







标题:《End-to-End Object Detection with Transformers》
Transformer的端到端目标检测
1.摘要:
我们提出了一种将目标检测视为直接集合预测问题的新方法,我们的方法简化了监测管道,有效地消除了对许多手工设计组件的需求,例如非极大值抑制或者锚生成,这些组件有效地编码了我们对任务的先验知识。新框架的主要成分,称为检测转换器或 DETR,是基于集合的全局损失,它通过二部匹配强制唯一的预测,以及变压器编码器-解码器架构。给定一组固定的学习对象查询,DETR 推理对象和全局图像上下文的关系,以并行直接输出最终的预测集。与许多其他现代检测器不同,新模型在概念上很简单,不需要专门的库。DETR在具有挑战性的COCO对象检测数据集上展示了与成熟和高度优化的Faster RCNN基线相当的准确性和运行时性能。此外,DETR可以很容易地推广,以统一的方式产生全景分割。我们表明它明显优于竞争基线。
2.模型结构:
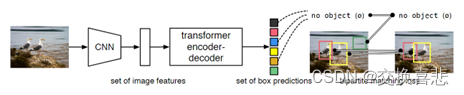

3.方法
- 首先通过CNN抽取图片特征,然后拉成一个向量,将向量送入编码器,进一步学习全局特征,帮助后面做检测,再用transformer decoder去生成很多的预测框,然后把预测的框和ground truth的框做一个匹配,最后在匹配的框里面去算目标检测的loss。
- 预测还是推理都没有anchor生成这一步。
- 将DETR通过二分图匹配算得目标函数。
主要就讲两个东西,基于集合的目标函数,和DETR结构。
问题是怎么知道那个预测框对应哪个ground truth框呢,因为N设定为100,会出来100个预测框,但是一张图片所含的物体种类可能只有十几个,作者把这种对应转化成了一个二分图匹配的问题。
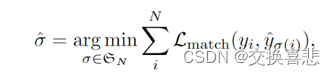
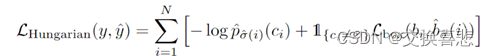
Bounding box的损失,之前用的L1,loss太大不利于优化,所以作者不仅用了L1 loss,还用了generalized iou loss,是一个和框大小无关的目标函数。
先算了一个最优匹配,然后再算loss
4.结论
我们提出了 DETR,这是一种基于变换器和二分匹配损失的目标检测系统的新设计,用于直接集预测。该方法在具有挑战性的 COCO 数据集上实现了与优化的 Faster R-CNN 基线相当的结果。DETR 易于实现,并且具有灵活的架构,可以轻松扩展到全景分割,并具有具有竞争力的结果。此外,它在大型对象上实现了比 Faster R-CNN 更好的性能,这可能是由于处理自注意力执行的全局信息。这种检测器的新设计也带来了新的挑战,特别是在小物体的训练、优化和性能方面。当前的检测器需要几年的改进来应对类似的问题,我们希望未来的工作能够成功地解决 DETR 的问题。














 1944
1944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









