






author: 张俊林
关于社区问答系统的问题背景,我们在之前的“利用卷积神经网络构造社区问答系统”一文里已经说明得非常清楚,本文就不再赘述,不清楚背景的读者可自行參照上文。我们这些相关的研发工作主要是为了开发畅捷通“会计家园”交流社区的相关功能。为了保持行文完整。简明叙述形式化描写叙述的问题例如以下:
假设我们已知问答库例如以下:
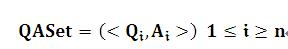
当中,Qi是问答社区中的历史问题,Ai是Qi问题的精华答案;
现有社区用户提出的新问题:Qnew
我们须要学习映射函数:
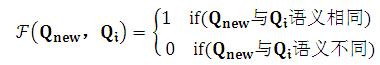
意即对于新问题Qnew,我们希望通过学习系统找到社区中已经出现过的语义同样问题Qi。然后将相应的答案Ai推荐给用户。
这样就达到了社区信息复用的目的。这个问题事实上对于问答社区比方百度知道、知乎等都是存在的。解决这个问题的思路也全然能够复用到此类问答社区中。
除了上篇文章讲述的利用CNN来构造ML系统外,我们还尝试了使用RNN及其改进模型LSTM。本文主体内容即为使用深度双向LSTM构造社区问答系统的思路及效果。
|深度双向LSTM模型
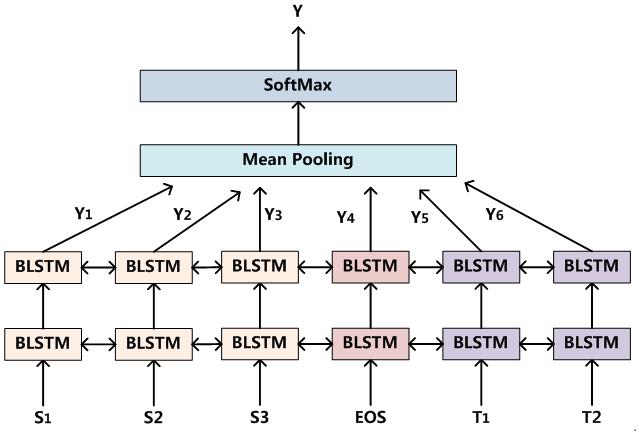
图1 深度双向LSTM
深度双向LSTM模型的结构如图1所看到的。
首先强调一下,这个结构也是一个解决对照两个句子类似性的通用RNN解决方式,不只能够使用在问答社区。凡是涉及到对照两个句子或者实体关系的场合全然能够套用这个模型来解决。这点希望读者注意。
首先。由于我们面临的问题是对照两个问题Qi和Qj是否语义同样,那么对于RNN来说存在一个神经网络的输入层怎样构造的难题。CNN解决这类问题就比較直观。一般一个输入套上一个CNN来抽取出句子特征。然后再套上MLP神经网络来表达两者之间的关系就可以。RNN表达单个输入句子是非常直观的,可是直接表达两个句子之间的关系相对而言就没那么直观。一般能够如图1这么做。就是把两个问题Qi和Qj拼接起来,中间用一个特殊分隔符EOS切割,这里EOS不代表一个句子的结束,而是代表两个句子的分隔符号,这个也请读者注意。如此就构造出了RNN的输入层。
有了输入层,上面就优点理了。
首先我们在输入层之上。套上一层双向LSTM层。LSTM是RNN的改进模型。相比RNN,能够更有效地处理句子中单词间的长距离影响。而双向LSTM就是在隐层同一时候有一个正向LSTM和反向LSTM,正向LSTM捕获了上文的特征信息,而反向LSTM捕获了下文的特征信息,这样相对单向LSTM来说能够捕获很多其它的特征信息。所以通常情况下双向LSTM表现比单向LSTM或者单向RNN要好。
图1中输入层之上的那个BLSTM层就是这个第一层双向LSTM层神经网络。
我们能够把神经网络的深度不断拓展,就是在第一层BLSTM基础上。再叠加一层BLSTM,叠加方法就是把每一个输入相应的BLSTM层的输出作为下一层BLSTM神经网络层相应节点的输入,由于两者全然是一一相应的,所以非常好叠加这两层神经网络。假设你觉得有必要,全然能够如此不断叠加更深一层的BLSTM来构造多层深度的BLSTM神经网络。
在最后一层BLSTM神经网络之上。能够使用Mean Pooling机制来融合BLSTM各个节点的结果信息。
所谓Mean Pooling。详细做法就是把BLSTM各个节点的输出结果求等权平均,首先把BLSTM各个输出内容叠加,这是pooling的含义,然后除以输入节点个数。这是mean的含义,Mean Pooling就是这个意思。
怎样从物理意义上来理解Mean Pooling呢?这事实上能够理解为在这一层,两个句子中每一个单词都对终于分类结果进行投票,由于每一个BLSTM的输出能够理解为这个输入单词看到了全部上文和全部下文(包括两个句子)后作出的两者是否语义同样的推断,而通过Mean Pooling层投出自己宝贵的一票。
所以RNN场景下的Mean Pooling能够看作一种深度学习里的“民主党”投票机制。
在Mean Pooling之上,我们还能够套上一层SoftMax层,这样就能够实现终于的分类目的。
通过以上方式,我们就通过输入层、多层BLSTM层、Mean Pooling层和输出层构造出一个通用的推断两个句子语义是否同样的深度学习系统。
事实上这个结构是非常通用的,除了推断两个句子关系,对于单句子分类明显也是能够套用这个结构的。
模型结构已经讲完。后面我们将进入实验部分,由于希望和CNN结果进行效果对照。我们先简单说明下两个同样能够用来解决社区问答问题的CNN结构,这两个结构在之前的“利用卷积神经网络构造社区问答系统”文中都有详细描写叙述,这里不展开讲。不过列出结构图,以方便理解和对照模型。
|两个CNN模型结构
两个CNN模型结构參考图2和图3,图2这样的结构是利用CNN推断多个输入句子关系的简单直接的结构,含义是先各自抽取每一个句子的特征然后比較两者的关系。而图3这样的结构的含义是先把两个句子之间的关系明白表达出来作为输入。然后再套上一个CNN模型来进行分类预測。
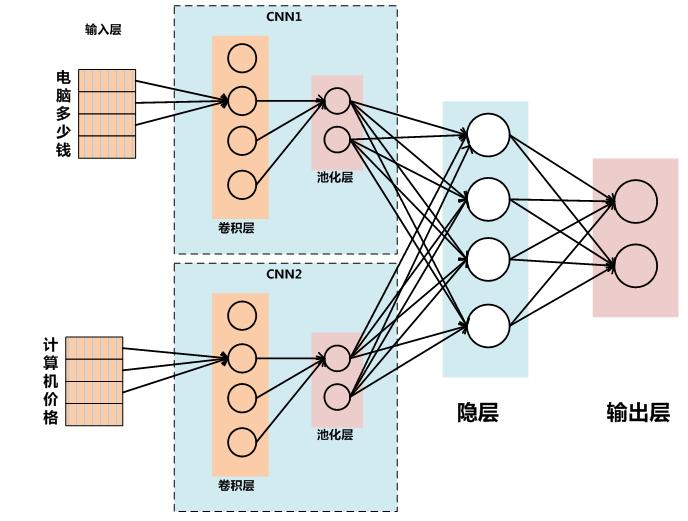
图2 CNN模型1
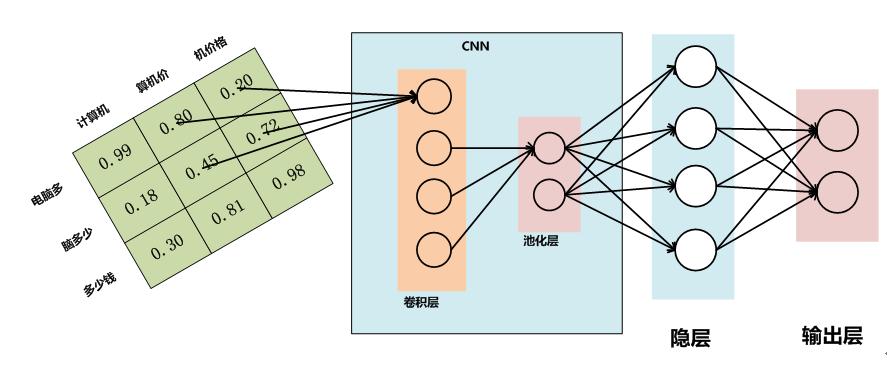
图3 CNN模型2
|实验结果及与两个CNN模型对照
在之前的文章“利用卷积神经网络构造社区问答系统”中我们使用自己构造的实验数据验证了CNN模型2的效果。
之后,我们添加了训练数据的数量,以及加大了负例的难度。事实上在这个社区问答问题中,负例的难度对于实验效果指标影响是比較大的。所谓难度,是指负例中两个句子间语义相关程度究竟有多强,假设负例中两个句子语义相关程度越强,则分类难度越高。
至于模型。我们补充了CNN模型1,在新数据集合下測试了CNN模型2的效果,对于BLSTM来说,则做了双层BLSTM和单层BLSTM的实验。所以能够觉得有四个模型參与效果对照。
经过參数调优,这四个模型在这个新的训练集和測试集下,详细实验结果例如以下:
CNN模型1 分类精度:89.47%
CNN模型2 分类精度:80.08%
双层BLSTM模型 分类精度:84.96%
单层BLSTM模型 分类精度:89.10%
能够看出,在这个问答社区问题里,CNN模型1和单层BLSTM效果接近,而双层BLSTM模型效果有下降。这或许跟实验数据规模不够大有一定关系。所以复杂模型的优势发挥不出来,而CNN模型2则效果相对差些,这或许说明了CNN模型2没有将两个句子的原始信息输入到模型里,而是直接将其关系作为输入,这样的情况下存在信息损失的可能。
致谢:感谢畅捷通智能平台的沈磊、薛会萍、黄通文、桑海岩等同事在模型训练及训练数据的收集整理方面的工作。
















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









