







 本文介绍了一种新的伪装目标检测模型C2F-Net,通过ACFM融合跨层特征和DGCM捕捉全局上下文信息,实现在多个基准数据集上的显著性能提升。方法包括注意力诱导的ACFM和双分支全局上下文模块,以及针对不同尺寸输入的处理策略。
本文介绍了一种新的伪装目标检测模型C2F-Net,通过ACFM融合跨层特征和DGCM捕捉全局上下文信息,实现在多个基准数据集上的显著性能提升。方法包括注意力诱导的ACFM和双分支全局上下文模块,以及针对不同尺寸输入的处理策略。
21年的一篇CVPR
论文link:link
code:link
摘要
伪装目标检测是一项具有挑战性的任务,因为目标与周围环境之间的边界对比度很低。此外,伪装物体的外观变化很大,例如物体的大小和形状,这增加了准确的COD的难度。本文提出了一种新的上下文感知跨级融合网络(C2F-Net)来解决具有挑战性的协同设计任务。具体地说,我们提出了一种注意力诱导的跨层融合模块(ACFM)来整合具有信息的注意系数的多层特征。然后,融合后的特征被馈送到所提出的双分支全局上下文模块(DGCM),该模块产生用于利用丰富的全局上下文信息的多尺度特征表示。在C2F-Net中,这两个模块以级联方式在高层特征上进行。在三个广泛使用的基准数据集上的大量实验表明,我们的C2F-Net是一个有效的COD模型,其性能明显优于最新的模型。
1.主要贡献
1.提出一个新的COD模型:C2F-Net,结合了跨层特征和丰富的全局上下文信息
2.提出了一种上下文感知模块DGCM,利用融合后的特征中的全局上下文信息,DGCM能够捕获有价值的上下文信息,这是提高COD准确率的关键因素
3.我们将跨层特征与一个有效的融合模块ACFM结合,该模块将这些特征与MSCA提供的有价值的注意线索相结合。
4.在三个基准数据集上的大量实验表明,我们的C2F-Net在四个评价指标方面优于14个最先进的模型
2.模型结构图
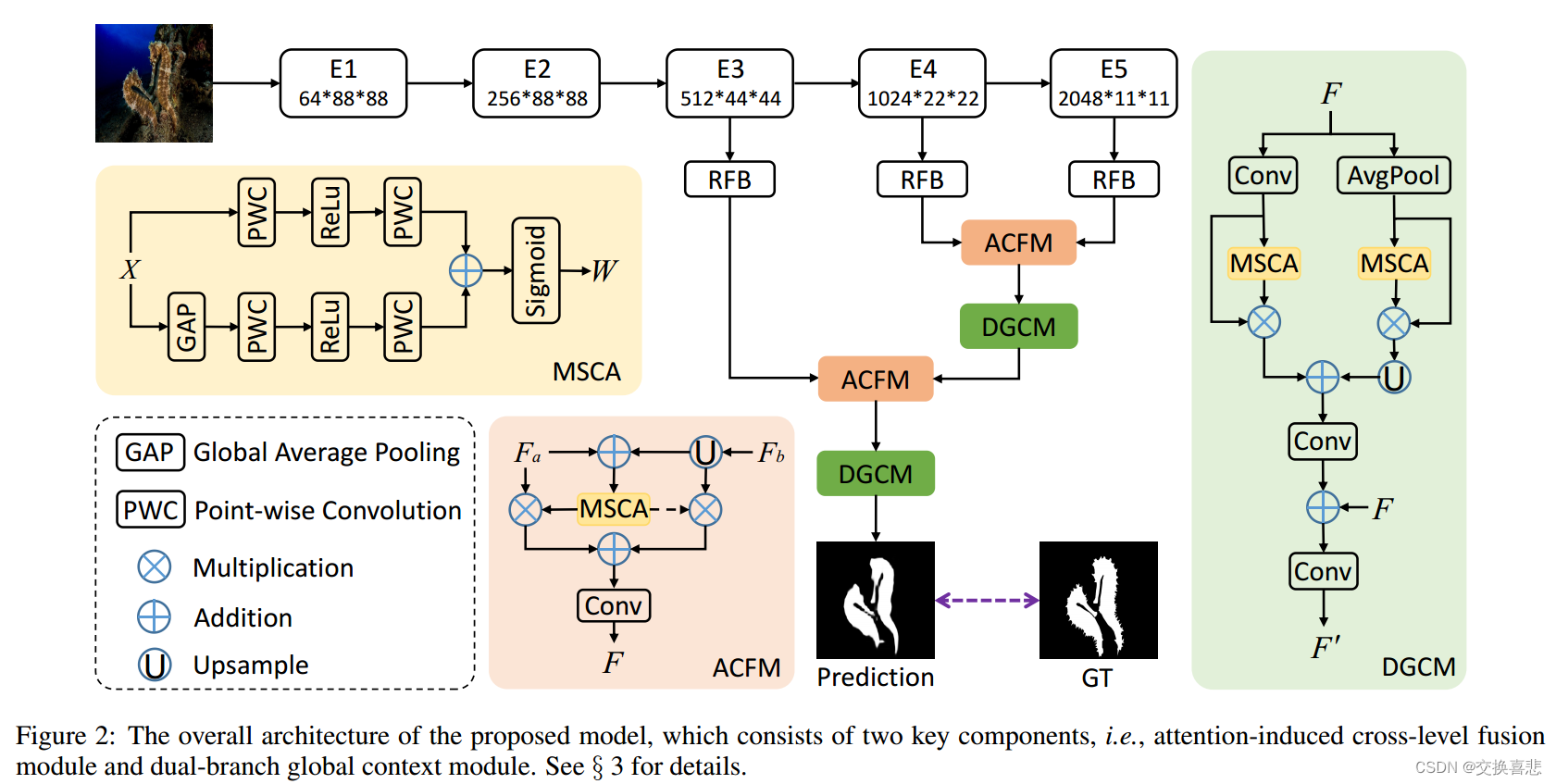
3.方法
C2FNet总体架构,该架构融合了上下文感知的跨层特征来提高伪装目标检测的性能,具体来说就是采用Resnet50在五个不同层次的层提取特征,表示为: f i ( i = 1 , 2 , . . . 5 ) f_i(i=1,2,...5) fi(i=1,2,...5),然后,采用RFB模块来扩展感受域,以捕捉特定层中的更丰富的特征,RFB组件包括五个分支,在每个分支中,第一卷积层具有 1 × 1 1 \times 1 1×1的维度将信道大小减少到64,然后是两层,即(2k−1)×(2k−1)卷积层和当k>2时具有特定扩张率(2k−1)的3×3卷积层。将前四个支路级联,然后使用1×1卷积运算将它们的信道尺寸减小到64。然后,添加第五个分支,并将整个模块馈送到RELU激活函数,以获得最终的特征。在此基础上,提出了一种融合多尺度特征的注意力诱导跨层融合模块(ACFM)和一种挖掘融合特征中多尺度上下文信息的双分支全局上下文模块(DGCM)。最后给出了伪装目标检测的预测结果。
3.1 ACFM:Attention-indiced Cross-level Fusion Module
具有较大空间分辨率的低层特征比高层特征需要更多的计算资源,但对深度集成模型的性能贡献较小,出于这一观察,只在高层次特征中进行ACFM,将
f
i
(
i
=
3
,
4
,
5
)
f_i(i=3,4,5)
fi(i=3,4,5)成为高层特征,其跨层融合过程如下:
F
a
b
=
M
(
F
a
∪
F
b
)
⊗
F
a
⊕
(
1
−
M
(
F
a
∪
F
b
)
)
⊗
F
b
{F_{{\rm{ab}}}} = M({F_a} \cup {F_b}) \otimes {F_a} \oplus (1 - M({F_a} \cup {F_b})) \otimes {F_b}
Fab=M(Fa∪Fb)⊗Fa⊕(1−M(Fa∪Fb))⊗Fb
得到跨层融合特征
F
a
b
F_{ab}
Fab
补充一下对于
F
b
F_b
Fb,为什么使用的是1-M而不是像
F
a
F_a
Fa那样用M,这个作者在github的issues里面这样解释的:
ACFM是一个跨层融合模块,信息逐层向前传输,即高层信息
(
F
b
)
(F_b)
(Fb)应和低层信息
(
F
a
)
(F_a)
(Fa)保持接近,因此在对MSCA进行初始融合计算后,应该将M作为
F
a
F_a
Fa的注意力权重,如果同时使用相同的M将
F
a
F_a
Fa和
F
b
F_b
Fb相乘,那么灵活性就丧失了,因此使用1-M让模块在模型学习时分配
F
a
F_a
Fa和
F
b
F_b
Fb的权重。
3.2 DGCM Dual-branch Global Context Module
采取所提出的ACFM对不同层次的多尺度特征进行融合,引入多尺度通道注意机制来获得信息丰富的基于注意力的融合特征。此外,全局上下文信息是提高伪装目标检测性能的关键,因此提出一种双分支全局上下文模块(DGCM)来利用融合的跨层特征中丰富的全局上下文信息。具体地,ACFM的输出
F
∈
R
W
×
H
×
C
F \in {R^{W \times H \times C}}
F∈RW×H×C通过卷积运算和平均合并分别馈送到两个支路。我们可以得到
F
c
∈
R
W
×
H
×
C
{F_c} \in {R^{W \times H \times C}}
Fc∈RW×H×C和
F
p
∈
R
W
2
×
H
2
×
C
{F_p} \in {R^{\frac{W}{2} \times \frac{H}{2} \times C}}
Fp∈R2W×2H×C,为了学习基于注意力的多尺度层次特征表示,首先将
F
c
F_c
Fc和
F
p
F_p
Fp反馈给MSCA组件。
首先元素乘法将MSCA的输出与相应的特征进行融合,得到
F
c
m
∈
R
W
×
H
×
C
{F_{cm}} \in {R^{W \times H \times C}}
Fcm∈RW×H×C与
F
p
m
∈
R
W
2
×
H
2
×
C
{F_{pm}} \in {R^{\frac{W}{2} \times \frac{H}{2} \times C}}
Fpm∈R2W×2H×C,然后使用加法操作直接融合来自两个分支的特征,以获得
F
c
p
m
F_{cpm}
Fcpm。最后利用残差结构对F和
F
c
p
m
F_{cpm}
Fcpm进行融合,得到
F
′
F^{'}
F′.
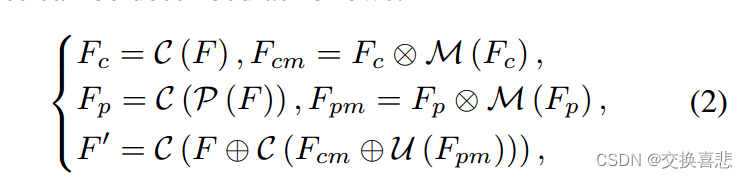
3.3 Loss Function
L = L I o U w + L B C E w L=L_{IoU}^{w}+L_{BCE}^{w} L=LIoUw+LBCEw
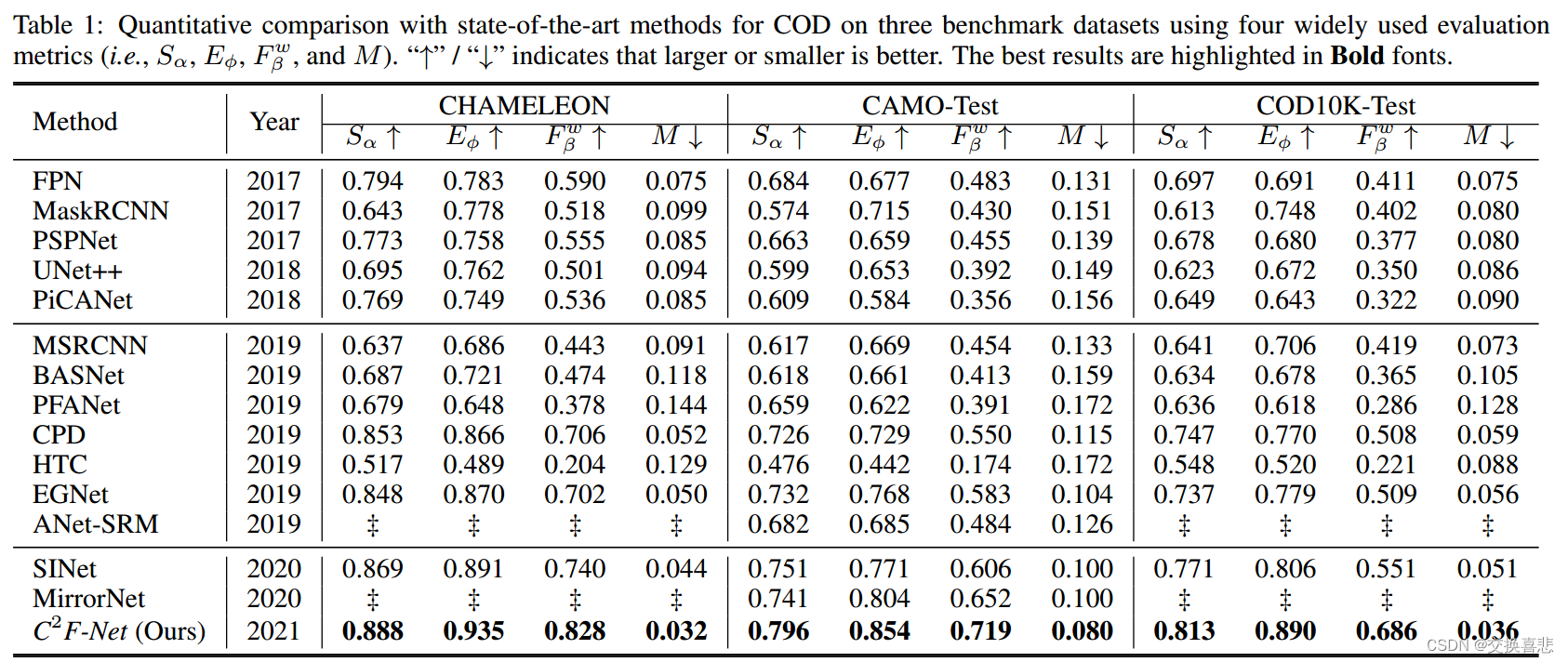
4 实验

5.结论
本文提出了一种新的伪装目标检测网络C2F-Net,它综合了伪装目标的跨层特征和丰富的全局上下文信息。我们提出了一种上下文感知模块DGCM,它利用融合后的特征中的全局上下文信息。我们将跨层特征与一个有效的融合模块ACFM相结合,该模块将这些特征与MSCA提供的有价值的注意线索相结合。在三个基准数据集上的大量实验结果表明,该模型的性能优于其他最先进的方法。
issue:
关于预训练模型的问题,issue里面有人问resnet的权重,现在给出的伪装目标检测的backbone权重都是resnet在ImageNet上pretrain的结果,有人提问在ImageNet上pretrain时,图片的大小是
224
×
224
224 \times 224
224×224,但是C2FNet的训练图片的大小是
352
×
352
352 \times 352
352×352,图片尺寸不一样难道没有影响吗,作者给出的回复说的听明确的,在此记录一下:
1.用于伪装目标检测的通用基线方法SINet选择
352
×
352
352 \times 352
352×352作为输入尺寸,为了公平的比较,许多后续方法都遵循SINet的输入大小,C2FNet也是如此。
2. COD不是一个分类任务,Res2Net只是作为一个特征提取器,而不是分类器,因此FC层(全连接层)被放弃,因此,输入图像大小的变化并不会影响网络的运行。
3. COD是一个像素级的分割任务,需要较高的分辨率来保留更多的有效信息,以COD10K为代表的数据集都有着非常高的分辨率,将所有图像压缩为
224
×
224
224 \times 224
224×224是不合适的。
4. 相关研究也表明,提高分辨率可以获得更大的收益,你可以看到YOLO系列演进过程中输入大小的变化,这将帮助你理解迁移学习和微调。
5. 一般来说,对于非分类任务,输入大小不受预训练模型的限制是一个领域共识。















 3811
3811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









