







请大家关注我,我会一直更新下去。欢迎进QQ群交流:323140750大家一起进步、学习。
6.1.4 机器学习在高频交易中的应用
机器学习在高频交易中有许多应用,它们利用大数据和复杂算法来提高交易决策和执行的效率。下面是机器学习在高频交易中的一些常见应用:
- 市场制造(Market Making):机器学习模型可以分析市场数据,识别潜在的买卖信号,并快速调整报价。这可以帮助市场制造商更好地管理他们的交易书,提高点差利润。
- 预测价格趋势:机器学习可以用于分析历史价格和交易数据,以预测资产价格的未来趋势。这有助于高频交易者决定何时买入或卖出。
- 统计套利策略:机器学习模型可以识别潜在的统计套利机会,通过分析相关资产之间的价格差异来决定何时买入或卖出。
- 动态风险管理:机器学习可以用于实时监控交易组合的风险,并在必要时自动执行风险管理策略,例如止损或调整头寸。
- 情感分析:通过自然语言处理和情感分析技术,机器学习可以分析新闻、社交媒体和其他非结构化数据,以了解市场情绪和舆论,从而调整交易策略。
- 交易执行优化:机器学习可以帮助选择最佳的交易执行策略,以减小滑点和交易成本。这包括基于实时市场条件调整订单执行的算法。
- 模型选择和超参数调整:机器学习可以用于选择适合高频交易的模型,并调整模型的超参数以提高性能。
- 监督和非监督学习:监督学习可以用于建立预测模型,而非监督学习可以用于发现市场中的潜在模式和趋势。
- 深度强化学习:深度强化学习可以用于训练智能代理来执行交易决策。这些代理可以通过与市场的互动来不断学习和改进策略。
需要指出的是,机器学习在高频交易中的应用需要高度优化和低延迟的计算能力,因为高频交易涉及在极短的时间内做出决策和执行交易。此外,这些模型也需要不断地进行监督和更新,以适应不断变化的市场条件。风险管理也是至关重要的,以确保不会因机器学习模型的不准确性而产生巨大损失。因此,在高频交易中使用机器学习需要谨慎和专业的方法。
假设某散户被深套在比亚迪(002594.SZ),他为了快速回本,制作了简易的短线做T降低成本的交易策略:涨一块卖5手,跌一块买五手。请看下面的实例,功能是根据这个散户的交易策略在日线图上面绘制买卖点。
实例6-1:针对比亚迪的日内做T交易策略(源码路径:daima/6/ping.py)
实例文件ping.py的具体实现代码如下所示。
import tushare as ts
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题
# 设置Tushare令牌
token = ''
ts.set_token(token)
# 初始化Tushare客户端
pro = ts.pro_api()
# 获取比亚迪股票数据
stock_symbol = '002594.SZ' # 比亚迪的股票代码
# 获取比亚迪的日线数据
data = pro.daily(ts_code=stock_symbol, start_date='20230901', end_date='20230930')
# 将日期字符串转换为日期格式
data['trade_date'] = pd.to_datetime(data['trade_date'])
# 模拟交易策略
buy_price = None
sell_price = None
buy_signal = []
sell_signal = []
for index, row in data.iterrows():
if buy_price is None:
buy_price = row['close'] # 买入价格
elif row['close'] >= buy_price + 1.0: # 当股价涨一块,卖出
sell_price = row['close']
buy_signal.append((row['trade_date'], buy_price))
sell_signal.append((row['trade_date'], sell_price))
buy_price = None
elif row['close'] <= buy_price - 1.0: # 当股价跌一块,买入
buy_price = row['close']
# 绘制日线图
plt.figure(figsize=(12, 6))
plt.plot(data['trade_date'], data['close'], label='Close Price', color='blue')
plt.scatter(*zip(*buy_signal), label='Buy', marker='^', color='green', s=100)
plt.scatter(*zip(*sell_signal), label='Sell', marker='v', color='red', s=100)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('BYD Daily Chart with Buy/Sell Signals - September 2023')
plt.grid(True)
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
在上述代码中,使用Tushare库来获取比亚迪(股票代码:002594.SZ)在2023年9月份的日线股价数据,并针对一个简单的交易策略进行了模拟交易,最后绘制了比亚迪的日线图,并分别标记了买入和卖出点。对上述代码的具体说明如下:
- 首先设置字体为宋体(SimHei),以确保中文显示正常。然后解决图像中的“-”负号的乱码问题。
- 设置Tushare的API令牌,使用Tushare库初始化Tushare客户端,以便访问Tushare的数据接口。
- 使用Tushare的接口获取比亚迪在2023年9月份的日线股价数据,并将数据存储在一个Pandas DataFrame中。
- data['trade_date'] = pd.to_datetime(data['trade_date']):将DataFrame中的日期字符串列转换为日期格式,以便后续处理。
- 模拟交易策略:使用一个简单的交易策略,根据股价涨跌来决定买入和卖出:当股价涨1块以上时卖出,当股价跌1块以上时买入。
- 买入和卖出点的价格和日期会被记录在buy_signal和sell_signal列表中。
- 使用Matplotlib库绘制比亚迪的日线图,其中plt.plot()绘制股价曲线,plt.scatter()用于在图上标记买入和卖出点。
- 最后,使用plt.show()显示绘制的图表。
这段代码绘制了比亚迪在2023年9月份的日线图,并标记了根据交易策略生成的买入和卖出点,如图6-1所示。买入点用绿色的三角形表示,卖出点用红色的倒三角形表示。注意,这只是一个示例,大家可以根据自己的需求和交易策略进行进一步的分析和改进。
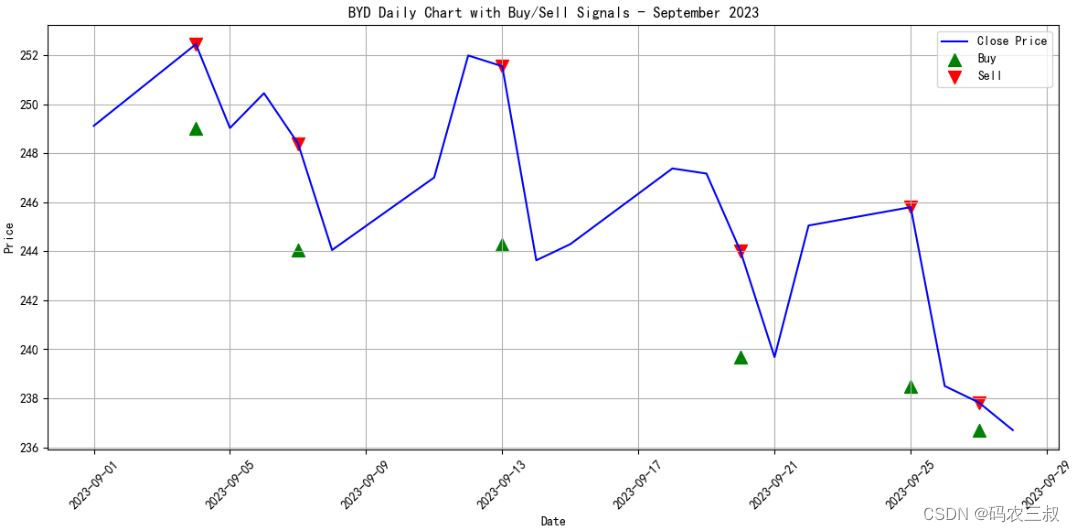
图6-1 比亚迪日线做T交易图
6.1.5 高频交易中的预测建模
在高频交易中,预测建模是一项关键的任务,它旨在使用数据和算法来预测资产价格的未来走势,以实现交易策略的制定和执行。在高频交易中,预测建模的一般步骤和方法如下:
(1)数据收集:首先,收集各种与交易相关的数据,包括市场数据(股票、期货、外汇等价格数据)、交易量、交易订单簿数据、新闻事件、宏观经济指标等。这些数据通常以时间序列的形式存在。
(2)数据预处理
- 清洗和处理原始数据以去除噪声、异常值和缺失值。
- 对数据进行采样或聚合以适应高频交易的时间尺度。
- 特征工程:构建有效的特征来捕捉市场的潜在模式和趋势。
(2)选择模型
- 根据问题的性质选择合适的预测模型,常用的包括时间序列模型(如ARIMA、GARCH)、机器学习模型(如线性回归、随机森林、神经网络)、深度学习模型(如循环神经网络RNN、长短时记忆网络LSTM)等。
- 高频交易通常需要模型具有快速的推断能力,因此通常会选择高效的模型,例如线性模型或基于树的模型。
(3)模型训练
- 使用历史数据来训练选定的模型。训练过程通常包括参数估计、模型选择和性能评估。
- 为了适应高频交易,模型训练可能需要采用滚动窗口的方式,不断更新模型以反映最新的市场情况。
(4)模型评估
- 使用交叉验证或其他评估方法来评估模型的性能。常见的性能指标包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、对数损失等。
- 在高频交易中,模型评估需要考虑交易成本、滑点等因素,因为这些因素对策略的盈利能力产生重要影响。
(5)模型优化
- 根据评估结果对模型进行调整和优化,以提高其预测能力和稳定性。
- 可能需要调整模型的超参数、特征工程、风险管理策略等。
(6)模型部署
- 将训练好的模型部署到实际的高频交易系统中,以执行实时交易决策。
- 需要考虑模型的实时性和性能,确保模型能够在极短的时间内生成预测并执行交易。
(7)监控和维护
- 持续监控模型的性能和策略的盈亏情况,随时进行调整和改进。
- 高频交易中的市场情况可能会发生快速变化,因此需要及时应对。
需要注意的是,高频交易中的预测建模是一个复杂而竞争激烈的领域,需要深入的领域知识、数据分析技能和高效的计算能力。同时,风险管理和执行策略也是至关重要的因素,因为高频交易涉及大量的交易和极短的持仓时间。
实例6-2:针对比亚迪的简易版高频交易大模型(源码路径:daima/6/mo.py)
实例文件mo.py的功能是,利用机器学习和深度学习技术进行金融数据建模,包括特征工程、神经网络模型构建和超参数调整。文件mo.py的具体实现代码如下所示。
# 初始化Tushare客户端
pro = ts.pro_api()
# 获取比亚迪股票数据
stock_symbol = '002594.SZ' # 比亚迪的股票代码
# 获取比亚迪的两年历史日线数据
data = pro.daily(ts_code=stock_symbol, start_date='20210917', end_date='20230917')
# 将日期字符串转换为日期格式
data['trade_date'] = pd.to_datetime(data['trade_date'])
# 更复杂的特征工程:添加技术指标
data['price_change'] = data['close'].diff() # 价格变化
data['volume_change'] = data['vol'].diff() # 成交量变化
# 移动平均线(MA)
data['ma_5'] = data['close'].rolling(window=5).mean()
data['ma_10'] = data['close'].rolling(window=10).mean()
data['ma_20'] = data['close'].rolling(window=20).mean() # 添加20日均线
# 相对强度指数(RSI)
delta = data['price_change']
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['rsi'] = 100 - (100 / (1 + rs))
# 布林带(Bollinger Bands)
data['std'] = data['close'].rolling(window=20).std()
data['upper_band'] = data['ma_20'] + (data['std'] * 2)
data['lower_band'] = data['ma_20'] - (data['std'] * 2)
# 数据预处理:删除NaN值
data = data.dropna()
# 特征和标签
X = data[['price_change', 'volume_change', 'ma_5', 'ma_10', 'ma_20', 'rsi', 'upper_band', 'lower_band']].values[:-1] # 删除最后一行以对齐标签
y = data['close'].shift(-1).dropna().values # 预测下一日的收盘价
# 数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
class ComplexModel(BaseEstimator, TransformerMixin):
def __init__(self, hidden_units=64, learning_rate=0.001):
self.hidden_units = hidden_units
self.learning_rate = learning_rate
self.model = None
def fit(self, X, y):
self.model = nn.Sequential(
nn.Linear(8, self.hidden_units),
nn.ReLU(),
nn.Linear(self.hidden_units, self.hidden_units),
nn.ReLU(),
nn.Linear(self.hidden_units, 1)
)
criterion = nn.MSELoss()
optimizer = optim.Adam(self.model.parameters(), lr=self.learning_rate)
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32).view(-1, 1)
for _ in range(100):
optimizer.zero_grad()
outputs = self.model(X_tensor)
loss = criterion(outputs, y_tensor)
loss.backward()
optimizer.step()
return self
def transform(self, X):
X_tensor = torch.tensor(X, dtype=torch.float32)
with torch.no_grad():
return self.model(X_tensor).numpy()
def predict(self, X):
X_tensor = torch.tensor(X, dtype=torch.float32)
with torch.no_grad():
return self.model(X_tensor).numpy().flatten()
# 创建Pipeline包装模型
estimator = Pipeline([
('model', ComplexModel())
])
# 定义Grid Search的参数空间
param_grid = {
'model__hidden_units': [32, 64, 128],
'model__learning_rate': [0.001, 0.01, 0.1]
}
# 创建Grid Search对象
grid_search = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=3, scoring='neg_mean_squared_error', verbose=2)
# 执行Grid Search
grid_search.fit(X_train, y_train)
# 输出最佳参数组合
best_params = grid_search.best_params_
print("Best Parameters:", best_params)
# 获取最佳模型
best_model = grid_search.best_estimator_
# 在测试集上评估最佳模型
y_pred = best_model.transform(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error with Best Model: {mse}')
上述代码的具体实现流程如下所示:
- 获取比亚迪股票数据:使用Tushare的pro.daily()方法获取比亚迪的两年历史日线数据。
- 特征工程:将日期字符串转换为日期格式,添加了一些技术指标,如价格变化、成交量变化、移动平均线(MA)、相对强度指数(RSI)、布林带(Bollinger Bands)等。
- 数据预处理:删除包含NaN值的行。
- 特征和标签的准备:提取特征和标签,并将它们转换为NumPy数组。删除最后一行以对齐标签。
- 数据划分为训练集和测试集:使用train_test_split函数将数据划分为训练集和测试集。
- 使用PyTorch创建了一个复杂的神经网络模型,包括多个全连接层和ReLU激活函数。使用均方误差(MSE)作为损失函数,Adam优化器进行模型训练。
- 使用Pipeline包装模型:使用Pipeline将神经网络模型包装起来,以便与GridSearchCV一起使用。
- 定义了超参数空间,包括隐藏层单元数和学习率。
- 使用GridSearchCV创建了一个网格搜索对象,以在参数空间中寻找最佳模型参数。
- 执行Grid Search:使用训练集数据执行网格搜索以找到最佳模型参数组合。
- 打印出找到的最佳参数组合,获取具有最佳参数的最佳模型。
- 使用最佳模型在测试集上进行预测,并计算均方误差(MSE)来评估模型性能。
在笔者电脑中执行后会输出:
Fitting 3 folds for each of 9 candidates, totalling 27 fits
[CV] END .model__hidden_units=32, model__learning_rate=0.001; total time= 0.2s
[CV] END .model__hidden_units=32, model__learning_rate=0.001; total time= 0.2s
[CV] END .model__hidden_units=32, model__learning_rate=0.001; total time= 0.2s
[CV] END ..model__hidden_units=32, model__learning_rate=0.01; total time= 0.2s
[CV] END ..model__hidden_units=32, model__learning_rate=0.01; total time= 0.3s
[CV] END ..model__hidden_units=32, model__learning_rate=0.01; total time= 0.4s
[CV] END ...model__hidden_units=32, model__learning_rate=0.1; total time= 0.4s
[CV] END ...model__hidden_units=32, model__learning_rate=0.1; total time= 0.4s
[CV] END ...model__hidden_units=32, model__learning_rate=0.1; total time= 0.5s
[CV] END .model__hidden_units=64, model__learning_rate=0.001; total time= 0.6s
[CV] END .model__hidden_units=64, model__learning_rate=0.001; total time= 0.8s
[CV] END .model__hidden_units=64, model__learning_rate=0.001; total time= 0.6s
[CV] END ..model__hidden_units=64, model__learning_rate=0.01; total time= 0.6s
[CV] END ..model__hidden_units=64, model__learning_rate=0.01; total time= 0.5s
[CV] END ..model__hidden_units=64, model__learning_rate=0.01; total time= 0.5s
[CV] END ...model__hidden_units=64, model__learning_rate=0.1; total time= 0.4s
[CV] END ...model__hidden_units=64, model__learning_rate=0.1; total time= 0.5s
[CV] END ...model__hidden_units=64, model__learning_rate=0.1; total time= 0.5s
[CV] END model__hidden_units=128, model__learning_rate=0.001; total time= 0.6s
[CV] END model__hidden_units=128, model__learning_rate=0.001; total time= 0.6s
[CV] END model__hidden_units=128, model__learning_rate=0.001; total time= 0.6s
[CV] END .model__hidden_units=128, model__learning_rate=0.01; total time= 0.6s
[CV] END .model__hidden_units=128, model__learning_rate=0.01; total time= 0.7s
[CV] END .model__hidden_units=128, model__learning_rate=0.01; total time= 0.6s
[CV] END ..model__hidden_units=128, model__learning_rate=0.1; total time= 0.7s
[CV] END ..model__hidden_units=128, model__learning_rate=0.1; total time= 0.5s
[CV] END ..model__hidden_units=128, model__learning_rate=0.1; total time= 0.6s
Best Parameters: {'model__hidden_units': 32, 'model__learning_rate': 0.01}
Mean Squared Error with Best Model: 1235.542134373023
注意:本实例处理的是比亚迪股票的日线数据,即每日的股票价格和交易数据。这是相对较低频的数据,因为它们是每日的快照。而高频交易通常涉及更高频的数据,例如秒级或毫秒级的数据,因为高频交易需要更快的决策和执行速度。在Tushare中也提供了更加高频的数据,例如分钟级别和秒级别的数据,但是这些高频的数据要单独收费。请大家缴纳费用,使用上述代码即可实现高频交易的大模型。
6.1.6 量化交易框架
在市场中有很多开源的A股量化交易框架和相关的源码,在下面列出了一些常见的A股量化交易框架和相关资源:
- vn.py:是一个针对中国A股市场的量化交易框架,它提供了易于使用的API,并支持多个券商的接口。你可以在 GitHub 上找到 vn.py 的源码和文档。
- RQAlpha:是使用 Python 编写的开源量化交易平台,支持A股市场。它提供了丰富的数据源和策略回测功能,可以帮助你开发和测试量化交易策略。
- QuantConnect:是一个基于云的量化交易平台,它支持多个市场,包括A股。你可以使用它的开源框架 Lean 来开发和测试策略。
- Alpha360:是一个用于量化交易研究和策略开发的开源框架,它支持A股市场,并提供了许多常用的技术指标和策略示例。
- ricequant:是一个量化交易社区,提供了量化策略回测平台和在线编程环境,支持A股市场。
- easytrader:是一个用于中国A股市场的量化交易框架,它允许开发人员编写自动化交易策略并执行交易。这个库的目标是简化股票交易策略的开发和执行,使其更加容易。
上面介绍的这些框架和平台通常提供了丰富的文档和示例代码,可以帮助大家入门量化交易并开发自己的交易策略。开发者可以根据自己的需求和编程技能选择合适的框架来开始量化交易的研究和实践。在使用这些框架时,务必谨慎测试和验证你的策略,量化交易涉及风险,需要谨慎对待。

















 4861
4861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











