







最新人工智能论文:http://paperreading.club
虽然很多CNN模型在图像识别领域取得了巨大的成功,但是一个越来越突出的问题就是模型的复杂度太高,无法在手机端使用,为了能在手机端将CNN模型跑起来,并且能取得不错的效果,有很多研究人员做了很多有意义的探索和尝试,今天就介绍两个比较轻量级的模型 mobile net 和 shuffle net。
在介绍这几个轻量型的网络之前,我们先来看看,为什么卷积神经网络的运算功耗这么大。
卷积神经网络,顾名思义,就是会有很多的卷积运算,而卷积神经网络中,最费时间的就是其中的卷积运算。我们知道,一张 h×wh×w 的图像,与一个 k×kk×k 的卷积核做卷积卷积运算,需要 h×w×k×kh×w×k×k 这么多次的运算,而 CNN 中,随便一个卷积层, 都会有几十甚至上百个 feature map, 假设卷积层 l1l1 含有 c1c1 个 feature map,即通道数为 c1c1, 每个 feature map 的大小为 h1×w1h1×w1, 卷积核的大小为 k×kk×k,假设 l2l2 的 feature map 大小与 l1l1 一样,通道数为 c2c2 ,l2l2 中每个 feature map 上的一个像素点,都是由 l1l1 上的 feature map 与 卷积核做卷积运算得来的。这样,总共需要的运算次数为:
h1×w1×k×k×c1×c2h1×w1×k×k×c1×c2
Mobile-Net V1
为了减少运算量,Mobile-net V1 利用了 depth-wise 的概念,我们都知道 pooling 层的运作机理,input feature map 和 output feature map 是 一 一对应的,depth-wise convolution 也是类似的道理,做卷积的时候不再把 input feature map 进行线性组合了,而是采取一 一对应的方式,这样卷积的运算次数就变成了:
h1×w1×k×k×c1h1×w1×k×k×c1
也就是说,我input 有 c1c1 个 feature map,卷积之后,还是有 c1c1 个 feature map,运算量减少了很多。
不过,也带来一个问题,这样卷积得到的 feature map 之间没有任何信息融合,这肯定不利于特征提取的,所以在 depth-wise 卷积运算后面,会再接一个 1×11×1 的卷积运算,所以总的运算次数是:
h1×w1×k×k×c1+h×w×c2×c1h1×w1×k×k×c1+h×w×c2×c1
V1 主要的模块如下图所示,就是利用 depth-wise 卷积替换了常规的卷积运算,为了让得到的 feature map 进行信息融合,后面又接了一个 1×11×1 的卷积。

Mobile-Net V2
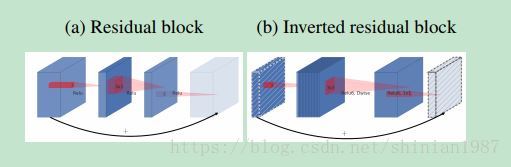
Mobile-Net V1 推出来之后,Google 又推出了 Mobile-Net V2,V2 在 residual-block 里面做文章,利用 depth-wise convolution 和 1×11×1 的卷积,简单来说,就是对 input feature map,先利用 1×11×1 进行通道扩展,这样一扩展,可以增加通道数,提升卷积层特征的表示能力,接着再利用 depth-wise convolution 做卷积运算,这样不会增加太多的运算量,又能利用很多的通道,最后再做一个通道压缩,一压缩,往后传的 feature map 的通道数并不会增加,论文中也给出了示意图:
Shuffle-Net
shuffle-net 这个网络模型,是利用了 group 卷积的概念,与 depth-wise 有点像,只不过,depth-wise 是 feature map 一 一对应的,而 group 卷积是将每个卷积层的 feature map 分成几个组,每个组之间没有交叉,不过组内的 feature map 做卷积的时候和常规的卷积运算是一样的,所以 group 卷积的复杂度应该是介于常规卷积核 depth-wise 卷积之间的,shuffle-net 的创新之处在于,group 卷积之后,为了增加组与组之间的 feature map的通信,提出了一个 shuffle channel 的技术,就是将 group 卷积之后 feature map 打乱,乱序连接到下一层,如下图所示:
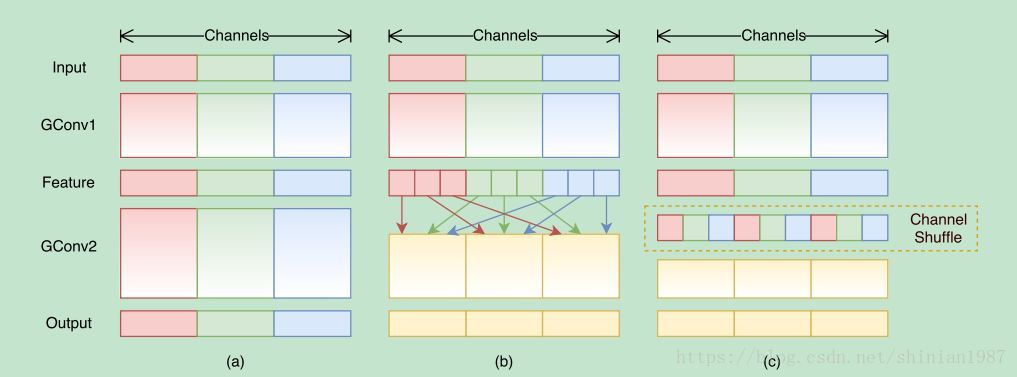
通过 group 卷积,可以降低运算量,通过 channel shuffle,可以增加 feature map之间的信息融合,所以 shuffle-net 也能在提升运算效率的同时,保持一定的特征学习能力。论文也给出几种不同的 block,
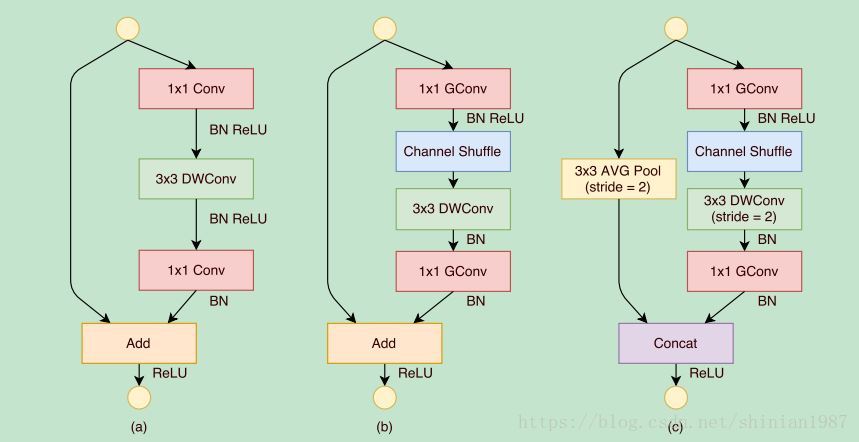
上图 (a) 是利用 depth-wise 卷积,(b) 和 (c) 都是 shuffle-net 的模块,不同的就是卷积的 stride 不同,所以最后的处理方式也不太一样。
参考文献
1: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
Applications
2: MobileNetV2: Inverted Residuals and Linear Bottlenecks
3: ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
Devices















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









