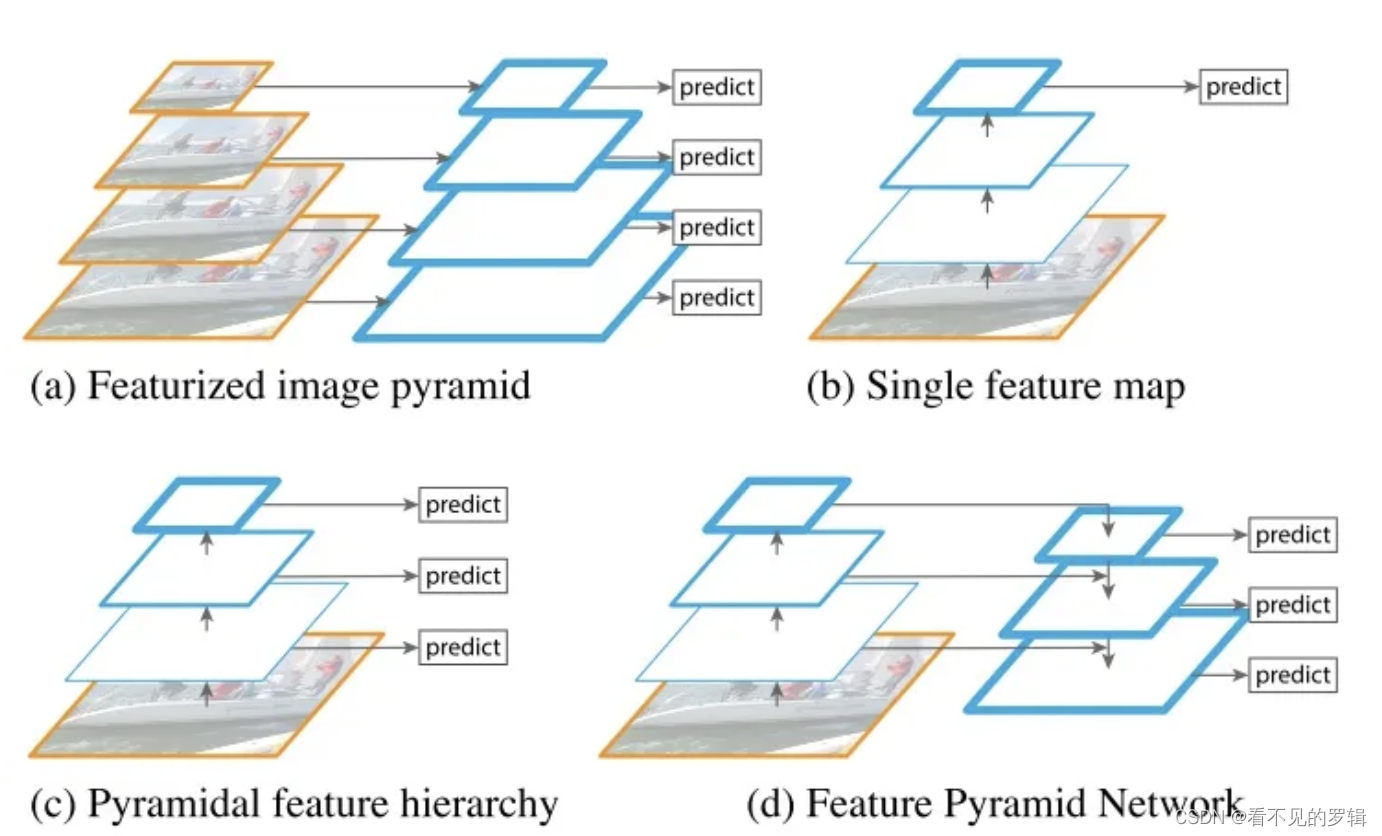
FPN详情:https://zhuanlan.zhihu.com/p/92005927

Q:特征向量生成器(FVG)?
A:
Transformer中更多是:

一般的FVG可能包括:

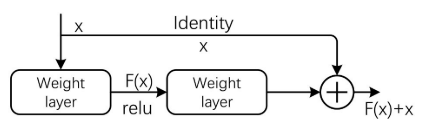
Q:变压器中的shortcut?
A:shortcut残差结构,为了让我们训练更深层次的网络,解决网络退化的问题。由于残差结构引起的路径依赖,需要使用多级缓冲区来减少执行半映射优化之前管道等待的计算开销。

Q:加速器设计中重叠模式与数据流模式?
A:重叠模式类似于GPU中的计算单元,资源可以共用(适用于所有计算方式),比较灵活。其控制机制类似于一般的处理器,但是无法保证所有任务在资源利用率和计算性能上较高。
而数据流模式类似专用加速器设计,是根据网络数据流的流动来进行分模块的设计,优点是可以根据不同计算部分特性的差异,我们可以使用不同的方式来优化每个硬件内核中的实现和并行方案,缺点是不够灵活,需要定制化设计。
Q:同质性衡量优化后的结果?


为了使计算性能和硬件利用率更好,我们需要尽可能地降低同质性的值。因此,我们提出了一种基于贪心策略的工作负载同质性算法来完成DSE任务。如算法1所示,初始化参数后,我们可以从硬件模板中获得每个计算单元组件,无需并行化。首先,我们在当前组件列表中找到具有巨大延迟的组件。然后,确定是否组件可以根据当前情况进行加速,提高计算性能,降低延迟。经过判断,修改组件的内部配置,并行度增加1,计算单元组件随硬件模板再生。对于这个不能再加速的组件,另一部分将通过降低除该组件外的其他组件的并行度,更新整个组件列表的方式进行处理。此外,算法会检查更新后的组件列表的资源使用情况,并更新同质性的当前值和旧值。最后,我们将根据现有条件得到具有工作负载同质性的计算单元的实现。
[Ref:Wang T, Gong L, Wang C, et al. Via: A novel vision-transformer accelerator based on fpga[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2022, 41(11): 4088-4099.]


















 3859
3859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











