








11.12 结果分析
这是本项目的最后工作,通过对BERT和RoBERTa两种模型的情感分析性能进行比较,通过混淆矩阵和分类报告来评估它们在微博情感分类任务上的表现。结果分析的目的是总结和比较两个模型在不同情感类别上的准确性、召回率、F1分数等性能指标,以便为模型选择和改进提供有价值的见解。
11.12.1 RoBERTa情感分类报告
通过下面的代码生成并打印输出BERT模型在测试集上的分类报告信息,包括了每个情感类别(Negative、Neutral、Positive)的精确度、召回率、F1分数等评估指标。
print('Classification Report for BERT:\n',classification_report(y_test,y_pred_bert, target_names=['Negative', 'Neutral', 'Positive']))上述代码生成并打印出BERT模型在测试集上的分类报告,其中包含了每个情感类别(Negative、Neutral、Positive)的精确度、召回率、F1分数等评估指标。根据结果,BERT模型在各个情感类别上表现均衡,整体准确度较高。执行后会输出:
Classification Report for BERT:
precision recall f1-score support
Negative 0.88 0.91 0.89 1629
Neutral 0.89 0.75 0.82 614
Positive 0.89 0.91 0.90 1544
micro avg 0.89 0.89 0.89 3787
macro avg 0.89 0.86 0.87 3787
weighted avg 0.89 0.89 0.88 3787
samples avg 0.89 0.89 0.89 378711.12.2 RoBERTa情感分类报告
下面的代码生成并打印出RoBERTa模型在测试集上的分类报告,其中包含了每个情感类别(Negative、Neutral、Positive)的精确度、召回率、F1分数等评估指标。
print('Classification Report for RoBERTa:\n',classification_report(y_test,y_pred_roberta, target_names=['Negative', 'Neutral', 'Positive']))上述代码生成并打印出RoBERTa模型在测试集上的分类报告,其中包含了每个情感类别(Negative、Neutral、Positive)的精确度、召回率、F1分数等评估指标。根据结果,RoBERTa模型在Negative和Positive情感类别上表现良好,但在Neutral类别上的表现相对较差。执行后会输出:
Classification Report for RoBERTa:
precision recall f1-score support
Negative 0.91 0.89 0.90 1629
Neutral 0.74 0.84 0.78 614
Positive 0.92 0.88 0.90 1544
micro avg 0.88 0.88 0.88 3787
macro avg 0.85 0.87 0.86 3787
weighted avg 0.88 0.88 0.88 3787
samples avg 0.88 0.88 0.88 378711.12.3 两种大模型性能的对比可视化
使用Seaborn库绘制了两个热力图,展示了BERT和RoBERTa两个模型在测试集上的混淆矩阵。
fig, ax = plt.subplots(1,2,figsize=(9,5.5))
labels = ['Negative', 'Neutral', 'Positive']
plt.suptitle('Sentiment Analysis Comparison\n Confusion Matrix', fontsize=20)
sns.heatmap(confusion_matrix(y_test.argmax(1),y_pred_bert.argmax(1)), annot=True, cmap="Blues", fmt='g', cbar=False, ax=ax[0], annot_kws={"size":25})
ax[0].set_title('BERT Classifier', fontsize=20)
ax[0].set_yticklabels(labels, fontsize=17);
ax[0].set_xticklabels(labels, fontsize=17);
ax[0].set_ylabel('Test', fontsize=20)
ax[0].set_xlabel('Predicted', fontsize=20)
sns.heatmap(confusion_matrix(y_test.argmax(1),y_pred_roberta.argmax(1)), annot=True, cmap="Blues", fmt='g', cbar=False, ax=ax[1], annot_kws={"size":25})
ax[1].set_title('RoBERTa Classifier', fontsize=20)
ax[1].set_yticklabels(labels, fontsize=17);
ax[1].set_xticklabels(labels, fontsize=17);
ax[1].set_ylabel('Test', fontsize=20)
ax[1].set_xlabel('Predicted', fontsize=20)
plt.show()执行后会绘制两种大模型的混淆矩阵对比可视化图,如图11-8所示。混淆矩阵是一种用于评估分类模型性能的可视化工具,显示了模型对每个类别的分类情况。其中,热力图中的颜色越深,表示模型在该类别上的表现越好。整个图表通过两个子图进行对比,分别展示了BERT和RoBERTa分类器的混淆矩阵。
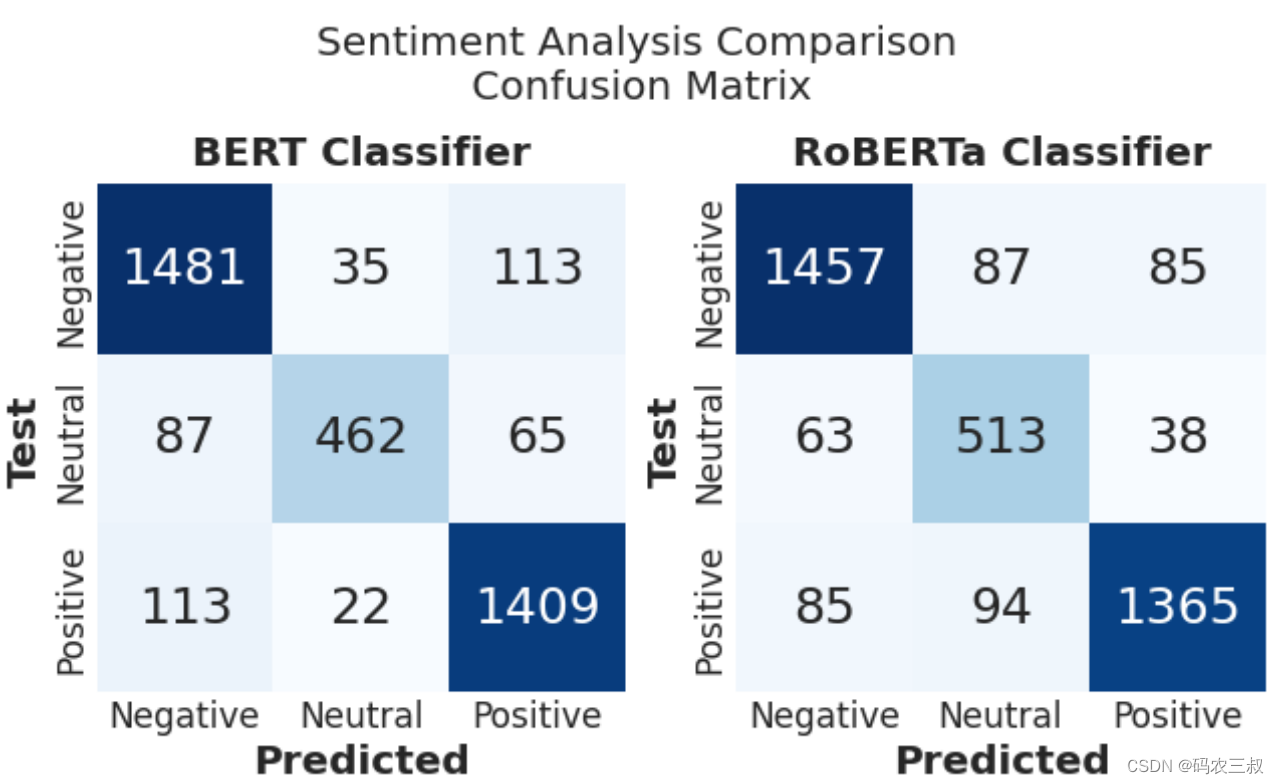
图11-8 混淆矩阵对比图
这个可视化图展示了BERT和RoBERTa两个模型在情感分析任务上的优秀性能,分类的准确度达到了90%左右。
本项目已完结:
(11-1)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):背景介绍+项目介绍_大模型情感分析-CSDN博客
(11-2)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):技术栈+模块架构-CSDN博客
(11-3)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):准备工作-CSDN博客
(11-4)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):数据探索-CSDN博客
(11-5)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):初步清理-CSDN博客
(11-6)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):训练数据的深度清理+测试数据的深度清理-CSDN博客
(11-7)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):情感列分析-CSDN博客
(11-8)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):基准模型——朴素贝叶斯分类器-CSDN博客
(11-9)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):基于BERT大模型情感分析-CSDN博客
(11-10)基于大模型的情感分析系统(Tensorflow+BERT+RoBERTa+Sklearn):基于RoBERTa大模型的情感分析-CSDN博客
















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











