










一、主流模型推理部署框架
ONNX Runtime
-
介绍:由微软推出,用于优化和加速机器学习推理和训练,适用于ONNX模型,是一个跨平台推理和训练机器学习加速器。
-
特点:高性能推理引擎,支持多操作系统(Windows、Linux、Mac、Android、iOS等),可利用硬件(CUDA、TensorRT、DirectML、OpenVINO等)增加性能,支持PyTorch、TensorFlow等深度学习框架的模型。
-
优缺点:优点是推理速度快,支持多平台和硬件加速;缺点是相对其他框架,可能在一些特定领域的优化上稍逊一筹。
-
应用场景:适用于需要高性能推理的机器学习应用,如图像分类、语音识别等。
NCNN
-
介绍:由腾讯开发,专为移动设备和嵌入式设备优化的轻量级高性能深度学习框架。
-
特点:轻量级、高性能,支持多种操作系统和硬件平台(Android、iOS、Linux、Windows等),提供硬件加速支持(OpenMP、Vulkan等),灵活的模型转换工具可将主流深度学习框架的模型转换为ncnn格式。
-
优缺点:优点是内存占用低,推理速度快,支持多平台和硬件加速;缺点是可能在一些复杂模型的支持上有所欠缺。
-
应用场景:适用于移动应用、嵌入式设备和边缘计算等场景。
OpenVINO
-
介绍:由英特尔开发,旨在优化和加速在各种英特尔架构(CPU、GPU、FPGA等)上的深度学习推理。
-
特点:支持多种深度学习框架(TensorFlow、PyTorch等),提供模型优化和加速工具,支持Windows、Linux等操作系统。
-
优缺点:优点是针对英特尔硬件进行了深度优化,推理速度快;缺点是对其他硬件平台的支持可能有限。
-
应用场景:适用于英特尔硬件平台上的深度学习推理应用,如计算机视觉、大型语言模型等。
TensorRT
-
介绍:由NVIDIA开发,专为深度学习推理优化的高性能框架。
-
特点:支持GPU加速,提供低延迟和高吞吐量的推理性能,支持多种深度学习框架(TensorFlow、PyTorch等)的模型。
-
优缺点:优点是推理速度快,支持GPU加速;缺点是对非NVIDIA硬件平台的支持有限。
-
应用场景:适用于需要高性能推理的深度学习应用,如自动驾驶、视频分析等。
其他框架简介
-
MediaPipe:由Google开发,用于构建多媒体处理管道,支持实时音频和视频分析。
-
TensorFlow自己提供的部署服务:TensorFlow Serving、TensorFlow Lite
-
pytorch自己提供的部署服务:libtorch
-
MindSpore:华为开发的深度学习框架,支持移动、边缘和云端部署。
-
OpenCV DNN Module:OpenCV中的深度学习模块,支持多种深度学习框架的模型,并提供简单的推理接口。
-
MNN:阿里巴巴开发的轻量级深度学习框架,专为移动和嵌入式设备设计。
-
RKNN:瑞芯微开发的深度学习推理框架,支持在RK系列芯片上高效运行。
-
TVM:一个开源的深度学习编译器栈,旨在提高深度学习模型的执行效率和可移植性。
-
TNN:腾讯开发的轻量级深度学习推理框架,支持多平台和硬件加速。
-
MACE:小米开发的移动AI计算引擎,支持在移动设备上进行高效的深度学习推理。
对比与总结
-
性能:TensorRT、ONNX Runtime和OpenVINO在性能上表现突出,特别是在针对特定硬件平台进行优化时。
-
跨平台性:ONNX Runtime、NCNN和TensorFlow Lite等框架在跨平台支持上更具优势。
-
易用性:MediaPipe、TensorFlow Lite等框架提供了易于使用的API和工具,方便开发者快速上手。
-
应用场景:不同框架适用于不同的应用场景,如TensorRT适用于需要高性能推理的自动驾驶和视频分析应用,而NCNN则更适合移动应用和嵌入式设备。
应用平台:
| 模型推理部署框架 | 应用平台 |
|---|---|
| NCNN | 移动端 |
| OpenVINO | CPU,GPU,嵌入式平台都可以使用,尤其是在CPU上首选OPenVINO。DepthAI嵌入式空间AI平台。 |
| TensorRT | 只能用在NIVDIA的GPU上的推理框架。NIVDIA的Jetson平台。 |
| Mediapipe | 服务端,移动端,嵌入式平台,TPU。 |
研发单位:
- 腾讯公司开发的移动端平台部署工具——NCNN;
- Intel公司针对自家设备开开发的部署工具——OpenVINO;
- NVIDIA公司针对自家GPU开发的部署工具——TensorRT;
- Google针对自家硬件设备和深度学习框架开发的部署工具——Mediapipe;
- 由微软、亚马逊 、Facebook 和 IBM 等公司共同开发的开放神经网络交换格式——ONNX;
如何选择:
- ONNXRuntime 是可以运行在多平台 (Windows,Linux,Mac,Android,iOS) 上的一款推理框架,它接受 ONNX 格式的模型输入,支持 GPU 和 CPU 的推理。唯一不足就是 ONNX 节点粒度较细,推理速度有时候比其他推理框架如 TensorRT 较低。
- NCNN是针对手机端的部署。优势是开源较早,有非常稳定的社区,开源影响力也较高。
- OpenVINO 是 Intel 家出的针对 Intel 出品的 CPU 和 GPU 友好的一款推理框架,同时它也是对接不同训练框架如 TensorFlow,Pytorch,Caffe 等。不足之处可能是只支持 Intel 家的硬件产品。
- TensorRT 针对 NVIDIA 系列显卡具有其他框架都不具备的优势,如果运行在 NVIDIA 显卡上, TensorRT 一般是所有框架中推理最快的。一般的主流的训练框架如TensorFlow 和 Pytorch 都能转换成 TensorRT 可运行的模型。当然了,TensorRT 的限制就是只能运行在 NVIDIA 显卡上,同时不开源 kernel。
- MediaPipe 不支持除了tensorflow之外的其他深度学习框架。MediaPipe 的主要用例是使用推理模型和其他可重用组件对应用机器学习管道进行快速原型设计。MediaPipe 还有助于将机器学习技术部署到各种不同硬件平台上的演示和应用程序中,为移动、桌面/云、web和物联网设备构建世界级ML解决方案和应用程序。
二、ONNX
1.1 什么是 ONNX
开放神经网络交换 ONNX(Open Neural Network Exchange)是一套表示深度神经网络模型的开放格式,由微软和 Facebook 于 2017 推出,然后迅速得到了各大厂商和框架的支持。通过短短几年的发展,已经成为表示深度学习模型的实际标准,并且通过 ONNX-ML,可以支持传统非神经网络机器学习模型,大有一统整个 AI 模型交换标准。
1.2 ONNX 的核心思想
ONNX 定义了一组与环境和平台无关的标准格式,为 AI 模型的互操作性提供了基础,使 AI 模型可以在不同框架和环境下交互使用。硬件和软件厂商可以基于 ONNX 标准优化模型性能,让所有兼容 ONNX 标准的框架受益。目前,ONNX 主要关注在模型预测方面(inferring),使用不同框架训练的模型,转化为 ONNX 格式后,可以很容易的部署在兼容 ONNX 的运行环境中。

1.3 ONNX 的存储方式 —— ProtoBuf
ONNX 使用的是 Protobuf 这个序列化数据结构去存储神经网络的权重信息。
Protobuf 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
1.4 ONNX的关键特点
-
跨框架兼容性:ONNX支持多种深度学习框架,如TensorFlow、PyTorch、Caffe2、MXNet、Chainer、Core ML、Scikit-learn等。这意味着开发者可以在一个框架中训练模型,然后将其导出为ONNX格式,并在另一个框架中加载和使用,而无需对模型进行重新训练或修改。
-
可扩展性:ONNX的设计考虑了未来的可扩展性,它允许添加新的操作符(op)和数据类型,以支持新的深度学习模型结构和参数表示。这使得ONNX能够适应不断发展的深度学习领域,并保持其作为标准模型表示格式的领先地位。
-
标准化:ONNX提供了一种标准化的模型表示方法,这有助于消除不同深度学习框架之间的壁垒,促进模型共享和重用。通过采用ONNX格式,开发者可以更容易地与其他人合作,共享和部署他们的模型。
-
优化与推理:虽然ONNX本身不直接执行模型推理,但它为各种推理引擎提供了统一的输入格式。这些推理引擎可以针对特定的硬件和操作系统进行优化,以提高模型推理的速度和效率。ONNX Runtime就是这样一个高性能推理引擎,它支持ONNX模型,并提供了跨平台的执行能力。
1.5 ONNX Runtime
ONNX Runtime是一个用于高性能推理的开源引擎,由微软推出。它支持在多个平台上运行ONNX模型,并提供了一组API来加载和执行这些模型。ONNX Runtime针对不同硬件和操作系统进行了优化,可以充分发挥硬件的性能,提高模型推理的速度和效率。
ONNX Runtime的主要特点包括:
- 高性能推理:通过针对不同硬件和操作系统进行优化,ONNX Runtime提供了高性能的模型推理能力。
- 跨平台支持:ONNX Runtime可以在不同的操作系统上运行,包括Windows、Linux、Mac、Android、iOS等。
- 硬件加速:ONNX Runtime可以利用多种硬件加速技术,如CUDA、TensorRT、DirectML、OpenVINO等,来进一步提高推理性能。
- 易用性:ONNX Runtime提供了简洁易用的API,使得开发者可以方便地将ONNX模型加载到应用中,并进行推理。
1.6 ONNX 与 ONNX Runtime区别总结
- 功能定位:ONNX是一个模型表示格式,用于模型的互操作性和转换;而ONNX Runtime是一个高性能推理引擎,用于模型的优化和运行。
- 应用场景:ONNX主要用于模型的跨框架转换和共享;ONNX Runtime则用于模型的推理加速和部署。
- 技术特点:ONNX注重模型的统一表示和可扩展性;ONNX Runtime则注重高性能、跨平台和硬件优化。
1.7 ONNX的应用场景
-
模型转换与部署:开发者可以将在一个深度学习框架中训练的模型转换为ONNX格式,然后将其部署到另一个框架或平台上。这有助于简化模型部署流程,降低部署成本。
-
模型优化:通过采用ONNX格式,开发者可以利用各种优化工具和技术来改进模型的性能和准确性。这些优化可能包括量化、剪枝、融合等操作,旨在减少模型的计算复杂性和存储需求。
-
跨平台推理:ONNX支持跨平台推理,使得模型可以在不同的操作系统和硬件上运行。这有助于确保模型的兼容性和可移植性,使得开发者可以在不同的环境中部署和使用他们的模型。
-
模型共享与重用:通过采用ONNX格式,开发者可以更容易地与其他人共享和重用他们的模型。这有助于促进深度学习领域的知识共享和合作,推动技术的快速发展。
总之,ONNX作为一个开放的深度学习模型表示格式,在深度学习模型的互操作性和标准化方面发挥着重要作用。它有助于消除不同深度学习框架之间的壁垒,促进模型共享和重用,为深度学习的发展提供了有力的支持。
三、NCNN
ncnn 是一个为移动端优化的高性能神经网络前向计算框架。它最初由腾讯优图实验室开发,并广泛应用于腾讯的多种业务和产品中。ncnn 专为移动端设备设计,注重高性能和低内存占用,同时提供了易于使用的 API 和跨平台支持。
2.1 ncnn 的关键特点
-
高性能:ncnn 针对移动端 CPU、GPU 和 NPU 进行了深度优化,能够充分利用硬件资源,提供高效的神经网络前向计算能力。
-
低内存占用:ncnn 采用了内存池管理、零拷贝等技术,有效降低了内存占用和内存分配/释放的开销。
-
跨平台支持:ncnn 支持多种操作系统,包括 Android、iOS、Linux 和 Windows,能够在不同的平台上无缝运行。
-
易于集成:ncnn 提供了简洁易用的 API,方便开发者将其集成到自己的项目中。同时,ncnn 还提供了丰富的示例代码和文档,帮助开发者快速上手。
-
模型兼容性:ncnn 支持从多种深度学习框架(如 TensorFlow、PyTorch、Caffe、ONNX 等)导入模型,并提供了模型转换工具,方便开发者将已有的模型转换为 ncnn 格式。
-
量化支持:ncnn 支持模型量化,通过降低模型精度来减少计算量和内存占用,同时保持较高的模型性能。
2.2 ncnn 的应用场景
-
移动端应用:ncnn 特别适合用于移动端应用中的图像识别、语音识别、自然语言处理等任务。它能够在有限的硬件资源下提供高效的神经网络前向计算能力。
-
嵌入式系统:ncnn 也可以在嵌入式系统中运行,如智能家居设备、安防监控设备等。它能够在低功耗的硬件上实现高效的神经网络推理。
-
边缘计算:ncnn 可以用于边缘计算场景,将深度学习模型部署到边缘设备上,实现实时数据处理和分析。
-
游戏开发:ncnn 可以用于游戏开发中的图像处理和人工智能任务,如角色识别、物体检测等。

总之,ncnn 是一个为移动端优化的高性能神经网络前向计算框架,具有高性能、低内存占用、跨平台支持等特点。它广泛应用于移动端应用、嵌入式系统、边缘计算和游戏开发等领域,为开发者提供了高效、易用的神经网络推理能力。
三、OpenVINO
OpenVINO是由英特尔(Intel)开发的专门用于优化和部署人工智能推理的半开源工具包,主要用于对深度推理做优化,特别侧重于计算机视觉任务。

以下是对OpenVINO的详细介绍:
3.1 、主要功能
- OpenVINO能够优化和加速在各种英特尔架构(如CPU、GPU、FPGA和VPU等)上的深度学习推理。
- 它支持从流行框架(如TensorFlow、PyTorch、Caffe、MXNet、Kaldi、ONNX等)导入模型,并将这些模型转换为适合在英特尔硬件上部署的中间表示(Intermediate Representation,IR)格式。
- OpenVINO提供了丰富的API和工具,包括模型优化器、训练后优化工具、基准测试工具等,用于模型的转换、优化、部署和性能评估。
3.2、优势特点
- 显著减少推理时间:通过优化模型和执行推理,OpenVINO能够显著减少深度学习模型的推理时间,提高实时性能。
- 跨平台支持:OpenVINO支持Windows、Linux、macOS和Raspbian OS等多种操作系统,以及英特尔的各种硬件平台。
- 易用性:OpenVINO提供了简洁易用的API和丰富的文档、示例代码,降低了开发者的学习成本和使用难度。
- 高性能:通过针对英特尔硬件的深度优化,OpenVINO能够充分发挥硬件的性能,提供高效的推理能力。
3.3、应用场景
- 计算机视觉:OpenVINO在计算机视觉领域有着广泛的应用,如图像分类、目标检测、人脸识别、图像分割等。
- 自然语言处理:除了计算机视觉任务外,OpenVINO还支持自然语言处理模型的优化和部署,如文本分类、情感分析、机器翻译等。
- 边缘计算:OpenVINO能够优化和部署深度学习模型到边缘设备上,实现实时数据处理和分析。
- 物联网(IoT):在物联网领域,OpenVINO可以用于智能家居、智能安防、智能交通等场景,提供高效的人工智能推理能力。
3.4、安装与部署
- 安装:用户可以从OpenVINO的官方网站下载安装程序,并按照屏幕上的说明进行操作。安装完成后,需要配置环境变量以使用OpenVINO的工具和API。
- 部署:部署OpenVINO模型通常包括以下几个步骤:加载和转换模型、编译模型、运行推理等。OpenVINO提供了丰富的示例代码和文档来帮助用户完成这些步骤。
3.5、版本更新与升级
- OpenVINO不断更新和升级,以支持新的深度学习模型、框架和硬件平台。用户可以从官方网站下载最新版本的OpenVINO,并参考官方文档进行升级和迁移。
总之,OpenVINO是一个功能强大、易用且高效的深度学习推理优化工具包,适用于各种英特尔架构的硬件平台。它能够帮助开发者快速地将深度学习模型部署到实际应用中,并充分发挥硬件的性能。
四、TensorRT
TensorRT是NVIDIA发布的一款针对其GPU的深度学习推理优化框架,旨在提高模型部署时的运行速度。

以下是对TensorRT的详细介绍:
4.1、主要功能
TensorRT能够将训练好的深度学习模型进行转换并优化,以支持高效的推理。它支持多种深度学习框架,如Caffe、TensorFlow、PyTorch、ONNX等,能够将这些框架的模型转换为TensorRT可执行的引擎。通过TensorRT的优化,深度学习模型可以在NVIDIA的GPU上实现更快的推理速度,同时降低延迟和功耗。
4.2、关键特性
- 高性能推理:TensorRT针对NVIDIA GPU进行了深度优化,能够充分利用GPU的计算能力,提供高性能的推理服务。
- 跨框架支持:TensorRT支持多种深度学习框架,方便开发者将不同框架训练的模型转换为TensorRT引擎进行推理。
- 自动优化:TensorRT能够针对运行时性能自动优化训练过的神经网络,包括层融合、内核自动调优等技术,进一步提高推理速度。
- 量化支持:TensorRT支持INT8量化,通过降低模型精度来减少计算量和内存占用,同时保持较高的模型性能。
- 易于集成:TensorRT提供了丰富的API和工具,方便开发者将其集成到自己的项目中,并支持多种操作系统和硬件平台。
4.3、应用场景
TensorRT在深度学习推理任务中有广泛的应用场景,包括但不限于:
- 边缘计算和嵌入式系统:TensorRT可以在边缘设备和嵌入式系统上实现高效的深度学习推理,提供快速、低功耗的推理能力。
- 计算机视觉:TensorRT可用于图像分类、目标检测、人脸识别、图像分割等计算机视觉任务,加速推理速度,提高实时性能。
- 语音和语音识别:TensorRT可用于语音情感分析、语音识别模型的推理加速等任务,提高语音处理任务的推理效率和实时性能。
- 自然语言处理:TensorRT也可以应用于自然语言处理(NLP)任务,如文本分类、情感分析、机器翻译等,通过优化和加速提高NLP任务的推理速度。
- 智能视频分析:TensorRT可用于视频分析和智能视频监控应用,如对象跟踪、行为识别、实时视频分割等任务,实现实时的视频分析和智能决策。
4.4、安装与配置
安装TensorRT需要匹配正确的CUDA和cuDNN版本。用户可以从NVIDIA的官方网站下载TensorRT安装包,并按照屏幕上的说明进行操作。安装完成后,需要配置环境变量以使用TensorRT的工具和API。此外,TensorRT还提供了Python API,方便开发者使用Python编写脚本来构建、优化和执行深度学习模型。
4.5、版本更新与升级
TensorRT不断更新和升级,以支持新的深度学习模型、框架和硬件平台。用户可以从NVIDIA的官方网站下载最新版本的TensorRT,并参考官方文档进行升级和迁移。在升级过程中,用户需要注意版本兼容性,确保新版本的TensorRT与现有的CUDA、cuDNN和深度学习框架兼容。
综上所述,TensorRT是一款针对NVIDIA GPU的深度学习推理优化框架,具有高性能、跨框架支持、自动优化、量化支持和易于集成等关键特性。它在边缘计算、计算机视觉、语音和语音识别、自然语言处理以及智能视频分析等领域有广泛的应用场景。通过安装与配置以及版本更新与升级等操作,用户可以充分利用TensorRT的优势来提高深度学习模型的推理速度和性能。
五、MediaPipe
MediaPipe是由Google Research开发的一款开源框架,旨在为实时和流媒体提供跨平台的可定制机器学习解决方案。以下是对MediaPipe的详细介绍:
5.1、核心特性
- 跨平台支持:MediaPipe支持多种平台,包括Android、iOS、Web、桌面以及边缘设备等,这使得开发者可以轻松地将模型部署到不同的平台上。
- 高效的实时处理:MediaPipe具有高度优化的性能,能够在资源受限的设备上进行实时处理,特别适合于移动设备和嵌入式系统。
- 模块化设计:MediaPipe使用图表(graph)来组织和连接不同的处理模块,这种设计使得开发者可以灵活地组合和复用不同的处理组件。
- 丰富的预构建解决方案:MediaPipe提供了多种预构建的解决方案,如手部追踪、面部检测、姿态估计、自拍分割等,开发者可以直接使用这些解决方案来快速构建应用。
5.2、应用场景
- 增强现实(AR):借助MediaPipe的手势识别功能,可以实现手势控制游戏或应用,提升用户体验。
- 健康医疗:通过MediaPipe的姿态估计功能,可以远程进行动作康复指导,精准追踪患者的运动状态。
- 教育领域:利用MediaPipe的面部表情分析功能,可以辅助情感教学,提高互动性。
- 零售行业:通过MediaPipe的对象识别功能,可以实现自动化的商品识别与计数,提升库存管理效率。
- 无障碍技术:支持视觉障碍者通过手势操作电子设备,提高生活便利性。

5.3、技术架构
MediaPipe的技术架构基于图形化的处理方式,将应用的机器学习管道构建为模块化组件的图形。这些组件可以通过直观的动图预览进行配置和连接,从而实现快速原型设计。MediaPipe还支持多种后端驱动,如TensorFlow等,以支持复杂的机器学习模型应用于视频流。
5.4、安装与配置
安装MediaPipe需要确保开发环境满足一定的要求,包括操作系统、开发工具以及依赖库等。具体安装步骤通常包括克隆MediaPipe的GitHub仓库、安装所需的依赖库、设置环境变量以及使用Bazel构建MediaPipe项目等。此外,MediaPipe还提供了Python API,方便开发者使用Python编写脚本来构建和部署机器学习模型。
5.5、社区与支持
MediaPipe拥有一个活跃的开发者社区,社区成员可以分享经验、解决问题并推动项目的发展。此外,Google还为MediaPipe提供了强大的技术支持和文档资源,帮助开发者更好地理解和使用MediaPipe。
综上所述,MediaPipe是一款功能强大、易于使用和扩展的机器学习框架,适用于多种应用场景和平台。通过利用MediaPipe的预构建解决方案和模块化设计,开发者可以快速构建和部署高效的机器学习模型。
六、YOLOv8的5种不同部署方式推理速度对比:Pytorch、ONNX、OpenVINO-FP32/int8、TensorRT
本文介绍了如何将YOLOv8模型转为其他不同的部署文件格式,并且比较了YOLOv8n.pt的5种不同部署方式:包括原生yolov8n.pt的Pytorch格式、ONNX、OpenVINO-FP32、OpenVINO-int8、TensorRT在CPU和GPU下的推理速度对比,供小伙伴们参考。小伙伴们自己训练的v8模型可以用同样的方式进行转换测试。
【注:不同硬件设备可能测试会略有差异,但趋势应该没有问题,本文结果仅供参考】
6.1 模型导出方法
6.1.1 模型导出代码
yolov8提供了很简洁的模型转换方式,代码如下所示:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
# Export the model
model.export(format="onnx")
在上面代码中可以使用 format 参数导出为任何格式,即 format='onnx' 或 format='engine' .我们也可以直接在导出的模型上进行预测或验证 yolo predict model=yolov8n.onnx ,即 导出完成后,将显示模型的使用示例。
6.1.2 可导出的模型格式
可用的 YOLOv8 导出格式如下表所示:
| Format | format Argument | Model | Metadata | Arguments |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
其中format列表示,导出时format设置的参数名称。Arguments表示导出对应格式时可以额外设置的参数。比如,导出int8格式的openvino模型,代码如下:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
# Export the model
model.export(format="openvino",int8=True)
6.1.3 导出模型参数说明
下表详细介绍了可用于将 YOLO 模型导出为不同格式的配置和选项。这些设置对于优化导出模型的性能、大小以及跨各种平台和环境的兼容性至关重要。正确的配置可确保模型已准备好以最佳效率部署在预期应用程序中。
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
format | str | 'torchscript' | 导出模型的目标格式,如 'onnx' 、 'torchscript' 、 'tensorflow' 或其他格式,用于定义与各种部署环境的兼容性。 |
imgsz | int 或 tuple | 640 | 模型输入所需的图像大小。可以是方形图像的整数,也可以是特定尺寸的元组 (height, width) 。 |
keras | bool | False | 支持将 TensorFlow SavedModel 导出为 Keras 格式,从而提供与 TensorFlow 服务和 API 的兼容性。 |
optimize | bool | False | 在导出到 TorchScript 时对移动设备应用优化,从而可能减小模型大小并提高性能。 |
half | bool | False | 启用 FP16(半精度)量化,减小模型大小,并可能加快在支持的硬件上的推理速度。 |
int8 | bool | False | 激活 INT8 量化,进一步压缩模型并加快推理速度,同时将精度损失降至最低,主要针对边缘设备。 |
dynamic | bool | False | 允许 ONNX 和 TensorRT 导出的动态输入大小,从而增强处理不同图像尺寸的灵活性。 |
simplify | bool | False | 使用 onnxslim 简化 ONNX 导出的模型图,从而可能提高性能和兼容性。 |
opset | int | None | 指定 ONNX 操作集版本,以便与不同的 ONNX 分析程序和运行时兼容。如果未设置,则使用支持的最新版本。 |
workspace | float | 4.0 | 设置最大工作空间大小(以 GiB 为单位),用于 TensorRT 优化,平衡内存使用量和性能。 |
nms | bool | False | 将非最大抑制 (NMS) 添加到 CoreML 导出中,这对于准确高效的检测后处理至关重要。 |
batch | int | 1 | 指定导出模型批量推理大小或导出的模型将在模式下 predict 并发处理的最大图像数。 |
调整这些参数可以自定义导出过程以满足特定要求,例如部署环境、硬件约束和性能目标。选择适当的格式和设置对于在模型大小、速度和精度之间实现最佳平衡至关重要。
6.2 模型推理速度对比
本文将yolov8n.pt模型分别导出ONNX、OpenVINO-FP32、OpenVINO-int8、TensorRT这4种格式,加上原生pytorch格式的yolov8n.pt模型,共5种格式模型。分别在CPU与GPU上进行了推理测试,测试结果如下表:
| model_name | device | FPS |
|---|---|---|
| yolov8n.pt | GPU | 77 |
| yolov8n.onnx | GPU | 81 |
| yolov8n_openvino_model | GPU | 38 |
| yolov8n_int8_openvino_model | GPU | 60 |
| yolov8n.engine | GPU | 104 |
| yolov8n.pt | cpu | 9 |
| yolov8n.onnx | cpu | 22 |
| yolov8n_openvino_model | cpu | 34 |
| yolov8n_int8_openvino_model | cpu | 51 |
| yolov8n.engine | cpu | 0 |
为了更直观的进行推理结果展示,我们直接将表格结果显示为图标形式,绘图代码如下:
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
# 示例数据
categories = ['Pytorch', 'ONNX', 'OpenVINO-FP32','OpenVINO-int8', 'TensorRT']
data_1 = [9, 22, 34, 51, 0]
data_2 = [77, 81, 38, 60,104]
# data_3 = [14, 30, 22, 36]
# 设置柱子宽度和间距
bar_width = 0.25
index = np.arange(len(categories))
# 绘制第一个数据集的条形图
bars1 = plt.bar(index, data_1, bar_width, label='CPU', color='b')
# 绘制第二个数据集的条形图,注意x坐标要偏移以避免重叠
bars2 = plt.bar(index + bar_width, data_2, bar_width, label='GPU', color='r')
# 绘制第三个数据集的条形图,继续偏移
# bars3 = plt.bar(index + 2*bar_width, data_3, bar_width, label='Dataset 3', color='g')
# 在每个柱子上方显示数值
def add_value_labels(ax, bars):
for bar in bars:
height = bar.get_height()
ax.annotate('{}'.format(height),
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
add_value_labels(plt.gca(), bars1)
add_value_labels(plt.gca(), bars2)
# 设置图表标题和轴标签
plt.title('Comparison of model inference speed')
plt.xlabel('Model Name', fontsize=14)
plt.ylabel('FPS', fontsize=14)
plt.xticks(index + bar_width, categories)
# 创建图例
plt.legend()
# 显示网格
plt.grid(axis='y', linestyle='--', linewidth=0.7, alpha=0.7)
# 显示图表
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
# plt.show()
plt.savefig('chart.jpg')
最终绘制结果如下所示,可以更好的对比不同模型的检测速度。
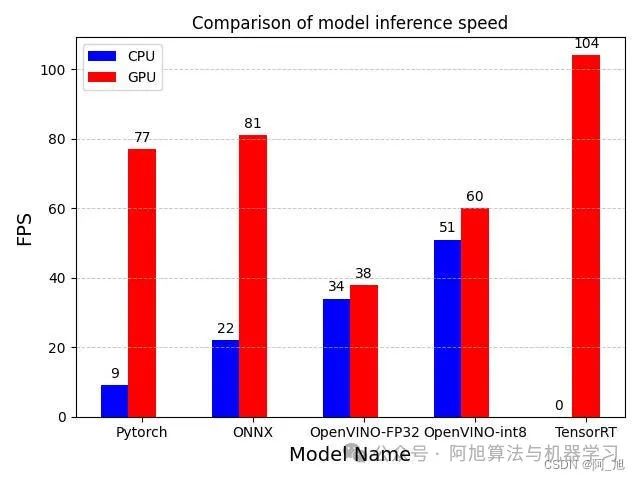
从上述结果可以看出:在CPU设备上:
-
yolov8n.pt模型的性能最低,每秒处理9帧。
-
yolov8n.onnx模型稍微优于yolov8n.pt,每秒处理22帧。
-
yolov8n_openvino_model模型的性能最佳,每秒处理34帧。
-
yolov8n_int8_openvino_model模型略高于yolov8n_openvino_model,每秒处理51帧
-
yolov8n.engine模型只能在GPU运行,无法测试。
在GPU设备上:
-
yolov8n.pt模型的性能比CPU处理快很多,每秒处理77帧。
-
yolov8n.onnx模型稍微优于yolov8n.pt,每秒处理81帧。
-
yolov8n_openvino_model模型的性能最低,每秒处理38帧。
-
yolov8n_int8_openvino_model模型略高于yolov8n_openvino_model,每秒处理60帧。
-
yolov8n.engine模型的性能最佳,每秒处理104帧。
总体上,对于相同的模型和设备,使用GPU比使用CPU获得更高的处理帧数。此外,yolov8n.engine模型在GPU设备上表现最出色,达到了100帧/s;yolov8n.pt与yolov8n.onnx其次,约为80帧/s。在CPU上OpenVINO_int8表现出的性能最佳, 可以达到60帧/s,基本可以满足实际的检测帧率需求。
需要注意的是,FPS仅是模型性能的一个指标,实际应用中还需要综合考虑其他因素,如模型的准确性、内存占用等。
参考
















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









