







随着GPT-4、DeepSeekMoE等模型的发布中均涉及到了混合专家模型(MoE,Mixture of Experts)的话题,MoE 模型已经成为开放 AI 社区的热门话题。2023年6月,美国知名骇客George Hotz在接受采访时透露,GPT-4由8个220B的专家模型组成。假如把8个专家模型比喻为比GPT-3还大的脑袋,那GPT-4就是一个八个头的超级大怪兽。
GPT-4(MoE)比GPT-3(Transformer)和GPT-3.5(RLHF)强大一个数量级的关键,可能就是来源于MoE架构。之前的GPT大模型增大参数的方法是在一个GPT模型上堆层数,现在变成了堆模型数。将来大语言模型的研究新方向,可能就不是增大单一模型的向量维度和层数了,而是增大整体架构的模型数了。GPT-4引入MoE似乎是个必然,因为无论是算力、数据、稳定性,万亿级参数的单个大模型训练很困难,而且推理成本也会居高不下,跑万亿个参数的计算才能算出一个token的速度和成本比较不可观。所以,将若干个模型堆成一个MoE大模型似乎是个必然趋势。
那么,究竟什么是MoE大模型?MoE大模型具备哪些优势呢?
MoE,全称为Mixed Expert Models,混合专家模型,简单理解就是将多个专家模型混合起来形成一个新的模型。在理解MOE之前,有两个思想前提,可以帮助我们更容易地理解MOE架构。一是在现实生活中,如果有一个包括了多个领域知识的复杂问题,我们该使用什么样的方法来解决呢?最简单的办法就是先拆分任务到各领域,然后把各个领域的专家集合到一起来攻克这个任务,最后再汇总结论。这个思想可以追溯到集成学习,MoE和集成学习的思想异曲同工,都是集成了多个模型的方法,区别在于集成学习不需要将任务分解为子任务。集成学习是通过训练多个基学习器来解决同一问题,并且将它们的预测结果简单组合(例如投票或平均)。而MOE是把大问题先做拆分,再逐个解决小问题,再汇总结论。二是模型规模是提升模型性能的关键因素之一。在有限的计算资源下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
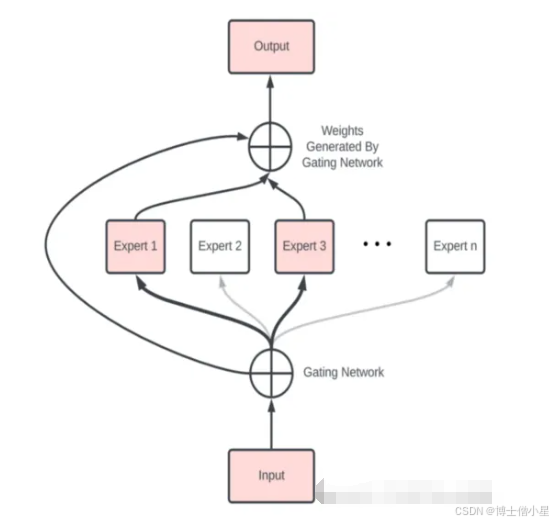
MoE正是基于上述的理念,它由多个专业化的子模型(即“专家”)组合而成,每一个“专家”都有其擅长的领域。而决定哪个“专家”参与解答特定问题的,是一个称为“门控网络”的机制。技术上常说的门控机制,可能会先想到LSTM的门控机制,但是这里的门控机制和LSTM里的门控不一样。LSTM的门是为了控制信息流动,这里的门就更像我们日常中提到的门,选择进门或是不进门,是一个控制是否使用某个专家模型的概率分布值。
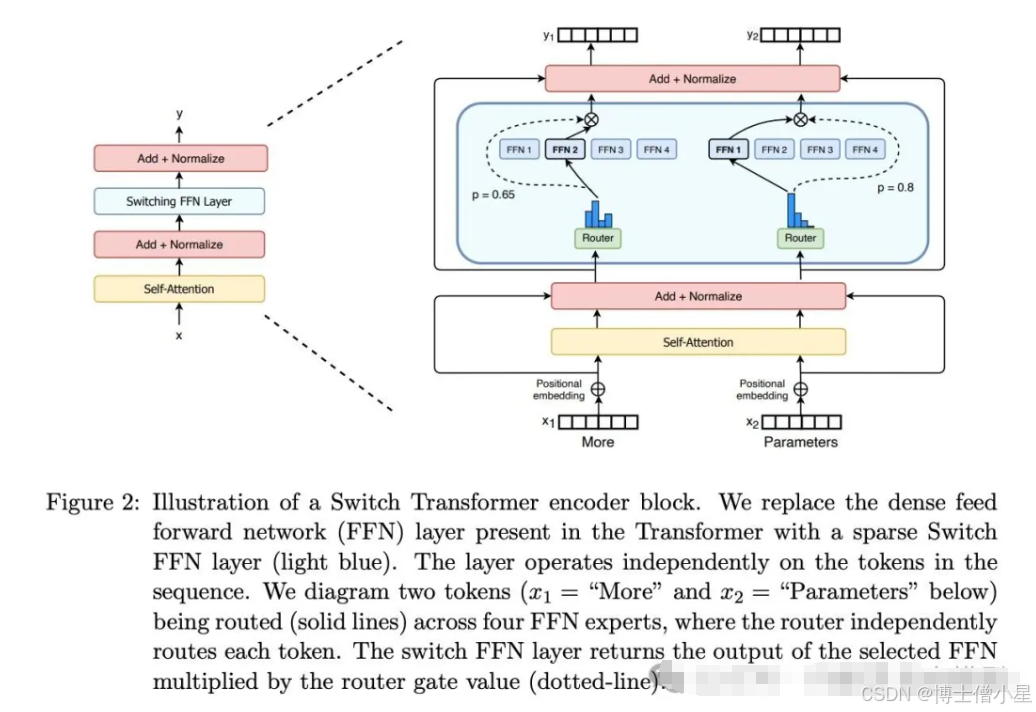
MoE基于Transformer架构,主要由两部分组成:
稀疏 MoE 层:MoE层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”模型,每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构。
门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。例如,在上图中,“More”这个 token 可能被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。同时,一个 token 也可以被发送到多个专家。token 的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。例如Google的Switch Transformer,模型大小是T5-XXL的15倍,在相同计算资源下,Switch Transformer模型在达到固定困惑度 PPL 时,比T5-XXL模型快4倍。

MoE结合大模型属于老树发新芽,MOE大模型的崛起是因为大模型的发展已经到了一个瓶颈期,包括大模型的“幻觉”问题、逻辑理解能力、数学推理能力等,想要解决这些问题就不得不继续增加模型的复杂度。随着应用场景的复杂化和细分化,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,尤其在多模态大模型的发展浪潮之下,每个数据集可能完全不同,有来自文本的数据、图像的数据、语音的数据等,数据特征可能非常不同,MoE是一种性价比更高的选择。国内大模型已经开始朝着MoE方向大步前进,在2024年,估计会有越来越多大模型选择MoE架构。
一、Adaptive mixtures of local experts
Adaptive mixtures of local experts,这是大多数MoE论文都引用的最早的一篇文章,发表于1991年。论文介绍了一种新的监督学习过程——由多个独立网络组成一个系统,每个网络单独处理训练集合的子集。因为对于多任务学习,如果是常见的多层网络学习,各层之间的网络通常会有强烈的干扰效应,这会导致学习过程变慢和泛化能力差。为了解决这个问题,论文提出了使用多个模型(即专家,expert)去学习,使用一个门控网络(gating network)来决定每个数据应该被哪个模型去训练的权重,这样就可以减轻不同类型样本之间的干扰。

但是,作者提到这个损失函数可能会导致专家网络之间的强烈耦合,因为是所有专家网络的权重加总来共同计算损失的,一个专家权重的变化会影响到其他专家网络的loss。这种耦合可能会导致多个专家网络被用于处理每条样本,而不是专注于它们各自擅长的子任务。为了解决这个问题,论文重新定义了损失函数,以鼓励专家网络之间的相互竞争。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











