







多项式事件模型(multinomial event model)
回顾
上述文章讨论了基于朴素贝叶斯的文本分类,即多变量伯努利事件模型(multi-variate Bernoulli event model)
本章继续讨论多项式事件模型(multinomial event model)
概念初步
专为文本分类而生。(后验估计)
ps:最大后验估计补习
模型
- 我们首先假设,邮件是随机发送过来的(垃圾与非垃圾),所以有先验概率p(y)
- 然后我们假定(强假设),邮件里每个单词是独立的,p(xi=1|y)=φ(i|y)
总概率
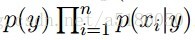
综述
设xi为email里第i个词,且xi=(dict里对应单词的位置)
显然xi在{1, ... ,|V|}里取值,其中|V|是特征字典(dict)的长度
所以:
- 一个长度为n的email就被描述成一个长度为n的向量x(i):
- 假定给定训练集:
- 根据模型概率,新样本的似然函数为:
- 极大似然估计为:
- 加入拉普拉斯平滑:
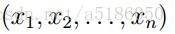
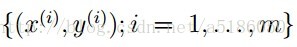
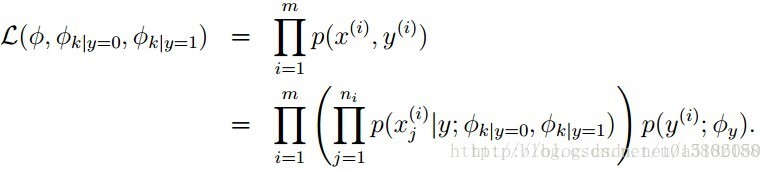
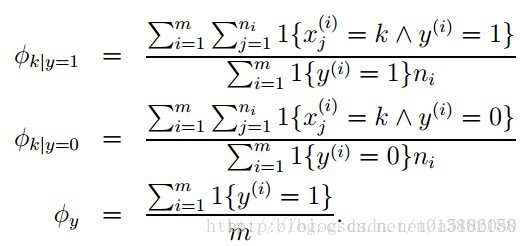
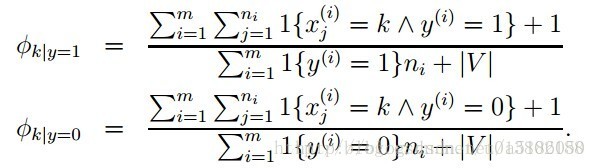
总结
笔者在几次实战后,发现绝大部分文本分类运用该模型效果良好。
接下来我会举例实战,不懂的或者需要源代码的可以联系我。
如果您看到这篇文章有收获或者有不同的意见,欢迎点赞或者评论。
python群:190341254
丁。














 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









