







代码:https://github.com/HuKai97/detr-annotations
论文:https://arxiv.org/pdf/2005.12872.pdf
参考视频:DETR 论文精读【论文精读】_哔哩哔哩_bilibili
团队:Meta AI
摘要
DETR 做目标检测任务既不需要proposal,也不需要anchor,直接用Transformer全局预测能力把目标检测看成一个集合预测的问题,不需要用nms作后处理
对于一张图片,固定预测一定数量的物体(原作是100个,在代码中可更改),模型根据这些物体对象与图片中全局上下文的关系直接并行输出预测集, 也就是 Transformer 一次性解码出图片中所有物体的预测结果,这种并行特性使得 DETR 非常高效。
背景
相关工作
目标检测
现在大部分的目标检测都是根据已有的初始预测去做一些猜测
twostage:初始猜测是proposal
singlestage:初始猜测是anchor
后处理:
猜想:1)set based loss 2)recurrent detector
贡献
1)把目标检测做成端到端的框架,删除依赖于人的先验的部分,比如最大值抑制和生成anchor
2)提出新的目标函数,通过二分图匹配的方式强制模型输出独一无二的预测
3)用了Transformer Encoder和Decoder的架构,解码器的时候有另外一个输入:learn object queries,和全局图像信息结合在一起,通过不停做注意力操作让模型直接输出预测框
方法
DETR模型结构
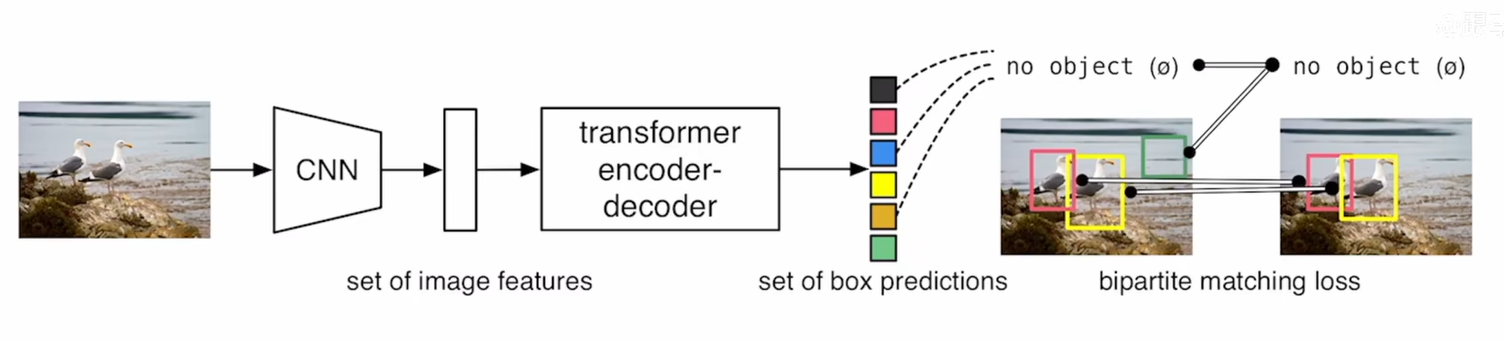
step1:
先用卷积神经网络来抽取特征
step2:
拿到特征之后拉直送到Transformer encoder-decoder里面
step3:
encoder继续学习全局信息(非常有利于去移除冗余的框),为decoder的出预测框进行铺垫
step4:
decoder中进行object query,但是这里的object query有多少个就决定了它后面会有多少个框
但是六层decoder中第一层可以不做自注意力
六个decoder中都加了ffn(trick)
step5:
训练的时候通过二分图匹配的方法去算最后的loss,匹配上ground truth之后才会去算一个分类的loss和bounding box的loss;剩下的框被视作背景类;
推理的时候不用loss,直接用罚值去卡一下置信度
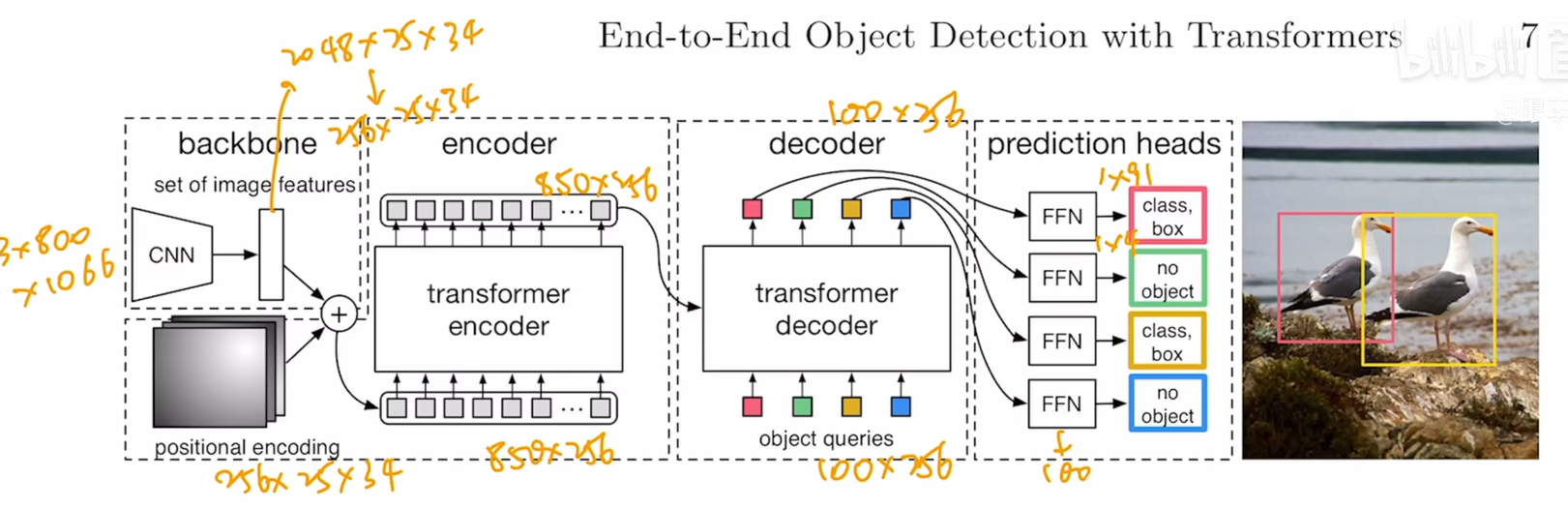
*2048~256是通过1x1卷积实现的
*这里拉直是指把HXW(25*24~850)
*object embedding 是 learnable positional embedding
*cross attention:850*256喝100*256反复做自注意力操作
*拿到100*256之后就进行预测了,也就是检测头,不过检测头是标准MLP,做两个预测,一个类别预测一个出框预测
基于集合的目标函数
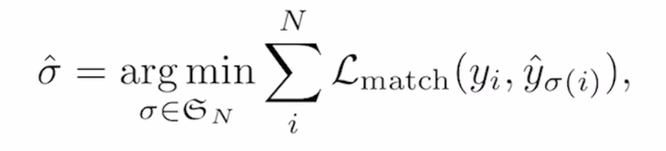
先生成一百个框
如何知道哪个框对应预测框?-二分图匹配 e.g匈牙利算法/linear sum assignment去解决
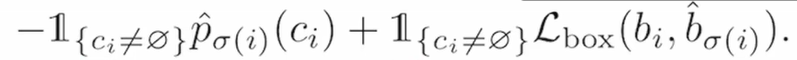
最后的公式↓ 分类loss+出框loss;先去算最优匹配,再在最优匹配上面算loss
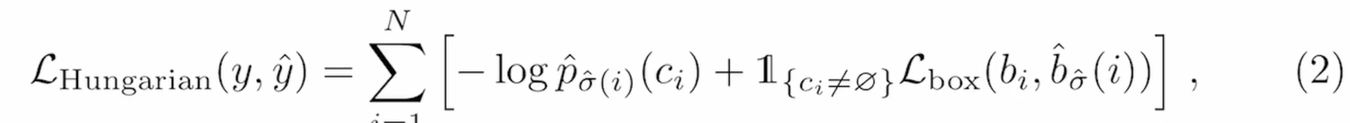
结果
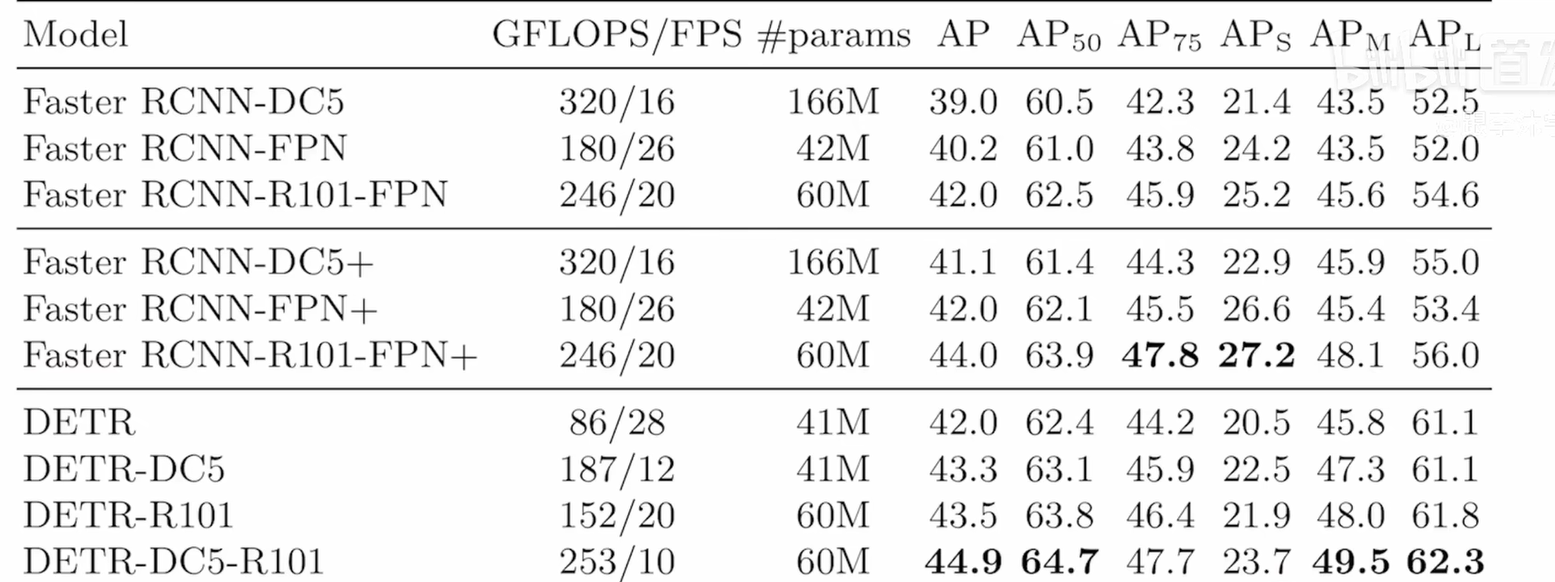
在大目标检测上效果好,小目标检测效果不是很好
改进:deformable DETR,引入多尺度特征,解决DETR训练太慢的问题
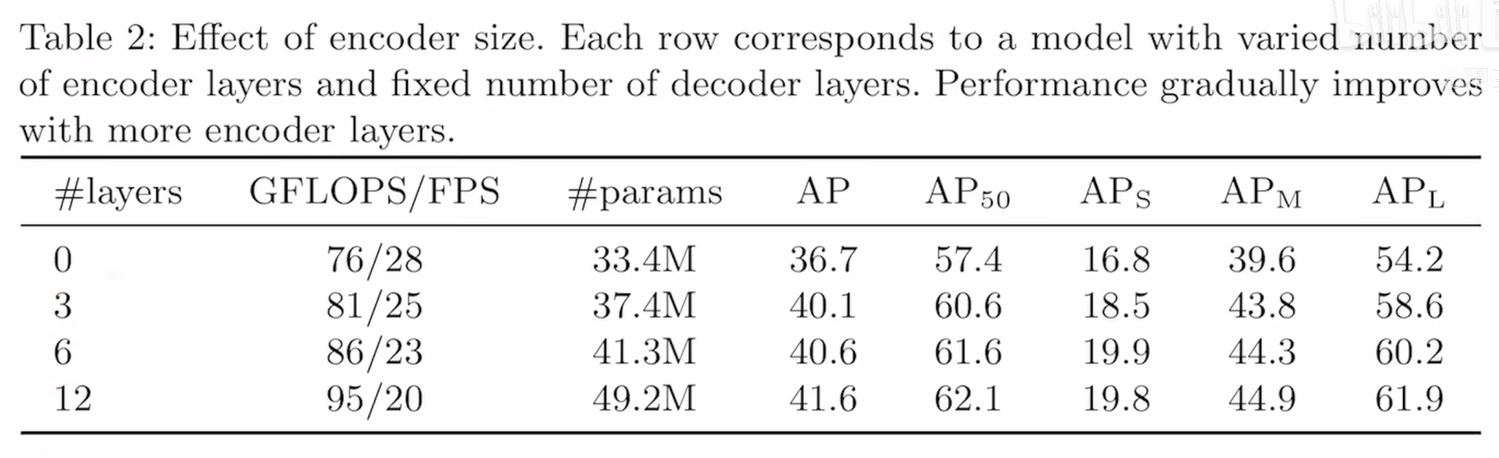
transformer编码器

自注意力可视化
transformer解码器

对于头和尾巴等边缘极值点decoder能处理好,并且处理遮挡问题
Object Query可视化
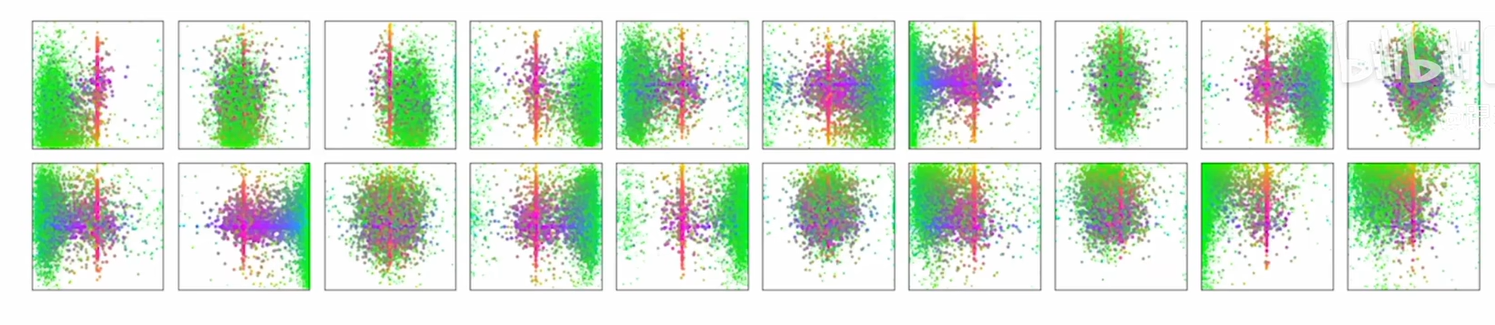















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









