








9.3 概率图模型应用实战
经过本书签名的学习,已经初步了解了TensorFlow Probability概率模型的基本知识。在本节的内容中,将通过具体实实例来讲使用TensorFlow Probability开发实用程序的知识。
9.3.1 高斯过程回归实战
在本实例中,将使用 TensorFlow和TensorFlow Probability探索高斯过程(缩写为:GP)回归。我们将从一些已知函数中生成一些嘈杂的观察结果,并将 GP 模型拟合到这些数据中。然后在经过GP处理后验证采样,并在其域中的网格上绘制对应的采样函数值。
假设x是任何集合,一个高斯过程是通过索引随机变量的集合x这样如果
来自 GP 的完整样本包含整个空间的实值函数 并且在实践中实现是不切实际的;通常人们会选择一组点来观察样本并在这些点上绘制函数值。这是通过从适当的(有限维)多变量高斯采样来实现的。
注意,根据上面的定义,任何有限维多元高斯分布也是一个高斯过程。通常,当提到一个 GP 时,它隐含地表示索引集是一些Rn这个假设。
高斯过程在机器学习中的一个常见应用是高斯过程回归。这个想法是我们希望在给定噪声观察的情况下估计一个未知函数![]() 函数在有限点数。
函数在有限点数。
接下来开始实现噪声正弦数据的精确 GP 回归,实例文件是Gaussian_Process_Regression_In_TFP.ipynb,具体实现流程如下:
(1)从嘈杂的正弦曲线生成训练数据,然后从 GP 回归模型的后验中采样一堆曲线。我们使用 Adam来优化内核超参数(我们在先验条件下最小化数据的负对数似然)。我们绘制训练曲线,然后是真实函数和后验样本。
def sinusoid(x):
return np.sin(3 * np.pi * x[..., 0])
def generate_1d_data(num_training_points, observation_noise_variance):
"""在一组随机点上生成噪声正弦观测值。
返回:观察指数点、观察值
"""
index_points_ = np.random.uniform(-1., 1., (num_training_points, 1))
index_points_ = index_points_.astype(np.float64)
# y = f(x) + noise
observations_ = (sinusoid(index_points_) +
np.random.normal(loc=0,
scale=np.sqrt(observation_noise_variance),
size=(num_training_points)))
return index_points_, observations_
#生成具有已知噪声级的训练数据(然后将尝试从数据中恢复此值)。
NUM_TRAINING_POINTS = 100
observation_index_points_, observations_ = generate_1d_data(
num_training_points=NUM_TRAINING_POINTS,
observation_noise_variance=.1)(2)将先验放在内核超参数上,并使用写出超参数和观察数据的联合分布tfd.JointDistributionNamed。
def build_gp(amplitude, length_scale, observation_noise_variance):
"""定义给定内核参数的GP输出的条件距离。”“”
#创建协方差核,它将在先验(用于最大似然训练)和后验(用于后验预测采样)之间共享
kernel = tfk.ExponentiatedQuadratic(amplitude, length_scale)
#创建GP先验分布,将使用它来训练模型参数
return tfd.GaussianProcess(
kernel=kernel,
index_points=observation_index_points_,
observation_noise_variance=observation_noise_variance)
gp_joint_model = tfd.JointDistributionNamed({
'amplitude': tfd.LogNormal(loc=0., scale=np.float64(1.)),
'length_scale': tfd.LogNormal(loc=0., scale=np.float64(1.)),
'observation_noise_variance': tfd.LogNormal(loc=0., scale=np.float64(1.)),
'observations': build_gp,
})(3)可以验证从先验中采样并计算样本的对数密度来检查我们的实现。
x = gp_joint_model.sample()
lp = gp_joint_model.log_prob(x)
print("sampled {}".format(x))
print("log_prob of sample: {}".format(lp))执行后会输出:
sampled {'observation_noise_variance': <tf.Tensor: shape=(), dtype=float64, numpy=2.067952217184325>, 'length_scale': <tf.Tensor: shape=(), dtype=float64, numpy=1.154435715487831>, 'amplitude': <tf.Tensor: shape=(), dtype=float64, numpy=5.383850737703549>, 'observations': <tf.Tensor: shape=(100,), dtype=float64, numpy=
array([-2.37070577, -2.05363838, -0.95152824, 3.73509388, -0.2912646 ,
0.46112342, -1.98018513, -2.10295857, -1.33589756, -2.23027226,
-2.25081374, -0.89450835, -2.54196452, 1.46621647, 2.32016193,
5.82399989, 2.27241034, -0.67523432, -1.89150197, -1.39834474,
-2.33954116, 0.7785609 , -1.42763627, -0.57389025, -0.18226098,
-3.45098732, 0.27986652, -3.64532398, -1.28635204, -2.42362875,
0.01107288, -2.53222176, -2.0886136 , -5.54047694, -2.18389607,
-1.11665628, -3.07161217, -2.06070336, -0.84464262, 1.29238438,
-0.64973999, -2.63805504, -3.93317576, 0.65546645, 2.24721181,
-0.73403676, 5.31628298, -1.2208384 , 4.77782252, -1.42978168,
-3.3089274 , 3.25370494, 3.02117591, -1.54862932, -1.07360811,
1.2004856 , -4.3017773 , -4.95787789, -1.95245901, -2.15960839,
-3.78592731, -1.74096185, 3.54891595, 0.56294143, 1.15288455,
-0.77323696, 2.34430694, -1.05302007, -0.7514684 , -0.98321063,
-3.01300144, -3.00033274, 0.44200837, 0.45060886, -1.84497318,
-1.89616746, -2.15647664, -2.65672581, -3.65493379, 1.70923375,
-3.88695218, -0.05151283, 4.51906677, -2.28117003, 3.03032793,
-1.47713194, -0.35625273, 3.73501587, -2.09328047, -0.60665614,
-0.78177188, -0.67298545, 2.97436033, -0.29407932, 2.98482427,
-1.54951178, 2.79206821, 4.2225733 , 2.56265198, 2.80373284])>}
log_prob of sample: -194.96442183797524(4)现在优化以找到具有最高后验概率的参数值,将为每个参数定义一个变量,并将它们的值限制为正值。
constrain_positive = tfb.Shift(np.finfo(np.float64).tiny)(tfb.Exp())
amplitude_var = tfp.util.TransformedVariable(
initial_value=1.,
bijector=constrain_positive,
name='amplitude',
dtype=np.float64)
length_scale_var = tfp.util.TransformedVariable(
initial_value=1.,
bijector=constrain_positive,
name='length_scale',
dtype=np.float64)
observation_noise_variance_var = tfp.util.TransformedVariable(
initial_value=1.,
bijector=constrain_positive,
name='observation_noise_variance_var',
dtype=np.float64)
trainable_variables = [v.trainable_variables[0] for v in
[amplitude_var,
length_scale_var,
observation_noise_variance_var]](5)为了根据我们观察到的数据调整模型,编写函数target_log_prob,该函数将采用(仍需推断)内核超参数。
def target_log_prob(amplitude, length_scale, observation_noise_variance):
return gp_joint_model.log_prob({
'amplitude': amplitude,
'length_scale': length_scale,
'observation_noise_variance': observation_noise_variance,
'observations': observations_
})
#优化模型参数
num_iters = 1000
optimizer = tf.optimizers.Adam(learning_rate=.01)
#使用“tf.function”跟踪损失,以便进行更有效的评估。
@tf.function(autograph=False, jit_compile=False)
def train_model():
with tf.GradientTape() as tape:
loss = -target_log_prob(amplitude_var, length_scale_var,
observation_noise_variance_var)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss
#在训练期间存储似然值,以便我们可以绘制进度
lls_ = np.zeros(num_iters, np.float64)
for i in range(num_iters):
loss = train_model()
lls_[i] = loss
print('Trained parameters:')
print('amplitude: {}'.format(amplitude_var._value().numpy()))
print('length_scale: {}'.format(length_scale_var._value().numpy()))
print('observation_noise_variance: {}'.format(observation_noise_variance_var._value().num执行后会输出:
Trained parameters:
amplitude: 0.9176153445125278
length_scale: 0.18444082442910079
observation_noise_variance: 0.0880273312850989(6)然后绘制预测曲线图,代码如下:
plt.figure(figsize=(12, 4))
plt.plot(lls_)
plt.xlabel("Training iteration")
plt.ylabel("Log marginal likelihood")
plt.show()绘制的预测曲线图如图9-2所示。
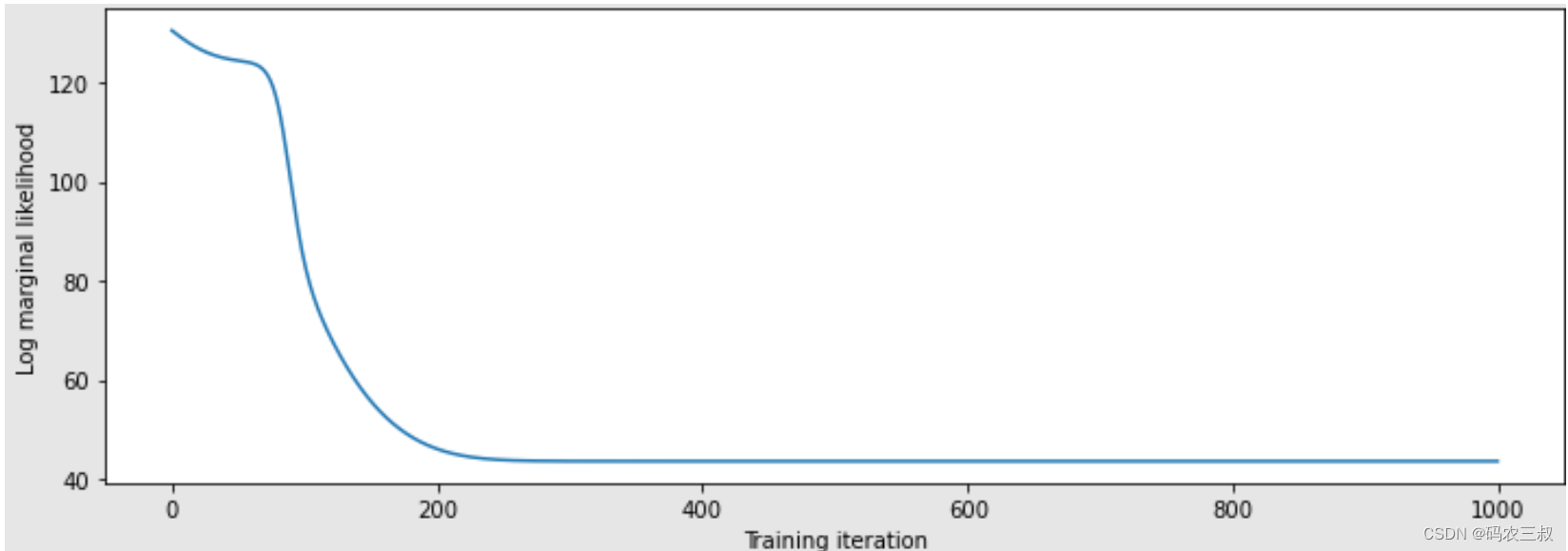
图9-2 预测曲线图
(7)训练好模型后,我们希望根据观察结果从后面的样本中取样,希望样本位于训练输入以外的点。
predictive_index_points_ = np.linspace(-1.2, 1.2, 200, dtype=np.float64)
#重塑为[200,1]——1是特征空间的维度。
predictive_index_points_ = predictive_index_points_[..., np.newaxis]
optimized_kernel = tfk.ExponentiatedQuadratic(amplitude_var, length_scale_var)
gprm = tfd.GaussianProcessRegressionModel(
kernel=optimized_kernel,
index_points=predictive_index_points_,
observation_index_points=observation_index_points_,
observations=observations_,
observation_noise_variance=observation_noise_variance_var,
predictive_noise_variance=0.)然后创建op以绘制50个独立样本,每个样本都是从预测指数点处的后部绘制的“关节”。因为我们有上面定义的200个输入位置,对应函数值的后验分布是200维多元高斯分布
num_samples = 50
samples = gprm.sample(num_samples)
#绘制真实函数、观察值和后验样本.
plt.figure(figsize=(12, 4))
plt.plot(predictive_index_points_, sinusoid(predictive_index_points_),
label='True fn')
plt.scatter(observation_index_points_[:, 0], observations_,
label='Observations')
for i in range(num_samples):
plt.plot(predictive_index_points_, samples[i, :], c='r', alpha=.1,
label='Posterior Sample' if i == 0 else None)
leg = plt.legend(loc='upper right')
for lh in leg.legendHandles:
lh.set_alpha(1)
plt.xlabel(r"Index points ($\mathbb{R}^1$)")
plt.ylabel("Observation space")
plt.show()绘制的可视化图如图9-3所示。
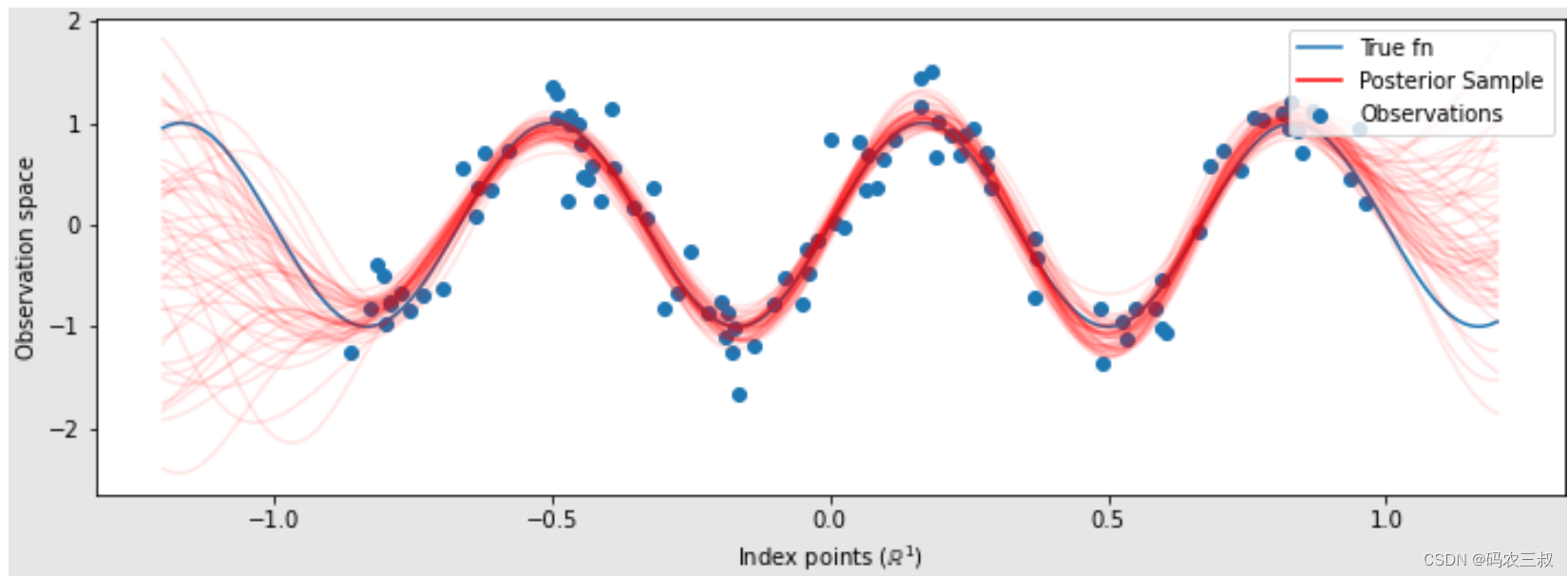
图9-3 绘制的可视化图
(8)使用 HMC 边缘化超参数
与其优化超参数,不如尝试将它们与 Hamiltonian Monte Carlo 结合起来。给定观察结果,首先定义并运行一个采样器,以从内核超参数的后验分布中近似抽取。
num_results = 100
num_burnin_steps = 50
sampler = tfp.mcmc.TransformedTransitionKernel(
tfp.mcmc.NoUTurnSampler(
target_log_prob_fn=target_log_prob,
step_size=tf.cast(0.1, tf.float64)),
bijector=[constrain_positive, constrain_positive, constrain_positive])
adaptive_sampler = tfp.mcmc.DualAveragingStepSizeAdaptation(
inner_kernel=sampler,
num_adaptation_steps=int(0.8 * num_burnin_steps),
target_accept_prob=tf.cast(0.75, tf.float64))
initial_state = [tf.cast(x, tf.float64) for x in [1., 1., 1.]]
#通过使用“tf.function”跟踪加快采样速度。
@tf.function(autograph=False, jit_compile=False)
def do_sampling():
return tfp.mcmc.sample_chain(
kernel=adaptive_sampler,
current_state=initial_state,
num_results=num_results,
num_burnin_steps=num_burnin_steps,
trace_fn=lambda current_state, kernel_results: kernel_results)
t0 = time.time()
samples, kernel_results = do_sampling()
t1 = time.time()
print("Inference ran in {:.2f}s.".format(t1-t0))执行后会输出:
Inference ran in 9.00s.然后通过检查超参数轨迹来对采样器进行完整性检查:
(amplitude_samples,
length_scale_samples,
observation_noise_variance_samples) = samples
f = plt.figure(figsize=[15, 3])
for i, s in enumerate(samples):
ax = f.add_subplot(1, len(samples) + 1, i + 1)
ax.plot(s)此时绘制的可视化图如图9-4所示。
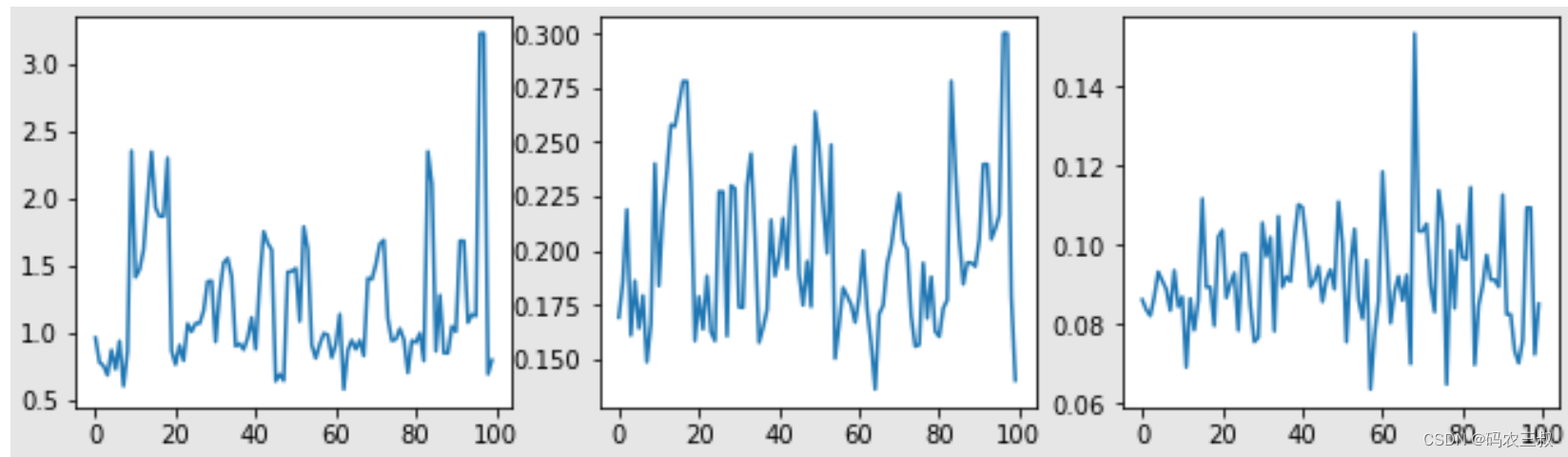
图9-4 绘制的可视化图
(9)现在不是用优化的超参数构建单个GP,而是将后验预测分布构建为GP的混合,每个GP由来自超参数后验分布的样本定义。这通过蒙特卡罗采样对后验参数进行近似积分,以计算未观察到的位置的边缘预测分布。
#采样的超参数有一个前导的批处理维度,`[num_results,…]`,因此它构造了一个* batch *内核
batch_of_posterior_kernels = tfk.ExponentiatedQuadratic(
amplitude_samples, length_scale_samples)
#batch内核创建了一批GP预测模型,每个后验样本一个。
batch_gprm = tfd.GaussianProcessRegressionModel(
kernel=batch_of_posterior_kernels,
index_points=predictive_index_points_,
observation_index_points=observation_index_points_,
observations=observations_,
observation_noise_variance=observation_noise_variance_samples,
predictive_noise_variance=0.)
#为了构造边际预测分布,我们对后验样本进行均匀加权平均
predictive_gprm = tfd.MixtureSameFamily(
mixture_distribution=tfd.Categorical(logits=tf.zeros([num_results])),
components_distribution=batch_gprm)
num_samples = 50
samples = predictive_gprm.sample(num_samples)
#绘制真实函数、观察值和后验样本.
plt.figure(figsize=(12, 4))
plt.plot(predictive_index_points_, sinusoid(predictive_index_points_),
label='True fn')
plt.scatter(observation_index_points_[:, 0], observations_,
label='Observations')
for i in range(num_samples):
plt.plot(predictive_index_points_, samples[i, :], c='r', alpha=.1,
label='Posterior Sample' if i == 0 else None)
leg = plt.legend(loc='upper right')
for lh in leg.legendHandles:
lh.set_alpha(1)
plt.xlabel(r"Index points ($\mathbb{R}^1$)")
plt.ylabel("Observation space")
plt.show()此时绘制的可视化图如图9-5所示。
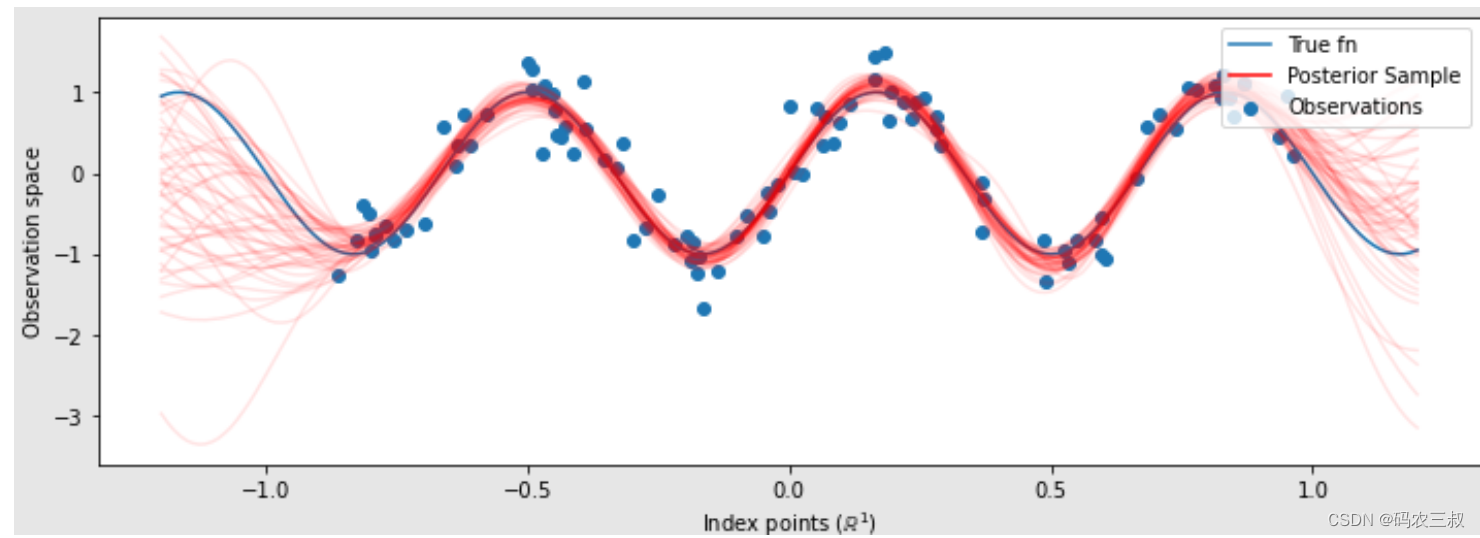
图9-5 绘制的可视化图
由此可见,尽管在这种情况下差异很小,但总的来说,希望后验预测分布比上面所做的仅使用最可能的参数具有更好的泛化能力(为保留数据提供更高的可能性)。

















 4223
4223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











