







论文地址:https://arxiv.org/pdf/2108.07993
代码地址:https://github.com/HKUST-Aerial-Robotics/EPSILON
1. 摘要
论文提出了一种名为EPSILON的高效自动驾驶规划系统,用于在高度交互的环境中操作车辆。EPSILON是一个具备交互感知能力的高效规划系统,已经在仿真和真实世界密集城市交通中进行了广泛验证。系统采用分层结构,包括交互式行为规划层和基于优化的运动规划层。行为规划采用部分可观测马尔可夫决策过程(POMDP)进行建模,但比直接使用POMDP更高效,其关键在于对动作空间和观测空间的引导分支,将原问题分解成少量闭环策略评估问题。此外,提出了一种具有安全机制的新型驾驶员模型,以克服先验知识不完美带来的风险。运动规划方面,提出了时空语义走廊(SSC)以统一建模复杂驾驶环境的约束条件,并在此基础上优化出安全、平滑的轨迹,遵循行为规划层的决策。实验证明,EPSILON在密集交通流中能实现接近人类的自然驾驶行为,既平滑又安全,且相较于现有方法不过于保守。
2. 方法
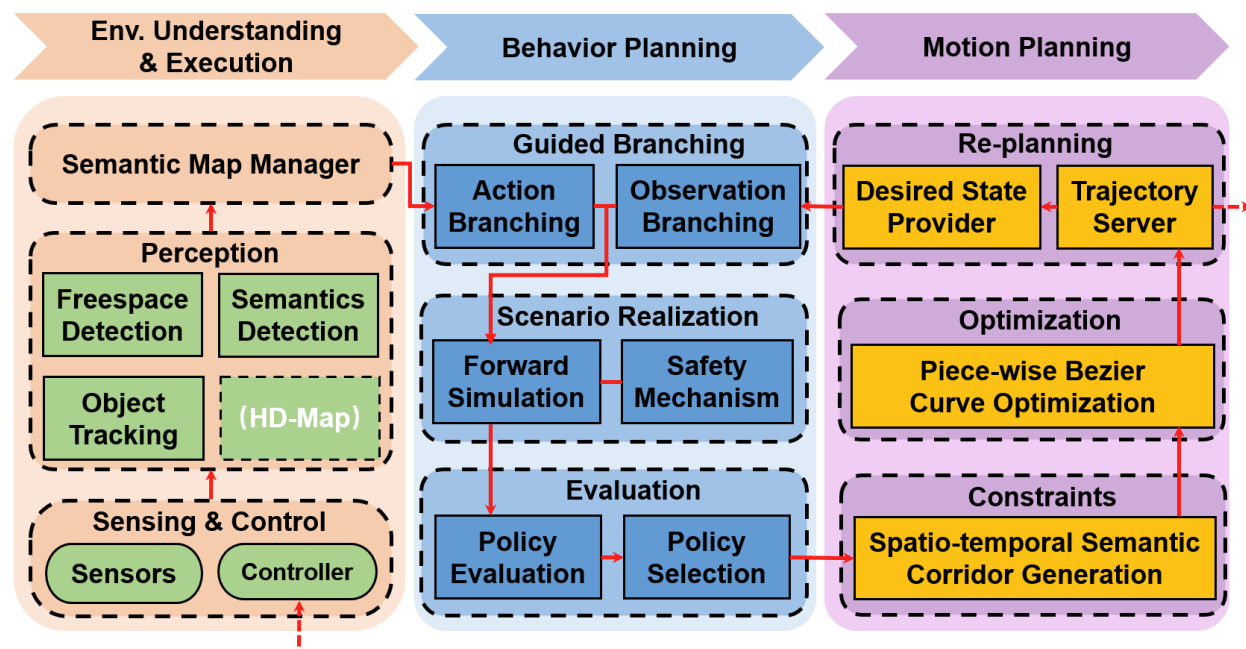
EPSILON规划系统的整体结构如图所示,整个规划系统包括环境理解模块、行为规划和运动规划三个模块。感知模块包括了自由空间检测、语义检测(如车道线检测、交通灯检测等)以及目标检测与跟踪。感知模块的输出被同步传递给一个语义地图管理器,该模块负责组织各种数据结构,并向规划模块提供查询接口,语义地图以20Hz频率更新。
行为规划层主要进行上层语义级规划,EPSILON不需要一个单独的轨迹预测模块,轨迹预测功能已融合进了行为规划器内部。行为规划器主要包括三个过程:引导式分支(Guided Branching):根据预定义的策略扩展自车的动作序列,同时推理其他交通参与者的可能意图。场景实现(Scenario Realization):将一个具体的场景通过多智能体闭环仿真逐步实现。策略评估(Policy Evaluation):评估不同场景下的各个策略,选择最优决策,行为规划层的工作频率为20Hz。
运动规划层对行为规划层的输出轨迹进行优化。将静态障碍物、动态障碍物以及环境语义元素施加的约束统一建模为一个时空语义通道(Spatio-Temporal Semantic Corridor, SSC),以行为层提供的初步轨迹为参考初值。然后,采用分段贝塞尔曲线(piecewise Bézier curves)对轨迹进行优化,运动规划层的工作频率为20Hz。
2.1 高效行为规划
人类驾驶员在决策时,并不会在心中建立一个细粒度的栅格地图。相反,人类通常根据通用驾驶知识,只会考虑少数几个长期的语义级别动作(semantic-level actions),比如:保持当前车道(lane keeping)、变道(lane change)、让行(yield)等等,这种决策方式使得人类的决策非常高效。此外,在POMDP框架下,另一个导致效率低下的问题是:其他智能体的意图(intentions)是不可观测的,需要在观测空间(observation space)上进行采样和分支。但问题在于,随着周围交通参与者数量的增加,意图组合数量呈指数级增长,计算代价极高。
2.2.1 自车行为策略树(DCP-Tree:Domain-Specific Closed-loop Policy Tree)
为了解决动作空间过大的问题,引入了语义级动作(Semantic-Level Actions)进行引导式规划。这些动作具有如下特点:直接对应人类可感知的驾驶操作(如加速、变道);每个语义动作可以封装为一个小型闭环控制器(predefined controller);可以在执行时逐步生成具体的原始控制量(如方向盘转角、加速度)。在引导式规划中,仅自车的语义动作是可控的,其他车辆的动作由驾驶员模型推断。为了进一步提高效率,论文设计了领域特定的闭环策略树DCP-Tree策略如下:
-
每次规划周期,从当前正在执行的动作(ongoing action)出发;
-
允许在规划周期内发生最多一次动作切换(one action change);
-
每个动作序列表示一个完整的策略;
-
整个动作树的规模随树深度线性增长,而不是指数增长。
本部分内容开源代码如下:纵向语义包括三个:加速、减速和匀速。横向语义包括三个:车道保持、左换道和右换道。动作序列总共有5层,每层1s,总规划时长5s。横向允许一次动作改变,如从保持车道切到左车道或右车道,如果换了车道,后面动作就一直保持新车道,不再切换。所以其动作序列总共有九种。每一个分支整个时间序列保持相同的纵向语义,一共有9*3=27条轨迹。如果初始意图是正在左换道,不允许直接从左换道到右换道,轨迹一共就有5*3=15条轨迹。
- 保持车道 + 保持车道 + 保持车道 + 保持车道 + 保持车道
- 换到左车道 + 保持左车道 + 保持左车道 + 保持左车道 + 保持左车道
- 换到右车道 + 保持右车道 + 保持右车道 + 保持右车道 + 保持右车道
- 保持车道 + 换到左车道 + 保持左车道 + 保持左车道 + 保持左车道
- 保持车道 + 换到右车道 + 保持右车道 + 保持右车道 + 保持右车道
- 保持车道 + 保持车道 + 换到左车道 + 保持左车道 + 保持左车道
- 保持车道 + 保持车道 + 换到右车道 + 保持右车道 + 保持右车道
- 保持车道 + 保持车道 + 保持车道 + 换到左车道 + 保持左车道
- 保持车道 + 保持车道 + 保持车道 + 换到右车道 + 保持右车道
enum class DcpLonAction {
kMaintain = 0,
kAccelerate,
kDecelerate,
MAX_COUNT = 3
};
enum class DcpLatAction {
kLaneKeeping = 0,
kLaneChangeLeft,
kLaneChangeRight,
MAX_COUNT = 3
};
ErrorType DcpTree::GenerateActionScript() {
action_script_.clear();
std::vector<DcpAction> ongoing_action_seq;
for (int lon = 0; lon < static_cast<int>(DcpLonAction::MAX_COUNT); lon++) {
ongoing_action_seq.clear();
ongoing_action_seq.push_back(
DcpAction(DcpLonAction(lon), ongoing_action_.lat, ongoing_action_.t));
for (int h = 1; h < tree_height_; ++h) {
for (int lat = 0; lat < static_cast<int>(DcpLatAction::MAX_COUNT);
lat++) {
if (lat != static_cast<int>(ong 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









