







在"notebooks" 目录中保存了和数据处理相关的Notebook文件:data_cleaning.ipynb、eda_feature_eng.ipynb和initial_analysis.ipynb。
12.5.1 初步分析
文件initial_analysis.ipynb实现对数据的初步分析功能,对数据集进行初步的探索,获取数据的基本信息、形状和分布。这有助于你对数据集有一个整体的了解,并为后续的分析和处理做好准备。文件initial_analysis.ipynb的具体实现流程如下:
(1)读取数据集中articles主表的数据,并将其存储在名为 df_articles 的 DataFrame 中,然后展示 DataFrame 的前三行数据。对应的实现代码如下所示:
ARTICLES_MASTER_TABLE = os.path.join(PROJECT_ROOT,
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','data_folders'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','raw_data'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','article_data'),
)
df_articles = pd.read_csv(ARTICLES_MASTER_TABLE)
df_articles.head(3)执行后会输出;
article_id product_code prod_name product_type_no product_type_name product_group_name graphical_appearance_no graphical_appearance_name colour_group_code colour_group_name ... department_name index_code index_name index_group_no index_group_name section_no section_name garment_group_no garment_group_name detail_desc
0 108775015 108775 Strap top 253 Vest top Garment Upper body 1010016 Solid 9 Black ... Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic Jersey top with narrow shoulder straps.
1 108775044 108775 Strap top 253 Vest top Garment Upper body 1010016 Solid 10 White ... Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic Jersey top with narrow shoulder straps.
2 108775051 108775 Strap top (1) 253 Vest top Garment Upper body 1010017 Stripe 11 Off White ... Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic Jersey top with narrow shoulder straps.
3 rows × 25 columns(2)通过如下代码获取 DataFrame 的形状信息,即数据框中的观测数量和变量数量。执行后返回一个元组,其中包含 DataFrame df_articles 的行数和列数。
df_articles.shape执行后会输出:
(105542, 25)(3)通过如下代码获取 DataFrame 的列标签,即数据框中的变量名称。执行后返回一个包含 DataFrame df_articles 的列名的索引对象。
df_articles.columns执行后会输出:
Index(['article_id', 'product_code', 'prod_name', 'product_type_no',
'product_type_name', 'product_group_name', 'graphical_appearance_no',
'graphical_appearance_name', 'colour_group_code', 'colour_group_name',
'perceived_colour_value_id', 'perceived_colour_value_name',
'perceived_colour_master_id', 'perceived_colour_master_name',
'department_no', 'department_name', 'index_code', 'index_name',
'index_group_no', 'index_group_name', 'section_no', 'section_name',
'garment_group_no', 'garment_group_name', 'detail_desc'],
dtype='object')(4)通过如下代码对 DataFrame df_articles 进行空值检查的操作,返回一个包含每列空值数量的 Series 对象,其中每个列名对应的值表示该列中的空值数量。
df_articles.isnull().sum()执行后会输出:
article_id 0
product_code 0
prod_name 0
product_type_no 0
product_type_name 0
product_group_name 0
graphical_appearance_no 0
graphical_appearance_name 0
colour_group_code 0
colour_group_name 0
perceived_colour_value_id 0
perceived_colour_value_name 0
perceived_colour_master_id 0
perceived_colour_master_name 0
department_no 0
department_name 0
index_code 0
index_name 0
index_group_no 0
index_group_name 0
section_no 0
section_name 0
garment_group_no 0
garment_group_name 0
detail_desc 416
dtype: int64具体来说,df_articles.isnull() 返回一个布尔类型的 DataFrame,其中每个单元格的值为 True(如果是空值)或 False(如果不是空值)。然后,方法sum()对每列进行求和,将 True 的数量累加,从而得到每列的空值数量。这对于了解 DataFrame 中的缺失数据情况非常有用,可以帮助数据分析人员决定如何处理这些缺失值。
(5)通过如下代码返回 DataFrame df_articles 中第 5 行的数据。
df_articles.iloc[5]执行后会输出:
article_id 110065011
product_code 110065
prod_name OP T-shirt (Idro)
product_type_no 306
product_type_name Bra
product_group_name Underwear
graphical_appearance_no 1010016
graphical_appearance_name Solid
colour_group_code 12
colour_group_name Light Beige
perceived_colour_value_id 1
perceived_colour_value_name Dusty Light
perceived_colour_master_id 11
perceived_colour_master_name Beige
department_no 1339
department_name Clean Lingerie
index_code B
index_name Lingeries/Tights
index_group_no 1
index_group_name Ladieswear
section_no 61
section_name Womens Lingerie
garment_group_no 1017
garment_group_name Under-, Nightwear
detail_desc Microfibre T-shirt bra with underwired, moulde...
Name: 5, dtype: object(6)通过如下代码获取 DataFrame df_articles 中的前 10 行和除最后一列之外的所有列的数据。
df_articles.iloc[0:10,:-1]执行后返回一个包含前 10 行和除最后一列之外的所有列数据的 DataFrame:
article_id product_code prod_name product_type_no product_type_name product_group_name graphical_appearance_no graphical_appearance_name colour_group_code colour_group_name ... department_no department_name index_code index_name index_group_no index_group_name section_no section_name garment_group_no garment_group_name
0 108775015 108775 Strap top 253 Vest top Garment Upper body 1010016 Solid 9 Black ... 1676 Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic
1 108775044 108775 Strap top 253 Vest top Garment Upper body 1010016 Solid 10 White ... 1676 Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic
2 108775051 108775 Strap top (1) 253 Vest top Garment Upper body 1010017 Stripe 11 Off White ... 1676 Jersey Basic A Ladieswear 1 Ladieswear 16 Womens Everyday Basics 1002 Jersey Basic
3 110065001 110065 OP T-shirt (Idro) 306 Bra Underwear 1010016 Solid 9 Black ... 1339 Clean Lingerie B Lingeries/Tights 1 Ladieswear 61 Womens Lingerie 1017 Under-, Nightwear
4 110065002 110065 OP T-shirt (Idro) 306 Bra Underwear 1010016 Solid 10 White ... 1339 Clean Lingerie B Lingeries/Tights 1 Ladieswear 61 Womens Lingerie 1017 Under-, Nightwear
5 110065011 110065 OP T-shirt (Idro) 306 Bra Underwear 1010016 Solid 12 Light Beige ... 1339 Clean Lingerie B Lingeries/Tights 1 Ladieswear 61 Womens Lingerie 1017 Under-, Nightwear
6 111565001 111565 20 den 1p Stockings 304 Underwear Tights Socks & Tights 1010016 Solid 9 Black ... 3608 Tights basic B Lingeries/Tights 1 Ladieswear 62 Womens Nightwear, Socks & Tigh 1021 Socks and Tights
7 111565003 111565 20 den 1p Stockings 302 Socks Socks & Tights 1010016 Solid 13 Beige ... 3608 Tights basic B Lingeries/Tights 1 Ladieswear 62 Womens Nightwear, Socks & Tigh 1021 Socks and Tights
8 111586001 111586 Shape Up 30 den 1p Tights 273 Leggings/Tights Garment Lower body 1010016 Solid 9 Black ... 3608 Tights basic B Lingeries/Tights 1 Ladieswear 62 Womens Nightwear, Socks & Tigh 1021 Socks and Tights
9 111593001 111593 Support 40 den 1p Tights 304 Underwear Tights Socks & Tights 1010016 Solid 9 Black ... 3608 Tights basic B Lingeries/Tights 1 Ladieswear 62 Womens Nightwear, Socks & Tigh 1021 Socks and Tights
10 rows × 24 columns在数据集中有如下两列重要信息:
- "desc_detail" 是关于商品的简要信息。但有416个商品没有提供这些详细信息。因此,我们将不使用这个特征进行商品嵌入。
- "product_name" 中包含像"(1)"这样的特殊字符和数字。虽然我们可以删除特殊字符,但是有些商品名称中包含了数字,例如以套装形式出售的袜子,其中名称中包含了套装中的商品数量。如果我们使用这个特征,需要在处理"product_name"时考虑这种情况。
哪些特征组合可能对描述商品并对交易数据进行探索性数据分析有帮助呢?
(7)通过如下代码返回列product_type_name中唯一的值,它会返回一个包含所有不重复的产品类型名称的数组。这个操作可以帮助我们了解数据集中有哪些不同的产品类型。
df_articles.product_type_name.unique() 执行后会输出:
array(['Vest top', 'Bra', 'Underwear Tights', 'Socks', 'Leggings/Tights',
'Sweater', 'Top', 'Trousers', 'Hair clip', 'Umbrella',
'Pyjama jumpsuit/playsuit', 'Bodysuit', 'Hair string', 'Unknown',
'Hoodie', 'Sleep Bag', 'Hair/alice band', 'Belt', 'Boots',
'Bikini top', 'Swimwear bottom', 'Underwear bottom', 'Swimsuit',
'Skirt', 'T-shirt', 'Dress', 'Hat/beanie', 'Kids Underwear top',
'Shorts', 'Shirt', 'Cap/peaked', 'Pyjama set', 'Sneakers',
'Sunglasses', 'Cardigan', 'Gloves', 'Earring', 'Bag', 'Blazer',
'Other shoe', 'Jumpsuit/Playsuit', 'Sandals', 'Jacket', 'Costumes',
'Robe', 'Scarf', 'Coat', 'Other accessories', 'Polo shirt',
'Slippers', 'Night gown', 'Alice band', 'Straw hat', 'Hat/brim',
'Tailored Waistcoat', 'Necklace', 'Ballerinas', 'Tie',
'Pyjama bottom', 'Felt hat', 'Bracelet', 'Blouse',
'Outdoor overall', 'Watch', 'Underwear body', 'Beanie', 'Giftbox',
'Sleeping sack', 'Dungarees', 'Outdoor trousers', 'Wallet',
'Swimwear set', 'Swimwear top', 'Flat shoe', 'Garment Set', 'Ring',
'Waterbottle', 'Wedge', 'Long John', 'Outdoor Waistcoat', 'Pumps',
'Flip flop', 'Braces', 'Bootie', 'Fine cosmetics',
'Heeled sandals', 'Nipple covers', 'Chem. cosmetics', 'Soft Toys',
'Hair ties', 'Underwear corset', 'Bra extender', 'Underdress',
'Underwear set', 'Sarong', 'Leg warmers', 'Blanket', 'Hairband',
'Tote bag', 'Weekend/Gym bag', 'Cushion', 'Backpack', 'Earrings',
'Bucket hat', 'Flat shoes', 'Heels', 'Cap', 'Shoulder bag',
'Side table', 'Accessories set', 'Headband', 'Baby Bib',
'Keychain', 'Dog Wear', 'Washing bag', 'Sewing kit',
'Cross-body bag', 'Moccasins', 'Towel', 'Wood balls',
'Zipper head', 'Mobile case', 'Pre-walkers', 'Toy', 'Marker pen',
'Bumbag', 'Dog wear', 'Eyeglasses', 'Wireless earphone case',
'Stain remover spray', 'Clothing mist'], dtype=object)(8)通过如下代码返回列product_group_name中唯一的值,这个操作可以帮助我们了解数据集中有哪些不同的产品组。
df_articles.product_group_name.unique()执行后会返回一个包含所有不重复的产品组名称的数组:
array(['Garment Upper body', 'Underwear', 'Socks & Tights',
'Garment Lower body', 'Accessories', 'Items', 'Nightwear',
'Unknown', 'Underwear/nightwear', 'Shoes', 'Swimwear',
'Garment Full body', 'Cosmetic', 'Interior textile', 'Bags',
'Furniture', 'Garment and Shoe care', 'Fun', 'Stationery'],
dtype=object)(9)通过如下代码返回 index_name 列中唯一的值。它会返回一个包含所有不重复的索引名称的数组。这个操作可以帮助我们了解数据集中有哪些不同的索引名称。
df_articles.index_name.unique()执行后会输出:
array(['Ladieswear', 'Lingeries/Tights', 'Baby Sizes 50-98', 'Menswear',
'Ladies Accessories', 'Sport', 'Children Sizes 92-140', 'Divided',
'Children Sizes 134-170', 'Children Accessories, Swimwear'],
dtype=object)(10)我们在 "colour_group_name"、"graphical_appearance_name"、"garment_group_name" 和 "product_type_name" 特征中有一个 "Unknown" 的标签类型,如果对任何物品进行交易,我们需要考虑这些标签。当与交易表进行合并时,我们可能需要处理其中的任何记录。要查看实际的物品,请访问 H&M 网站的产品页面,并在URL中输入文章ID,它将显示该物品。例如:
https://www2.hm.com/en_us/productpage.0743722002.html - 美国站点
https://www2.hm.com/en_in/productpage.0811198001.html - 印度站点每个 article_id 应该是长度为10,因此,在前面补充0以获取产品详细页面。通过如下代码统计每个产品代码(product_code)的出现次数,并按降序重置索引,将列名改为 'no_count'。然后将索引列名改为 'product_code',将上述统计结果与 df_articles 数据框中的 'product_code' 和 'prod_name' 列进行合并。使用 'product_code' 列作为合并键,使用内连接方式进行合并。
最后将合并结果存储在变量 data 中。接下来,打印 data 中前 10 个产品代码的数据。
data = (df_articles['product_code'].value_counts()
.reset_index(name = 'no_count')
.rename(columns = {'index':'product_code'})
.merge(df_articles[['product_code','prod_name']]
.groupby('product_code')
.nth(0)
.reset_index(),
on = 'product_code',
how = 'inner'
)
)
#Top 20 product code
data[:10]执行后会输出:
product_code no_count prod_name
0 783707 75 1pk Fun
1 684021 70 Wow printed tee 6.99
2 699923 52 Mike tee
3 699755 49 Yate
4 685604 46 TOM FANCY
5 739659 44 Dragonfly dress
6 664074 41 Charlie Top
7 570002 41 ROY SLIM RN T-SHIRT
8 562245 41 Luna skinny RW
9 685816 41 RONNY REG RN T-SHIRT(11)在数据集中大约有47,000个独特的产品代码对应着105,000个商品。这意味着大约有49%的商品具有相同的产品代码,只是颜色等方面存在差异。这在从图像生成商品嵌入时将会有所帮助。接下来让我们随机抽样一些产品代码,比较这些商品,看看它们之间的差异。对应的实现代码如下所示:
# 随机选择商品,并显示商品的图片和详细信息
groupby = "product_code"
hlpimage.show_item_img_detail(items=hlpdf.random_sample_by_catagory(df=df_articles, filter='', group_by=groupby, no_sample=15),
show_item_detail=False)
# 随机选择一个具有大约75个独特商品的商品
hlpimage.show_item_img_detail(df_articles[df_articles.product_code == 783707])
# 设置筛选条件和分组方式,显示随机选择的商品的图片和详细信息
filter = {'index_group_name': 'Baby/Children'}
groupby = "product_group_name"
hlpimage.show_item_img_detail(items=hlpdf.random_sample_by_catagory(df_articles, filter, groupby, no_sample=4),
show_item_detail=True)
# 设置筛选条件和分组方式,显示随机选择的商品的图片和详细信息
filter = {'index_group_name': 'Ladieswear'}
groupby = "product_group_name"
hlpimage.show_item_img_detail(items=hlpdf.random_sample_by_catagory(df_articles, filter, groupby, no_sample=4),
show_item_detail=True)
# 根据筛选条件过滤数据,并显示前5行(除最后一列)
filter = (df_articles.index_group_name == "Baby/Children") & (df_articles.product_type_name == "Fine cosmetics")
df_articles[filter].iloc[:5, :-1]
# 设置显示的最大行数。None:无限制
# pd.set_option('display.max_rows', None)
# pd.set_option('display.max_rows', 50) #此设置无效
# 获取指定列的索引值
col_index = df_articles.columns.get_indexer(['article_id', 'product_code', 'prod_name', 'product_type_name',
'product_group_name', 'index_name', 'index_group_name',
'garment_group_name'])
# 随机选择50个商品进行分析
# replace=True表示可以多次选择相同的值
chosen_idx = np.random.choice(df_articles.shape[0], replace=False, size=50)
df_articles.iloc[chosen_idx, col_index]
# pd.reset_option('display.max_rows') # 重置最大行数设置,恢复默认
# 可以假设article_id是递增的,即新商品添加到目录时,编号递增
sorted(df_articles.article_id.unique())[:15] # 此处的商品编号并不是按递增顺序排列
# 商品的编号不是按照递增顺序排列的上述代码的实现流程如下:
- 随机选择一些商品,并显示它们的图片和基本信息。
- 随机选择一个具有大约75个独特商品的商品,并显示其图片和详细信息。
- 使用特定的筛选条件和分组方式,随机选择一些商品,并显示它们的图片和详细信息。
- 根据特定的筛选条件过滤数据,并显示满足条件的商品的前5行(不包括最后一列)。
- 设置要显示的最大行数和指定列的索引值,然后随机选择一些商品进行分析,并显示所选列的数据。
- 检查商品编号是否按递增顺序排列,发现它们并不是按递增顺序排列的。
(12)开始处理Customer数据,首先读取客户主数据文件并将其存储到名为df_customer的DataFrame中。对应的实现代码如下所示:
CUSTOMER_MASTER_TABLE = os.path.join(PROJECT_ROOT,
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','data_folders'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','raw_data'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','customer_data'),
)
df_customer = hlpread.read_csv(CUSTOMER_MASTER_TABLE)
df_customer.head()执行后输出:
customer_id FN Active club_member_status fashion_news_frequency age postal_code
0 00000dbacae5abe5e23885899a1fa44253a17956c6d1c3... NaN NaN ACTIVE NONE 49.0 52043ee2162cf5aa7ee79974281641c6f11a68d276429a...
1 0000423b00ade91418cceaf3b26c6af3dd342b51fd051e... NaN NaN ACTIVE NONE 25.0 2973abc54daa8a5f8ccfe9362140c63247c5eee03f1d93...
2 000058a12d5b43e67d225668fa1f8d618c13dc232df0ca... NaN NaN ACTIVE NONE 24.0 64f17e6a330a85798e4998f62d0930d14db8db1c054af6...
3 00005ca1c9ed5f5146b52ac8639a40ca9d57aeff4d1bd2... NaN NaN ACTIVE NONE 54.0 5d36574f52495e81f019b680c843c443bd343d5ca5b1c2...
4 00006413d8573cd20ed7128e53b7b13819fe5cfc2d801f... 1.0 1.0 ACTIVE Regularly 52.0 25fa5ddee9aac01b35208d01736e57942317d756b32ddd...具体来说,上述代码使用函数os.path.join()将项目根目录(PROJECT_ROOT)与配置文件中指定的数据文件夹路径、原始数据文件路径和客户数据文件名进行连接,从而生成客户主数据文件的完整路径。然后,hlpread.read_csv函数被调用,该函数接受完整路径作为参数,并读取CSV文件内容到df_customer DataFrame中。最后,使用head函数查看df_customer DataFrame的前几行数据。
(13)使用Seaborn库和Matplotlib库绘制了关于顾客年龄的可视化图表,可视化分析顾客的年龄分布情况,通过箱线图和直方图展示了不同的视角,帮助我们更好地理解和分析顾客年龄的特征。对应的实现代码如下所示:
sns.boxplot(x = df_customer.age)
sns.displot(df_customer, x = "age", binwidth = 5)
plt.show()执行后的效果如图12-1所示。
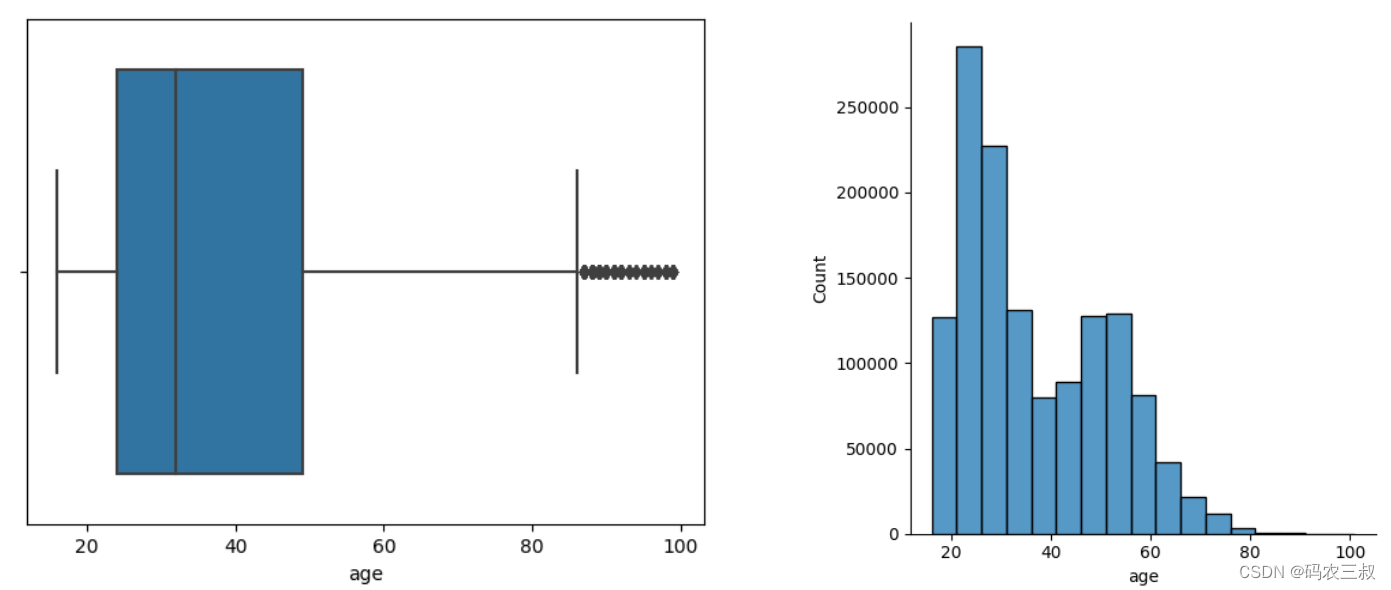
图12-1 顾客年龄的可视化图
(14)开始处理交易数据,首先通过如下代码读取交易数据文件,并将其存储在名为df_transaction的Pandas DataFrame中。对应的实现代码如下所示:
TRANSACTION_DATA_TABLE = os.path.join(PROJECT_ROOT,
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','data_folders'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','raw_data'),
hlpread.read_yaml_key(os.path.join(PROJECT_ROOT, CONFIGURATION_PATH),'data_source','transaction_data'),
)
df_transaction = pd.read_csv(TRANSACTION_DATA_TABLE,
parse_dates = ['t_dat'],
)
df_transaction.head()执行后输出:
t_dat customer_id article_id price sales_channel_id
0 2018-09-20 000058a12d5b43e67d225668fa1f8d618c13dc232df0ca... 663713001 0.050831 2
1 2018-09-20 000058a12d5b43e67d225668fa1f8d618c13dc232df0ca... 541518023 0.030492 2
2 2018-09-20 00007d2de826758b65a93dd24ce629ed66842531df6699... 505221004 0.015237 2
3 2018-09-20 00007d2de826758b65a93dd24ce629ed66842531df6699... 685687003 0.016932 2
4 2018-09-20 00007d2de826758b65a93dd24ce629ed66842531df6699... 685687004 0.016932 2(15)计算交易数据中的最早日期和最晚日期,并打印输出这两个日期的信息。对应的实现代码如下所示:
max_t_date = df_transaction.t_dat.max()
min_t_date = df_transaction.t_dat.min()
print(f'Transaction records from: {min_t_date} to {max_t_date}')(16)创建一个计数条形图来显示不同销售渠道的交易记录数量,并设置相应的标签和图例。对应的实现代码如下所示:
ax = sns.countplot(
data = df_transaction,
x = 'sales_channel_id',
hue ='sales_channel_id',
)
ax.set_xlabel("Sales Channel")
ax.set_ylabel("Count")
ax.legend(labels = ['Offline', 'Online'])执行后的效果如图12-2所示。
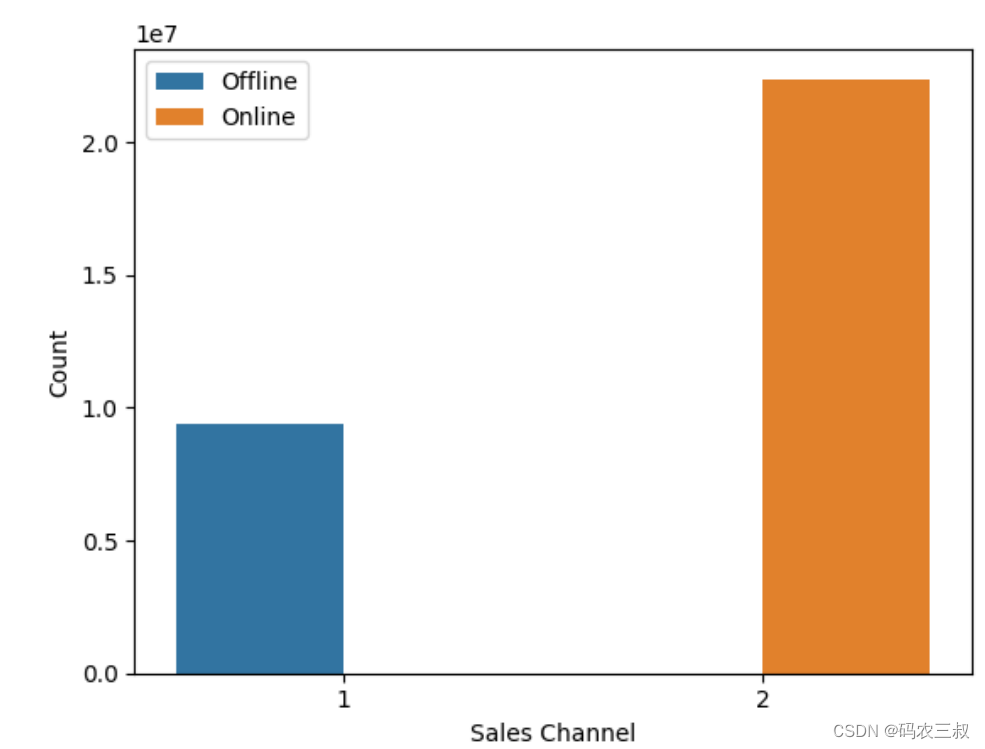
图12-2 可视化不同销售渠道(线上、线下)的交易记录数量



















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











