







ViTGAN是加州大学圣迭戈分校与 Google Research提出的一种用视觉Transformer来训练GAN的模型。该论文已被NIPS(Conference and Workshop on Neural Information Processing Systems,计算机人工智能领域A类会议)录用,文章发表于2021年10月。
论文地址:https://arxiv.org/abs/2107.04589
代码地址:https://github.com/teodorToshkov/ViTGAN-pytorch
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
最近,Vision Transformer(VIT)在图像识别方面表现出了竞争性的性能,同时需要更少的视觉特定感应偏差。在本文中,我们研究这种观察是否可以扩展到图像生成。为此,我们将ViT体系结构集成到生成性对抗网络(GAN)中。我们观察到,现有的GANs正则化方法与自我注意的交互作用很差,导致训练期间严重不稳定。为了解决这个问题,我们引入了新的正则化技术,用ViTs训练GANs。根据经验,我们的方法名为ViTGAN,在CIFAR-10、CelebA和LSUN卧室数据集上实现了与基于CNN的最先进StyleGAN2相当的性能
二、为什么提出ViTGAN?
2021年论文《An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR,2021.》视觉Transformer(简称ViT) 在图像识别方面表现出具有竞争力的性能,在ViTGAN中,主要研究的是是否能用Transformer来进行图像生成。研究议题是:不使用卷积或池化,能否使用视觉 Transformer 来完成图像生成任务?更具体而言:能否使用 ViT 来训练生成对抗网络(GAN)并使之达到与已被广泛研究过的基于 CNN 的 GAN 相媲美的质量?
使用原始Vit来组建GAN时,训练非常不稳定,而且在鉴别器训练的后期,对抗性训练经常受到高方差梯度的阻碍,此外,传统的正则化方法,如梯度惩罚,谱归一化无法解决这个不稳定性问题。针对这些问题,为了实现训练动态的稳定以及促进基于 ViT 的 GAN 的收敛,这篇论文提出了多项必需的修改。
以往的生成性Transformer将图像生成建模为一个自回归序列学习问题。与ViTGAN比较接近的工作就是TransGAN,TransGAN提出多任务协同训练和局部初始化以获得更好的训练,但却忽略了训练稳定性的关键技术,在很大程度上落后于领先的卷积GAN模型。
三、Vision Transformer
Vision Transformer是一种纯Transformer架构,用于对一系列图像块进行操作的图像分类。
在ViT中, x ∈ R H × W × C \mathbf{x} \in \mathbb{R}^{H \times W \times C} x∈RH×W×C被展平为一系列patches,每个patch为 x p ∈ R L × ( P 2 ⋅ C ) \mathbf{x}_{p} \in \mathbb{R}^{L \times\left(P^{2} \cdot C\right)} xp∈RL×(P2⋅C),其中 L = H × W P 2 L=\frac{H \times W}{P^{2}} L=P2H×W,P×P×C是每个图像块的尺寸。
图像序列中引入一个可学习的分类嵌入
x
c
l
a
s
s
x_{class}
xclass,已经位置嵌入
E
p
o
E_{po}
Epo,形成patch嵌入
h
0
h_0
h0:
h
0
=
[
x
class
;
x
p
1
E
;
x
p
2
E
;
⋯
;
x
p
L
E
]
+
E
p
o
s
,
E
∈
R
(
P
2
⋅
C
)
×
D
,
E
p
o
s
∈
R
(
L
+
1
)
×
D
h
ℓ
′
=
MSA
(
LN
(
h
ℓ
−
1
)
)
+
h
ℓ
−
1
,
ℓ
=
1
,
…
,
L
h
ℓ
=
MLP
(
LN
(
h
ℓ
′
)
)
+
h
ℓ
′
,
ℓ
=
1
,
…
,
L
y
=
LN
(
h
L
0
)
\begin{aligned} \mathbf{h}_{0} &=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{L} \mathbf{E}\right]+\mathbf{E}_{p o s}, & & \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{p o s} \in \mathbb{R}^{(L+1) \times D} \\ \mathbf{h}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{h}_{\ell-1}\right)\right)+\mathbf{h}_{\ell-1}, & & \ell=1, \ldots, L \\ \mathbf{h}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{h}_{\ell}^{\prime}\right)\right)+\mathbf{h}_{\ell}^{\prime}, & & \ell=1, \ldots, L \\ \mathbf{y} &=\operatorname{LN}\left(\mathbf{h}_{L}^{0}\right) & & \end{aligned}
h0hℓ′hℓy=[xclass ;xp1E;xp2E;⋯;xpLE]+Epos,=MSA(LN(hℓ−1))+hℓ−1,=MLP(LN(hℓ′))+hℓ′,=LN(hL0)E∈R(P2⋅C)×D,Epos∈R(L+1)×Dℓ=1,…,Lℓ=1,…,L
其中,MSA是多头自注意力(MSA):
MSA
(
X
)
=
concat
h
=
1
H
[
Attention
h
(
X
)
]
W
+
b
\operatorname{MSA}(\mathbf{X})=\operatorname{concat}_{h=1}^{H}\left[\operatorname{Attention}_{h}(\mathbf{X})\right] \mathbf{W}+\mathbf{b}
MSA(X)=concath=1H[Attentionh(X)]W+b
单个注意力头的计算公式为:
Attention
h
(
X
)
=
softmax
(
Q
K
⊤
d
h
)
V
\operatorname{Attention}_{h}(\mathbf{X})=\operatorname{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d_{h}}}\right) \mathbf{V}
Attentionh(X)=softmax(dhQK⊤)V
四、ViTGAN
ViTGAN的基础结构如下,一个ViT组成了生成器,一个ViT组成了鉴别器:
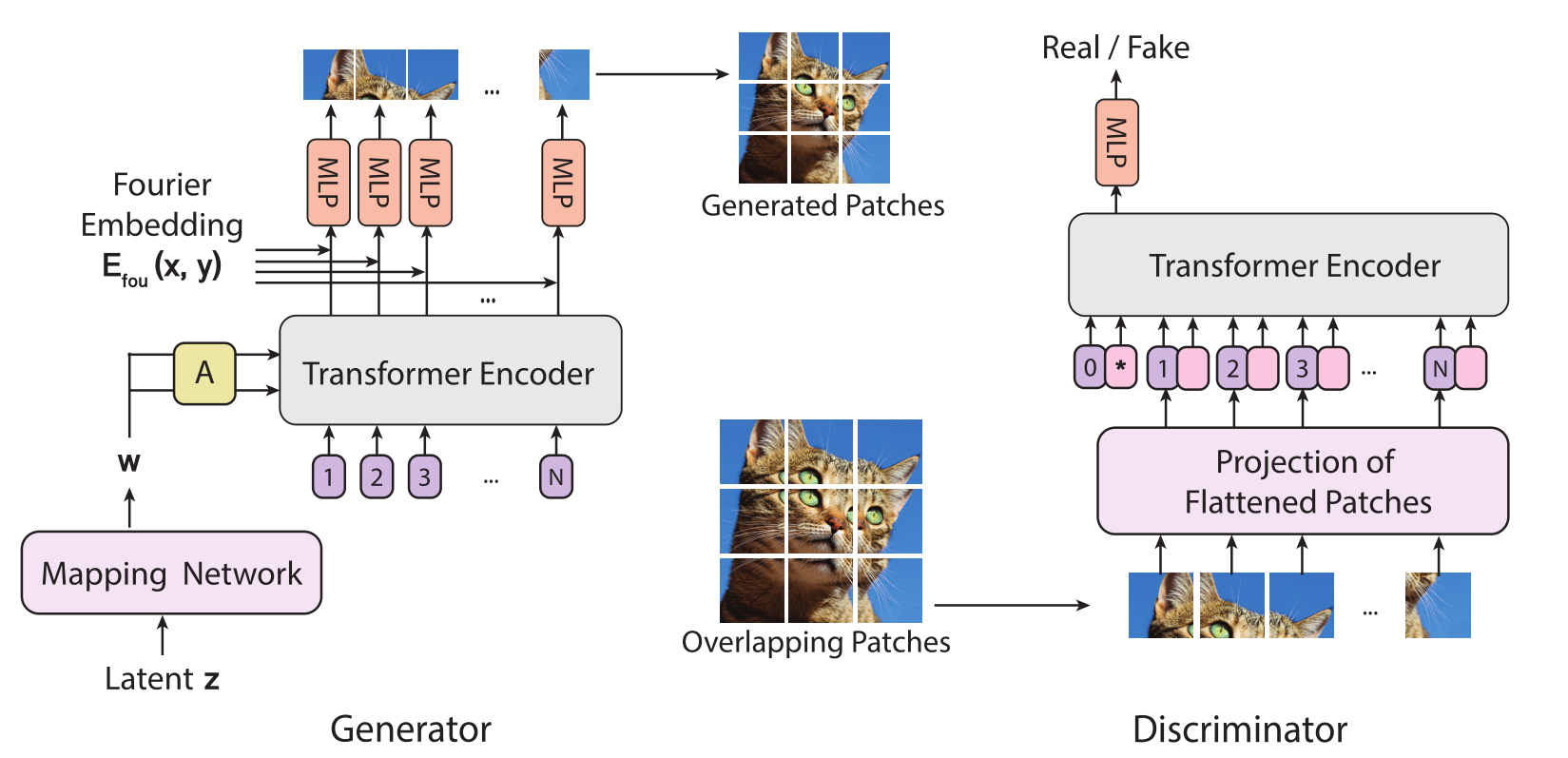
直接使用ViT会使训练不稳定,于是作者引入了(1)生成器结构优化;(2)鉴别器正则化
4.1、生成器
因为ViT(Vision Transformer)原来是对图片进行分类,预测标签,而ViTGAN想达到的是让其能在空间区域生成像素。
作者为此比较了三种Transformer做生成器的架构,输入为 由MLP从高斯噪声向量z 导出的潜在向量w
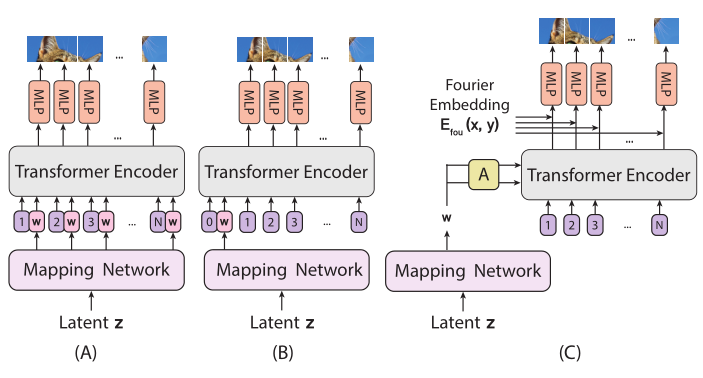
(A):在每个位置嵌入中加入中间潜在嵌入w,然后经过Transformer和一层MLP分别指导不同patch块的像素生成
(B):只在序列最开始加入中间潜在嵌入w
(C):将归一化Norm层替换为自调制层(SLN),该自调制层如下所示,其使用从w中学到的仿射变换(A)对norm层进行调整。
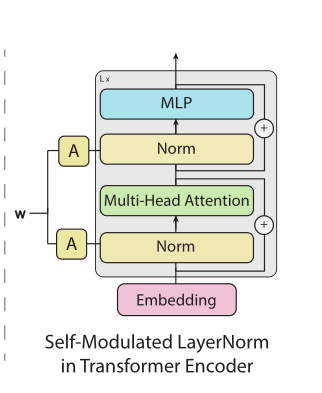
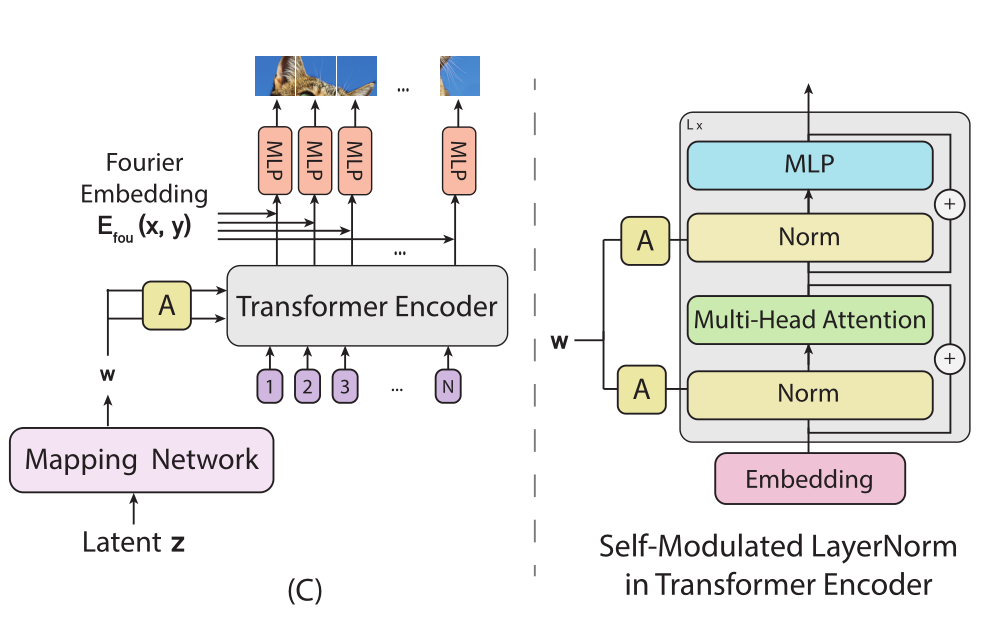
作者使用的是C,下面将对其结构和原理进行剖析:
4.1.1、生成器设计
要用Transformer生成像素值,就要使用一个线性投影层E,其将输入的D维嵌入映射到每个大小为P×P×C的patch当中,然后每个patch(一共(H*W)/P² 个patch)最终重组成一整张图像。
于是基于ViT设计的生成器由两个组件组成:(1)Transformer块;(2)输出映射层。
如下图所示,Transformer块作为编码器,主体结构如下右所示,将Embedding经过Norm、多头注意力层、Norm和MLP后输出到输出映射层,输出映射层主要是一个MLP。
计算原理如下:
h
0
=
E
pos
,
E
pos
∈
R
L
×
D
,
h
ℓ
′
=
MSA
(
SLN
(
h
ℓ
−
1
,
w
)
)
+
h
ℓ
−
1
,
ℓ
=
1
,
…
,
L
,
w
∈
R
D
h
ℓ
=
MLP
(
SLN
(
h
ℓ
′
,
w
)
)
+
h
ℓ
′
,
ℓ
=
1
,
…
,
L
y
=
SLN
(
h
L
,
w
)
=
[
y
1
,
⋯
,
y
L
]
y
1
,
…
,
y
L
∈
R
D
x
=
[
x
p
1
,
⋯
,
x
p
L
]
=
[
f
θ
(
E
f
o
u
,
y
1
)
,
…
,
f
θ
(
E
f
o
u
,
y
L
)
]
x
p
i
∈
R
P
2
×
C
,
x
∈
R
H
×
W
×
C
\begin{aligned} \mathbf{h}_{0} &=\mathbf{E}_{\text {pos }}, & & \mathbf{E}_{\text {pos }} \in \mathbb{R}^{L \times D}, \\ \mathbf{h}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{SLN}\left(\mathbf{h}_{\ell-1}, \mathbf{w}\right)\right)+\mathbf{h}_{\ell-1}, & & \ell=1, \ldots, L, \mathbf{w} \in \mathbb{R}^{D} \\ \mathbf{h}_{\ell} &=\operatorname{MLP}\left(\operatorname{SLN}\left(\mathbf{h}_{\ell}^{\prime}, \mathbf{w}\right)\right)+\mathbf{h}_{\ell}^{\prime}, & & \ell=1, \ldots, L \\ \mathbf{y} &=\operatorname{SLN}\left(\mathbf{h}_{L}, \mathbf{w}\right)=\left[\mathbf{y}^{1}, \cdots, \mathbf{y}^{L}\right] & \mathbf{y}^{1}, \ldots, \mathbf{y}^{L} \in \mathbb{R}^{D} \\ \mathbf{x} &=\left[\mathbf{x}_{p}^{1}, \cdots, \mathbf{x}_{p}^{L}\right]=\left[f_{\theta}\left(\mathbf{E}_{f o u}, \mathbf{y}^{1}\right), \ldots, f_{\theta}\left(\mathbf{E}_{f o u}, \mathbf{y}^{L}\right)\right] & & \mathbf{x}_{p}^{i} \in \mathbb{R}^{P^{2} \times C}, \mathbf{x} \in \mathbb{R}^{H \times W \times C} \end{aligned}
h0hℓ′hℓyx=Epos ,=MSA(SLN(hℓ−1,w))+hℓ−1,=MLP(SLN(hℓ′,w))+hℓ′,=SLN(hL,w)=[y1,⋯,yL]=[xp1,⋯,xpL]=[fθ(Efou,y1),…,fθ(Efou,yL)]y1,…,yL∈RDEpos ∈RL×D,ℓ=1,…,L,w∈RDℓ=1,…,Lxpi∈RP2×C,x∈RH×W×C
4.1.2、 自调制层归一化层(SLN)
自调制是指:不使用噪声z作为输入,而是使用z来调制LayerNorm运算:
SLN
(
h
ℓ
,
w
)
=
SLN
(
h
ℓ
,
MLP
(
z
)
)
=
γ
ℓ
(
w
)
⊙
h
ℓ
−
μ
σ
+
β
ℓ
(
w
)
\operatorname{SLN}\left(\mathbf{h}_{\ell}, \mathbf{w}\right)=\operatorname{SLN}\left(\mathbf{h}_{\ell}, \operatorname{MLP}(\mathbf{z})\right)=\gamma_{\ell}(\mathbf{w}) \odot \frac{\mathbf{h}_{\ell}-\boldsymbol{\mu}}{\boldsymbol{\sigma}}+\beta_{\ell}(\mathbf{w})
SLN(hℓ,w)=SLN(hℓ,MLP(z))=γℓ(w)⊙σhℓ−μ+βℓ(w)
其中µ和σ表示的是总输入的均值和方差,γl和βl表示的是计算由z导出的潜在向量控制的自适应归一化参数。
4.1.3、隐式神经表征生成patch片图像
使用隐式神经表示学习从patch embedding y i y^i yi到patch pixel x p i x^i_p xpi的映射。当与傅里叶特征或正弦激活函数结合时,隐式表示可以将生成样本的空间限制为平滑变化的自然信号的空间,在式子中表示为 E f o u E_{fou} Efou是空间位置的傅里叶编码, f θ f_θ fθ是两层MLP。
4.2、鉴别器设计
鉴别器暂略,详情可以看原文
五、实验
5.1、数据集
CIFAR-10 、LSUN bedroom、CelebA
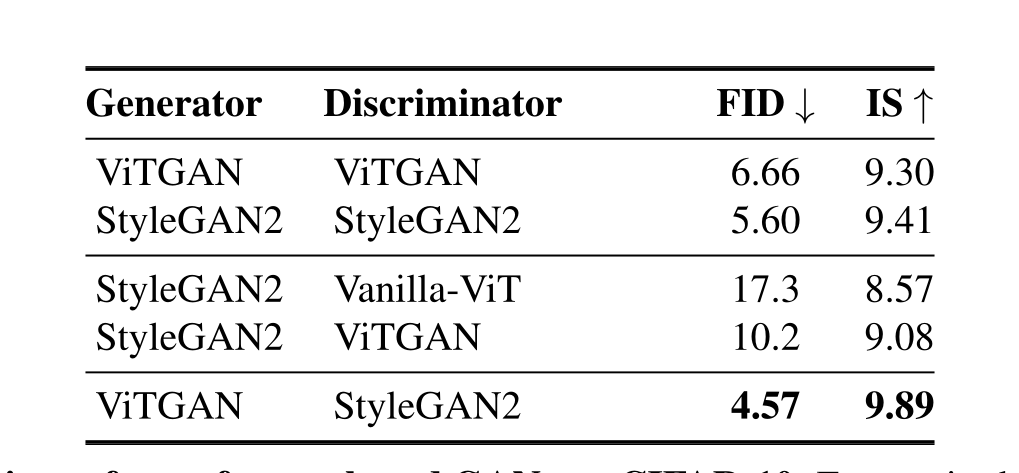
5.2、实验结果


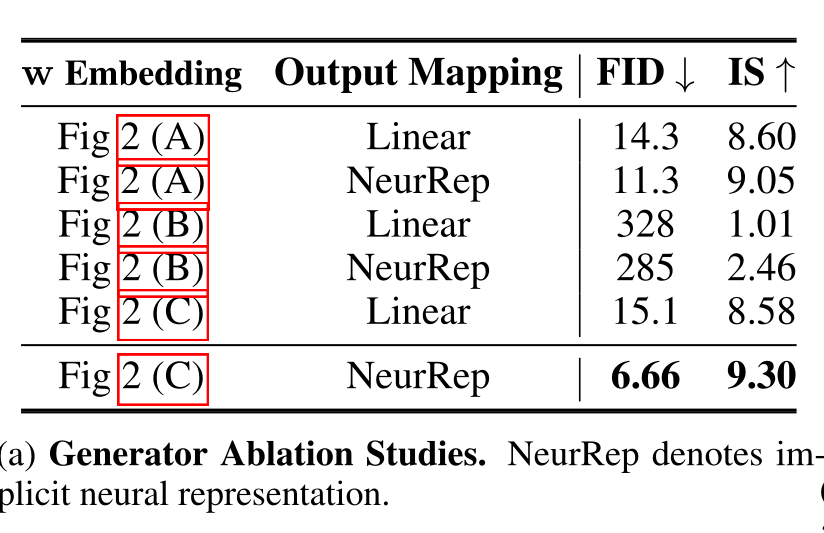
5.3、消融实验
六、总结
- 在GANs中利用了vision transformer,并提出了确保其训练稳定性和改进其收敛性的关键技术;
- 经过丰富的实验证明其与基于CNN的最先进的GANs性能相当。
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝



















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











