






前言
近年,研究发现 CNN 在特征提取过程中会损失结构信息,而且 CNN 的实际感受野远小于理论感受野,因此基于 CNN 的伪装目标检测模型通常不能充分地捕获全局上下文信息。2017年,Vaswani等人针对自然语言处理提出的Transformer能够利用自注意力捕获长距离依赖关系,更好地捕获全局信息。由于Transformer在计算机视觉领域中的巨大潜力,研究者们也将其引入到了伪装目标检测任务中。
我们还观察到,对于密集的预测任务,Transformer的位置编码在建模准确的“空间”信息时效果较差。
T 2 N e t T^2Net T2Net模型利用Swin Transformer作为主干网提取丰富的全局伪装特征,并利用一种基于残差通道注意力和密集金字塔池化的深度监督结构来缓解Swin Transformer不直接提供空间监督的问题。
主要贡献:
- 提出了一个基于Transformer backbone的主干网络,完成基于全监督的SOD、基于RGB-D的SOD、基于弱监督的SOD,和基于RGB图像的伪装目标检测任务。
- 提出了深度监督模块和难度感知模块,可以在基于Transformer backbone的框架中生成更强的空间监督。
- 对比CNN backbone和Transformer backbone,发现Transformer backbone的主要优势在于使用远距离依赖建模机制进行准确的结构和语义信息编码。
传统的基于手工特征的显著目标检测模型、基于cnn的模型和基于transformer的模型的感受野的比较。CNN backbone的感受野随着层的加深而逐渐增大,但问题在于感受野的增大是以结构信息的损失为代价的。并且,一旦信息丢失,就无法完全恢复。另外,尽管CNN的理论感受野覆盖了整个图像,但是许多研究表明,CNN的实际感受野比理论感受野小得多。
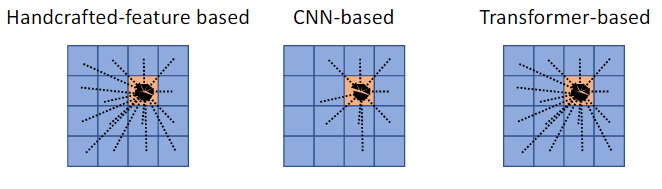
将CNN骨干网和transformer骨干网的特征可视化在下图中,发现transformer骨干网分别在低层和高层特征中编码了更准确的对象结构信息和更清晰的语义信息。

1. 模型的特点
模型包含两个主要模块:显著性“生成器”,用于进行深度信息监督的显著性预测;基于置信度估计的“判别器”,用于估计像素级置信度图,实现难度感知学习。
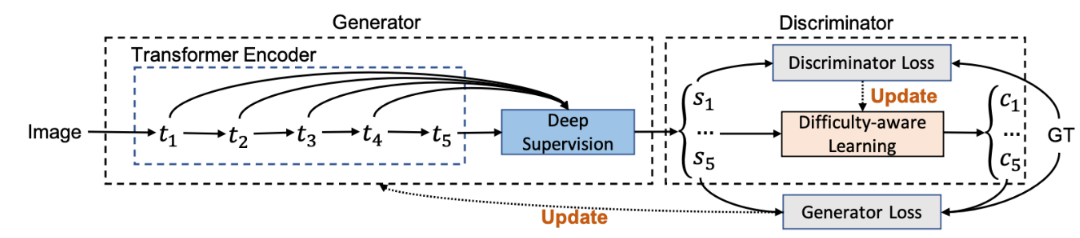
2. 模型结构
2.1 生成器
显著性“生成器”由Transformer编码器 E θ ( x ) E_{ \theta }(x) Eθ(x)和深度监督模块 G β ( E θ ( x ) ) G_{\beta}(E_{\theta}(x)) Gβ(Eθ(x))组成,其中 θ \theta θ和 β \beta β代表每个模块的参数集合, x x x代表输入图像。
将Swin Transformer作为Transformer编码器,生成通道大小分别为128、256、512、1024和1024的特征图 E θ ( x ) = { t l } l = 1 5 E_{\theta}(x)=\lbrace t_l \rbrace ^5 _{l=1} Eθ(x)={tl}l=15
使用来自Transformer编码器的特征 E θ ( x ) = { t l } l = 1 5 E_{\theta}(x)=\lbrace t_l \rbrace ^5 _{l=1} Eθ(x)={tl}l=15,在网络的每个层级进行显著性预测并实现深度信息监督,其结构图如下所示。
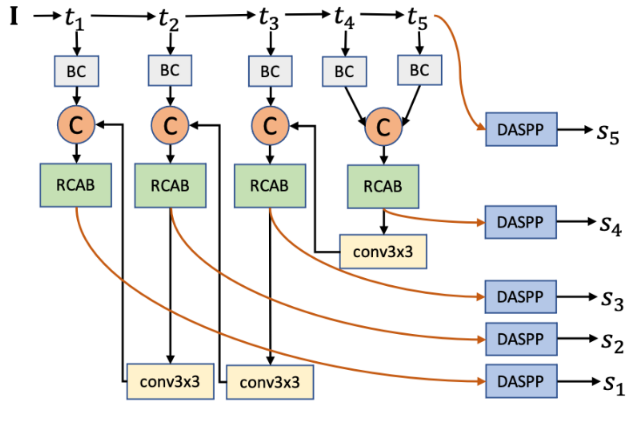
首先使用5个不同的 3 × 3 3 \times 3 3×3卷积层将Transformer backbone输出的特征图 { t l } l = 1 5 \lbrace t_l \rbrace ^5 _{l=1} {tl}l=15映射到相同的通道大小 C = 32 C = 32 C=32(使用 batch normalization,“BC”),得到特征图 { d l } l = 1 5 \lbrace d_l \rbrace ^5 _{l=1} {dl}l=15。
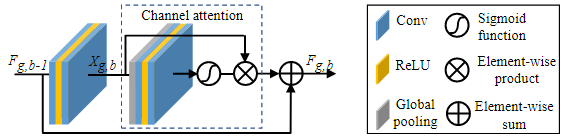
然后使用一个U形解码器来实现多尺度显著性预测。将相邻特征聚合定义为: b l = C a ( [ d l , c o n v 3 × 3 ( b l + 1 ) ] ) b_l=C^a([d_l,{conv}_{3 \times 3}(b_{l+1})]) bl=Ca([dl,conv3×3(bl+1)]), l = 1 , … , 4 l=1,\ldots,4 l=1,…,4,其中, C a C^a Ca是一个残差通道注意力模块(RCAB)来提取通道上的判别特征。 c o n v 3 × 3 {conv}_{3 \times 3} conv3×3是一个 3 × 3 3 \times 3 3×3卷积层, [ ⋅ ] [ \cdot ] [⋅]代表通道连接。对于最高层级的特征,有 b l = d l b_l = d_l bl=dl。在通道连接前,通过双线性插值将 b l + 1 b_{l+1} bl+1上采样到与 d l d_l dl相同的空间大小。
残差通道注意力模块(RCAB)如下图。
通过相邻特征聚合,得到单通道显著性预测 { s l = D m ( b l ) } l = 1 5 \lbrace s_l = D_m(b_l) \rbrace ^5 _{l=1} {sl=Dm(bl)}l=15,其中 D m D_m Dm是使用多尺度膨胀卷积的DenseASPP模块,来生成最终的显著性图。
为了训练全监督模型,采用加权结构感知损失(参考F3Net,与SINet-v2相同),即加权二元交叉熵损失和加权IOU损失之和:
L f u l l l ( s l , y ) = w ∗ L c e l ( s l , y ) + L i o u l ( s l , y ) , l = 1 , … , 5 L_{full}^l(s_l,y)=w * L_{ce}^l(s_l,y) + L_{iou}^l(s_l,y), l = 1, \ldots, 5 Lfulll(sl,y)=w∗Lcel(sl,y)+Lioul(sl,y),l=1,…,5
其中,y是GT显著性图,w是边缘感知权重,其定义为 w = 1 + 5 ∗ ∣ a p ( y ) − y ∣ w=1+5*\lvert ap(y)-y \rvert w=1+5∗∣ap(y)−y∣, a p ( ⋅ ) ap(\cdot) ap(⋅)表示平均池化操作。 L c e l L^l_{ce} Lcel是二元交叉熵损失, L i o u l L^l_{iou} Lioul是加权IOU损失,定义为:
L i o u l = 1 − w ∗ i n t e r l + 1 w ∗ u n i o n l − w ∗ i n t e r l + 1 , l = 1 , … , 5 L_{iou}^l = 1 - \frac{w*{inter}^l + 1}{w*{union}^l - w*{inter}^l + 1}, l=1,\ldots,5 Lioul=1−w∗unionl−w∗interl+1w∗interl+1,l=1,…,5
其中, i n t e r l = s l ∗ y {inter}^l=s_l*y interl=sl∗y, u n i o n l = s l + y {union}^l=s_l+y unionl=sl+y,最终生成器的全监督损失函数如下: L f u l l g = A v e ( { L f u l l l } l = 1 5 ) L_{full}^g=Ave(\lbrace L_{full}^l \rbrace ^5 _{l=1}) Lfullg=Ave({Lfulll}l=15),其中, A v e ( ⋅ ) Ave(\cdot) Ave(⋅)代表求平均值。
源代码中实际生成器的损失函数:
loss_dis_output = CE(torch.sigmoid(Dis_output), make_dis_label(opt.gt_label, gts)) # gt_label = 1
supervised_loss = cal_loss(pred['sal_pre'], gts, loss_fun)
loss_all = supervised_loss + 0.1*loss_dis_output
L f u l l g = A v e ( { L f u l l l } l = 1 4 ) + 0.1 ∗ L c e ( s i g m o i d ( R γ ( s l , x ) ) , g l ) } l = 4 L_{full}^g=Ave(\lbrace L_{full}^l \rbrace ^4 _{l=1}) + 0.1*L_{ce}(sigmoid(R_{\gamma}(s_l,x)),g_l) \rbrace_{l=4} Lfullg=Ave({Lfulll}l=14)+0.1∗Lce(sigmoid(Rγ(sl,x)),gl)}l=4
2.2 判别器
判别器 R γ R_{\gamma} Rγ有5个卷积核大小为3的卷积层组成,它将图像 x x x和模型预测 s l s_l sl在通道维度上拼接在一起,[12, 4, 384, 384],作为输入,并产生一个[12, 1, 48, 48]的通道置信度图 c l c_l cl。 γ \gamma γ是判别器的参数集合。将判别器的监督定义为模型预测和GT显著图之间的差异 g l = ∣ y − s l ∣ g_l=\lvert y-s_l \rvert gl=∣y−sl∣。
判别器的损失函数定义为二元交叉熵损失 L d i s = A v e ( { L c e ( s i g m o i d ( R γ ( s l , x ) ) , g l ) } l = 1 5 ) L_{dis}=Ave(\lbrace L_{ce}(sigmoid(R_{\gamma}(s_l,x)),g_l) \rbrace^5_{l=1} ) Ldis=Ave({Lce(sigmoid(Rγ(sl,x)),gl)}l=15)。
难度感知学习
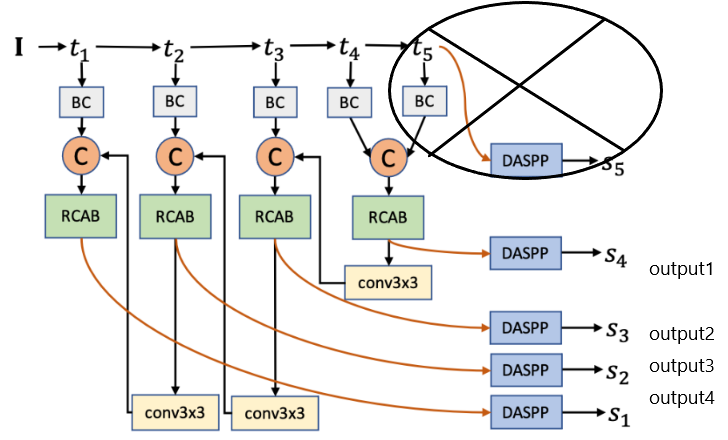
难度感知学习类似于hard negative mining,其目的是更多地强调hard样本。通过判别器,模型可以估计生成器中预测的逐像素精确度,如下图所示。
因为模型对简单样本的预测比对难样本的预测更准确,所以这可以作为评估样本像素难度的一个很好的指标。

给定生成器的预测
s
l
s_l
sl和判别器
c
l
=
s
i
g
m
o
i
d
(
R
γ
(
s
l
,
x
)
)
c_l=sigmoid(R_{\gamma}(s_l,x))
cl=sigmoid(Rγ(sl,x))的输出,我们将生成器损失函数中的边界感知权重w替换为
c
l
c_l
cl,并将其定义为难度感知损失
L
d
l
L_d^{l}
Ldl。然后将多个预测的难度感知损失定义为
L
d
=
A
v
e
(
{
L
d
l
}
l
=
1
5
)
L_d=Ave(\lbrace L_d^l \rbrace _{l=1}^5)
Ld=Ave({Ldl}l=15)。
利用 L d L_d Ld和全监督损失 L f u l l g L_{full}^g Lfullg,我们得到了全监督学习模型的最终损失函数: L f u l l = 0.5 ∗ ( L f u l l g + L d ) L_{full}=0.5*(L_{full}^g + L_d) Lfull=0.5∗(Lfullg+Ld)。
3. 思考与分析
T 2 N e t T^2Net T2Net模型使用Swin Transformer作为backbone,并且加入了两个关键的模块:深度监督模块和难度感知学习模块。
实验表明,深度监督模块可以恢复底层特征到高层特征的梯度,有助于更高级别的特征在同一语义对象内实现统一的激活;而难度感知学习模块能有效地识别hard像素,从而实现有效的hard negative挖掘。
不使用 vs. 使用深度监督模块的对比如下图。

运行时间对比:
该框架的参数总数为89M,与现有模型相似,如Basnet[86]和JLDCF[106]分别有87M和144M参数。在推论方面,我们的模型达到了46fps,与现有的模型相当。
CVPR2023中FasterNet提到模型运行效率方面的问题,FLOPs的减少不一定会带来网络运行延迟的减少,还应该关注模型对内存访问的频率。
疑问
- saliency_detector.py中sod_model()函数,为什么要进行noise_model()?通过实验说明有无noise_model效果如何变化。
- trainer_gan.py中判别器部分实际只使用了 S 4 S_4 S4,即output1。是否是出于参数量的考虑?如果使用生成器全部4层的输出进行判别器的训练能否获得更好的效果?同时参数量如何变化?
- trainer_gan.py中判别器中的损失函数并没有将生成器损失函数中的边界感知权重w替换为 c l c_l cl,而是全部使用交叉熵损失函数。如果替换结果如何?
- 生成器模型结构与由粗到细的伪装目标检测模型十分接近,参考SINet-v2,如果将分组反向注意力机制引入其中,效果如何?















 1850
1850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









