






2025
GPU
上海站

GPU高级调试与优化
AI技术的高速发展让GPU红的如火如荼,而且这种趋势还在扩张,3D、计算机视觉、VR/AR、视频编解码等GPU应用百花齐放。但是从系统架构来看,GPU依然还处于外设的地位,还没有摆脱从属身份。因为这个根本特征,对GPU编程并不像对CPU编程那样直接,而调试和优化GPU软件的难度就更大了,要比CPU复杂很多。
本研习班直面如何提高GPU工作效率这一目标,从硬件结构、软件接口和工具三个维度螺旋推进,深度解析驾驭现代GPU所需的关键知识和工具。硬件方面,以NVIDIA的特斯拉系列为重点,兼顾AMD、INTEL和ARM的产品做横向比较。软件方面,覆盖硬件指令(SASS)、中间指令(PTX)、编程模型(CUDA、OpenCL、OpenVX、DirectX和OpenGL)、驱动模型(DRM和WDDM)和工具三个层面。具体由以下10个主题和6个动手试验组成。
THIS ISGPU高级调试与优化
TIME 时间
2025年3月7日 - 3月9日
ADDRESS 地点
Shanghai 上海

课程形式
讲解
实战演练
讨论点评
培训对象
使用GPU进行通用计算和图形加速的软件工程师(开发和测试)、技术经理和科研人员。
预备知识
C语言
Linux系统基本命令
课程大纲
序言(0.5h)
为加速而生
课程要点/ KEY POINTS
硬件加速、从可配置到可编程、ASIC、G80、GPGPU、John Nickolls、Brook和CUDA、GPU的四大功能模块。

第一部分(1.5h)
在CUDA-GDB中理解CUDA
课程要点/ KEY POINTS
CUDA简要历史、CUDA的C扩展、kernel函数、WARP、CUDA的线程组织、准备调试环境、单GPU调试和多GPU调试、远程调试、nvcc、-G和-g选项、附加到已经运行的进程、启用kernel初始断点(break on launch)、观察源代码和汇编指令、设置断点、单步跟踪、条件断点、观察CUDA的内建变量、PTX指令集、理解WARP、grid、block和thread、Grid-Stride Loops、观察GPU线程、观察GPU的调用栈、观察GPU的寄存器、观察错误信息、从GPU上打印信息。
试验1
编译和观察简单的CUDA程序
编译一个简单的CUDA程序、使用CUDA SDK中的二进制工具观察其内容、理解CUDA的编译过程和程序文件格式。
试验2
改进和调试向量乘法程序
使用CUDA技术编写一个做向量乘法的小程序、理解如何向kernel函数传递参数和传回计算结果。
试验3
学习CUDA-GDB的基本用法
调试一个简单CUDA程序、练习常用的CUDA-GDB扩展命令、理解CUDA编程的关键概念。
第二部分(1.5h)
NVIDIA GPU微架构
课程要点/ KEY POINTS
三大系类、历代微结构(Fermi、Kepler、Maxwell、Pascal、Volta、Truing、Ampere、Hopper、Lovelace)、从SIMD到SIMT、warp、SM(Streaming Multiprocessors)、GigaThreads调度器、ECC支持、第三代SM、Hyper-Q、Grid Management Unit(GMU)、SMX、动态并行、Maxwell微架构、SMM、指令缓存、WARP调度器、指令分发单元、Pascal微架构、伏特微架构、Tensor Core、软件仿真(GPUSim)。

第三部分(1.5h)
PTX指令集和PTX编程入门
课程要点/ KEY POINTS
PTX源文件、nvcc -ptx、PTX汇编器(ptxas)、预处理指令、注释、标号、指令语句、基本指令格式、常量、寄存器、缓存和共享内存、状态空间、寄存器、变量和数组、张量和多维矩阵。
试验4
编写PTX程序
使用nvcc -ptx产生PTX文件、理解CU代码和PTX指令的对应关系、使用PTX指令编写大矩阵乘法程序、使用ptxas进行编译。
第四部分(1.5h)
PTX高级编程
课程要点/ KEY POINTS
显式并行、CTA、cluster和grid、Warp内共享程序指针和独立调度、特殊寄存器、消除分支和谓词执行、线程之间同步、栈、从栈上动态分配内存。
第五部分(1.5h)
使用Nsight调试CUDA程序
课程要点/ KEY POINTS
Nsight简介、安装和设置环境信息、在VS中编译CUDA程序、产生调试信息(-G)、本地调试模型、Nsight Monitor、设置断点、观察变量、在Cuda Info窗口中观察计算状态、WarpWatch、调用栈、源代码跟踪、PTX/SASS汇编调试、数据断点、API Trace、OpenCL kernel追踪、产生GPU转储(core dump)。
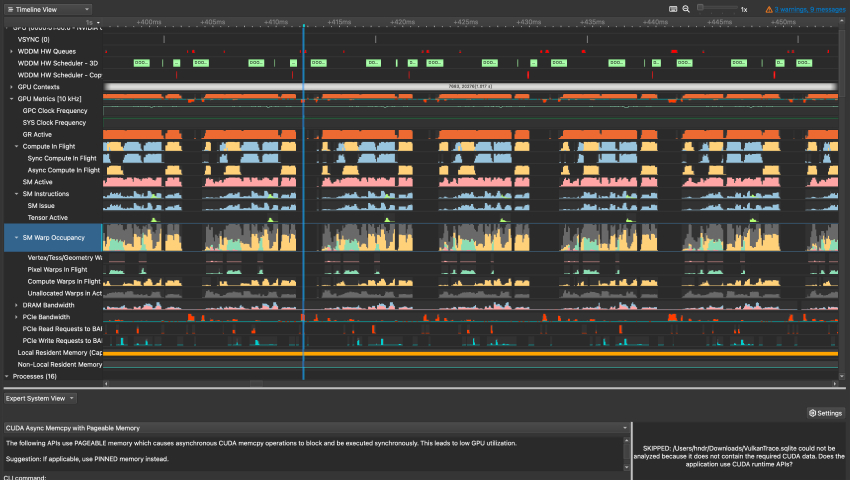
试验5
使用Nsight调试CUDA程序
在VS中编译和调试一个典型的并行计算程序、熟悉Nsight提供的常用调试功能、包括产生调试信息、建立调试会话、设置各种断点、观察源代码和变量、单步跟踪等。
第六部分(1.5h)
显存锥鉴
课程要点/ KEY POINTS
系统架构、内存映射、PCI Aperture、GART、GTT、访问主内存、 UVA/UMA、Batch Buffer、CUDA中的内存类型、内存共享、内存复制、使用本地共享内存(shared memory)、使用CUDA memory checker检查内存问题(越界访问)、使用Nsight的内存调优功能。
第七部分(1.5h)
驱动程序和软件栈
课程要点/ KEY POINTS
DX和WDDM、UMD、KMD和DX运行时、DRM、GEM和KMS、启用DRM的调试功能、NVIDIA的GPU驱动、社区版本(Nouveau)、半开源版本、开源版本的局限。
第八部分(1.5h)
使用CUDA profiler优化CUDA程序
课程要点/ KEY POINTS
测量GPU的时间、nvprof、命令行选项、指定收集范围、定义输出目标、Visual Profiler基础、配置远程目标、导入数据、观察时序图、识别重要事件(CPU缺页、GPU缺页、数据迁移、内存复制)、采样视图、分析热点、源代码和汇编结合分析、Profile API、定义别名、定制标记、创建调优会话。
试验6
使用nvprof和Visual Profiler优化
使用nvprof观察大模型推理程序的执行细节、收集性能数据、在Visual Profiler中进行深入分析、定位热点和瓶颈。
第九部分(1.5h)
与CPU和外存交互
课程要点/ KEY POINTS
收集事件、识别典型问题(从外存加载数据)、GPU/CPU Starvation、CPU/GPU Idle、线程切换、分析线程切换原因、GPUDirect RDMA、GPUDirect Storage、理解DMA、使用Nsight/nvprof定位热点和性能瓶颈、实例演示。
第十部分(1.5h)
使用Mali GPU做大模型推理
课程要点/ KEY POINTS
Mali GPU概要、在AI推理中的应用、微架构演进、内部结构、通用计算执行单元、统一内存、OpenCL Kernel、实例演示(使用OpenCL加速Llama大模型推理)。
讲师介绍

张银奎
Raymond Zhang
绰号:格蠹老雷
1996年毕业于上海交通大学信息与控制工程系,在软件产业工作20余年,一多半时间在INTEL公司的上海研发中心工作,其中五年多工作在INTEL的GPU部门,以调试显卡驱动代码和各类GPU有关的问题为乐。业余时间喜欢写作和参与各类技术会议,发文数百万字,探讨各类软件问题。2015年起获微软全球最有价值技术专家(MVP)奖励。著有《软件调试》、《格蠹汇编》和《软件简史》,曾经主笔《程序员》杂志调试之剑专栏 。在多家跨国公司历任开发工程师、软件架构师、开发经理、项目经理等职务,对 IA-32 架构、操作系统内核、驱动程序、虚拟化技术、云计算、软件调优、尤其是软件调试有较深入研究。
从2005年开始公开讲授“Windows内核及高级调试”课程,曾在微软的Webcast和各种技术会议上做过《Windows Vista内核演进》、《调试之剑》(全球软件战役研究峰会)、《感受和思考调试器的威力》(CSDN SD2.0大会)、《Windows启动过程》、《如何诊断和调试蓝屏错误》、《Windows体系结构——从操作系统的角度》(以上三个讲座都是微软“深入研究Windows内部原理系列”的一部分)等。翻译(合译)作品有《现代x86汇编语言编程》、《21世纪机器人》、《观止——微软创建NT和未来的夺命狂奔》、《数据挖掘原理》、《机器学习》、《人工智能:复杂问题求解的结构和策略》等。
附录1
往届研习班部分照片







- 左右滑动查看更多 -
附录2
报名或垂询
标准收费
标准收费:6898元 / 每人
优惠条款:开课十日前报名可享九五折优惠。
课程顾问
Lisa
邮箱:lisa.long@nanocode.cn
微信:13801874134
Gary
邮箱:jiali.liu@nanocode.cn
微信:17600723325
公司付款信息
账户名称:格蠹信息科技(上海)有限公司
开户行:招商银行股份有限公司上海浦江镇支行
账号:1219 3085 8010 501
-END-
【盛格塾】
正心诚意,格物致知
以人文情怀审视软件,以软件技术改变人生

格友公众号

盛格塾小程序
扫描上方二维码或在微信中搜索“盛格塾”小程序
可以阅读更多文章和有声读物
往期推荐

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









