






一、综述
Feichtenhofer受机器学习中的特征选择方法启示,想到了一个简单的逐步扩张不同维度的方法,从基础的模型X2D出发,探索了帧率、帧数、分辨率、深度、宽度、bottleneck宽度对模型性能的影响。不同的是用了坐标下降+贪心策略进行快速“搜索”,方法简单但十分有效。
现有的方法倾向于对基于图像分类的模型进行时间维度的扩张,同时保留空间属性,包括直接转化2D网络为3D网络、增加RNN进行融合、加相同2D卷积处理光流作为辅助特征,尽管这些方法可以使用图像分类任务进行预训练,但这失去了视频任务的针对性,会继承图像分类模型的偏差。
SlowFast研究了slow和fast不同分支时间、空间和通道分辨率的作用,fast分支很轻量但单独一个fast分支效果很差,最后的结果离不开基于图像分类设计的繁重的slow分支。本文的目的之一也是想探究繁重的slow分支是否必须的,亦或一个足够轻量的分支同样可比。
因此与其他工作最大的不同是,本文没有针对某一种2D网络进行扩张,而是设计了一种更小更轻量的结构,并在不同维度上进行扩张实现效率和准确率的权衡。
作者认为对小模型在时间维度进行扩张固然可以提升准确率,但是这样的计算量和准确率的权衡并不一定比在其他维度进行扩张好,尤其是低计算量模型,这些模型在不同维度上扩张会快速增加准确率。
再者,作者思考了图像分类模型的发展史,这些模型经历了渐进式地对深度、输入分辨率、通道宽度的探索,然而对于视频分类模型却没有相似的研究,而是像前面所说的只在时间维度进行扩张。作者因此提出了对不同维度的思考,具体如下:
1.对于3D网络什么样的采样方式才是最好的?更长的稀疏采样亦或更短的稠密采样?(采样帧率)
2.是否需要一个更好的空间分辨率?是否存在一个最大空间分辨率导致性能饱和?(空间分辨率)
3.更快的帧率+更“瘦”的模型好亦或更慢的帧率+更“宽”的模型好?也即slow分支和fast分支哪种的结构更好?又或者存在一个二者的中间结构更好?(帧率与宽度,呼应前面对slow和fast的思考)
4.当增加网络宽度时,是增加全局的宽度好还是增加bottleneck的宽度好?(宽度,inverted bottlenetck结构的借鉴)
5.网络变深的同时,是否应该增加输入的时空分辨率以保证感受野大小足够大?又或者应该增大不同的维度?(深度与时空分辨率)
二、网络结构

上图是X3D的基本结构,融合了ResNet结构和fast分支,如果所有变量都设置为1则得到退化的单帧模型,上图中输入的size为
T
×
S
2
T×S^2
T×S2 , T为帧数,S为宽高。注意同样在每一层的第一个残差block进行空间下采样,并且时间维度只在最后的全局池化层进行下采样。再者,这里的
3
×
3
2
3×3^2
3×32为channel-wise卷积,
c
o
n
v
1
conv_1
conv1中的
3
×
1
3×1
3×1卷积同样为depth-wise卷积。
扩张维度
渐进式网络扩张
下面介绍如何对前面提到的6个维度进行扩张
前向扩张=>给定复杂度,逐步逐维度扩张

作者的策略是,每一步只扩张一个维度,其他维度保持常数,而每一步最好的扩张因子被保留,接着进行下一步扩张。再者,每一步的扩张是渐进式的,也即复杂度约2倍增长。这种方法可以看成是坐标下降法的特殊形式,扩张2倍的各维度操作具体如下:

关于坐标下降法,简单来说就是迭代的将某些变量固定,而对其他的变量求极值的方法。
后向收缩=>超过复杂度,回溯收缩
因为前向扩张是离散地对不同维度进行扩张,在某一步进行扩张时,可能会因为上一步的前向扩张导致复杂度不满足条件,由此回溯。如上一步增加采样帧率为两倍,则回溯使的采样帧率小于两倍。
Model
渐进式扩张后,列举了如下三种不同复杂度的网络。
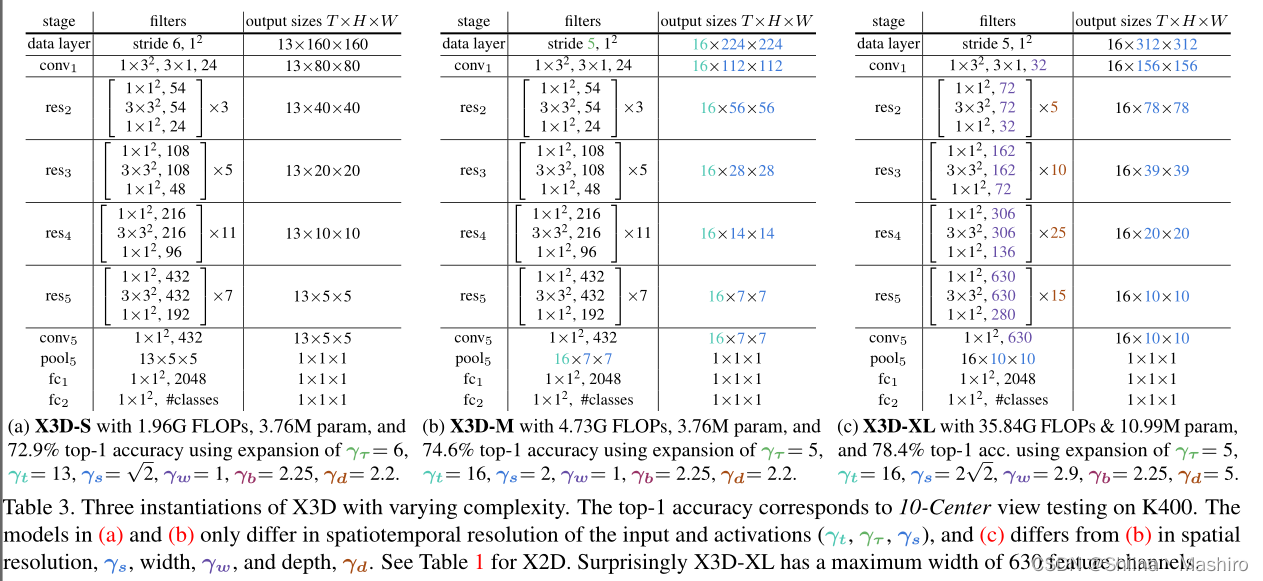
需要注意的是,从附录中看,作者参考2D mobile结构的成功经验,使用了SE block和swish非线性激活函数,,为了节省内存,作者根据轻量型进行了微调,SE中的channel放缩为原本的
1
/
16
1/16
1/16倍,只在
3
×
3
2
3×3^2
3×32 卷积后使用,swish只在bottleneck的前后使用,而其他层保留使用ReLU激活,不使用MobileNetV2中提到的线性激活函数设计,一是因为作者发现这在分布式训练中不稳定,二是这样不允许0初始化最后一个BN层。
关于0初始化最后一个BN层,参考FAIR一小时训练ImageNet的论文《Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour》

Experiment Detail
首先是在Kinetics-400上的扩张实验,注意的是FLOPs为单clip居中裁剪计算得到,而验证时实际采样有两种,一是10clip居中裁剪,而是10clip左中右裁剪,最后取softmax分数平均值。


渐进式扩张
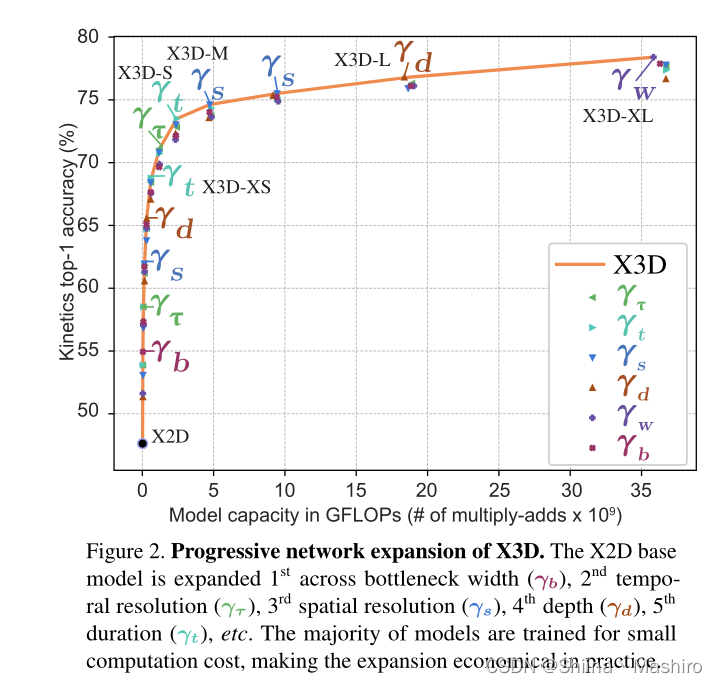
扩张从最简单的“X2D”结构开始,top-1为47.75%,参数量为1.63M,FLOPs为20.67M。渐进式扩张过程如上,有如下几个observation:
1.扩张任意一个维度都增加了准确率,验证了最初的motivation。
2.第一步扩张的不是时间维度,而是bottleneck宽度,这验证了MobileNetV2中的倒置残差结构,作者认为原因可能是这些层使用了channel-wise卷积十分轻量,因此首先扩张这个维度比较economical。且不同维度准确率变化很大,扩张bottleneck宽度达到了55.0%,而扩张深度只有51.3%。
3.第二步扩张的为帧数(因为最初只有单帧,因此扩展采样帧间隔和帧数是等同的),这也是我们认为“最应该在第一步扩张的维度”,因为者提供更多的时间信息。
4.第三步扩张的为空间分辨率,紧接着第四步为深度,接着是时间分辨率(帧率)和输入长度(帧间隔和帧数),然后是两次空间分辨率扩张,第十步再次扩张深度,这符合直观的想法,扩张深度会扩张滤波器感受野的大小。
5.值得注意的是,尽管模型一开始十分tiny(宽度比较小),但直到第十一步,模型才开始扩张全局的宽度,这使得X3D很像SlowFast的fast分支设计(时空分辨率很大但宽度很小),最后图里没显示扩张的两步为帧间隔和深度。
不同复杂度的模型
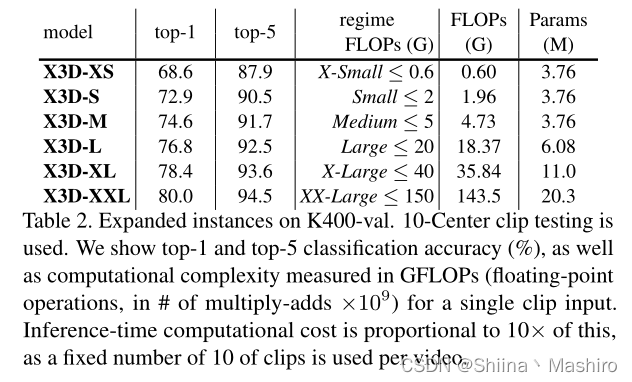
作者划分不同FLOPs,得到了一系列如上所示的模型。
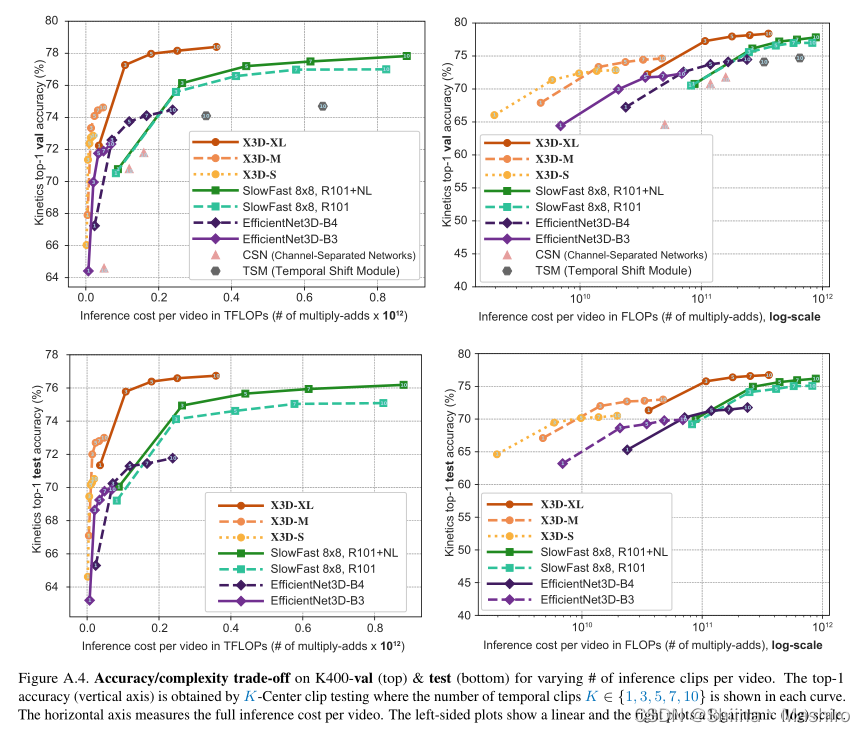
从上图曲线可以看到,X3D-S和X3D-M这些小模型可以在相同准确率的前提下,减小20倍的FLOPs。
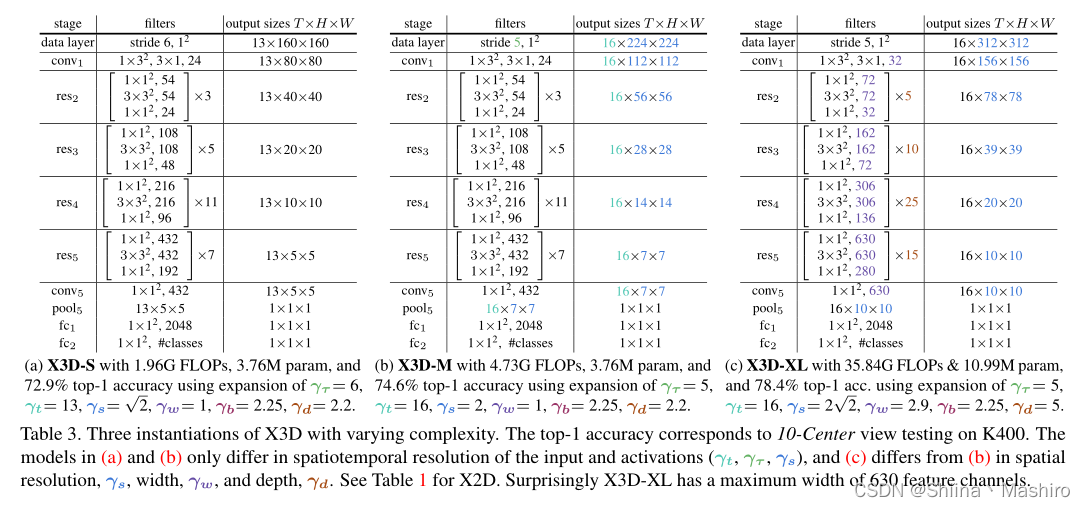
从上图可以观察,X3D-S只是X3D-M的低时空分辨率版本,X3D-XL相对X3D-M,扩张了空间分辨率和宽度。
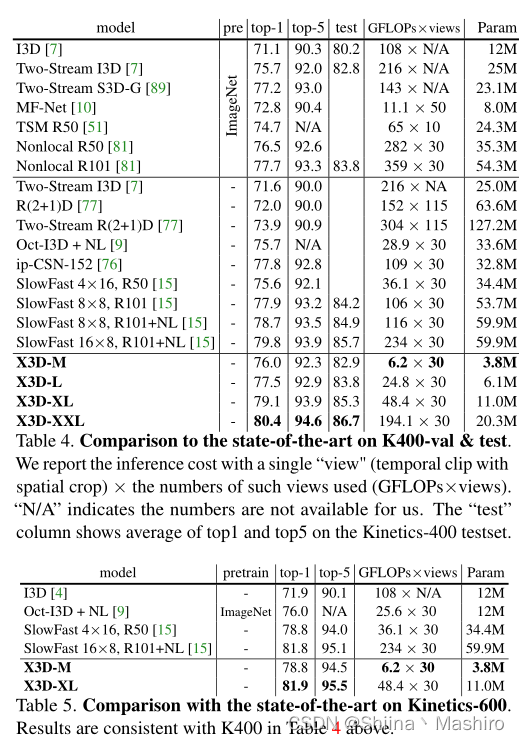
在test集上的准确率为top-1与top-5的平均值,可以看到,X3D-XL与SlowFast接近,但后者FLOPS为前者的4.8倍,参数为5.5倍,其他规格的X3D与相同准确率的模型比,FLOPs和参数量都少得可怕,X3D-XXL更是达到了80.4%
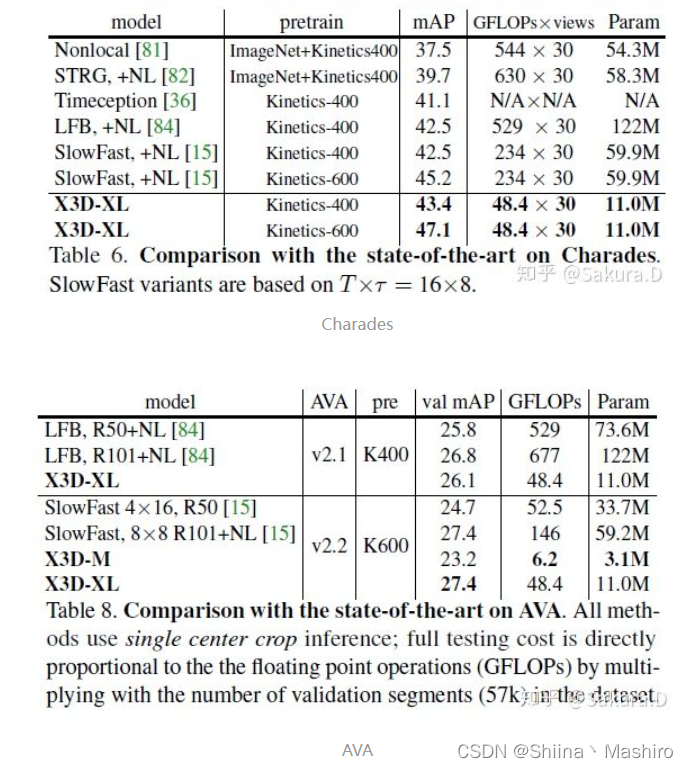
在Charades和AVA上同样有很好的效果。
消融实验
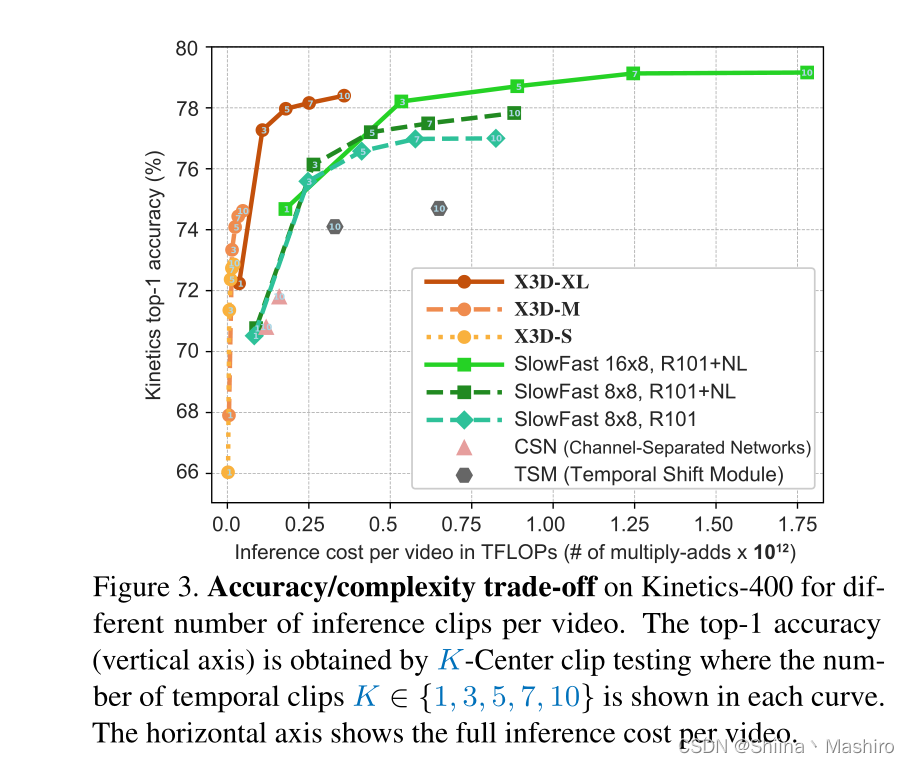
作者实验发现3clips与1clip相比准确率涨幅巨大,因为3clips包括了开始、中间和结束的部分,而1clip只包括中间的部分,而超过3clip增长缓慢,说明在不追求最高精度的前提下,稀疏clip采样策略更有效。
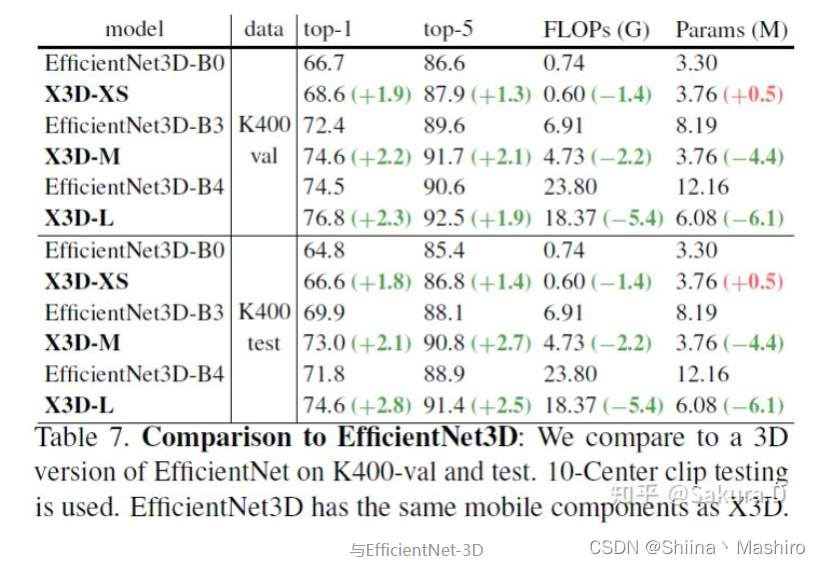
与EfficientNet-3D相比更高效。
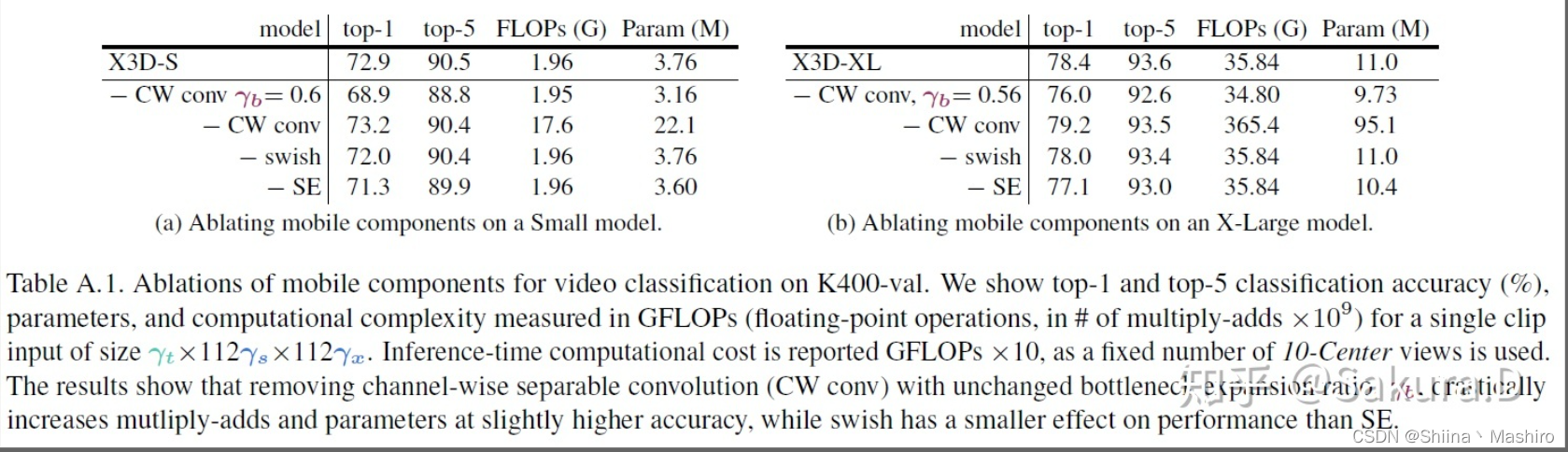
其次,作者探究的channel-wise卷积、swish激活函数以及SE block的作用。
探究CW Conv的时候有两种变体,一是替换回普通的卷积,同时减小bottleneck的宽度扩张比例保证近似的FLOPs和参数,二是直接替换回普通的卷积。可以看到相同FLOPs下CW Conv的影响明显,说明可分离卷积对轻量模型十分重要,再者,保持相同bottleneck宽度,普通的卷积效果更好,但相应的计算量巨大。
其次可以发现,swish的作用比较微弱,如要考虑内存开销可以使用inplace的ReLU。
最后,SE的作用显著,对轻量视频行为识别模型不可或缺。
三、结论
在良好的计算/精度权衡下,考虑扩展空间、时间、宽度和深度的多个候选轴,具有薄通道尺寸和高时空分辨率的网络可以有效地用于视频识别。

















 2983
2983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









