






🤖 快速入门MindSpore AI:打造你的智能助手
基本介绍 || 快速入门 || 张量 Tensor || 数据集 Dataset || 数据变换 Transforms || 网络构建 || 函数式自动微分 || 模型训练 || 保存与加载 || 使用静态图加速
函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter函数与计算图
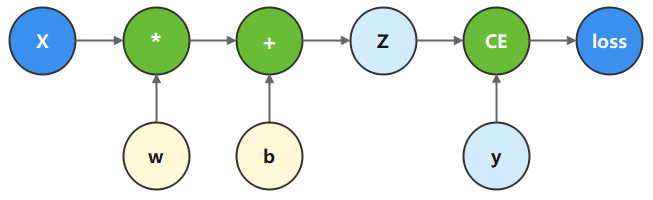
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
扩展:
计算 后使用二元交叉熵(Binary Cross-Entropy)
后面模型的预测 logits(即没有激活函数后的输出),而 y 是真实标签。
这个损失函数会返回一个损失值,该值越小表示模型预测与真实标签更接近,因此模型性能越好。
y初始化为0,所以
在这个模型中,𝑥为输入,𝑦为正确值,𝑤和𝑏是我们需要优化的参数。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias我们根据计算图描述的计算过程,构造计算函数。 其中,binary_cross_entropy_with_logits 是一个损失函数,计算预测值和目标值之间的二值交叉熵损失。
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss执行计算函数,可以获得计算的loss值。
loss = function(x, y, w, b)
print(loss)Tensor(shape=[], dtype=Float32, value= 0.914285)
微分函数与梯度计算
为了优化模型参数,需要求参数对loss的导数:𝜕loss/𝜕𝑤和𝜕loss/𝜕𝑏,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
-
fn:待求导的函数。 -
grad_position:指定求导输入位置的索引。
由于我们对𝑤和𝑏求导,因此配置其在function入参对应的位置(2, 3)。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
grad_fn = mindspore.grad(function, (2, 3))执行微分函数,即可获得𝑤、𝑏对应的梯度。
grads = grad_fn(x, y, w, b)
print(grads)(Tensor(shape=[5, 3], dtype=Float32, value= [[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))
Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, zgrad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)(Tensor(shape=[5, 3], dtype=Float32, value= [[ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00], [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00], [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00], [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00], [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00]]), Tensor(shape=[3], dtype=Float32, value= [ 1.06568694e+00, 1.05373347e+00, 1.30146706e+00]))
可以看到求得𝑤、𝑏对应的梯度值发生了变化。此时如果想要屏蔽掉z对梯度的影响,即仍只求参数对loss的导数,可以使用ops.stop_gradient接口,将梯度在此处截断。我们将function实现加入stop_gradient,并执行。
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)(Tensor(shape=[5, 3], dtype=Float32, value= [[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))
可以看到,求得𝑤、𝑏对应的梯度值与初始function求得的梯度值一致。
Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)((Tensor(shape=[5, 3], dtype=Float32, value= [[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01])), Tensor(shape=[3], dtype=Float32, value= [-1.40476596e+00, -1.64932394e+00, 2.24711204e+00]))
可以看到,求得𝑤、𝑏对应的梯度值与初始function求得的梯度值一致,同时z能够作为微分函数的输出返回。
神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的𝑤、𝑏作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z接下来我们实例化模型和损失函数。
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()完成后,由于需要使用函数式自动微分,需要将神经网络和损失函数的调用封装为一个前向计算函数。
# Define forward function
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss完成后,我们使用value_and_grad接口获得微分函数,用于计算梯度。
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())loss, grads = grad_fn(x, y)
print(grads)(Tensor(shape=[5, 3], dtype=Float32, value= [[ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01], [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 6.56869709e-02, 5.37334494e-02, 3.01467031e-01]))















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









