






YOLO是Joseph Redmon为主要作者,在2015年提出的第一个基于单个神经网络的目标检测系统。也是一种新的目标检测算法。在YOLO发布之前,例如RCNN等一系列目标检测算法都是使用二阶段目标检测,YOLO用一阶段代替二阶段,显著提高了算法执行的效率。在精度满足要求的情况下提高了速度,在当时引起了很大的反响。
本文主要是从YOLO的发展过程角度,避免大量文字的输入,只从每一个版本的改进的角度上去分析YOLO。
如果想要学习YOLO-V5如何使用,可以移步去我的这篇文章:https://blog.csdn.net/aosiweixin/article/details/130661330

前三代YOLO是原作者完成的,后面两代是俄罗斯人在原作者的基础上改进得到的。
YOLO-V1
【论文原文】:https://arxiv.org/pdf/1506.02640.pdf
【github地址】:https://github.com/gliese581gg/YOLO_tensorflow
YOLO-V1在2015年提出,它将输入的图片划分为7*7个网格,每个网格中一个锚定点,每个锚定点预测2个边界框,分别用损失函数计算其对应的置信度和类别概率。YOLO-V1网络结构如下图。
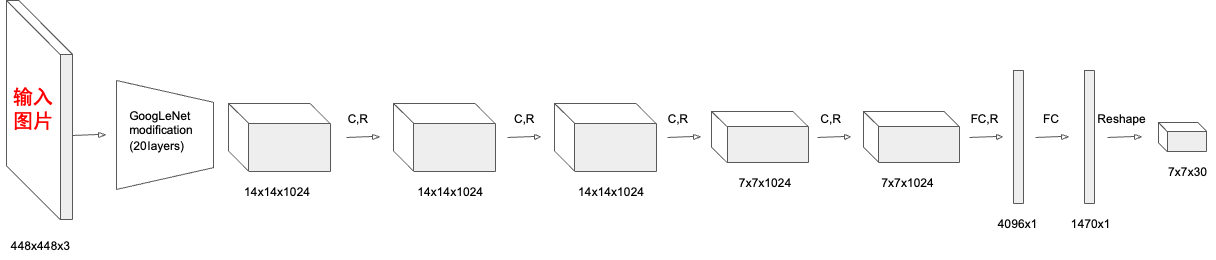
这种网格的构造在最后全连接FC的输出端体现的很明显,输出了一个7✖️7✖️30的张量,7*7就代表划分的网格,30通道的意义在下面解释。
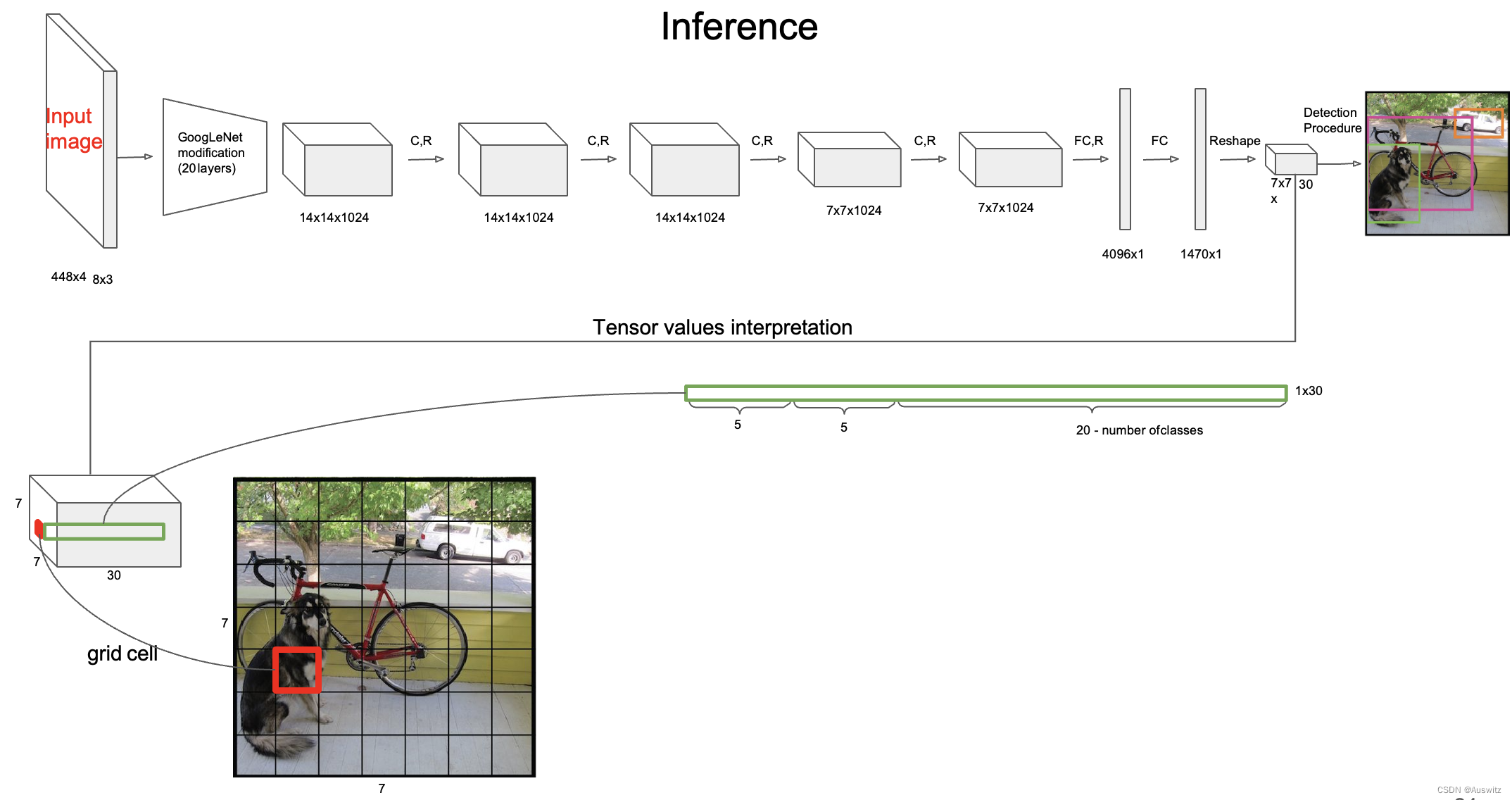
YOLO-V1的特征提取网络使用了简单的卷积神经网络,由24个卷积层和2个全连接层组成,使用了LeakyReLU激活函数来增强网络的线性特征,使用dropout来防止过拟合,经过特征提取网络,特征图被压缩成的张量送入全连接层进行预测,最后得到一个的张量,表示网格,前10个通道表示两个边界框的信息,后20个通道每一个通道表示一个类别。对于每个网格,YOLO选取最高置信度的边界框,再使用标签分配策略非极大值抑制算法去除重叠边界框,最终得到了检测结果。YOLOV1存在一些问题,对重合的物体无法有效检测,小物体无法检测。

YOLO-V2
【论文原文】:https://arxiv.org/pdf/1612.08242.pdf
【github地址】:https://github.com/longcw/yolo2-pytorch
YOLO-V2的提出解决了V1版本的一些问题,舍弃了dropout方法,卷积后都加入Batch Normalization去归一化,加速了收敛速度,有助于避免过拟合,使用了高分辨率训练器,提高了模型的map。【这里的BN做归一化已经是当年AI界的常识,人们发现在卷积后面加入BN可以有效的避免过拟合】
用Darknet 网络作为主干网络,Darknet去掉了全连接层,都使用卷积和池化去操作,减少了参数,同时借助VGG中的思想,使用的卷积核,这些操作有效的在保证精度的情况下提高了运算速度。
V1只有2个边界框,V2采用了聚类的方法,将真实的标签框进行聚类,得到五个更合适的标签框。关于这个聚类算法可以看我的另一篇文章【链接】。
YOLO-V3
【论文原文】:https://arxiv.org/pdf/1804.02767.pdf
【项目链接】:https://pjreddie.com/darknet/yolo/
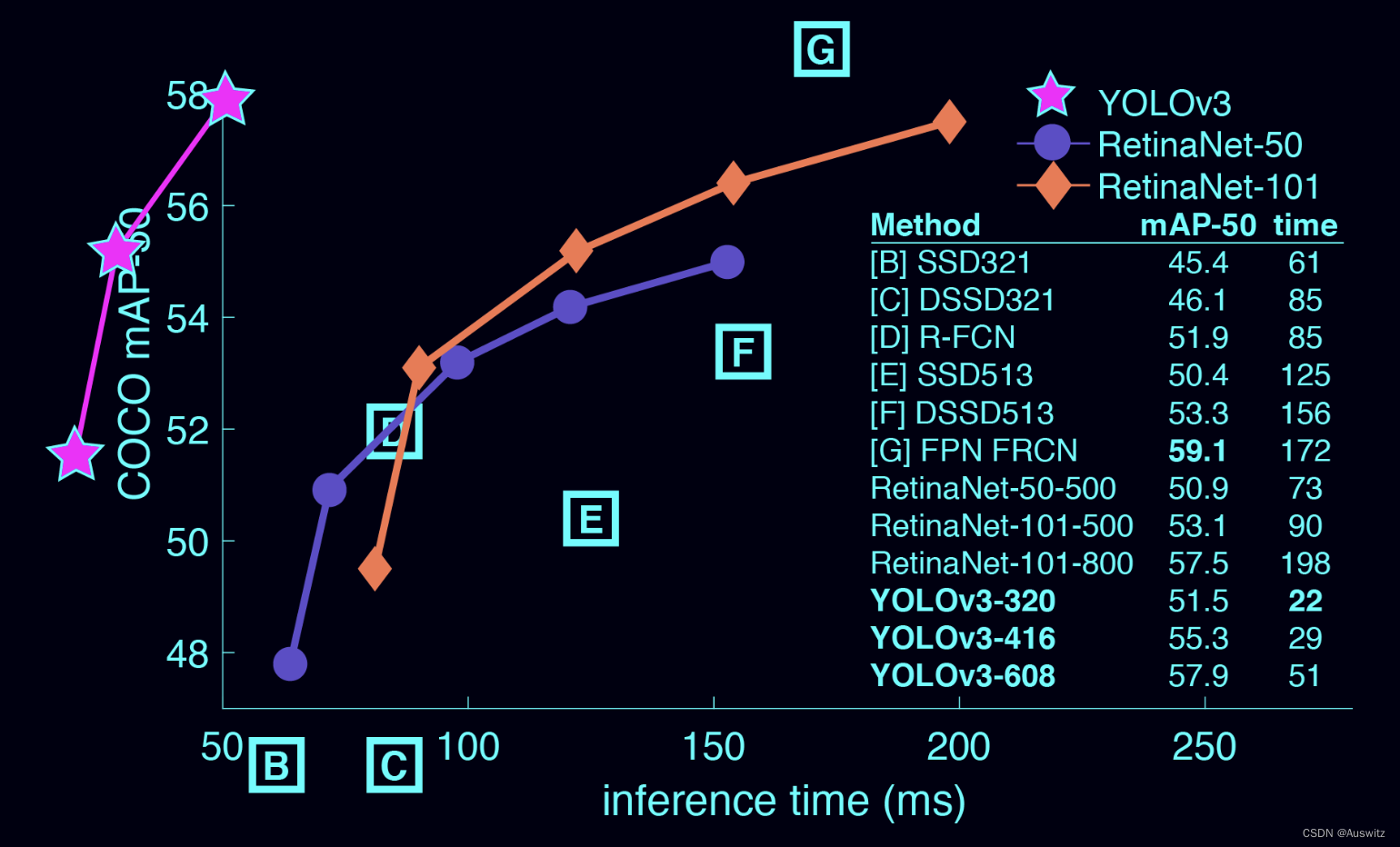
提到YOLO-V3,印象最深刻的就是他论文中用到的这张图。坐标轴之外的YOLO曲线突出了他的检测性能的强大之处。
YOLO-V3在网络结构的设计上提出了很大的更新,特征图提取更细致,使用了多尺度特征图信息来对不同尺寸物体进行识别。这种多尺度特征图不同于以往的输入端图像金字塔的结构,而是在后面将上采样图像与浅层网络特征图进行连接,再将连接后的图片进行预测,下图中1919的用来预测大目标,3838的用来预测中等目标,76*76的用来预测小型目标。
边界框相比于V2的五种,增加至9种。使用改进的SoftMax来预测多标签任务。同时加入了多尺度Scale变换,在网络最后的输出进行上采样再和之前的特征图连接,可以用来对更小目标进行检测。其网络结构图如下:
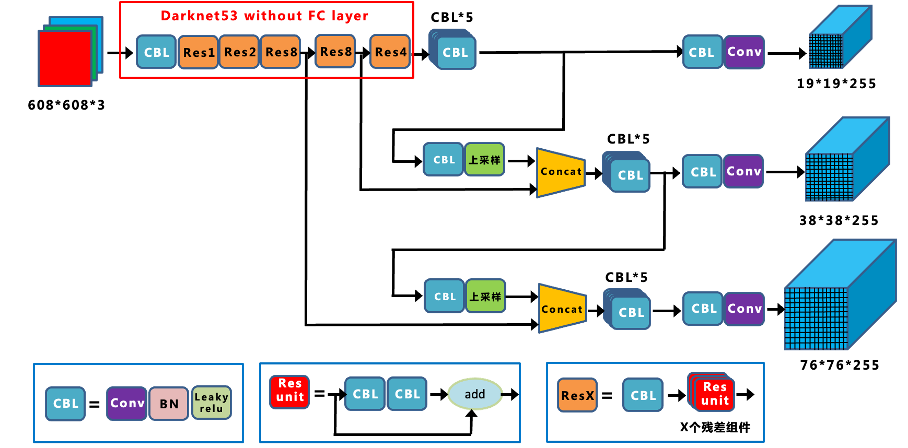
Darknet53结合了残差网络的思想,将网络层数加深,并且取消了全连接和池化层,池化用步长为2的卷积替代,在提高运算速度的同时保留了更多的特征【残差网络的加入能实现更深层网络,避免梯度消失问题】。
YOLO-V4
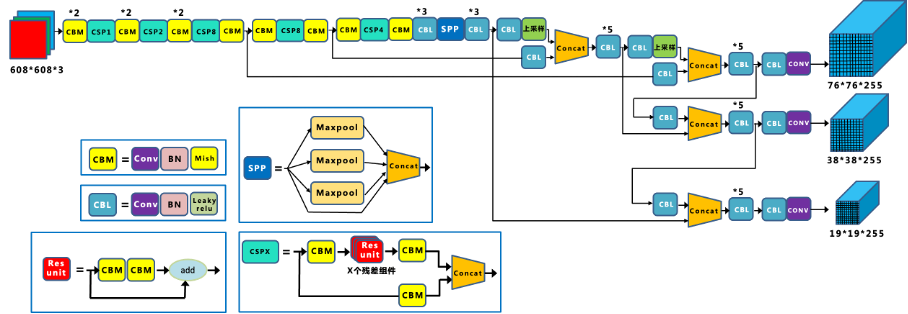
YOLO-V4整体架构和YOLO-V3都相同,只是在V3的基础上加了一些小的改进,在输入端采用了YOLO的数据增强功能,对于后续的训练有很大的帮助。网络部分,将CSP模块融入Darknet53网络,使用Mish激活函数替换了之前V1、V2、V3使用的LeakyReLU激活函数【但是V5官网保留了LeakyReLU激活函数的网络结构,需要手动替换网络文件】。网络结构如图。
YOLO-V5
【github地址】:https://github.com/ultralytics/yolov5
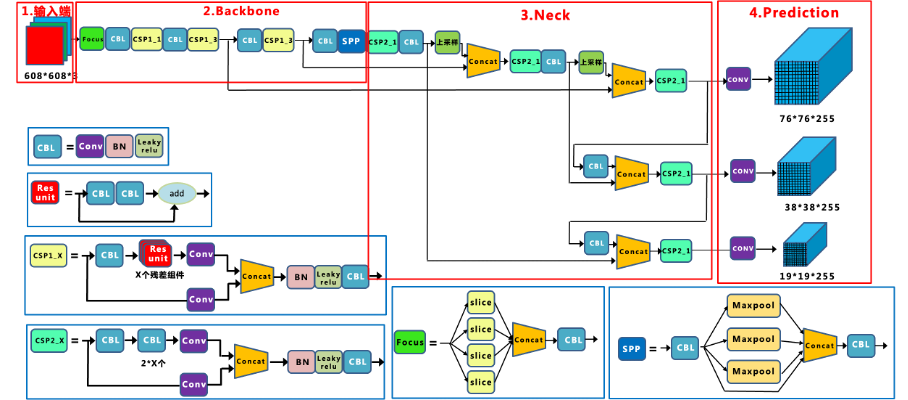
YOLO-V5的结构较V4相比改动不多,主干网络中加入了Focus结构,主干网络也改成了CSP-Darknet,其结构图如图。YOLO-V5在前几代的基础上更进一步,在目标检测上的性能非常好。
参考:
- 江大白老师的YOLO结构图
- YOLO官方的图片

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











