



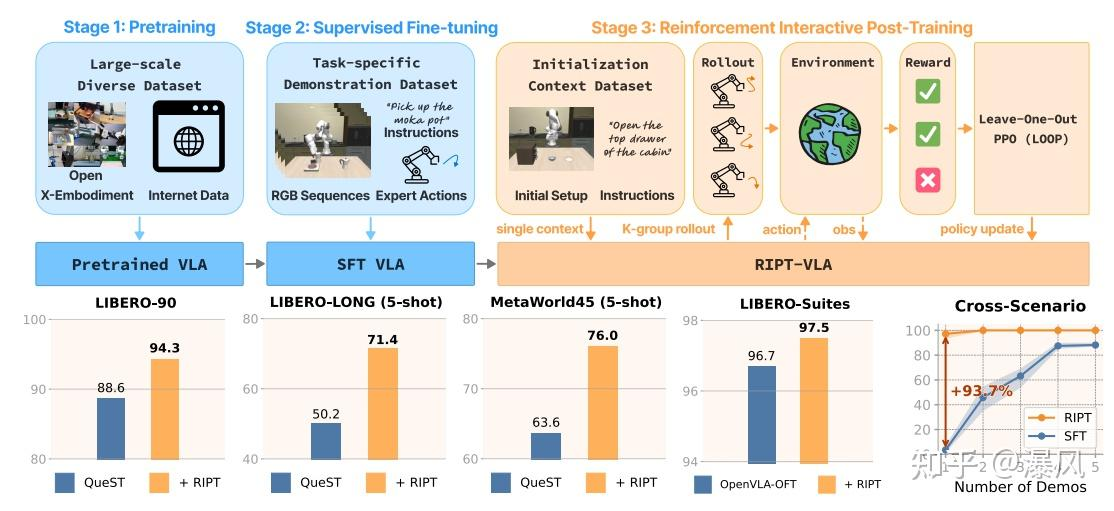
本文提出RIPT-VLA,一种基于强化学习的交互式后训练范式,用于优化预训练的视觉 - 语言 - 动作(VLA)模型,仅需稀疏二元成功奖励。该方法通过动态滚动采样和留一优势估计的
稳定策略优化算法,解决了现有 VLA 模型依赖大量离线专家演示、在低数据场景下适应性差的问题。实验表明,RIPT-VLA 可提升轻量级 QueST 模型 21.2%,使 7B 规模的
OpenVLA-OFT 达到 97.5% 的成功率,且仅用 1 个演示就能将成功率从 4% 提升至 97%,展现出优异的数据效率、计算效率和跨任务泛化能力。
一、研究背景与目标
现有 VLA 模型局限:依赖离线专家演示和监督模仿,难以适应新任务和低数据场景,长 horizon 任务中因分布偏移和级联错误易失败。
核心挑战:离线训练无法感知动作后果,监督微调需大量高质量数据,难以应对真实场景复杂性。
二、RIPT-VLA 方法框架
(一)三阶段训练流程
阶段 1:预训练:在大规模多样化数据集(如 Open-X Embodiment)上学习通用视觉 - 运动技能。
阶段 2:监督微调(SFT):在任务特定小数据集上优化,适应具体任务。
阶段 3:强化交互式后训练(RIPT-VLA):通过与环境交互获取二元奖励,用强化学习直接优化成功率。
(二)关键技术
动态滚动采样:过滤全成功或全失败的无信息轨迹,聚焦有梯度信号的样本。
留一优势估计(RLOO):对每个上下文采样 K 条轨迹,用其余轨迹奖励均值作为基线计算优势值。
近端策略优化(PPO):结合 RLOO 优势值,通过裁剪目标函数稳定策略更新。
简单来说LOOP就是RLOO+PPO:在 稀疏奖励 + 长时间序列 + 多任务不平衡 。场景中critic模型不好训,就采用留一法(RLOO)估计优势;然后在用PPO的clip算出loss进行优化。因此,在线采样中同一个context需要rollout多次。RIPT-VLA主要是采用LOOP算法的online RL,给出了开源代码。
将 VLA 视为马尔可夫决策过程。为了更好地优化 VLA 模型,我们将其任务定义为一个马尔可夫决策过程(MDP)。每个 episodes 以上下文 c=(o1, g) 初始化。状态表示为 [o1:t, g, a1:t−1],其中包括语言目标 g、过往观测序列 o1:t 和过往动作 a1:t−1。在每个时间步 t,VLA 策略从策略分布中采样生成一个动作:at∼πθ(・|o1:t, g, a1:t−1)。环境基于隐藏的环境动态转移到下一个观测 ot+1,生成新状态 [o1:t+1, g, a1:t]。在执行动作序列 a1:T 后,智能体从环境 E 中获得二元奖励 R (c, a)∈{0,1},表示任务成功或失败。VLA 优化的目标本质上是学习一个策略 πθ,以最大化期望任务成功奖励:
Rθ(c)=Ea∼πθ(・|c)[R (c, a)]。(3)
一种标准方法是策略梯度,其中A(c,a)是优势函数,表示动作 a 相较于基线的优劣程度。实际上,计算A(c,a)
较为困难,尤其是在稀疏奖励条件下。为解决此问题,近期一项研究提出了一种无评论家优化框架,称为留一近端策略优化(LOOP)[4]。具体而言,其结合了以下两种方法:
留一优势估计(RLOO)[16]:对于每个采样上下文 c,我们在固定采样策略πψ下生成 K 个轨迹akπψ(⋅∣c)k=1K。每个轨迹获得二元奖励Rk=R(c,ak)。轨迹 k 的留一基线通过对其他奖励求平均计算:。这种组归一化优势表明,在相同上下文中,一个滚动输出的性能相对于其他滚动输出的表现好多少或差多少。这使我们能够从稀疏的二元奖励中高效计算出稳定的优势信号,而无需学习价值函数。
这种组归一化优势表明,在相同上下文中,一个滚动输出的性能相对于其他滚动输出的表现好多少或差多少。这使我们能够从稀疏的二元奖励中高效计算出稳定的优势信号,而无需学习价值函数。
近端策略优化(PPO)[28]。为了使用收集的滚动输出 {(ck, ak, Ak)} 更新 πθ,我们计算重要性比率 rk = πθ (ak | ck)/πψ (ak | ck),其中 πθ 是当前正在更新的策略,πψ 是固定的采样策略(通常设置为 πθ 的最新检查点)。然后,我们使用以下裁剪目标来优化 πθ。
LOOP 采用 PPO 来优化由 RLOO 估计的优势,这使得在稀疏奖励设置下无需评论家(critic)即可实现样本高效的策略优化。
(这不GRPO吗?)
RIPT-VLA 方法框架
我们的 VLA 训练范式的前两个阶段与标准设置相同。在第一阶段,我们在一个大型、多样化的数据集Dpretrain上对 VLA 模型进行预训练,以学习视觉语言表示和通用视觉运动技能。然后,在第二阶段,我们在一个小数据集Dstt上对 VLA 进行微调,使其适应遵循指令来解决一小组目标任务。这些阶段产生了一个预训练的 VLA 策略πθ,该策略在目标任务上可以达到非零的成功率(可能非常低)。第三步,强化交互式后训练。在这个阶段,我们假设可以在环境 ε 中展开策略πθ,并在给定a∼πθ(⋅∣c)的情况下接收二元奖励R(c,a)∈{0,1},其中 c 为初始上下文。此外,我们使用初始上下文数据集Dc={(o1,g)}来为模型展开设置任务初始化。通常,我们通过直接从Dstt的序列中提取初始状态来获取Dc。对于每个优化步骤,我们在两个步骤之间迭代:展开收集和策略优化。
在展开收集阶段,我们从上下文数据集Dc中随机采样上下文ci,并让策略πθ与环境E交互以输出动作序列ai。对于每个展开轨迹,我们收集其奖励R(ci,ai)并计算优势值Ai=A(ci,ai),该值表示模型生成轨迹a时应被鼓励(A>0)或惩罚(A<0)的程度。我们将所有展开轨迹和奖励(ci,ai,Ai)添加到展开数据集Drollout中,直至收集到B条轨迹:Drollout={(ci,ai,Ai)}i=1B。
在策略优化阶段,我们使用强化学习算法在Drollout上对πθ进行N次迭代优化,以最大化公式 (3) 中的期望任务成功率。优化完成后,我们使用更新后的 VLA 策略πθ′收集新的展开轨迹,开启新的优化步骤。此过程重复直至达到M步,最终输出策略πθ∗,完成整个 VLA 训练流程。随后,我们将πθ∗部署到环境中进行测试。
此外还加了哪些trick呢?
动态拒绝机制:如果某个上下文 c 下的所有 K 个 rollouts 的奖励完全一致(都成功或都失败),则跳过这个任务,提升梯度有效性;
多任务场景群体采样:在 batch 中,分组采样多个 context,每个 context 对应 K 个 rollouts,相当于:从 multi-task context dataset 中选 B/K 个任务,每个任务采样 K 条轨迹,提高样本多样性,缓解 task imbalance;
部分off policy优化:每个 rollout 用多次(N>1):可视作轻度 off-policy,提高样本利用率。
4.3
Generalizing RIPT-VLA to Different VLA models
RIPT-VLA 与 VLA 模型中常用的离散和连续动作表示均兼容。RIPT-VLA 要求 VLA 模型能够在每一步输出动作的概率分布,这一要求在两个关键步骤中发挥作用。首先,在滚动收集阶段,为了支持同一初始化上下文的分组采样中生成多样化的滚动结果,我们需要从其输出分布中随机采样不同的动作:
at ∼ πθ (at | o1:t, g, a1:t−1), (7)
另一方面,为了执行稳定的策略优化,我们在公式 6 中计算信任区域 ri = πθ (ai|ci) / πψ (ai|ci),以将策略更新约束在原始策略的小区域内。此公式的一个关键组成部分是计算采样动作序列在两种策略下的对数概率。我们将采样动作序列 a = (a1, . . . , aT ) 的对数概率计算为每一步对数概率的和:
log πθ (a | c) = ∑(t=1 到 T) log πθ (at | a<t, c). (8)
换句话说,我们可以将 RIPT-VLA 应用于任何 VLA 模型 πθ,只要我们能从每一步的动作分布中采样随机动作 at,并计算 log πθ (at | a<t, c)。
Tokenized action head:对于具有离散动作输出的 VLA 模型,例如 QueST [22],动作被预测为来自固定词汇表的离散标记序列,其中动作头是使用负对数似然(NLL)损失训练的分类头。因此,log πθ (at | a<t, c) 可通过对模型分类头输出的 logits 应用 softmax 函数直接获得。我们也可以简单地从 softmax 后的分布中采样动作标记。
Regression action head:对于连续动作的 VLA 模型 [14],动作是使用均方误差(MSE)或 L1 损失进行回归的,这不产生对数概率。为了支持策略梯度优化,我们用一个轻量级的尺度预测头扩展模型,该头估计动作值的尺度 σθ。假设原始输出头提供均值 μθ,我们将策略视为因子化的高斯(MSE)或拉普拉斯(L1)分布,并在 Dsft 上使用公式 2 中的 NLL 损失对尺度头进行几次迭代训练。之后,我们可以采样动作 at,并使用预测的 μθ 和 σθ 以闭式形式计算 log πθ (at | a<t, c)。


















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











