







inspired by karpathy/micrograd: A tiny scalar-valued autograd engine and a neural net library on top of it with PyTorch-like API (github.com)and Taking PyTorch for Granted | wh (nrehiew.github.io).
这属于karpathy的karpathy/nn-zero-to-hero: Neural Networks: Zero to Hero ,(github.com)课程.事实上他还有很多值得一看的课程和repos.
tensor分成哪些部分?
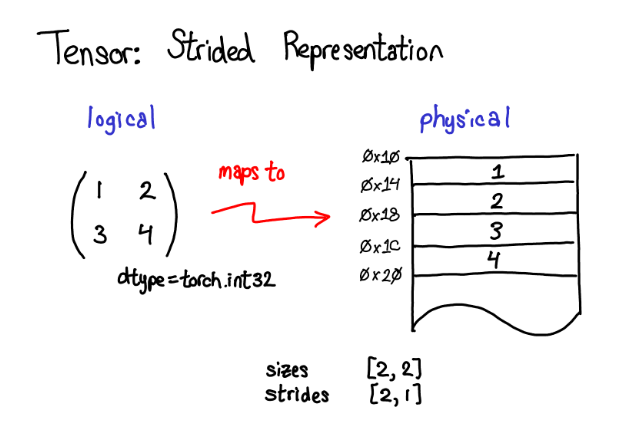
一个tensor可以分为元数据区和存储区(Storage)
信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type),storage_offset,layout等信息,而真正的数据则保存成连续数组,存储在存储区
tensor的存储
tensor数据底层存储是连续的,相对应的就是链表. pytorch使用Storage类存储数据. 可以使用tensor.storage()访问存储的数据
data = torch.arange(9)
print(data.storage().dtype)
print(data.storage().device)
print(data.storage().data_ptr()) #这里 存储数据也能访问数据的属性
All storage classes except for
torch.UntypedStoragewill be removed in the future, andtorch.UntypedStoragewill be used in all cases.
但是在最新的python中除了untypedstorage类其他都已经deprecated了,而在untypedstorage中数据是字节类型,并且也无法调用dtype这些属性,变得更加纯粹了.
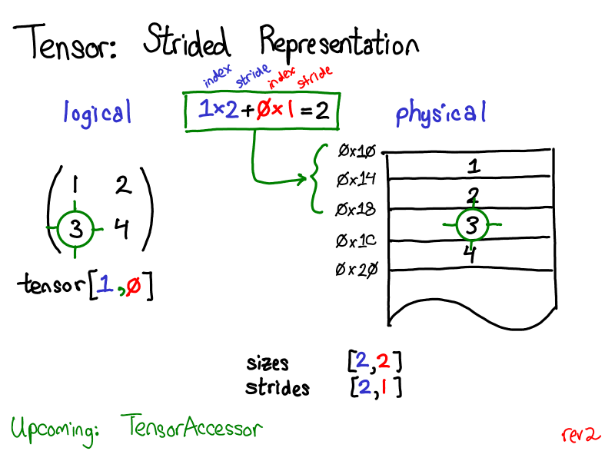
tensor的访问
pytorch数据存储是一维的,但是会根据它的一些元数据改变对它的"解释",而影响解释的元数据就是tride (as_strided可以使得两个tensor的size,stride和storage_offset一致)
stride stride是从一个元素到指定维度的另一个元素的间隔数,如果不指定维度,就返回在每个维度上的stride的tuple
Stride is the jump necessary to go from one element to the next one in the specified dimension
dim.A tuple of all strides is returned when no argument is passed in. Otherwise, an integer value is returned as the stride in the particular dimension
dim.storage_offset 返回tensor的第一个元素与storage的第一个元素的偏移量。
Returns
selftensor’s offset in the underlying storage in terms of number of storage elements (not bytes).x = torch.tensor([1, 2, 3, 4, 5]) x.storage_offset() x[3:].storage_offset()
pytorch中tensor存储区的数据是连续的,而stride规定了如何访问.访问的方式就是
data = torch.randn(1,20,20)
stride = data.stride() # -> (400, 20, 1)
data[0][2][3] -> 0*stride[0]+2*stride[2]+3*stride[3]->也就是说这个数据在第2*20+3*1=43个
注意torch存储数据是行优先,也就是说,像下面这样的数据,第二个是0.6960而不是-0.5163. 所以访问时就类似索引乘以对应的行/列数,从这个角度来看,stride就是一个映射函数.
tensor([[ 1.6427, 0.6960, 0.7865, 0.9934, 0.4952],
[-0.5163, -0.0823, -1.2630, -0.9474, 1.1055],
[ 0.1538, 1.0177, -1.8064, 0.6440, -1.4661],
[ 0.3305, 0.2681, 0.2768, -0.3924, 0.1743],
[-0.8965, -0.5499, -0.4545, -1.1470, 0.6883]])
tensor操作
可以对tensor的数据进行操作,比如下面运算,会改变tensor的存储数据.
data = torch.randn((4, 2))
stride = data.stride()
print(data, stride)
data[0, 1] = 10
print(data, stride)
data.add_(torch.ones((4, 2)))
print(data, stride)
但是有些操作不会,其只会返回数据相同(指的是数据在底层存储上相同)的视图(view),这些操作包括t(),expand,transpose,permute,view,squeeze等等,操作后的tensor数据不变(也就是views),但stride可能会改变,也就是说解释数据的方式会变.
底层存储并没有改变,只需将映射函数从旧形状的坐标系调整为新形状的坐标系。 如果映射函数已经将形状作为输入,那么只需更改形状属性即可。
reshape()、reshape_as()和flatten()可以返回视图或新张量,所以后续代码不要假定它返回的存储数据是否跟原本输入相同.- 如果输入的张量已经连续,
contiguous()会返回自身,否则会通过复制数据返回一个新的连续张量.
下面一个例子报错原因,就是stride的问题,具体来说,这里转置之后stride变了,size没变,使得后续的view操作不满足条件
x = torch.arange(9).reshape(3, 3) # 3 x 3 stride (3,1) size(3,3)
x.t().view(1, -1) # x.t() stride (1,3) size(3,3)
# >> RuntimeError: view size is not compatible with input tensor's
# size and stride. Use .reshape() instead
首先,view作用是返回一个存储数据相同,但shape/size可能不同的视图,要求新的视图与输入数据相兼容( 1.新的视图的每个dimension必须是输入的子空间或者2.新的视图的维度满足下面条件(连续性),否则不能得到新的视图.
假设得到的新的
t
e
n
s
o
r
维度涉及
d
,
.
.
,
d
+
k
,
对其中所有维度要求
:
stride
[
i
]
=
stride
[
i
+
1
]
×
size
[
i
+
1
]
假设得到的新的tensor维度涉及d,..,d+k,对其中所有维度要求:\\ \text{stride}[i]=\text{stride}[i+1]\times\text{size}[i+1]
假设得到的新的tensor维度涉及d,..,d+k,对其中所有维度要求:stride[i]=stride[i+1]×size[i+1]
如果不清楚是否可以执行 view(),建议使用 reshape()
reshape:如果形状兼容,则返回视图,否则返回拷贝(相当于调用 contiguous)
view之后size变为(1,9),这符合条件1,也就是size相符,再看这里(1,9)表明第二个维度跨域(span across)了原本输入的两个维度,而原本输入的两个维度中的第一个维度需要满足连续性条件,但是 stride[0] = 1 , stride[1]*size[1] = 1*3=3 不符合,所以view操作失败.
更抽象地说,因为没有办法在不改变底层数据的情况下对张量进行flatten处理.
我们能否从tensor的stride(3,1)推得tensor size是(3,3)?
答案是不能,它的size也完全可以是(4,3). 反过来size也不能推出stride.
在上面的例子中,比如底层数据是[1,2,3,4,5,6,7,8,9],stride是[3,1]. 也就是说在第一个维度下,数据到相同维度的下个数据间隔为3,同理第二个维度间隔为1,
经过转置之后,因为解释数据的方式变了,因为需要改变解释数据的方式,所以stride需要改变为(1,3). 再进行view(1,-1),如果不报错的话,size就是(1,9),你可能会认为结果不就是[[1,4,7,2,5,8…]]吗,但这个tensor的stride为多少呢? 是(9,1)吗,并不是.为什么呢,
因为底层数据[1,2,3,4,5,6,7,8,9],要查找第二个维度上的数据,比如1到4,在底层数据中是stride是3,而4到7也是3,所以是stride是(9,3),然而这跟size(1,9)不匹配(stride乘起来应该跟size乘起来应该相同,这是最起码的保证).
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
⬇⬇
tensor([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])

tensor的广播
PyTorch 的广播规则:(如何说一个tensor是可广播的)
-
两个张量必须至少有一个维度
-
从最右边的维开始,两个维必须大小相等,其中一个为 1 或者其中一个不存在。
Two tensors are “broadcastable” if the following rules hold:
- Each tensor has at least one dimension.
- When iterating over the dimension sizes, starting at the trailing dimension, the dimension sizes must either be equal, one of them is 1, or one of them does not exist.
Broadcasting semantics — PyTorch 2.3 documentation
If two tensors
x,yare “broadcastable”, the resulting tensor size is calculated as follows:- If the number of dimensions of
xandyare not equal, prepend 1 to the dimensions of the tensor with fewer dimensions to make them equal length. - Then, for each dimension size, the resulting dimension size is the max of the sizes of
xandyalong that dimension.
# from https://nrehiew.github.io/blog/pytorch/
for each dimension, starting from the right:
if both shapes have this dimension:
if they are different:
neither is 1: error
else: use larger dimension
else they are the same: use dimension
else:
use whichever dimension exists
广播,不存在数据copy.这意味着,如果将一个小张量广播到一个大得多的形状,就不会产生内存或性能开销。
其次,由于较小张量中使用的实际元素是相同的,因此梯度会沿着这个较小维度中的项目累积.这在调试梯度或执行涉及广播的自定义自动梯度函数时特别有用。
x=torch.empty(5,1,4,1)
y=torch.empty( 3,1,1)
(x+y).size()
x=torch.empty(1)
y=torch.empty(3,1,7)
(x+y).size()
x=torch.empty(5,2,4,1)
y=torch.empty(3,1,1)
(x+y).size()
如果一个 PyTorch 操作支持广播,那么它的张量数据就会自动扩展为大小相等的数据(无需复制数据),所以本质上也是返回一个视图.
利用矩阵乘法进行广播
矩阵是二维的,但是tensor是不限制的.
多维tensor如何相乘的呢?
- 取两个张量的最后两个维度,检查它们是否可以相乘.如果不能,则出错
- 广播剩余维数.结果形状为 [广播后的维数] + [矩阵乘法的结果形状]。
- 将 [广播后的维数] 作为批处理维度,执行batched matrix multiplication(其实就是矩阵乘法,但是两个相乘的矩阵分别来自不同的batch中的相同的index)
使用torch.matmul进行tensor相乘,它的计算方式如下
-
如果都是一维,进行点乘
-
如果都是二维,进行矩阵乘,如果是1维和二维,在一维度之前添加一个维度在进行矩阵乘,乘完之后再去掉.
-
如果是二维和1维,进行矩阵-向量乘法,得到向量.
-
如果两个参数都至少为 1 维,且至少一个参数为 N 维(N > 2),则返回一个batched matrix multiplication.
如果第一个参数是一维的,那么在进行batched matrix multiplication,会在其维度前添加一维,然后删除.
如果第二个参数是一维的,则在其维度后加上 1,以便进行batched matrix multiply,并在运算后删除.
非矩阵(即批处理)维度将被广播(因此必须是可广播的)
比如(jx1xnxn)和(kxnxn)得到(jxkxnxn),在batch上广播得到(jxk),简单来说就是最后两维(不够进行广播)进行相乘,除了后面两维,其他维度直接进行广播.
注意:广播逻辑在确定输入是否可广播时,只查看批次维度,而不查看矩阵维度。
这跟上面的广播逻辑不同.
a = torch.randn((3, 4, 1, 2)) # 3 x 4 x 1 x 2
b = torch.randn((1, 2, 3)) # 1 x 2 x 3
# Matrix Multiply Shape: 1x2 @ 2x3 -> 1x3
# Batch Shape: We broadcast (3, 4) and (1) -> (3, 4)
# Result shape: 3 x 4 x 1 x 3
c = torch.zeros((3, 4, 1, 3))
# iterate over the batch dimensions of (3, 4)
for i in range(3):
for j in range(4):
a_slice = a[i][j] # 1 x 2
b_slice = b[0] # 2 x 3
c[i][j] = a_slice @ b_slice # 1 x 3
assert torch.equal(torch.matmul(a, b), c)
反向传播
PyTorch 的核心是它的自动微分引擎.一般来说,每次在两个张量之间进行微分操作时,PyTorch 都会通过回调函数自动构建出整个计算图. 然后,当调用 .backward() 时,每个张量的梯度都会被更新. 这是 PyTorch 最大的抽象.
从标量的求导开始扩展到高维,这并不困难.首先需要理解标量的基本运算中的加/减法,乘法,幂、指以及对数.一个softmax操作就包含了加,幂指的操作.
可以将矩阵乘法看作是多个标量值的一系列乘法和加法运算,只需指定这些标量运算的后向运算,两个矩阵相乘的导数就自然而然地产生了.
从标量的角度来考虑梯度还有一个好处,就是可以直观地了解张量操作对梯度的影响。
例如,.reshape()、.transpose()、.cat 和 .split()等操作不会影响单个值及其在标量的梯度。 因此这些操作对张量梯度的影响自然就是操作梯度本身。
例如,使用 .reshape(-1) 对张量进行扁平化处理,对梯度的影响与调用 .reshape(-1) 对张量的梯度的影响相同。
优化
矩阵相乘
不使用 GPU 也能实现的优化方法.
一种可能的优化方法是利用内存访问模式,而不是改变算法。 回想一下,在给定 A @ B 的情况下,我们正在重复计算 A 中的一行和 B 中的一列的点乘.
简单的解决方法是转置,将其转为列主模式(column-first),这样每次从内存加载时,我们就可以在同一缓存行中加载 B 列中的正确项目.
转置是一种O(N) 操作,因此只适用于较大的矩阵.
另一种无需缓存的算法是对矩阵块进行运算,而不是一次性对整个矩阵进行运算。 这就是所谓的块矩阵乘法。 其原理是将矩阵分解成较小的块,然后在这些块上执行矩阵乘法。 这样做的另一个好处是减少了高速缓存的读取次数,因为我们现在是在矩阵的较小块上进行运算。
内存和中间值
这里原文Taking PyTorch for Granted | wh (nrehiew.github.io)似乎有typos,我进行了修正
在反向传播时,符合直觉的想法是保留中间值的梯度,以便后续计算leaf tensor的梯度.但是有些时候并不需要中间值的梯度
比如(a*b)+(c*d)=e,进行反向传播求e在a的梯度时如下
_t1 = a * b
_t2 = c * d
e = _t1 + _t2
其实就是求b,所以并不需要保留_t1和_t2的值.
参考资料
- karpathy/micrograd: A tiny scalar-valued autograd engine and a neural net library on top of it with PyTorch-like API (github.com)
- karpathy/nn-zero-to-hero: Neural Networks: Zero to Hero (github.com)
- karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs. (github.com)
- pytorch笔记(一)——tensor的storage()、stride()、storage_offset()_pytorch storage-CSDN博客
- PyTorch中张量的shape和stride的关系_shape和strides-CSDN博客
- PyTorch internals : ezyang’s blog
















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











