






✍🏻 本文作者:顾知、岁星、天扉、佳玏、允行
一、背景
随着生成式技术浪潮的兴起,Stable Diffusion结合Controlnet等控制能力在电商场景得到了广泛的应用,其中制作一张优秀的商品主图(亦或是广告的创意图,以下简称商品图)对商品的点击转化有着重要影响,商家往往需要投入不少时间和资金成本。如何通过AIGC能力来帮助商家节省成本、提高制作效率和投放效果是阿里妈妈万相实验室的初衷。
随着2023年7月SDXL文生图模型的发布,其生成结果相比SD1.5在语义表达和美观度上都有显著提升。但模型参数规模的大幅增长也带来了在训练和推理上的挑战。我们围绕SDXL模型进行了多角度效果优化以及推理加速优化,并且将其应用于万相实验室图像生成任务中,实现了全量上线。生成结果的视觉质量以及业务指标都有不错提升。部分相关工作沉淀到开源项目EcomXL(huggingface-ecomxl-controlnet)和SLAM (Sub-path Linear Approximation Model, huggingface-slam),欢迎交流&提出建议。
🔗 HuggingFace 项目链接(复制链接到浏览器访问):
EcomXL: https://huggingface.co/collections/alimama-creative/ecomxl-controlnet-662f1f0dac05b4f7c20fcde6
SLAM: https://huggingface.co/collections/alimama-creative/slam-662f1dd31d5c8cd0b3acb0e0
本篇工作更多从SDXL模型应用视角,阐述将其落地到规模化图像生成系统中遇到的效果和推理速度问题。在AIGC图像生成中,如何实现对生成结果更加可控请参考另一篇团队工作《百变背景:万相实验室AIGC电商图片可控生成技术》。
二、万相实验室简介
阿里妈妈万相实验室(https://agi.taobao.com)是面向商家/广告主建设的 Al Native 商品图片生成工具。它提供商品展示图片和服饰展示图片两项基本服务,支持通过丰富的虚拟模特、背景氛围实现商品的生动展示。平台内置海量商品预设背景描述可供选择和再次创作,商品的布局和大小可以精细调节,画面可以增加背景元素组合,虚拟模特的发型肤色身材搭配着装均可选择。
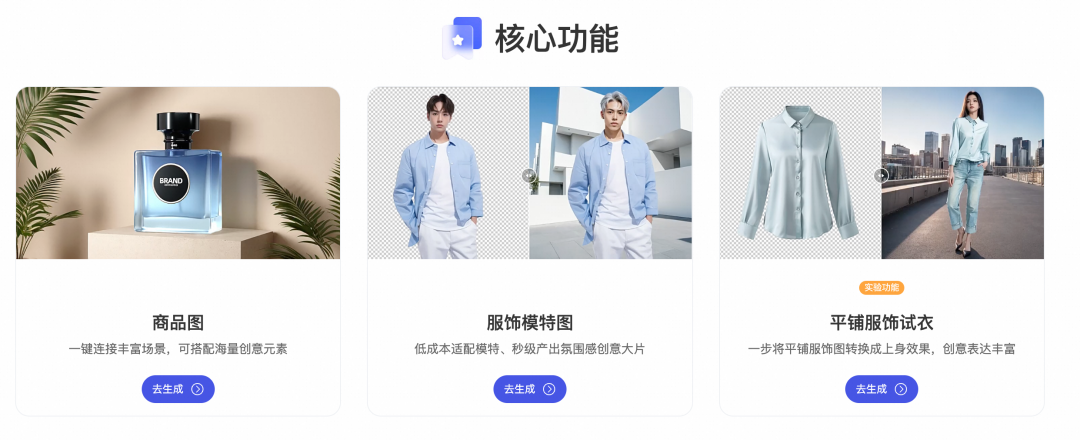
面向电商ToB的场景应用,我们可以将淘宝平台商品分为普通刚性商品和柔性服饰,前者是外观相对固定的商品,后者是外观多变且与人物交互的服饰。具体在以下几个方面体现对其生成效果的更高要求:(1)美观和真实的人像生成 (2)电商风格的背景生成 (3)自然贴切的商品与背景融合效果 (4)不同场景不同时延的服务能力。对应这些问题,我们提出面向电商场景的EcomXL系列工作,旨在在对社区SDXL的基础上实现更佳人物和背景绘画效果、更佳的Controlnet控制能力以及快速3秒电商生图方案。
三、EcomXL文生图模型
3.1 问题定义
尽管SDXL模型与SD1.5相比,在语义理解和视觉美感方面进步显著,但是在电商场景中应用对人像颜值和真实性,以及对电商风格背景的多样性提出更高的要求,因此人像不够美不够真、背景不够贴近电商场景是效果上的主要挑战。其次,在电商图像生成中,往往耦合了生成控制(例如:Controlnet/Lora),基础模型的变化进一步带来和生态适配性的问题。

3.2 模型优化

我们基于社区开源的数据以及内部数据,收集了千万规模的高质量人像和背景数据,用于补充SDXL模型在电商生成图像的质量。现有的一些工作如Dalle3 [1],pixart [2],EMU [3]等指出,详细准确的图像描述和高美观图像的筛选对模型最终的效果至关重要。因此,我们制定了机筛加人筛的数据筛选策略,并运用多模态大模型对其进行精细文本标签打标,在少量数据上进行了人工标签修正。以下是数据示意:

在具体的基础模型迭代中,我们提出了一个两阶段模型微调方法,通过模型微调和模型融合使得EcomXL在适配电商场景的同时,可以较好的保持SDXL优秀的语义理解能力,同时保持对社区生态的兼容性。
3.2.1 模型微调 - 去噪步数加权的蒸馏法
全参数模型微调带来的挑战是语义退化以及链路适配的问题。相比于基础模型本身通过亿级别的图文对训练,在少量数据上直接进行微调,虽然在微调样本上表现良好,但是泛化性下降,特别是体现在语义退化上。其次,全参数微调也会下降社区Controlnet和微调后基础模型的适配性。
为缓解上述问题,我们前期探索了部分参数微调、可插拔的Lora等等方案,在生成效果和后期迭代便利上都遇到不少挑战。我们提出了一种基于去噪步数加权的蒸馏方法,参考过往学者工作有将信噪比SNR(signal-to-noise ratio)应用于扩散模型加速采样 [4] 和加速训练 [5] 的有效性,我们使用时间步数t的函数作为加权权重,从训练约束的角度对SDXL模型进行微调。该方法在去噪损失函数的基础上加入了一个蒸馏损失,并通过一个参数来控制对总损失函数的贡献度。去噪前期,的值较小,较小,蒸馏损失函数主导总损失函数,使微调模型预测噪声对齐语义良好的原始模型;去噪声后期,SNR增加,蒸馏损失权重不断减小,预测图片分布逐渐对齐微调数据集。
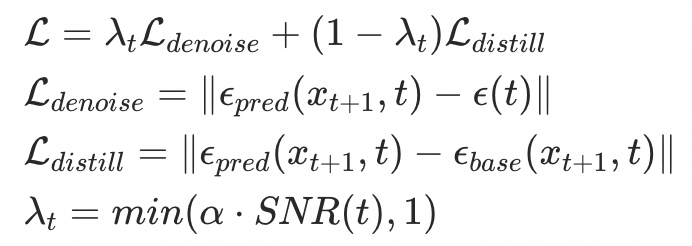
其中,扩散过程中t步的噪声,和为去噪过程中微调模型和原始模型分别预测的t步的噪声。为超参数,用于调节蒸馏强度。
其背后的思考是,去噪过程为coarse-to-fine的过程,初期主要生成的是整体的轮廓与布局,而后期则重点生成细节信息。如人像场景中,去噪前期模型生成身体/发型/背景的大致轮廓,去噪后期则生成面部、服饰等细节。我们的微调任务往往重在后期视觉细节的优化,而尽量保持前期语义理解。
3.2.2 模型融合 - 分层加权融合
为进一步提升微调模型对原始模型社区生态的兼容性,我们采用了模型融合策略,在构建SDXL的影响矩阵基础上,秉持“最大收益-最小改动”原则来进行新老模型的分层融合,在最小改动原始模型权重的基础上,把微调模型优势注入其中。模型融合公式如下:
其中,,和分别表示融合模型、基础模型和微调模型的第层的权重。为第层的融合系数。
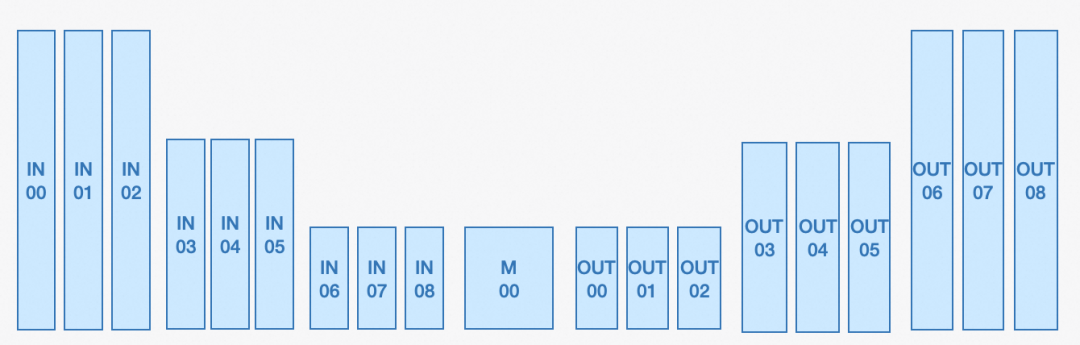
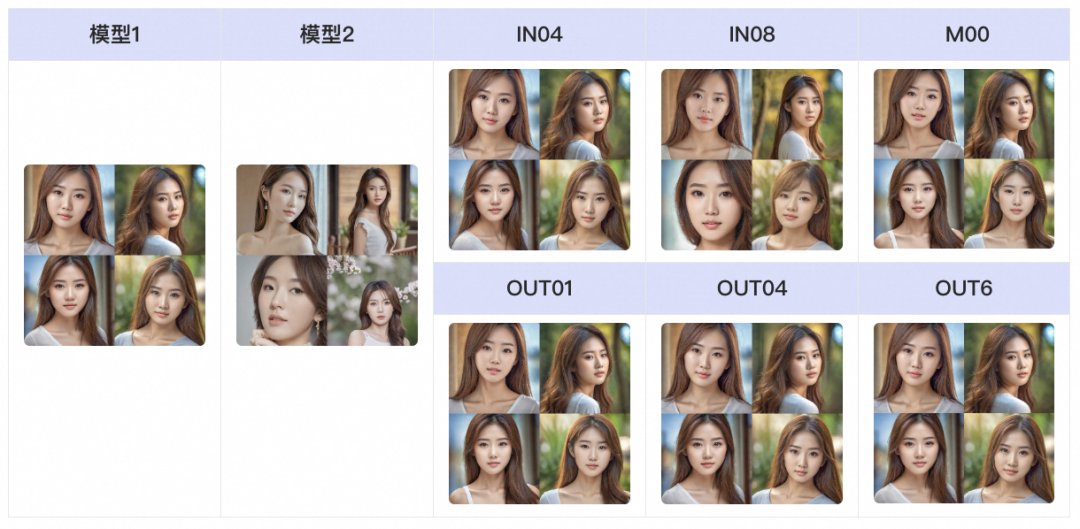
虽然模型融合作为社区解决小样本微调导致过拟合问题的常规手段,但现阶段社区尚缺乏SDXL对生图效果的影响矩阵。对此,为实现更精细融合,我们先对其影响矩阵进行总结。首先根据SDXL UNet结构将层进行归并划分为如上所述19个最小融合单位。随后,通过控制变量法探讨各个层对于生图效果的影响。以人像优化为例,我们将模型1的权重用模型2的对应层权重替换来探寻对于人脸生成影响较大的层。在随后的模型融合中,我们仅对人脸影响较大的层进行权重的加权融合,而其他层维持旧模型的权重。控制变量法的部分可视化结果如下,可见UNet深层 (如IN08、M00、OUT01) 相较于浅层(如IN04)对人脸具有更大影响。
3.2.3 对比效果
EcomXL在适配电商生图的同时,较大程度地保留了原模型的固有优势,其与原始SDXL模型在直接图像生成的效果对比如下:

四、EcomXL-ControlNet
EcomXL还处于在文生图阶段进行基础t2i模型的优化,实际在用户对主体抠图之后还会进行多个控制网络Controlnet的联合生成。联合生成的目标是既能够保持前景真实、又要背景足够丰富、还要前后景良好的融入效果。使用社区开源的SDXL inpainting/softedge Controlnet,在大规模测试之后,我们发现了不少效果上的问题。总结起来可以分为三类:(1)搭配商品图的背景生成;(2)服饰控制下的肢体生成;(3)边缘控制下的元素生成。

为解决以上问题,我们针对电商场景,从淘宝收集了千万级高质量商品数据,利用多模态大模型对其打标,同时进行了实例级别分割、边缘提取等预处理操作。在此基础上,训练了电商版SDXL版Inpainting/Softedge Controlnet,称作EcomXL-ControlNet。
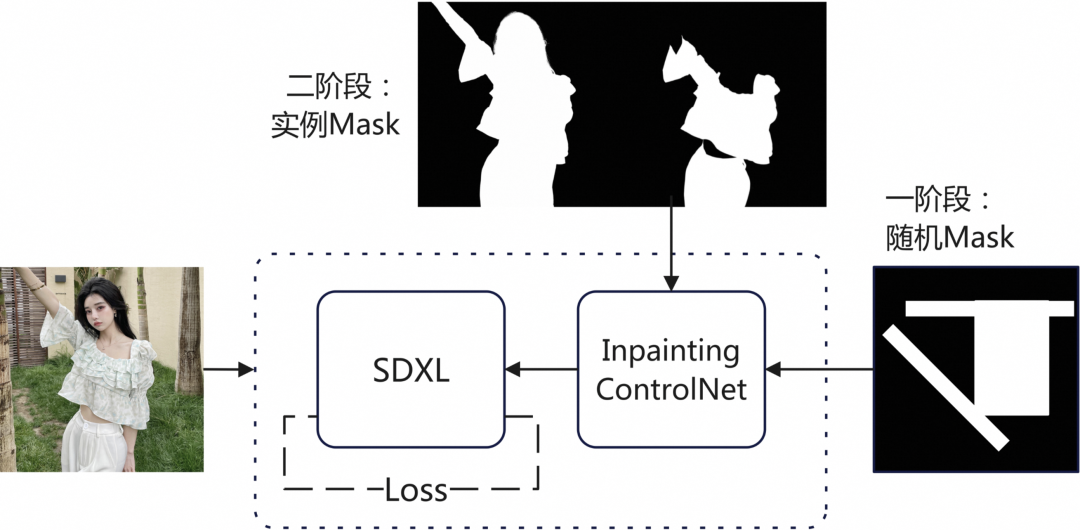
4.1 Inpainting Controlnet
Inpainting ControlNet的作用是进行图像补全:根据图像的已知前景图像,控制基础模型生成其余部分的图像。社区普遍使用随机Mask遮挡图像训练Inpainting ControlNet,使网络学习通用的图像补全能力。而在电商场景下,图像的已知前景通常为商品本身,具有完整的结构,同时待补全的部分通常为背景与模特肢体。我们希望模型能够在根据已知前景图像补全背景的同时,避免对商品本身进行不必要的扩展,降低商品边缘异常等问题的概率。同时,我们还希望模型可以在图像的已知前景为模特、服饰时,补全缺失的人体结构,缓解肢体无法生成与肢体畸形的概率。因此,我们提出了两阶段的Inpainting ControlNet训练方案:
第一阶段:基于通用数据使用随机Mask训练。
第二阶段:基于电商数据使用实例Mask微调,提高了前景维持、背景搭配、肢体生成的能力。
4.2 Softedge ControlNet
Softedge ControlNet的作用是进行边缘控制:根据Softedge边缘图像,控制基础模型生成边缘一致的图像。在电商场景中,Softedge ControlNet除了用来控制商品边缘外,还有着控制搭配元素生成的作用。我们使用了千万级别的高美观度数据训训练了Softedge ControlNet,数据来源包括开源和内部数据集、淘宝电商数据等。相比社区模型在边缘控制,边缘发光等问题上都有了明显的改善。此外,我们使用hed、pidinet、pidisafe等常用的edge预处理器混合使用的方式进行训练,对不同预处理器都有很好的适应能力。
五、EcomXL下3秒快速出图
EcomXL在推理耗时以及显存开销都有大幅增长,特别是更长的推理时间对客户体验带来挑战,跟进到社区有关LCM一致性模型的相关工作。我们提出了一种新的推理加速模型SLAM(Sub-path Linear Approximation Model),可将推理从25步降低至4步,同时相比社区LCM在相同步数下取得更好生成效果。该工作已整理成论文:https://arxiv.org/abs/2404.13903,并已上线到万相实验室。
5.1 一致性模型SLAM
LCM通过缩小相邻两个点间的映射误差来逐渐达到一致性,但这也引入了较大的累积误差,导致其一步生图时细节丢失较多,通常需要更多的推理步数来提升效果。针对这一问题,我们提出了子路径线性近似模型SLAM(Sub-path Linear Approximation Model)。SLAM为所有相邻点构建了线性子路径,并通过在该路径上的随机线性插值采样来完成连续的渐进式误差估计,使得整个学习过程更加平滑。其流程如下图所示:
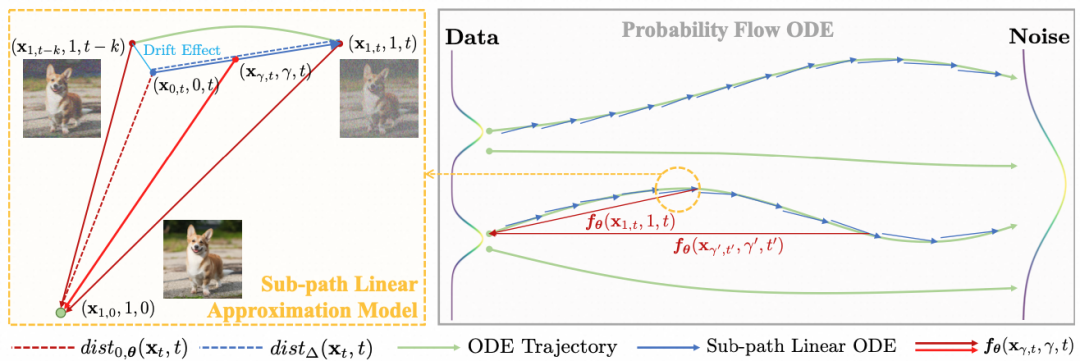
由于SLAM优化了相邻点间的映射误差,所以其完整去噪映射过程的累积误差也得以降低,从而提高了低步数下的生成质量。如下SLAM和LCM方法的指标对比,SLAM在2步的效果与LCM在4步的效果相当。如右侧示意图,SLAM的线条和纹理较LCM更清晰,生成细节更准确。

5.2 灵感推荐
结合EcomXL和SLAM的快速生图能力,万相实验室提供了全新的“灵感推荐”功能。在日常并发负载下,实现3秒内完成生成推理过程,叠加预处理和风控后处理,整体用户体验时间缩短到5秒内。从而助力客户更高效地尝试不同的生成风格。

六、业务效果评估
6.1 评估方法
为有效评估EcomXL对于业务最终效果的影响,我们将其与线上的Ecom1.5进行了离线和在线的对比。其中,离线对比以视觉可用率、1 vs. 1 胜率作为评估指标;在线对比以线上采纳率为评估指标,来最直观反映用户对于生图结果的满意程度。
视觉可用率:从模特语义属性和肢体畸形、商品抠图边缘和异常延展、背景构图逻辑和语义触发等角度评估生成图片的可用度。
1 vs. 1 胜率:采用成对图像盲测的测评方式,多位设计师通过个人专业角度投票选出其中更美观的一张。从而计算Ecom1.5和EcomXL的各自胜率。
在线采纳率:万相实验室一次生图请求产生4张不同种子点图像,在图像的粒度进行模型的打散,计算每个模型下载率=下载图片数量/生成图片数量。
6.2 线上效果
相较于线上的Ecom1.5,EcomXL在视觉可用率(+5pt)、1 vs. 1 胜率(+2.8pt)和线上采纳率(+2pt)均显著提升,因此,已经作为主模型装配到了阿里妈妈万相实验室。两者更多对比效果如下:

七、总结
我们从人物/电商风格生成、控制能力配套以及推理提速多个角度分析了SDXL应用在电商场景的不足,在进行优化后整理了一套综合解决方案EcomXL(huggingface-ecomxl,huggingface-slam),该方案已全量上线到万相实验室。期待未来能够朝着给客户提供秒级实时、逼真灵动的生成效果的目标,与业界同行一起努力探索更优秀的AIGC图像生成算法。
🔗 HuggingFace 项目链接(复制链接到浏览器访问):
EcomXL: https://huggingface.co/collections/alimama-creative/ecomxl-662f1f0dac05b4f7c20fcde6
SLAM: https://huggingface.co/collections/alimama-creative/slam-662f1dd31d5c8cd0b3acb0e0
🏷 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱 AIGC 时代!感兴趣的同学欢迎投递简历加入我们。
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
▐ 参考文献
[1] Betker J, Goh G, Jing L, et al. Improving image generation with better captions[J]. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2023, 2(3): 8.
[2] Chen J, Yu J, Ge C, et al. PixArt-: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis[J]. arXiv preprint arXiv:2310.00426, 2023.
[3] Dai X, Hou J, Ma C Y, et al. Emu: Enhancing image generation models using photogenic needles in a haystack[J]. arXiv preprint arXiv:2309.15807, 2023.
[4] Salimans T, Ho J. Progressive distillation for fast sampling of diffusion models[J]. arXiv preprint arXiv:2202.00512, 2022.
[5] Hang T, Gu S, Li C, et al. Efficient diffusion training via min-snr weighting strategy[J]. arXiv preprint arXiv:2303.09556, 2023.
END

也许你还想看
丨ACM MM’23 | 4篇论文解析阿里妈妈广告创意算法最新进展
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨CVPR 2023 | 基于无监督域自适应方法的海报布局生成
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









