






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


作者:胡连宇,石同凯,冯伟,尚凡华,万亮(天津大学智算学部ViL实验室)
单位:天津大学
论文:https://arxiv.org/abs/2410.06558
https://github.com/hulianyuyy/Deep_Correlated_Prompting
论文概述
当前多模态大模型通常建设输入是模态齐全的。然而,由于隐私问题、传感器设置、信号传输等因素,现实中输入常常可能是模态缺失的。为解决这一问题,本文提出了面向视觉理解的深度关联提示学习。在MMIMDb、HatefulMemes以及Food101三个数据集上的广泛实验验证了模型的有效性。充足的消融实验验证了模型的鲁棒性及可扩展性。
前言
问题定义:给定一个拥有M个模态(如M=2,对于图像和文本)的数据集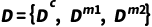 ,参考之前方法[1],我们将
,参考之前方法[1],我们将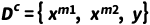 定义为完整数据,
定义为完整数据,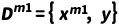 以及
以及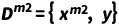 为模态缺失的数据,其中只有一个模态是缺失的(比如文本或图像)。该情况可以推广到任意多模态。
为模态缺失的数据,其中只有一个模态是缺失的(比如文本或图像)。该情况可以推广到任意多模态。
回顾之前方法:MMP[1]首先提出使用提示学习策略解决模态缺失问题。对于M模态输入,它将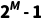 个提示向量赋给每种模态缺失情形(如3种提示向量,对于图像-文本任务,1种向量给模态齐全情形,1种向量给图像缺失情形,1种向量给文本缺失情形)。它直接将提示向量和输入进行拼接送入网络。在训练过程中,只有提示向量和网络末端的分类器被训练,其余部分均被冻结。
个提示向量赋给每种模态缺失情形(如3种提示向量,对于图像-文本任务,1种向量给模态齐全情形,1种向量给图像缺失情形,1种向量给文本缺失情形)。它直接将提示向量和输入进行拼接送入网络。在训练过程中,只有提示向量和网络末端的分类器被训练,其余部分均被冻结。
方法框架
虽然MMP[1]通过引入提示向量,相比于直接丢弃缺失模态的baseline能有效提示鲁棒性(如图1所示),但是它仅在输入层面简单将提示向量和输入拼接,忽略了以下方面:(1)忽略不同层之间提示向量的关联;(2)缺乏根据输入动态调整提示向量的能力;(3)忽略了不同模态间提示向量的互补性。
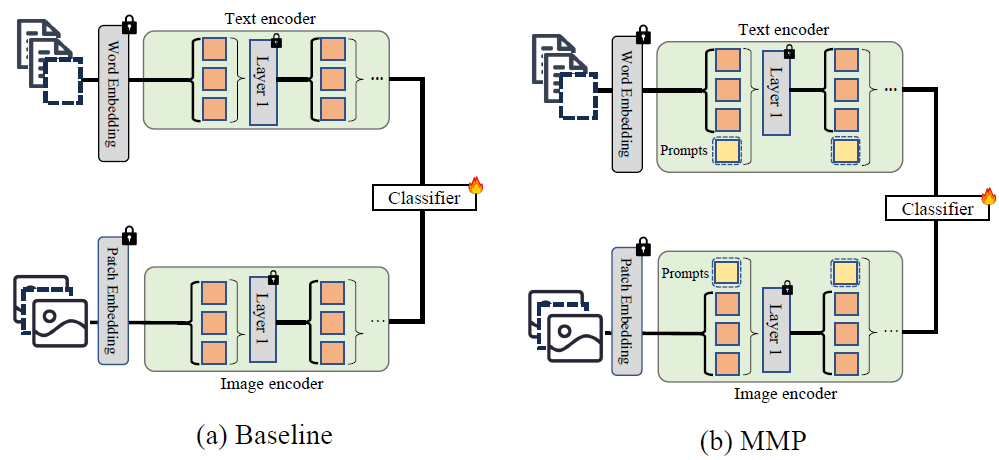
图1:MMP[1]与baseline对比
因此,我们提出多种不同提示向量,分别应对以上缺点,如图2所示。
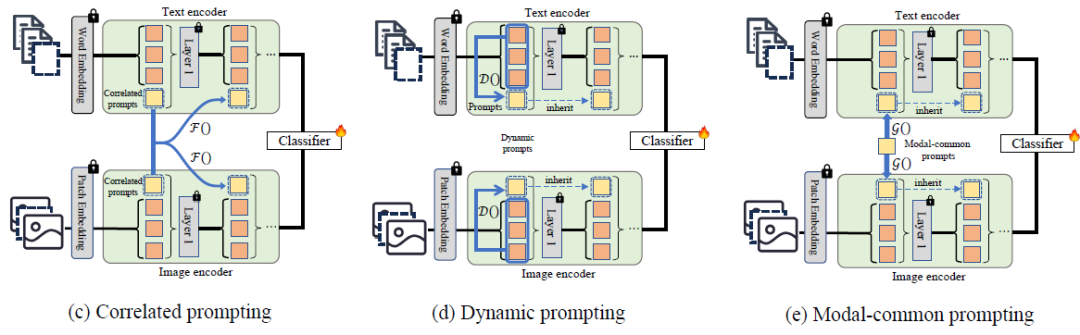
图2:所提出的三种提示学习方法图示
Correlated prompting:前一层的提示向量可以为后一层提供指导。如图2(c)所示,因此我们在第J层之前使用函数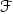 (实例化为一个MLP)基于上一层的提示向量,生成下一层的提示向量。第一层的提示向量被随机初始化。为结合多模态互补信息,我们将多个模态中前一层的提示向量,送入
(实例化为一个MLP)基于上一层的提示向量,生成下一层的提示向量。第一层的提示向量被随机初始化。为结合多模态互补信息,我们将多个模态中前一层的提示向量,送入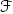 生成各模态下一层的提示向量。
生成各模态下一层的提示向量。
Dynamic prompting: 不同输入往往需要不同类型的提示。我们提出根据输入在第一层网络之前动态生成提示向量。如图2(d)所示,我们使用函数 (实例化为一个attention layer)基于输入向量,为本模态动态生成提示向量。
(实例化为一个attention layer)基于输入向量,为本模态动态生成提示向量。
Modal-common prompting: 不同模态间存在互补信息与共有信息。我们提出modal-common prompts,存储模态间共有信息,当某模态缺失时,为其提供缺失信息。图2(f)所示,我们随机初始化了一个modal-common prompt,使用函数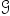 将其转化为每个模态的提示向量。
将其转化为每个模态的提示向量。
我们将以上三种提示向量拼接,并进一步与输入拼接后,送入模型。在训练过程中,只有提示向量及其生成模块,以及模型末端的分类器被更新,其余部分被冻结,因此只需要训练整个模型约2.4%的参数。整个模型框架如图3所示。
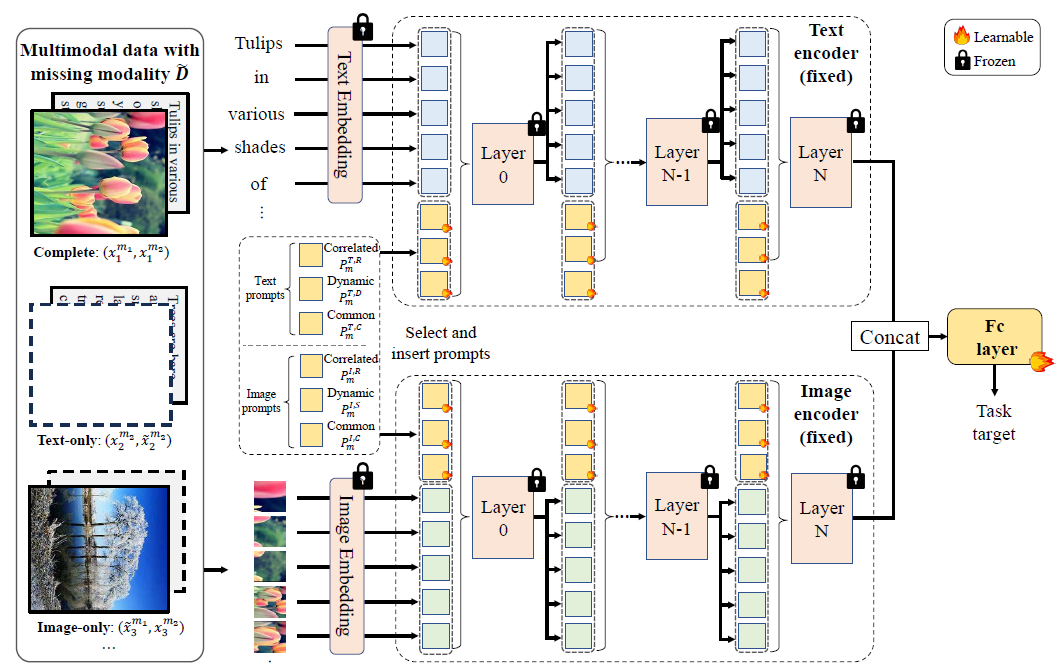
图3:整个模型框架
实验部分
实验细节:我们使用CLIP ViT-B/16作为基础模型,输入大小为224×224,最大文本输入长度为77。提示向量总长度为36,在一个3090 GPU上完成训练。
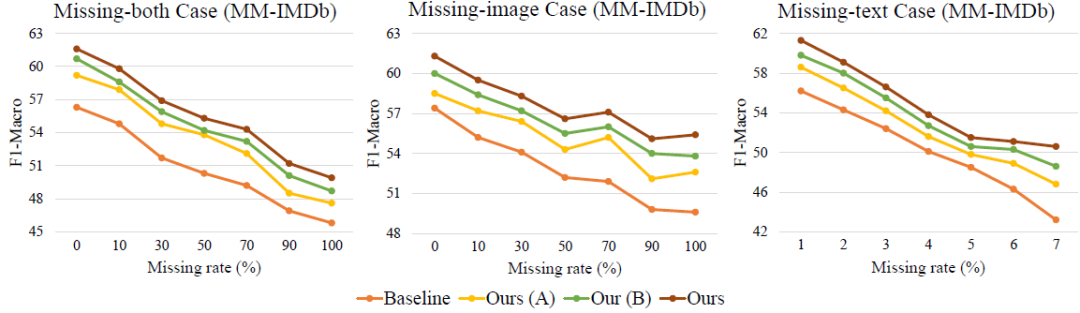
图1:模型有效性展示
模块有效性:图1比较了我们的方法(Ours)与(1)Baseline,直接丢弃模态缺失特征;(2)Ours(A),只使用Correlated prompting;(3)Ours(B),使用Correlated prompting与Dynamic prompts在MMIMDb数据集上在不同模态缺失率下的性能。左图、中图和右图分别展示了在图文均可能缺失、图像缺失和文本缺失下的性能。从图中可以看出,相比于Baseline,每个提出的模块都能有效提高模型性能。
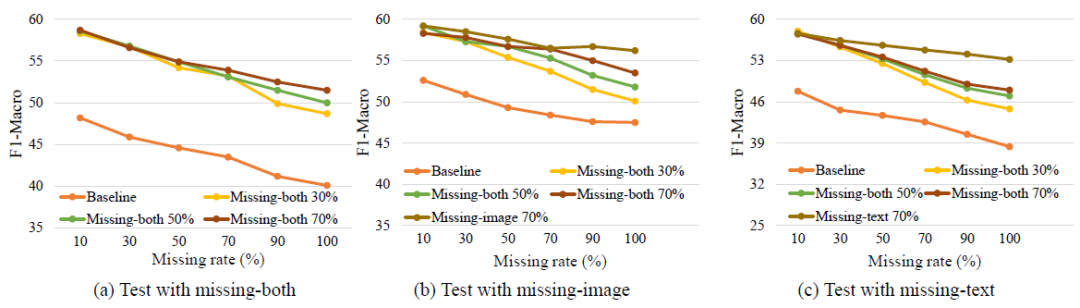
图2:模型鲁棒性展示
模型鲁棒性:在图2中,我们测试了模型在不同模态缺失下情况下的鲁棒性。图2(a):当训练时不同图文均可能缺失(missing-both),我们在不同缺失率下训练了模型,并在0-100%缺失率下在missing-both情况下进行测试,发现在缺失率较高情况下训练的模型,测试鲁棒性较好。图2(b):当训练时不同图文均可能缺失(missing-both)或图像可能缺失(missing-image)时,我们在不同缺失率下训练了模型,并在0-100%缺失率下在missing-image情况下进行测试,发现当训练和测试时图像可能缺失(missing-image)情况下训练的模型鲁棒性最好,但在不同图文均可能缺失(missing-both)情况下训练的模型也具有较好鲁棒性。图2(c):当训练时不同图文均可能缺失(missing-both)或文本可能缺失(missing-text)时,我们在不同缺失率下训练了模型,并在0-100%缺失率下在missing-text情况下进行测试,发现当训练和测试时图像可能缺失(missing-text)情况下训练的模型鲁棒性最好,但在不同图文均可能缺失(missing-both)情况下训练的模型也具有较好鲁棒性。结论:在训练时不同图文均可能缺失(missing-both)的情况下训练的模型,在不同测试情况包括不同图文均可能缺失(missing-both)、图像可能缺失(missing-image)和文本可能缺失(missing-text)时,均具有较高鲁棒性。
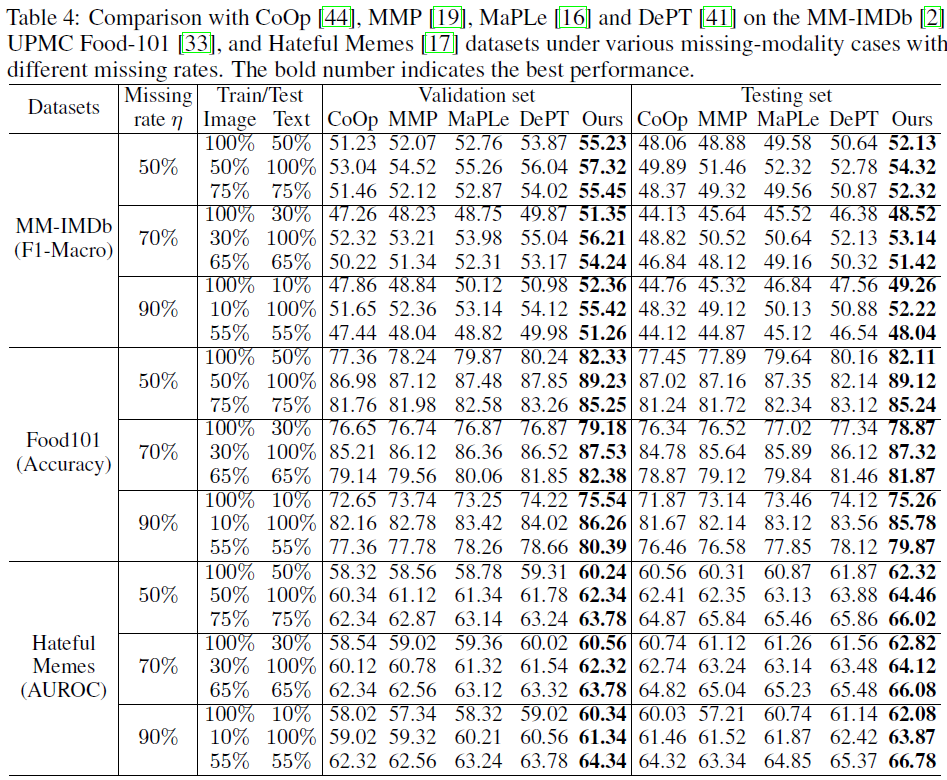
图4:和SOTA模型在MMIMDb、HatefulMemes以及Food101三个数据集上对比。
和SOTA模型对比:图4在MMIMDb、HatefulMemes以及Food101三个数据集上对比了我们的模型和其他SOTA方法。在不同数据集、不同缺失率以及缺失模态的情况下,我们的模型都取得了最高的精度,展示了良好的鲁棒性和可扩展性。
[1] Yi-Lun Lee, Yi-Hsuan Tsai, Wei-Chen Chiu, and Chen-Yu Lee. Multimodal prompting with missing modalities for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14943–14952, 2023
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









