






CVPR(Conference on Computer Vision and Pattern Recognition)是计算机视觉领域最有影响力的会议之一,主要方向包括图像和视频处理、目标检测与识别、三维视觉等。近期,CVPR 2024公布了最佳论文。共有10篇论文获奖,其中2篇最佳论文,2篇最佳学生论文,2篇最佳论文题目和4篇最佳学生论文提名。本公众号推出CVPR 2024最佳论文专栏,分享这10篇最佳论文。
00/ 论文分享
本推文详细介绍了CVPR 2024最佳论文《Rich Human Feedback for Text-to-Image Generation》。该论文的第一作者为梁有为。论文针对文本生成图像的伪影、不可信、低审美等问题,发布了第一个具有丰富人类反馈的数据集RichHF-18K。在此基础上,提出了一个多模态Transformer模型(RAHF)用于预测生成图像的丰富反馈,并进一步证明了RAHF预测的丰富人类反馈对改善图像生成的通用性。本推文由朱旺撰写,审校为李杨和陆新颖。
01 /研究背景与解决的关键问题
文本到图像的生成模型在基于文本描述生成高分辨率图像方面取得了重大进展,并正迅速成为包括娱乐、艺术和广告在内的各个领域内容创作的关键。然而,许多生成的图像仍然存在诸如伪影/不可信、与文本描述不一致以及低审美质量等问题。现有的生成图像的自动评估指标大多都是在图像的分布上计算,难以反映单个图像的细微差别。受基于人类反馈的强化学习在大型语言模型上的成功启发,论文试图通过丰富人类反馈信号来改进文本到图像生成模型,解决生成图像中存在的不真实、不对齐、低审美等问题。
02 /方法
论文提出了一种利用人类反馈信号来改进文本到图像生成模型的方法。首先发布了一个具有丰富人类反馈信息的数据集RichHF-18K,其中包括两个热力图(伪像/不可信和不对齐)、四个细粒度分数(合理性、对齐、美学和总体分数)以及一个文本序列(不对齐的关键字)。然后训练一个多模态Transformer模型来自动预测丰富的人类反馈信号,用以微调和改进生成模型。

图 1 注释图像的图示
2.1 RichHF-18K数据集
论文从 Pick-a-Pic 数据集中选择图像-文本对的子集进行数据注释。考虑到图像的平衡性,首先通过视觉回答模型从数据样本中提取一些基本特征,如是否逼真、种类、场景等。然后对每张图像在不可信/伪影或不对齐的位置进行标注,通过假设每个标记点具有有效半径,从而减少标记点个数。接着针对四种细粒度分数进行打分,生成具有丰富人类反馈的图像。考虑到数据集的可靠性,每张图像融合多人注释的信息,分数采用多人打分取平均的策略。生成图像的图示如图1所示。最后对生成的数据集进行分析,生成的打分符合高斯分布,确保有合理数量的正负样本来训练奖励模型。数据集的总大小为 18K,其中 16K 作为训练集,1K 作为验证集,1K 作为测试集。数据集的地址为:https://github.com/google-research/google-research/tree/master/richhf-18k。
2.2 预测丰富的人类反馈
论文提出了一个多模态 Transformer 模型用于自动预测丰富的人类反馈信息,其整体架构如图2所示。该模型基于 ViT 和 T5X 模型,ViT 将生成的图像作为输入,并将图像令牌作为高级表示输出。文本提示符号嵌入到密集向量中。图像标记和嵌入的文本标记由 T5X 中的 Transformer 自关注编码器连接和编码。在编码融合的文本和图像标记之上,论文使用三种预测器来分别预测热图、分数和文本输出。
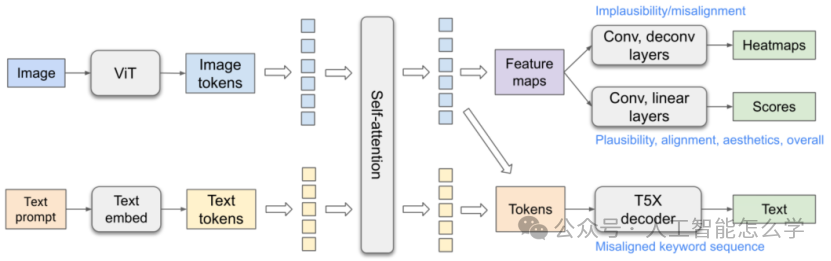
图 2 模型的整体架构
03 /实验结果
论文在发布的 RichHF-18K 数据集上对模型进行了训练并进行了大量实验。通过线性相关系数和等级相关系数对预测分数进行评估,并通过显著性热图指标对预测热图进行分析。对于不对齐的关键字序列预测,论文采用令牌级精度、召回率等指标进行评估。实验结果表明,论文提出的模型在预测人类反馈方面具有优越表现。此外,论文对预测的丰富人类反馈是否可以用于改进图像生成这一问题进行了验证。实验结果表明,通过 RAHF 微调后的 Muse 模型生成的图像具有更少的伪像和不可信性,并且每个细粒度评分都可以改善生成模型或图像的不同方面。
04 /结论
论文发布了第一个具有丰富人类反馈信号的数据集 RichHF-18,通过数据分析验证了数据集的可靠性和合理性。此外,论文设计并训练了一个多模态 Transformer 模型来预测丰富人类反馈。该模型基于 VIT 和 T5X 模型,在连接图像令牌和文本令牌之间使用自关注模块,将文本信息传播到图像标记,用于文本不对齐评分和热图预测,将视觉信息传播到文本标记,用于更好的视觉感知文本编码,以解码文本不对齐序列。实验表明,模型在预测输出人类反馈信息方面具有优越性能,并进一步验证了生成的预测反馈信息和模型可以用于微调生成模型。

扫码关注我们
微信号:人工智能怎么学

















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









