







随着信息的不断丰富,搜索和推荐成为了我们日常最长用到的两个功能,搜索是用户主动发起的信息查找需求,推荐则是平台根据用户标签/行为或用户query推荐给用户信息,用户是被动消费内容。
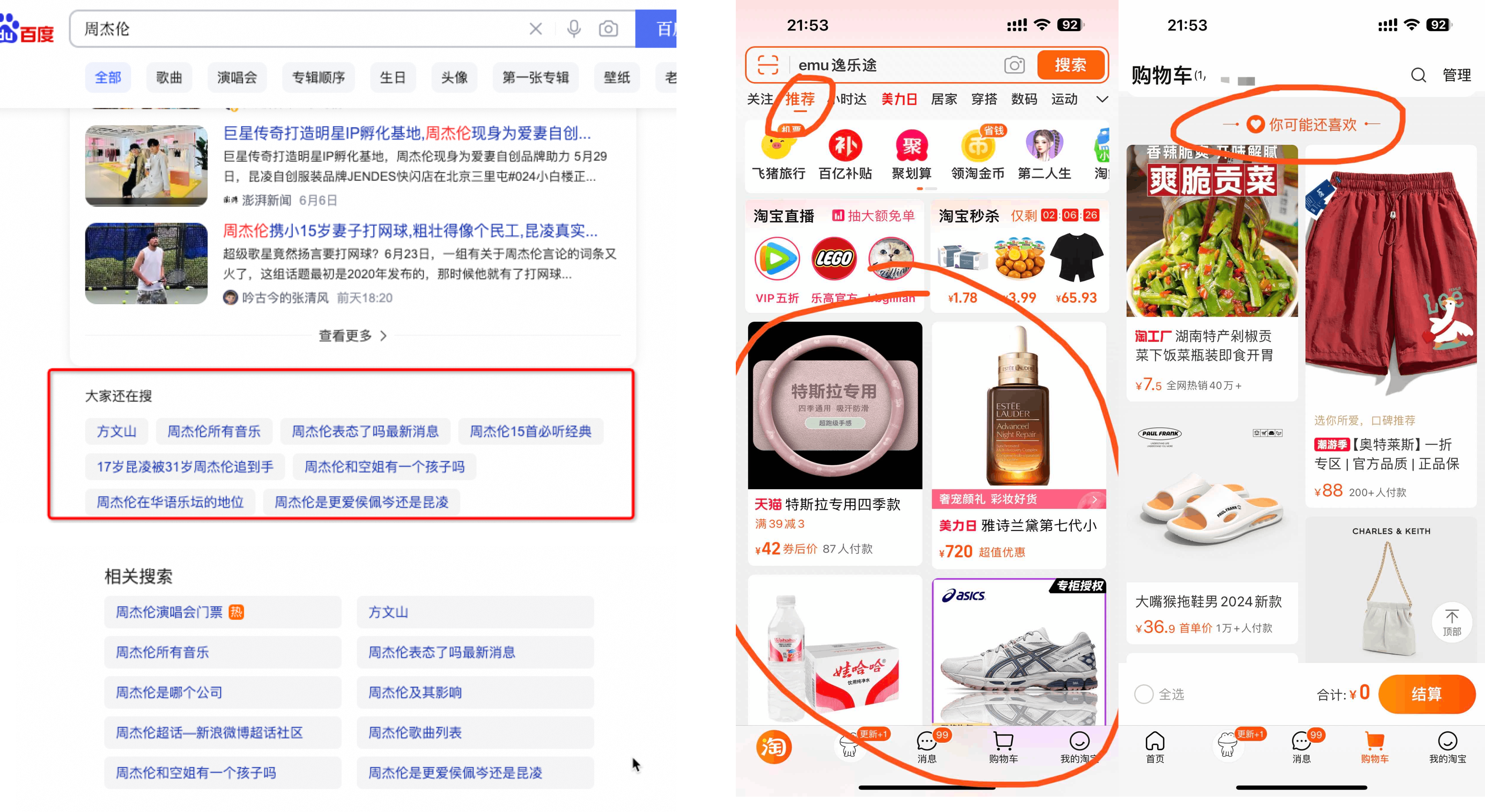
比如在百度上搜索“周杰伦”时,搜索结果会给你推荐“大家都在搜”和“相关推荐”的query;再比如在淘宝购物,推荐商品无处不在;更别提以抖音为代表的短视频、以今日头条为代表的信息流产品,完全是基于推荐系统构建的。
推荐系统的核心在于捕捉并理解用户的潜在偏好,进而为用户推送合适的信息资源。目前,主流的研究工作通常依赖于用户的交互行为日志数据(如点击商品、评论文本数据)和用户标签数据(如年龄、性别、职业)来训练推荐模型(通常是深度学习模型)。然而,这些方法在实践中面临着一系列技术挑战,如缺乏通用的知识信息、难以应对冷启动和领域迁移问题等。由于LLM具有优秀的语言理解和知识推理能力,近期很多研究工作尝试将其应用在推荐系统领域。
一、LLM作为推荐模型
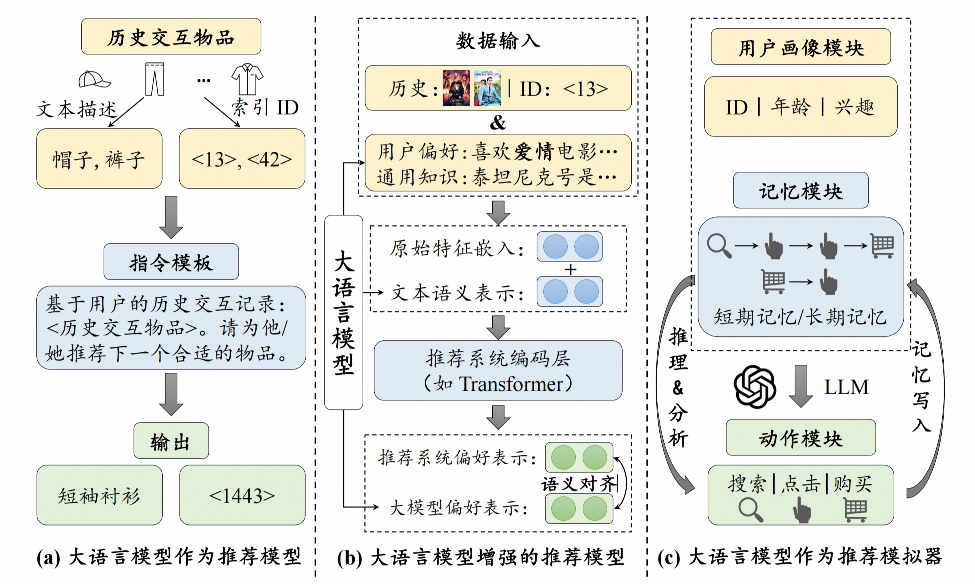
LLM可以直接作为推荐模型来提供推荐服务。根据是否需要进行参数更新,现有的研究工作可以分为基于特定提示的方法和基于指令微调的方法。
1、基于特定提示的方法
这类方法通常采用提示学习与上下文学习方法,通过设计一系列自然语言提示来完成多种推荐任务。下面以序列推荐任务为例,介绍如何设计对应的提示方法。
- 首先,可以将用户交互过的物品的文本描述(例如物品标题、描述、类别等)拼接在一起得到一个长句子作为输入文本。
- 然后,结合任务描述构造个性化推荐指令(例如“请基于该用户的历史交互物品向其推荐下一个合适的物品。”)。
- 此外,还可以在提示中加入一些特殊的关注部分来提高推荐性能,可以强调最近的历史交互物品(例如“注意,该用户最近观看的电影是《肖申克的救赎》。”)和应用上下文学习方法。
然而,由于推荐系统中特定领域的用户-物品协同关系较为复杂且难以通过文本数据充分建模,简单的自然语言提示难以使得LLM在性能上与经过充分训练的传统推荐模型竞争。
2、基于指令微调的方法
这类方法通过微调LLM将其适配到推荐系统,核心在于构建适合推荐任务的指令数据。相关指令可以基于用户与物品的交互数据以及定制化的提示模板来构造,从而为模型提供明确的任务指导。根据物品的表示方式,现有的方法包括以下两种。
- 第一种方法利用文本描述来表示每个物品,该指令构造过程与基于特定提示的方法类似,将用户特征、交互序列等上下文信息整合为纯文本指令用于训练LLM。
为了构造多样的指令形式,可以采用指令合成技术(如Self-Instruct),模拟用户在真实场景中产生的个性化指令,以帮助LLM理解用户多样化的意图和偏好。具体来说,在包含历史交互记录的基础上,进一步在指令中加入用户当前的意图(例如“现在用户期望购买一个轻便的手提包,请根据该需求提供物品推荐”)。
- 另一种方法是引入传统推荐系统中的索引ID来表示每个物品。
该方法首先构建物品索引,并使用一个或多个索引ID作为物品标识符,然后将这些索引ID作为扩展词元加入LLM词表。这样,用户的物品交互历史能够被表示为基于索引ID的扩展词元序列。
这种方法主要具有两个优点。首先,索引ID的表示在后续的微调过程中能够专门学习推荐任务相关的物品信息。其次,相较于文本描述,索引ID更加具体,有效限定了候选物品的词典空间,易于被模型直接生成。然而,LLM所建模的自然语言语义与推荐系统中蕴含的协同语义可能并不一致,故需要设计语义对齐任务以学习ID词元的嵌入表示,并将协同信息融入LLM的语义空间。
二、LLM增强的推荐模型
LLM还可以用于增强推荐系统的数据输入、语义表示或偏好表示,以从不同角度改进已有推荐模型的性能。
1、数据输入增强
在数据输入端,LLM可以用于用户或物品特征的增强。对于用户特征来说,可以使用LLM对用户的交互历史进行推理分析,以此获得更为详细的用户兴趣或蕴含的偏好信息。对于物品特征来说,LLM可以被用于从物品文本描述中提取关键属性或者推测缺失的物品特征。在此基础上,传统的推荐模型可以利用这些增强后的输入数据实现更为精准的推荐。
2、语义表示增强
在中间编码层,LLM通常被用来编码用户和物品的描述性信息(例如,物品的标题信息以及用户的评论文本),从而获得用户或物品的文本语义表示,可以将这些富含知识的语义表示作为输入特征,进而增强原有推荐模型的推荐效果。
实际上,早期的预训练语言模型已经通过这种方式在推荐领域中得到了广泛的应用。LLM因为其更强大的语义理解能力和丰富的通用知识,能够在冷启动和领域迁移等场景下为模型提供更大的助力。
3、偏好表示增强
除了上述两种方式外,还可以通过联合训练LLM和传统推荐模型,使两者输出的偏好表示对齐,进而增强推荐模型偏好表示的质量。该方式类似于知识蒸馏技术,可以将LLM的语义建模能力迁移给较小的协同过滤模型,以发挥大小模型各自的优势。在训练阶段完成后,实际部署时使用增强后的小模型即可,从而实现了提升推荐效果的同时,避免了LLM带来的大量计算开销。
三、LLM作为推荐模拟器
受自主智能体研究的启发,LLM进一步被用于设计推荐模拟器,用于仿真用户在推荐系统中的真实交互行为。推荐模拟器旨在为推荐系统中的每位用户构建一个基于LLM的智能体,以模拟他们在真实推荐系统中的交互行为。
以RecAgent为例,为了更好地实现个性化的模拟,RecAgent为每个智能体都集成了三个核心模块:用户画像模块、记忆模块和动作模块。
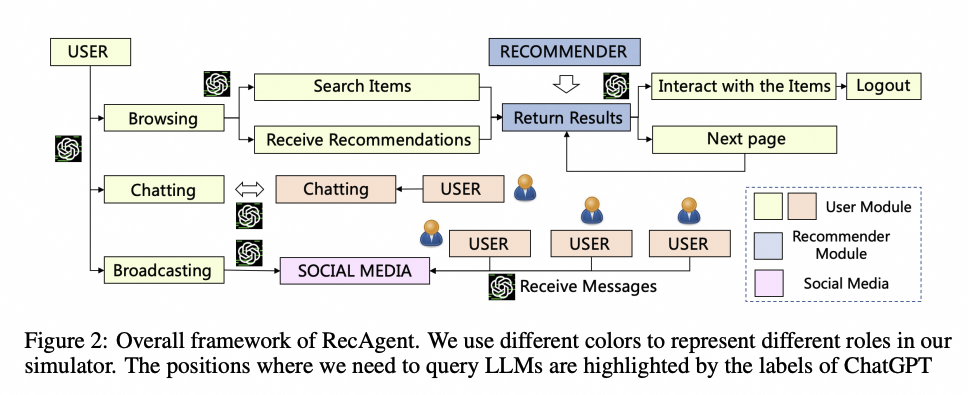
其中,用户画像模块中包含关于当前用户的相关背景信息(即各种用户属性和特征,如年龄、性别、职业等)。
记忆模块负责存储智能体在历史交互过程中的行为以及反馈信息。为了更准确地模拟用户偏好的变化过程,研究人员通常将记忆划分为多个类别,如短期记忆和长期记忆。
动作模块则用于模拟用户在推荐系统中的各种行为(如搜索、点击、购买等)。在模拟过程中,智能体借助LLM,根据用户画像和历史记忆来执行自我分析与反思,以挖掘潜在的用户行为偏好,之后动作模块基于这些偏好做出决策以确定用户的下一步动作(例如用户对推荐物品进行点击与评分),该动作将会被执行以得到新的用户行为信息。
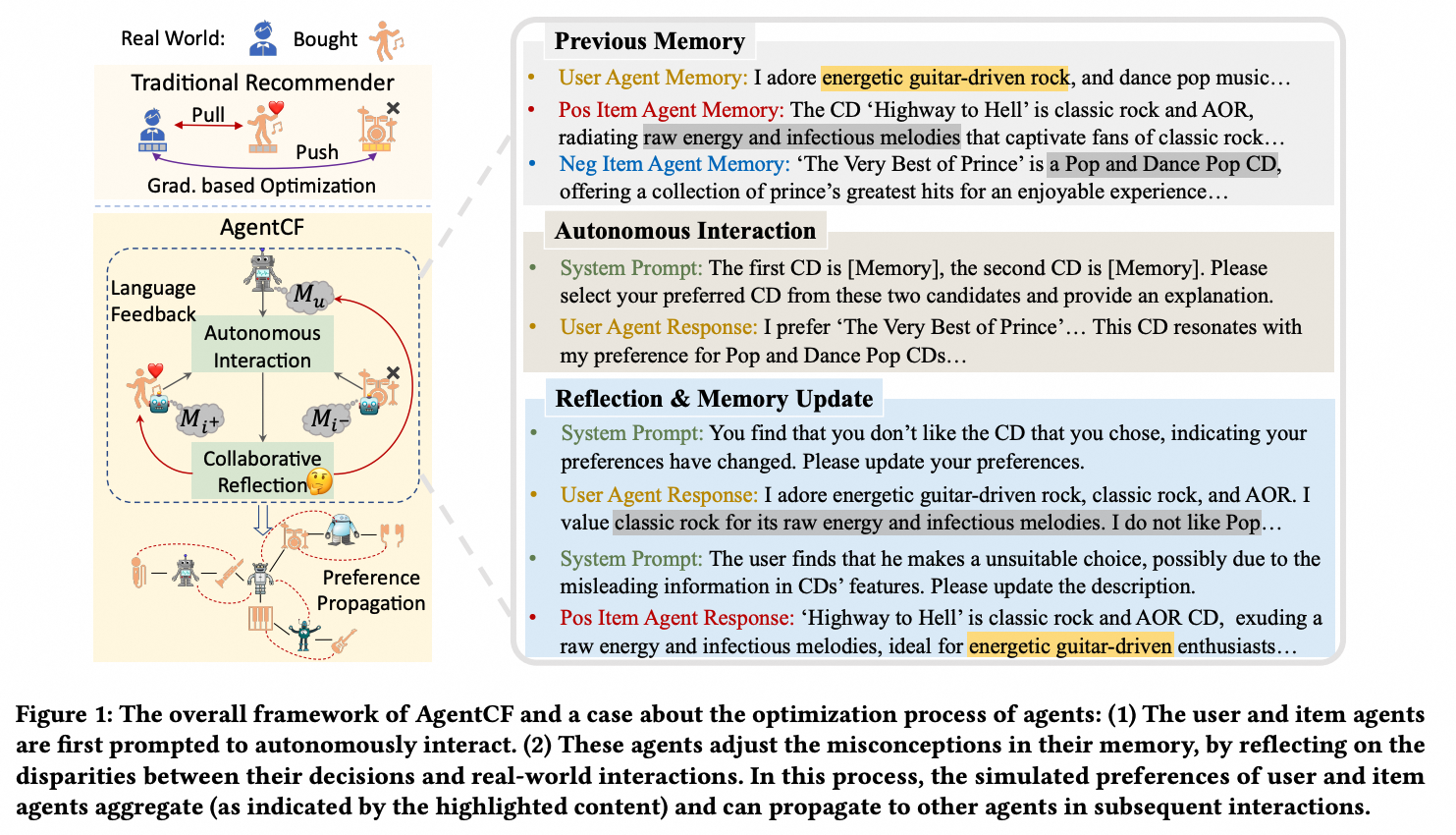
当前大多数推荐模拟器主要基于完全用户导向的设计,侧重于模拟刻画用户的偏好和行为,还可以进一步引入物品侧信息的建模。例如,AgentCF同时构建了用户和物品智能体,并在优化过程中进一步模拟传统推荐模型的协同过滤思想,建模用户和物品的双边关系来增强个性化推荐。
四、展望
1、应用建议
LLM在用户偏好理解、跨领域推荐、冷启动推荐等复杂推荐场景中展现了较强的性能。然而,受限于高昂的训练和部署成本,在推荐链路中,将LLM作为最后重排或精排模型可能更为实际。进一步,可以不直接将LLM用于部署,而是在真实场景中有选择性地使用LLM(如面临复杂用户行为时)来增强传统推荐模型的数据输入、中间编码或偏好表示,这样可以在避免巨大资源消耗的同时保留传统模型的优势。此外,LLM也可以作为推荐模拟器,通过模拟用户和物品的交互行为场景,进而帮助改善用户稀缺场景下的推荐系统服务。
2、现存问题和未来方向
目前,LLM在应用于真实场景下的推荐系统时依然存在一些亟待解决的问题。首先,在真实世界的应用平台中,推荐系统通常涉及大规模的用户和物品资源。即便仅将LLM作为特征编码器,也会带来巨大的计算和内存开销。其次,在推荐系统中,用户的交互历史往往包含长期的、复杂的偏好信息,而LLM有限的上下文建模长度可能限制了对这些信息的全面理解和利用。尽管面临诸多挑战,LLM在推荐系统中具有广阔的应用前景。例如,LLM出色的交互能力与语义理解能力为对话式推荐与可解释推荐都带来了重要的性能提升机会。
Reference
[1] RecAgent: A Novel Simulation Paradigm for Recommender Systems
[2] AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台,目前注册送20元测试金,可以畅享7小时4090算力,预装了主流的大模型和环境的镜像,开箱即用,非常方便。



















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











