






全文总结
这篇论文研究了如何将基于互联网规模数据训练的视觉-语言模型直接整合到端到端的机器人控制中,以提升泛化能力和实现语义推理。
研究背景
- 研究问题: 这篇文章要解决的问题是如何将大规模预训练的视觉-语言模型直接应用于机器人控制,以提高其泛化能力和实现语义推理。
- 研究难点: 该问题的研究难点包括:如何将自然语言响应和机器人动作统一格式化,如何在大规模预训练模型中融入机器人轨迹数据,以及如何在实时机器人控制中高效运行这些大型模型。
- 相关工作: 相关工作包括对视觉-语言模型的研究(如CLIP和VQA),以及将这些模型应用于机器人任务的研究(如状态机解释命令和低级控制器执行)。然而,这些方法通常只处理机器人规划的高层次方面,未能充分利用互联网规模模型的丰富语义知识。
研究方法
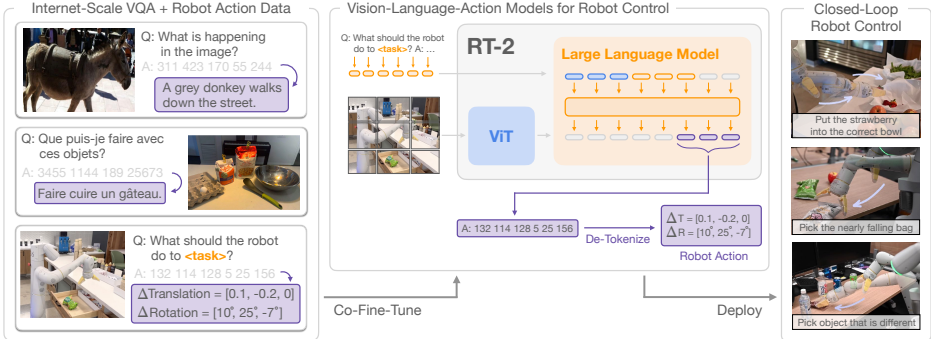
这篇论文提出了一种简单而有效的方法,通过将机器人动作表示为文本标记,并将其直接纳入模型的训练集中,从而实现视觉-语言-动作模型(VLA)。具体来说,
- 模型架构: 论文采用了PaLI-X和PaLM-E两种预训练的视觉-语言模型,并对其进行微调以输出低级机器人动作。这些模型被扩展以使用大型视觉-语言骨干网络。
- 动作编码: 动作空间包括机器人末端执行器的6自由度位置和旋转位移、夹持器的伸展级别以及一个用于终止任务的特殊离散命令。连续维度被均匀地离散化为256个区间,并将动作表示为8个整数。
- 共微调: 为了提高机器人性能,论文采用了共微调策略,即在微调过程中同时使用机器人数据和原始网络数据。这种方法使得策略能够同时接触到抽象的视觉概念和低级的机器人动作,从而提高泛化能力。
- 输出约束: 在机器人动作任务中,模型被约束为仅输出有效的动作标记,而在标准视觉-语言任务中,模型仍可以输出完整的自然语言标记。
实验设计
论文通过约6000次评估轨迹来验证RT-2模型在真实世界中的泛化能力和涌现能力。实验设计包括以下几个方面:
- 数据收集: 使用了来自Chen等人和Driess等人的原始网络数据,以及Brohan等人收集的机器人演示数据。每个机器人演示轨迹都附有描述任务的自然语言指令。
- 实验设置: 实验使用了7自由度的移动操作臂,动作空间如第3.2节所述。实验在多种条件下进行,包括未见过的对象、背景和环境。
- 对比基准: 实验中将RT-2与多个最先进的基线进行了比较,包括RT-1、VC-1、R3M和MOO等。
结果与分析
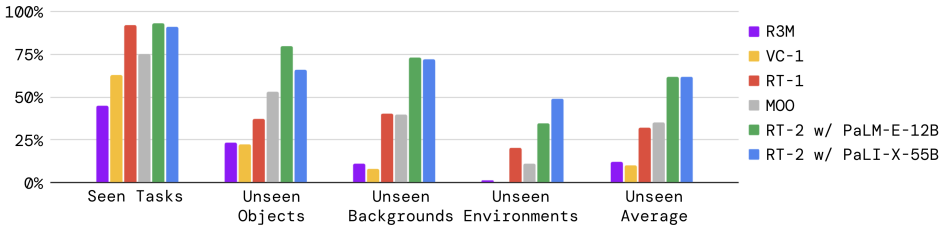
- 任务性能: RT-2模型在已知任务上的表现与RT-1相似,但在泛化实验中表现出显著优势。RT-2的平均性能比RT-1和MOO提高了约2倍,比其他基线提高了约6倍。
- 涌现能力: RT-2模型展示了多种涌现能力,包括语义理解和基本推理。例如,模型能够将草莓放入正确的碗中,识别即将掉落的袋子,并执行多阶段语义推理任务。
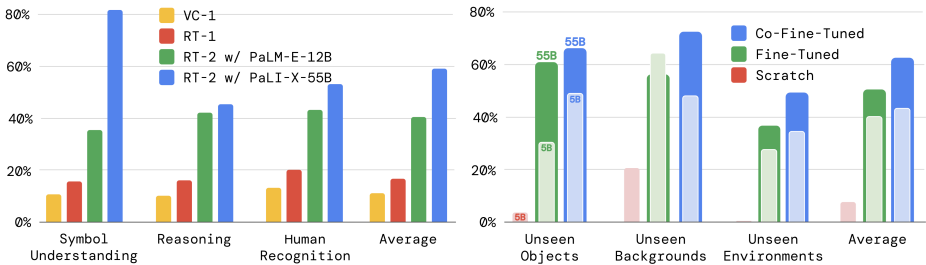
- 参数和训练策略: 实验结果表明,共微调比仅使用机器人数据进行微调的效果更好,且模型规模越大,泛化性能越好。
- 链式思维推理: 通过对PaLM-E模型进行少量梯度步骤的微调,RT-2展示了更复杂的语义推理行为。例如,模型能够生成计划并执行动作,从而更好地应对复杂命令。
总体结论
这篇论文提出了一种简单而有效的方法,通过将大规模预训练的视觉-语言模型直接应用于机器人控制,实现了显著的泛化能力和涌现语义推理能力。实验结果表明,RT-2模型在多种真实世界场景中表现出色,展示了其在机器人学习领域的战略潜力。未来的研究可以探索如何通过新的数据收集范式获取新技能,以及如何通过量化和蒸馏技术提高模型的实时推理能力。
核心速览
研究背景
- 研究问题:这篇文章研究了如何将互联网规模数据上训练的视觉语言模型(Vision-Language Models, VLMs)直接集成到机器人控制中,以增强泛化能力和实现涌现语义推理。目标是使单个端到端训练的模型能够学习将机器人观测映射到动作,并享受大规模预训练在语言和视觉语言数据上的好处。
- 研究难点:该问题的研究难点包括:如何将自然语言响应和机器人动作表达成相同的格式,并将它们直接纳入模型的培训集中;如何在机器人轨迹数据和互联网规模的视觉语言任务上共同微调最先进的视觉语言模型;如何在不增加新参数的情况下,使预训练的视觉语言模型输出文本编码的动作。
- 相关工作:该问题的研究相关工作包括:视觉语言模型的分类,如表示学习模型CLIP和视觉语言模型{vision, text}→{text};机器人学习中泛化的方法,如从大规模和多样化数据集中学习;以及预训练在机器人操作中的应用,如使用预训练的视觉表示初始化机器人的相机观测。
研究方法
这篇论文提出了一种简单而有效的方法,将大规模预训练的视觉语言模型直接用于低级机器人控制。具体来说,
-
模型架构:首先,描述了视觉语言模型(VLMs)的一般架构及其如何从常用的视觉语言任务模型中派生出来。然后,介绍了将VLMs微调以直接执行闭环机器人控制的配方和挑战。最后,描述了如何使这些模型适用于机器人任务,解决模型大小和推理速度的问题,以实现实时控制。
-
动作编码:将动作表示为模型输出的文本令牌,并将其视为自然语言令牌处理。动作空间包括机器人末端执行器的6自由度位置和旋转位移,以及机器人夹持器的扩展级别和一个特殊的分段命令,用于在策略成功完成时终止情节。连续维度(除分段命令外的所有维度)均匀离散化为256个区间。
-
共同微调:关键的技术细节是在微调过程中平衡机器人数据和原始网络数据的比率,通过增加机器人数据集的采样权重来实现。
-
输出约束:为了确保RT-2在解码时输出有效的动作令牌,通过仅在模型被提示为机器人动作任务时采样有效动作令牌来约束其输出词汇,同时允许模型在标准视觉语言任务上输出完整的自然语言令牌范围。
实验设计
- 数据收集:使用了来自Chen等人(2023b)和Driess等人(2023)的原始网络规模数据和机器人演示数据。原始网络规模数据包括视觉问答、字幕和无结构的图像和文本示例。机器人演示数据是从Brohan等人(2022)收集的,包含13个机器人在办公室厨房环境中进行的演示。
- 实验设置:评估了两种特定的RT-2实现,利用预训练的VLMs:(1)RT-2-PaLI-X,由5B和55B PaLI-X构建;(2)RT-2-PaLM-E,由12B PaLM-E构建。训练过程中使用了原始的网络规模数据和机器人演示数据。
- 参数配置:对于RT-2-PaLI-X-55B,使用学习率1e-3和批量大小2048,共同微调80K梯度步骤;对于RT-2-PaLI-X-5B,使用相同的学习率和批量大小,共同微调270K梯度步骤。对于RT-2-PaLM-E-12B,使用学习率4e-4和批量大小512,共同微调1M梯度步骤。
结果与分析
-
总体性能:在看到任务和未见任务的评估中,RT-2模型的表现与RT-1相似,但在各种泛化实验中,RT-2模型的表现显著优于基线模型。PaLM-E版本的RT-2在较难的泛化场景中表现更好,而在较简单的场景中表现略差。
-
涌现能力:定量评估结果表明,RT-2在各种新的指令上比RT-1表现高出2到3倍,展示了如何利用预训练的网络规模视觉语言数据的能力。
-
模型大小和训练策略:消融实验表明,模型大小对性能有重要影响,共同微调优于单独微调,单独微调又优于从头开始训练。

-
链式思维推理:通过增加一个“计划”步骤来增强RT-2的数据,使其能够生成计划和动作,展示了使用LLMs或VLMs作为规划器与低级策略结合的可能性。
总体结论
这篇论文描述了一种通过结合视觉语言模型预训练和机器人数据来训练视觉语言动作(VLA)模型的方法。提出了两种VLA模型的实现,RT-2-PaLM-E和RT-2-PaLI-X,并通过共同微调使其能够输出机器人动作。实验结果表明,这种方法能够显著提高泛化性能和涌现能力。尽管存在一些局限性,如模型无法学习新动作和计算成本高,但这种方法展示了机器人学习领域在受益于更好的视觉语言模型方面的潜力。
论文评价
优点与创新
- 强大的泛化能力:RT-2模型在未见过的物体、背景和环境中表现出色,显著优于基线模型。
- 新兴能力的展示:RT-2展示了从互联网规模预训练中继承的丰富语义理解和基本推理能力,能够执行复杂的任务,如使用石头作为临时锤子或选择适合疲劳者的饮料。
- 链式思维推理:通过引入“计划”步骤,RT-2能够进行更复杂的语义推理,生成计划和动作。
- 多模态句子生成:将机器人动作表示为文本令牌,并将其直接纳入模型的输入集,使模型能够学习到指令跟随的机器人策略。
- 大规模模型的应用:RT-2是迄今为止用于直接闭环机器人控制的最大模型,展示了其在实时控制中的潜力。
不足与反思
- 物理技能的局限性:尽管RT-2在语义理解和新颖任务的执行上表现出色,但其物理技能仍然局限于训练数据中看到的技能分布。未来的研究方向包括通过新的数据收集范式(如人类视频)来获取新技能。
- 计算成本高:大规模VLA模型的计算成本很高,实时推理可能成为主要瓶颈。未来的研究应探索量化和蒸馏技术,以提高模型的运行效率或降低成本硬件的要求。
- 可用模型数量有限:目前只有少数通用的VLA模型可供使用,未来希望有更多的开源模型可用,并开放专有模型的微调API,以便构建更多的VLA模型。
关键问题及回答
问题1:RT-2模型是如何将机器人动作表示为文本标记的?
RT-2模型通过将机器人动作离散化为文本标记来实现。具体来说,机器人末端执行器的6自由度位置和旋转位移,以及机器人夹持器的伸缩级别和一个特殊的终止命令被编码为整数。连续维度(除终止命令外)被均匀地离散化为256个区间,从而将机器人动作表示为8个整数。例如,机器人的末端执行器在x轴上的位移可以被离散化为一个介于0到255之间的整数,表示其在x轴上的位置。通过这种方式,动作被转换为文本标记,并在模型训练集中与自然语言标记一起使用。
问题2:共同微调在RT-2模型中的作用是什么?它如何提高泛化能力?
共同微调在RT-2模型中起到了关键作用。它通过将机器人数据和原始网络数据进行联合训练,而不是仅对机器人数据进行微调,从而提高了策略的泛化能力。具体来说,共同微调使得模型在微调过程中接触到抽象的视觉概念和低级别的机器人动作,这样模型在学习过程中不仅能够理解高层次的视觉语言信息,还能够掌握低级别的机器人控制技能。这种联合训练方法有助于模型在面对新的、未见过的任务时,能够更好地泛化和应用所学知识。实验结果表明,共同微调的RT-2模型在未见过的对象、背景和环境的平均得分显著高于仅对机器人数据进行微调的模型。
问题3:RT-2模型在实验中表现出了哪些涌现能力?
RT-2模型在实验中展示了一系列涌现能力,这些能力是通过将预训练在Web规模视觉语言数据集上的能力转移到机器人控制中实现的。具体表现包括:
- 符号理解:RT-2能够理解和执行复杂的符号指令,例如“move apple to 3”或“push coke can on top of heart”。
- 推理能力:RT-2能够进行基本的数学运算和逻辑推理,例如“move banana to 2”或“pick up the smallest object”。
- 人类识别:RT-2能够识别和处理与人类相关的任务和指令,例如“move the coke can to the person with glasses”。
这些涌现能力展示了RT-2模型在语义理解和基本推理方面的显著提升,使其能够在新的、未见过的任务中表现出类似人类的智能行为。

















 2403
2403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









