






微调大型语言模型(LLMs)已经彻底改变了自然语言处理(NLP),为语言翻译、情感分析和文本生成等任务提供了前所未有的能力。这种变革性的方法利用了像GPT-2这样的预训练模型,通过微调过程提升了它们在特定领域的表现。
在过去的一年半时间里,由于大型语言模型(LLMs)的普及,自然语言处理(NLP)领域经历了显著的转变。这些模型呈现的自然语言技能使得几年前看起来不可能实现的应用成为可能。LLMs正在改变边界,其能力范围从语言翻译到情感分析和文本生成。然而,我们都知道训练这类模型既耗时又昂贵。这就是为什么微调大型语言模型对于定制这些高级算法以满足特定任务或领域非常重要。这个过程增强了模型在专业任务上的表现,并显著扩大了它在各个领域的适用性。这意味着我们可以利用预训练的自然语言处理能力的LLMs,并进一步训练它们来执行我们的特定任务。今天,让我们探索预训练语言模型的精髓,并进一步深入了解微调过程:通过使用Hugging Face微调GPT-2模型的上手步骤。
预训练语言模型的工作原理
语言模型(Language Model或LM)是一种AI算法,它通过分析句子中已有的部分来预测接下来的单词。这种模型通常基于Transformer架构,例如GPT(生成式预训练变换器),它在大量文本数据上进行预训练。通过这样的训练,大型语言模型(LLMs)能够学习并掌握单词使用的上下文和自然语言的排列规则,从而在生成文本时更加流畅和准确。

图示:LLM的输入和输出
最重要的是,这些模型不仅擅长理解自然语言,而且擅长根据它们接收的输入生成文本。
什么是微调,它为什么重要?
微调是采用预训练模型并在特定领域的数据集上进一步训练它的过程。今天大多数LLM模型在通用性能上表现优异,但在特定的任务导向问题上却表现不佳。微调具备显著优势,包括降低计算开销和能够在不从头开始建模的情况下利用现有的先进模型。Transformer提供了广泛的预训练模型,适用于各种任务。微调这些模型是提高模型执行特定任务(如情感分析、问答或文档摘要)能力的关键步骤,确保更高的准确性。
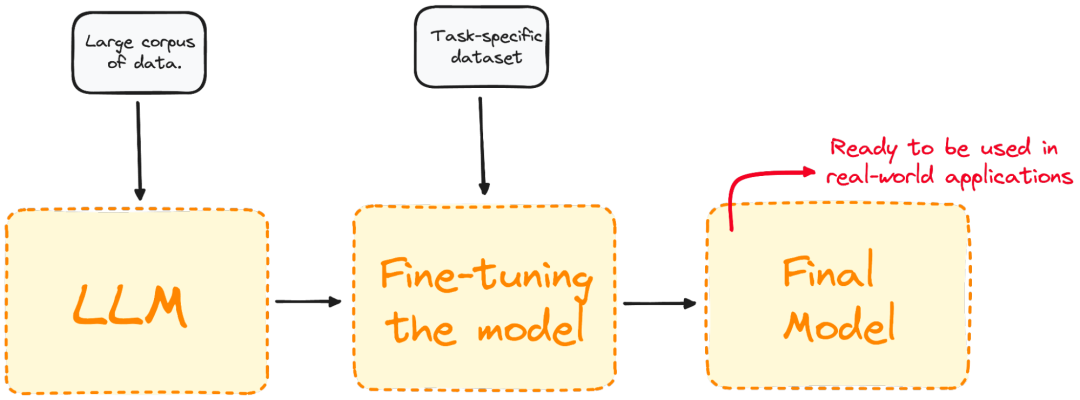
图示:可视化微调过程
微调优化了模型在特定任务上的表现,增强其在实际应用中的有效性和适用性。这一步骤对于定制化现有模型,以满足特定任务或领域的需求至关重要。
微调的几种方法
微调可以根据其核心关注点和特定目标,采用以下几种方法来进行。
监督式微调 最直接且常见的微调方法。在这种方法中,模型使用针对目标任务(例如文本分类或命名实体识别)的标注数据集进行进一步的训练。例如,我们将在包含已标注情感的文本样本的数据集上训练我们的模型,以进行情感分析。
少样本学习 在某些情况下,收集大量标注数据集是不切实际的。为解决这个问题,少样本学习尝试在提示词的开头提供一些示例。这有助于模型更好地理解任务的背景,而无需进行大量的微调。
迁移学习 尽管所有微调技术都是一种迁移学习,但这一类技术的具体目标是让模型能够执行与最初训练任务不同的任务。其主要思路是利用模型从大型通用数据集中获得的知识,将其应用到更具体或相关的任务中。
领域特定微调 这类模型微调微目的在于使其能够理解和生成特定领域或行业的文本。在由目标领域文本组成的数据集上对模型进行微调,以改进其语境和特定领域任务的知识。例如,要为医疗应用程序生成聊天机器人,模型将使用医疗记录进行训练,使其语言理解能力适应健康领域。
微调LLM的步骤
微调是将预先训练好的模型,通过在特定任务的数据集上进行训练来更新其参数的过程。让我们通过微调一个真实的模型来举例说明这一概念。假设我们正在使用GPT-2,但我们发现它在推断文本的情感方面表现不佳。我们自然会想到做些什么来提高它的准确性。
我们可以利用微调的优势,通过使用包含推文及其对应情感的数据集来训练从Hugging Face模型库中预训练的GPT-2模型,以此提升性能。以下是一个微调模型的基本示例:
第1步:选择预训练模型和数据集
要微调模型,我们需要有一个预先训练好的模型。在本例中,我们将使用 GPT-2 进行一些简单的微调。
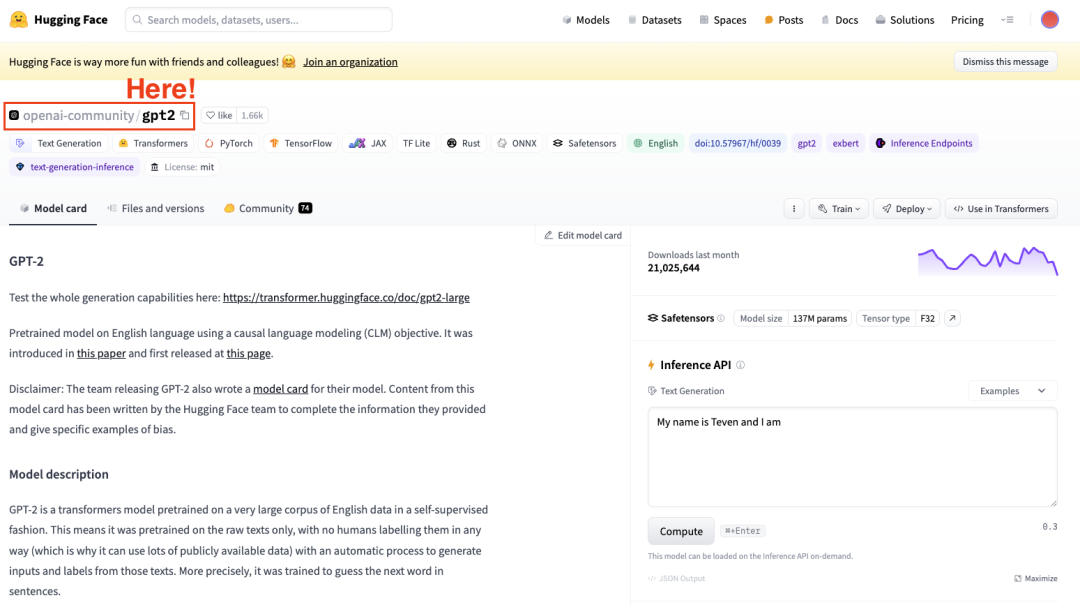
Hugging Face数据集中心的截图,选择OpenAI的GPT2模型。
第2步:加载要使用的数据
现在我们有了模型,我们需要一些高质量的数据来使用,这正是数据集库的用武之地。在本例中,我将使用Hugging Face数据集库导入一个包含按情感(积极、中立或消极)分割的文本的数据集。
from datasets import load_datasetdataset = load_dataset("mteb/tweet_sentiment_extraction")df = pd.DataFrame(dataset['train'])
如果我们查看刚刚下载的数据集,它是一个包含训练集和测试集的数据集。如果我们将训练子集转换为DataFrame,如下图所示:

图示:数据集
第3步:分词器 (Tokenizer)
既然我们已经获取了数据集,接下来是使用分词器(Tokenizer)来处理数据,以便它们能够被我们的模型正确解析。在 LLM 使用tokens时,我们需要一个分词器(Tokenizer)来处理数据集。若要一步处理数据集,可使用“数据集映射”方法对整个数据集应用预处理函数。这就是为什么要在第二步加载预先训练好的分词器(Tokenizer),并对数据集进行标记化处理,以便进行微调。
from transformers import GPT2Tokenizer# Loading the dataset to train our modeldataset = load_dataset("mteb/tweet_sentiment_extraction")tokenizer = GPT2Tokenizer.from_pretrained("gpt2")tokenizer.pad_token = tokenizer.eos_tokendef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
补充:为了提高处理要求,我们可以从完整数据集中创建一个较小的子集来微调我们的模型。训练集将用于微调模型,而测试集将用于评估模型。
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
第4步:初始化基础模型
首先加载模型并指定预期的标签数量。从情感数据集卡中,我们知道有三个标签:
from transformers import GPT2ForSequenceClassificationmodel = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)
第5步:评估方法
Transformers提供了一个优化训练的Trainer类。然而,这种方法不包括如何评估模型。这就是为什么,在开始训练之前,我们需要向Trainer传递一个函数来评估我们的模型性能。
import evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)
第6步:使用Trainer方法进行微调
我们的最后一步是设置训练参数并启动训练过程。Transformers库包含了Trainer类,它支持广泛的训练选项和特性,例如日志记录、梯度累积和混合精度。我们首先定义训练参数以及评估策略。一旦所有内容都定义好了,我们可以简单地使用train()命令来训练模型。
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(output_dir="test_trainer",#evaluation_strategy="epoch",per_device_train_batch_size=1, # Reduce batch size hereper_device_eval_batch_size=1, # Optionally, reduce for evaluation as wellgradient_accumulation_steps=4)trainer = Trainer(model=model,args=training_args,train_dataset=small_train_dataset,eval_dataset=small_eval_dataset,compute_metrics=compute_metrics,)trainer.train()
训练完成后,在验证集或测试集上评估模型的性能。同样,Trainer类已经包含了一个评估方法来处理这一点。
import evaluatetrainer.evaluate()
以上是对任何LLM微调的最基本步骤。记住,微调LLM对算力要求很高,请确保本地计算机具备足够的算力来完成这项任务。
微调最佳实践
为确保微调成功,请参考以下最佳实践:
数据质量和数量 微调数据集的质量在很大程度上决定了模型的性能。正如我们常说的:“Garbage In, Garbage Out”,因此,请始终确保数据是清洁、相关且规模足够。
超参数调整 超参数调整是微调过程中的关键步骤,这个过程通常需要多次迭代。您应该持续探索不同的学习率、批量大小和训练周期的组合,以便为您的项目找到最优的配置。精确调整是确保模型高效学习和适应未知数据的关键,可避免过度拟合的陷阱。
定期评估 定期评估模型在训练过程中的表现,以监控其有效性并根据需要进行调整。这涉及到在训练的不同阶段使用不同的验证数据集来评估模型的性能。
这种持续的评估对于了解模型在特定任务上的表现以及评估其过度拟合训练数据集的风险至关重要。基于验证阶段的反馈,可以适时调整模型参数或训练策略,以提升模型性能。
避免LLM微调陷阱
微调有时会导致次优结果。请警惕以下陷阱:
过拟合 可能发生在使用较小的数据集进行训练,或者训练周期(epochs)过多的情况下。这种情况下,模型可能在训练数据上表现出高准确率,但却难以在新的、未见过的数据上实现良好的泛化。
欠拟合 相反,训练不足或学习率过低可能导致欠拟合,模型无法充分学习任务。
灾难性遗忘 灾难性遗忘是一个在微调特定任务时可能出现的问题,其中模型可能会丧失其最初获得的广泛知识。这种现象会削弱模型在执行自然语言处理任务时的性能。
数据泄露 始终确保训练和验证数据集是分开的,并且没有重叠,因为数据泄露可能会给出误导性的高评价指标。
微调 vs RAG
RAG(检索增强)结合了基于检索的模型和生成模型的优势。在RAG中,检索器组件搜索大型数据库或知识库,根据输入查询查找相关信息。然后由生成模型使用这些检索到的信息产生更准确和上下文相关的响应。RAG的主优势包括:
-
动态知识整合:整合来自外部来源的实时信息,适合需要最新或特定知识的任务。
-
上下文相关性:通过提供检索文档的额外上下文,增强生成模型的响应。
-
多功能性:可以处理更广泛的查询,包括需要特定或罕见信息的查询,这些信息模型可能没有接受过训练。
在微调和RAG之间进行选择
在决定使用微调还是RAG时,请考虑以下因素:
-
任务性质:对于从高度专业化模型中受益的任务(例如,特定领域的应用),微调通常是首选方法。RAG适合需要整合外部知识或实时信息检索的任务。
-
数据可用性:微调需要大量与任务相关的标注数据。如果这类数据不足,RAG的检索组件可以通过外部来源获取相关信息来弥补。
-
资源限制:微调可能是计算密集型的任务,而RAG模型能够利用现有的数据库来增强生成模型,这样可以降低对大规模训练资源的需求。
灵雀云AML降低模型微调门槛
启动LLM的微调之旅为AI应用开启了一个充满可能性的新世界。通过深入理解并应用所概述的概念、实践和预防措施,我们可以有效地调整这些强大的模型以满足特定的需求,从而在整个过程中充分发挥它们的潜力。
在即将发布的灵雀云 AML v1.1 版本中,新增模型微调、模型训练的核心功能,不需要编写代码即可完成模型微调,并且该版本支持 LoRA 部分微调和分布式DDP微调。用户仅需在界面选择好预训练模型和数据集,即可启动微调任务,并实时监控训练任务的收敛状态!
此外, AML 1.1 版本将集成 Dify 并提供对AML 平台发布的 LLM 推理服务的访问能力。借助这一功能,用户可以利用 AML 的 LLM 与 Dify 快速构建自己的 LLM 微调和检索增强生成(RAG)应用。















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









