







On the Robustness of Large Multimodal Models Against Image Adversarial Attacks
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 方法-Method
- 实验结果和分析-Experimental Results and Analysis
- LMMs对对抗性视觉输入具有鲁棒性吗?-Are LMMs Robust Against Adversarial Visual Input?
- 评估LMMs的视觉问答(VQA)性能-Evaluating LMMs’ VQA Performance
- 视觉对抗攻击对LMMs并不具有通用性-Visual Adversarial Attacks are not Universal to LMMs
- 添加上下文可提高语言模型的鲁棒性-Adding Context Improves LMM Robustness
- 现实世界应用:上下文增强图像分类-Towards Real-World Application: ContextAugmented Image Classification
- 结论-Conclusion
本文 “On the Robustness of Large Multimodal Models Against Image Adversarial Attacks” 主要研究大型多模态模型(LMMs)对图像对抗攻击的鲁棒性。研究发现 LMMs 在无额外文本信息时对对抗攻击较脆弱,但上下文能提升其鲁棒性,还提出了查询分解的方法提高图像分类的鲁棒性。
摘要-Abstract
Recent advances in instruction tuning have led to the development of State-of-the-Art Large Multimodal Models (LMMs). Given the novelty of these models, the impact of visual adversarial attacks on LMMs has not been thoroughly examined. We conduct a comprehensive study of the robustness of various LMMs against different adversarial attacks, evaluated across tasks including image classification, image captioning, and Visual Question Answer (VQA). We find that in general LMMs are not robust to visual adversarial inputs. However, our findings suggest that context provided to the model via prompts—such as questions in a QA pair—helps to mitigate the effects of visual adversarial inputs. Notably, the LMMs evaluated demonstrated remarkable resilience to such attacks on the ScienceQA task with only an 8.10% drop in performance compared to their visual counterparts which dropped 99.73%. We also propose a new approach to real-world image classification which we term query decomposition. By incorporating existence queries into our input prompt we observe diminished attack effectiveness and improvements in image classification accuracy. This research highlights a previously under explored facet of LMM robustness and sets the stage for future work aimed at strengthening the resilience of multimodal systems in adversarial environments.
指令调优方面的最新进展推动了最先进的大型多模态模型(LMMs)的发展。鉴于这些模型的新颖性,视觉对抗攻击对LMMs的影响尚未得到充分研究。我们对各种LMMs在不同对抗攻击下的鲁棒性进行了全面研究,并在图像分类、图像描述生成和视觉问答(VQA)等任务中进行评估。我们发现,一般来说,LMMs对视觉对抗输入并不具备鲁棒性。然而,我们的研究结果表明,通过提示(如问答对中的问题)为模型提供的上下文有助于减轻视觉对抗输入的影响。值得注意的是,在评估的LMMs中,它们在ScienceQA任务中对这类攻击表现出了显著的恢复能力,与视觉模型相比,其性能仅下降了8.10%,而视觉模型的性能下降了99.73%。我们还提出了一种新的面向实际图像分类的方法,称之为查询分解。通过将存在性查询纳入输入提示中,我们观察到攻击有效性降低,并且图像分类准确率有所提高。这项研究突出了LMMs鲁棒性之前未被充分探索的一个方面,为未来旨在增强多模态系统在对抗环境中恢复能力的研究奠定了基础。
引言-Introduction
这部分内容主要介绍了大型多模态模型(LMMs)的发展、面临的问题以及本文的研究内容与发现,具体如下:
- LMMs的发展与优势:指令调优的进步推动了LMMs的发展,使其在图像分类、视觉问答、图像描述生成和语义分割等多领域表现出色。它能高效泛化到新领域,这得益于指令调优技术从文本模型扩展到多模态模型,减少了微调所需数据量。
- 研究问题的提出:尽管LMMs发展迅速,但对抗样本对其影响研究不足。传统对抗攻击多端到端生成,针对单一模态和模型最终损失。在多模态模型由不同预训练模型组合的当下,需重新评估这些攻击方法有效性。而且,LMMs规模大,攻击整个模型成本高,因此研究针对视觉编码器的对抗攻击对LMMs整体性能的影响至关重要。
- 研究内容与发现:全面分析了当前LMMs在多种对抗攻击、任务和数据集下的鲁棒性。研究发现,在无额外文本信息的情况下,如COCO分类(无上下文)或COCO图像描述生成任务中,LMMs对对抗性视觉扰动的鲁棒性较差;而上下文信息能增强其鲁棒性,如COCO分类(有上下文)任务。此外,在VQA任务中,当攻击不直接针对任务核心方面时,LMMs具有一定的固有鲁棒性。具体而言:
- LMMs通常易受对抗性视觉扰动影响,即便扰动仅针对视觉模型生成。
- 与分类和图像描述生成任务相比,LMMs在VQA任务中表现出更好的鲁棒性,当VQA问题查询的视觉内容与被攻击内容不同时,视觉攻击效果更差。
- 额外的文本上下文显著提高LMMs对视觉对抗输入的鲁棒性。
- 基于上述发现,设计了一种上下文增强的图像分类方案,显著提高了鲁棒性。

图1. 针对对抗图像的LLaVA问答对。“LLaVA”和“LLaVA(adv)”分别指LLaVA在使用干净图像和对抗图像时对用户查询的回答。对于读者来说,场景中有两只羊,而对抗攻击是基于最大化图像与“一张羊的照片”这一文本之间的距离。在前两对问答中,我们可以看到LLaVA(adv)的回答完全错误。然而,它仍然可以正确回答以下问题,因为这些问题与被攻击的对象(羊)无关。还要注意第二对和最后一对问答之间的对比。在提供了额外的上下文后,LLaVA(adv)正确地回答了问题。这些观察结果为本文的一些研究发现提供了支持。来源:COCO 2014
相关工作-Related Work
这部分主要介绍了大型多模态模型(LMMs)、对抗攻击以及LMMs和对抗样本相关的研究工作,为后续研究奠定基础,具体内容如下:
- 大型多模态模型(LMMs):LMMs通常由视觉模型、预训练大语言模型(LLM)和用于弥合图像与文本模态差距的投影模型构成。其中,LLaVA和InstructBLIP是当前LMMs领域的代表性模型。LLaVA将CLIP视觉编码器与Vicuna LLM相结合,通过简单线性投影转换视觉表示;基于BLIP2的模型则使用EVA-CLIP视觉编码器和带有可学习查询向量的Q-former来连接视觉和文本模态。这些模型在多种视觉语言任务中展现出强大能力。
- 对抗攻击:对抗攻击旨在对输入进行细微操纵,使神经网络产生错误输出,且这种操纵对人类来说通常难以察觉。主要分为白盒攻击和黑盒攻击两类。白盒攻击中,攻击者可完全访问模型参数;黑盒攻击中,攻击者仅拥有有限信息,如输出logits或标签。基于迁移的攻击利用白盒条件下替代模型的梯度,因其可能迁移到目标黑盒模型,成为模型的关键漏洞。此外,对抗攻击研究最初主要集中于图像分类,近年来在文本领域也有发展,可通过启发式方法或离散优化技术生成对抗样本。
- LMMs和对抗样本:尽管视觉和文本领域的对抗攻击研究广泛,但它们对当前LMMs的影响相对未被深入探索。近期研究虽展示了创建可有效“越狱”LMMs的对抗样本的可行性,这些样本能使LMMs产生有害内容,绕过模型对齐时的安全措施,但大多关注LMMs的安全性、潜在危害等问题。而本文研究重点在于系统地考察视觉对抗攻击影响下,LMMs执行各种任务时的准确性。
方法-Method
威胁模型-Threat Model
这部分主要介绍了研究中所采用的威胁模型,即基于梯度的白盒对抗攻击,具体内容如下:
- 攻击原理:聚焦基于梯度的白盒对抗攻击方法,这类方法通过计算梯度来确定修改输入的最有效方向,从而欺骗模型,同时满足 L p L_{p} Lp 约束。
- 形式化表达:给定输入-标签对 ( x , y ) (x, y) (x,y) 以及模型 f f f,目标是找到对抗扰动 δ \delta δ,使得 f ( x + δ ) ≠ y f(x + \delta) \neq y f(x+δ)=y,并且 δ \delta δ 要在特定的 L p L_{p} Lp 边界内。
- 具体攻击算法的目标函数
- PGD(Projected Gradient Descent,投影梯度下降):在满足 ∥ δ ∥ ∞ < ϵ \|\delta\|_{\infty}<\epsilon ∥δ∥∞<ϵ( ϵ \epsilon ϵ 是 L ∞ L_{\infty} L∞ 球的半径 )的条件下,最大化交叉熵损失 L ( f ( x + δ ) , y ) L(f(x+\delta), y) L(f(x+δ),y).
- CW(Carlini-Wagner):在满足 x + δ ∈ [ 0 , 1 ] x+\delta \in[0,1] x+δ∈[0,1] 的条件下,最大化 ∥ δ ∥ p + c ⋅ g ( x + δ ) \|\delta\|_{p}+c \cdot g(x+\delta) ∥δ∥p+c⋅g(x+δ). 其中 g ( x + δ ) = m a x ( f ( x + δ ) y − m a x { f ( x + δ ) i : i ≠ y } , − κ ) g(x+\delta)=max (f(x+\delta)_{y}-max \{f(x+\delta)_{i}: i \neq y\},-\kappa) g(x+δ)=max(f(x+δ)y−max{f(x+δ)i:i=y},−κ), c c c 是约束参数, κ \kappa κ 是置信参数。
攻击-Attacks
该部分主要介绍了研究中采用的对抗攻击方法及相关参数设置,具体内容如下:
- 攻击方法选择:挑选PGD(投影梯度下降)、CW(Carlini-Wagner)作为基于梯度的强攻击代表,同时选择APGD(自适应投影梯度下降,PGD的变体)进行实验。这些攻击方法均基于梯度计算来生成对抗样本,旨在干扰模型的正常判断。
- 参数设置:针对每种攻击方法,分别设置了“正常”和“强”两种参数设置,主要依据扰动的可感知程度来区分。
- 正常设置:CW的约束设为20,PGD和APGD的 ϵ \epsilon ϵ(扰动幅度限制)设为8/255,这是参考了之前的研究工作设定的参数。
- 强设置:PGD和APGD的
ϵ
\epsilon
ϵ 设为0.2,CW的约束设为100。
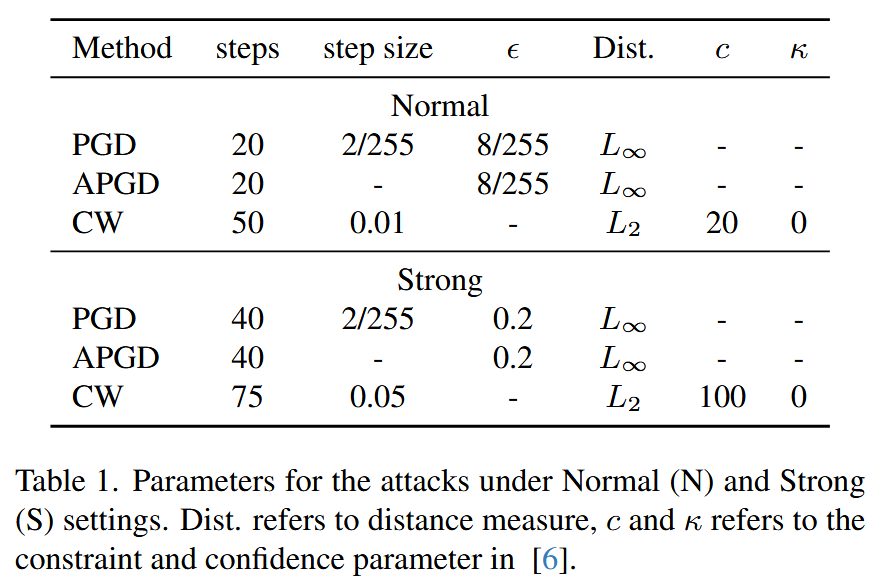
表1. 正常(N)和强(S)设置下的攻击参数。Dist. 指距离度量,c和κ指文献[6]中的约束参数和置信参数。
- 攻击实施特点:所有攻击仅针对图像编码器进行,不会对LLM(大语言模型)部分造成影响,以专注研究视觉对抗攻击对LMMs(大型多模态模型)的影响。不同攻击方法在不同参数设置下生成的对抗样本特性有所差异,如在正常设置下,对抗扰动几乎难以察觉;而在强设置下,PGD和APGD生成的扰动明显,CW生成的扰动即便在强设置下仍不易察觉。

图2. 由PGD、APGD和CW在正常和强参数设置下生成的CLIP对抗样本图像示例。图像来源:COCO 2014val。请注意,在强攻击下,PGD和APGD生成的对抗扰动变得非常明显,预计会导致更高程度的性能下降。
模型-Models
这部分主要介绍了研究中用于评估的三个最先进的大型多模态模型(LMMs),通过对不同模型的选择,为后续在多样且可控的实验条件下研究LMMs对对抗攻击的鲁棒性奠定基础,具体内容如下:
- 模型选择:挑选了三个具有代表性的LMMs进行评估,分别是LLaVA1.5、BLIP2和InstructBLIP。
- 模型特点
- LLaVA1.5:集成了Vicuna13B语言模型,采用CLIP图像编码器,通过直接将投影后的视觉令牌插入文本令牌的方式,融合图像和文本编码。
- BLIP2:结合了Flan T5 XXL语言模型,使用EVA-CLIP图像编码器,借助Q-former架构连接视觉和文本模态。
- InstructBLIP:同样利用Vicuna13B语言模型,与LLaVA1.5不同的是其采用Q-former架构来融合图像和文本信息,且在图像编码器方面与BLIP2类似 。
- 选择意义:这些模型在配置上各具特色,存在明显差异。选择它们进行实验,可以在多样化的模型条件下,研究LMMs在面对对抗攻击时的表现,确保实验结果的全面性和可靠性,使研究结论更具说服力。
任务与对抗生成-Tasks & Adversarial generation
该部分主要介绍了用于评估大型多模态模型(LMMs)对抗视觉攻击鲁棒性的任务,以及针对各任务生成对抗样本的方法,具体内容如下:
- 评估任务选择:研究选取了图像分类、图像描述和视觉问答(VQA)这三个常见的视觉任务,通过在这些任务上的测试,全面评估视觉对抗攻击对LMMs的影响。
- 对抗样本生成:针对LMMs的图像编码器生成对抗样本,其中LLaVA使用CLIP图像编码器,BLIP2和InstructBLIP使用EVA-CLIP图像编码器。利用CLIP文本编码器和BLIP的Q-former中的文本编码器,计算相应图像编码器的文本嵌入。对于PGD和APGD攻击,最大化模型logits与真实标签之间的交叉熵损失;对于CW攻击,最小化扰动 δ δ δ 的 l 2 l_{2} l2 距离和原论文中 f f f 函数的和.
- 各任务具体操作
- 图像分类:使用COCO 2014验证集进行评估,将文本类标签编码为“a photo of ”格式,计算图像编码与编码后的类标签之间的余弦相似度,以此作为类logits进行对抗生成和评估。向LMMs输入提示,让其生成图像中主要对象的单字或短语回答,再对回答进行编码并计算与类标签编码的余弦相似度来完成分类。
- 图像描述:采用COCO图像描述数据集2014val评估图像描述的鲁棒性。先对每张图像的5个图像描述进行编码取平均作为文本编码,计算图像与文本编码的余弦相似度作为图像的logits来生成对抗样本。评估时,让LMMs为图像生成图像描述,编码后与所有图像描述的文本编码计算余弦相似度进行检索。
- VQA:在VQA V2、ScienceQA-Image、TextVQA、POPE和MME这五个流行的VQA数据集上评估LMMs的鲁棒性。对于VQA V2,采用与图像分类任务相同的对抗生成过程;对于其他无真实标签的数据集,先让LLaVA生成合成图像描述,再按照图像描述检索任务的流程生成对抗样本,并遵循各数据集的官方评估程序进行评估。
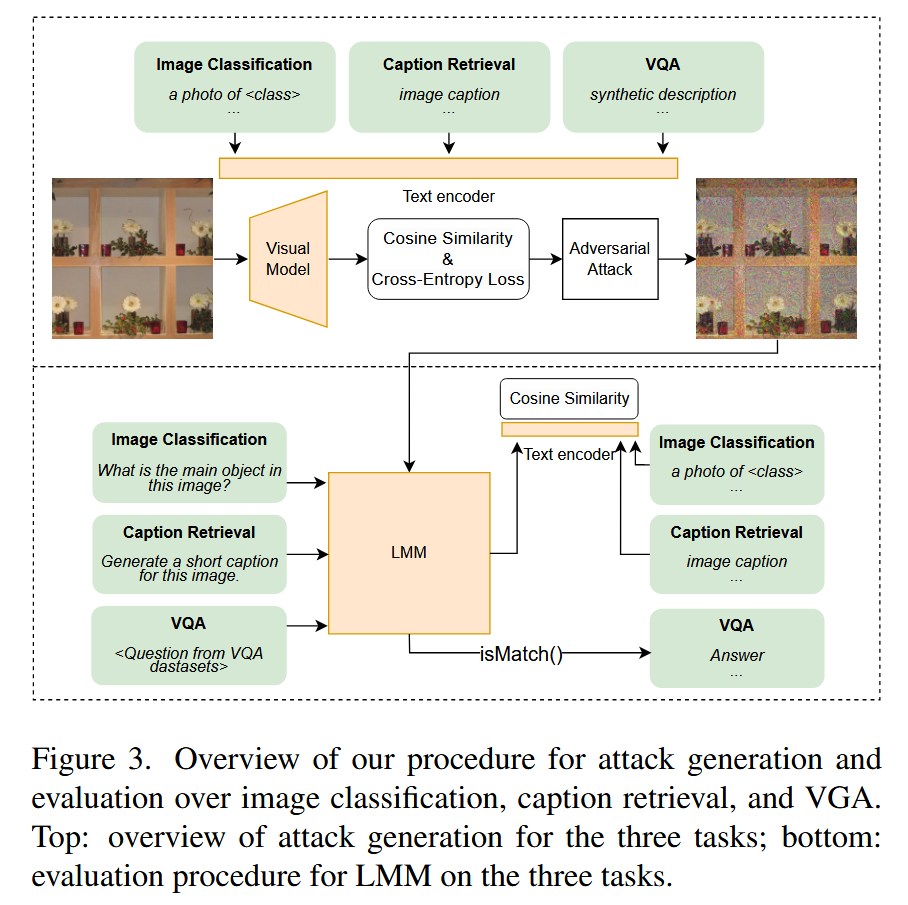
图3. 我们针对图像分类、图像描述和视觉问答(VQA)的攻击生成和评估流程概述。上图:三个任务的攻击生成概述;下图:大型多模态模型(LMM)在这三个任务上的评估流程。
实验结果和分析-Experimental Results and Analysis
LMMs对对抗性视觉输入具有鲁棒性吗?-Are LMMs Robust Against Adversarial Visual Input?
这部分通过对图像描述检索任务的分析,探究大型多模态模型(LMMs)对对抗性视觉输入的鲁棒性,研究发现LMMs在面对此类攻击时缺乏鲁棒性,具体内容如下:
- 研究目的:探究对抗性视觉输入对LMMs的影响,选择图像描述检索任务作为衡量LMMs对视觉输入整体理解能力的指标。
- 实验设置:以COCO 2014val数据集为基础,使用PGD、APGD和CW三种攻击方法,分别在正常(N)和强(S)两种参数设置下,对三个LMMs模型(LLaVA、BLIP2-T5和InstructBLIP)进行攻击实验。
- 实验结果:从表2数据可知,在PGD和APGD攻击下,所有LMMs在正常和强设置下的攻击后准确率均显著下降。如InstructBLIP在PGD-N攻击下,Top-1召回率降至1.9%,PGD-S攻击下进一步降至0.18%。且这些LMMs攻击后的准确率与CLIP/EVA-CLIP攻击后的准确率大致处于同一水平。
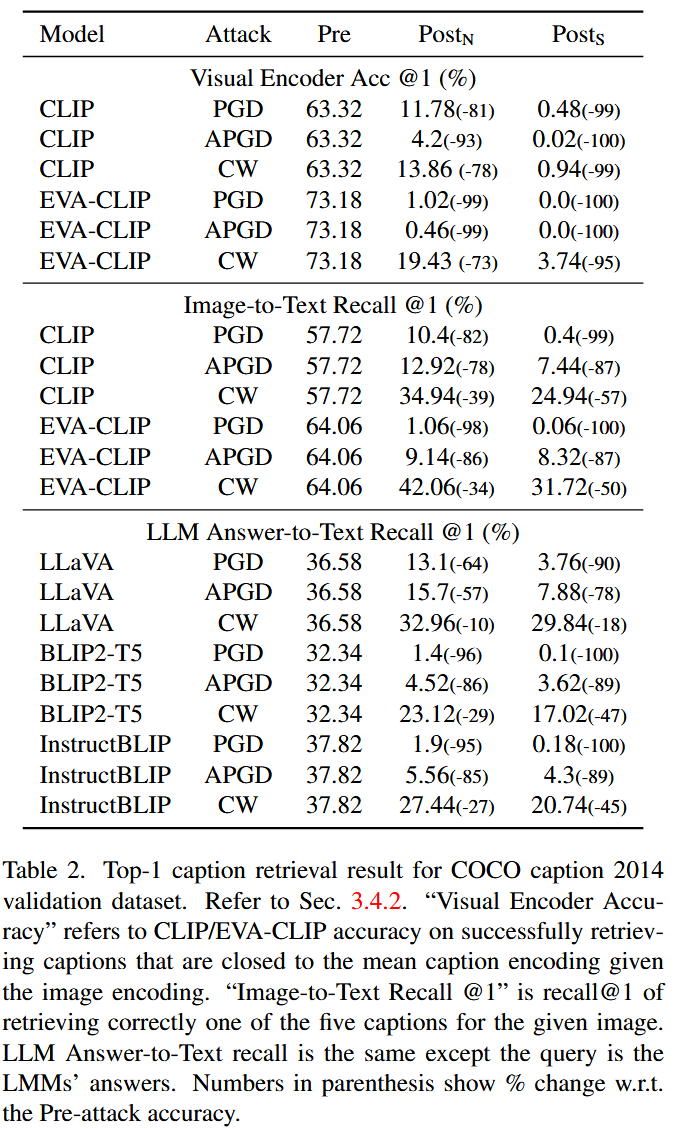
表2. COCO 2014图像描述验证数据集的Top-1图像描述检索结果。参考3.4.2节。“视觉编码器准确率”指的是CLIP/EVA-CLIP在根据图像编码成功检索与平均图像描述编码相近的图像描述时的准确率。“图像到文本召回率@1”是指针对给定图像,正确检索出五个图像描述之一的召回率@1。LLM答案到文本召回率与之相同,只是查询内容是LMMs的回答。括号中的数字表示相对于攻击前准确率的变化百分比。 - 结果分析:这表明即使对抗扰动不是通过针对LMMs文本生成损失的端到端过程生成的,也能严重削弱LMMs的有效性,额外添加到图像编码器的LLM并没有带来显著的鲁棒性提升,即LMMs对视觉对抗扰动缺乏鲁棒性。
评估LMMs的视觉问答(VQA)性能-Evaluating LMMs’ VQA Performance
这部分主要介绍了在对抗视觉攻击下,LMMs在VQA任务中的实验结果、分析以及相关猜想,具体内容如下:
- 实验结果:在VQA任务中,研究对三个LMMs(LLaVA、BLIP2-T5和InstructBLIP)在五个流行的VQA数据集(VQA V2、ScienceQA - Image、TextVQA、POPE和MME)上进行了对抗视觉攻击实验。结果显示,尽管相应视觉编码器的对抗准确率显著下降,但所有被评估的LMMs在各种VQA数据集中都表现出相当的韧性。例如在ScienceQA数据集上,所有三种攻击类型下,CLIP和BLIP视觉编码器的“Visual Encoder Accuracy”在攻击后均大幅下降至1%以下,然而三个LMMs的准确率相较于攻击前下降幅度均小于7%。
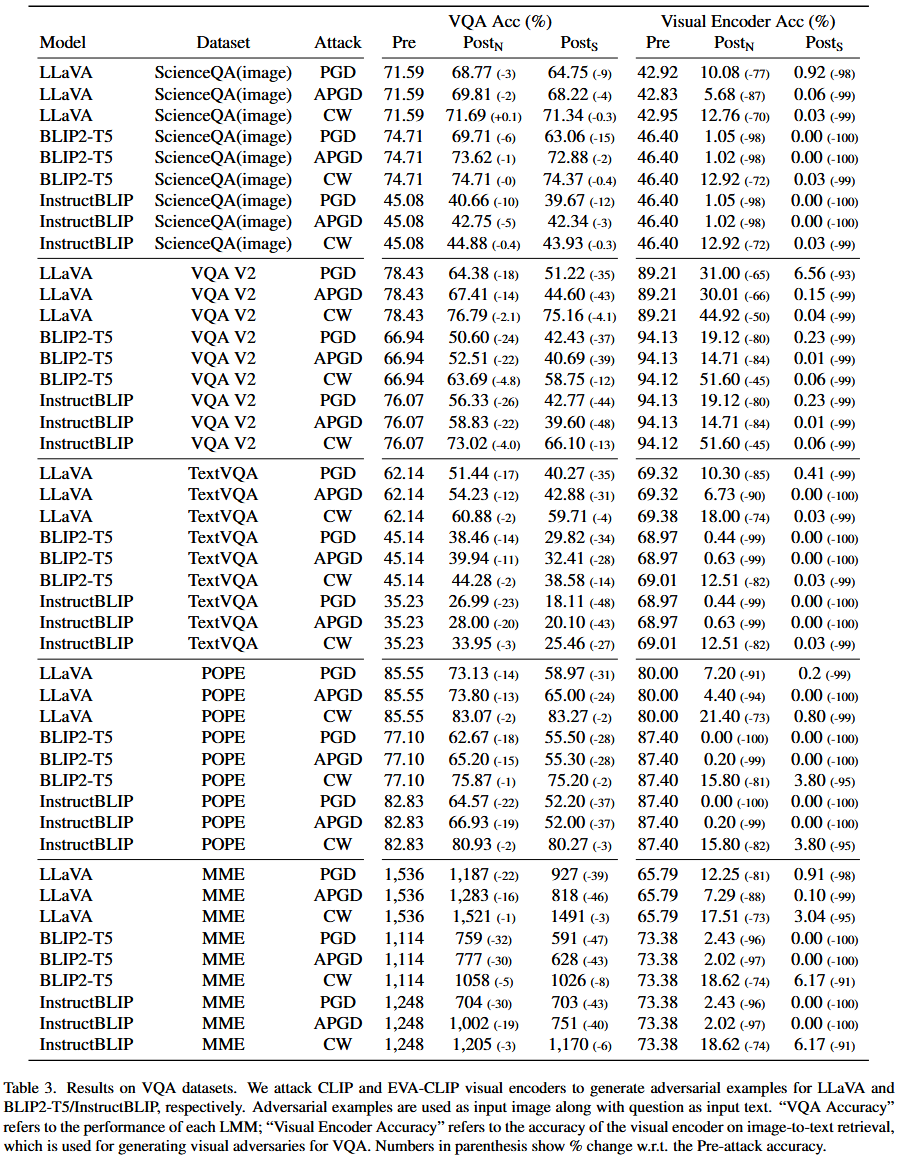
表3. 视觉问答(VQA)数据集的结果。我们分别攻击CLIP和EVA-CLIP视觉编码器,为LLaVA和BLIP2-T5/InstructBLIP生成对抗样本。对抗样本与问题作为输入文本一起被用作输入图像。“VQA准确率”指的是每个大型多模态模型(LMM)的性能;“视觉编码器准确率”指的是视觉编码器在图像到文本检索任务中的准确率,该准确率用于为VQA生成视觉对抗样本。括号中的数字表示相对于攻击前准确率的变化百分比。 - 差异分析:对比图像描述检索任务中LMMs对视觉对抗攻击缺乏鲁棒性的表现,VQA任务中LMMs的表现存在明显差异。
- 提出猜想:针对这一差异,提出两个猜想。一是LMMs的鲁棒性取决于查询内容是否与被攻击的对象相关,由于生成视觉对抗样本的攻击目标是图像描述中提及的内容,直观上未在描述中提到的方面受攻击影响较小;二是额外的上下文信息(如ScienceQA问题中的上下文)有助于提升LMMs的鲁棒性。后续将通过实验验证这两个猜想。
视觉对抗攻击对LMMs并不具有通用性-Visual Adversarial Attacks are not Universal to LMMs
这部分通过实证分析,以VQA V2数据集为例,探讨了视觉对抗攻击对LMMs的影响并非普遍一致,发现LMMs在特定情况下具有一定应对能力,具体内容如下:
- 研究结论:虽然LMMs对视觉对抗攻击并非天生具有抗性,但当查询焦点与攻击目标不同时,LMMs能够给出正确响应。
- 实验方法:以VQA V2数据集为案例进行研究,使用“a photo of ”作为文本标签生成对抗图像,主要攻击图像的中心对象。在评估时,观察不同查询内容下对抗攻击的效果。
- 实验现象:当查询内容与攻击目标(图像的主要对象)相同时,对抗攻击的效果增强;而当查询内容涉及图像的不同方面时,攻击的影响减弱。如在APGD-S攻击下,LLaVA对两张对抗图像的一般性描述回答错误,但对于其他不直接涉及被攻击对象属性的问题,如“Was this taken at sunset?”等,仍能正确回答。

图4. 两张来自COCO 2014验证集的对抗样本图像,由APGD PostS生成。“LLaVA”和“LLaVA(adv)”分别指LLaVA使用攻击前的干净图像和攻击后的图像所做出的回答。在每个单元格中虚线的上方,我们向LLaVA询问图像的总体描述;虚线下方的问题则取自VQA V2数据集。 - 结果分析:分析认为这种现象的原因,一是LLaVA可能从上下文直接“猜出”答案,这与LMMs在ScienceQA数据集上的高“鲁棒性”一致,该数据集中文本常足以找到答案;二是这些问题不直接查询对象或其属性,而是关于图像的周边方面。从LLaVA在APGD-N攻击下按问题类型的准确率下降情况来看,关于对象及其直接属性的“What”类问题准确率下降最多,而“Is/Has/Can”等查询图像周边方面的问题,虽然回答正确需要更复杂推理,但准确率下降幅度小得多,再次证实了上述猜想。
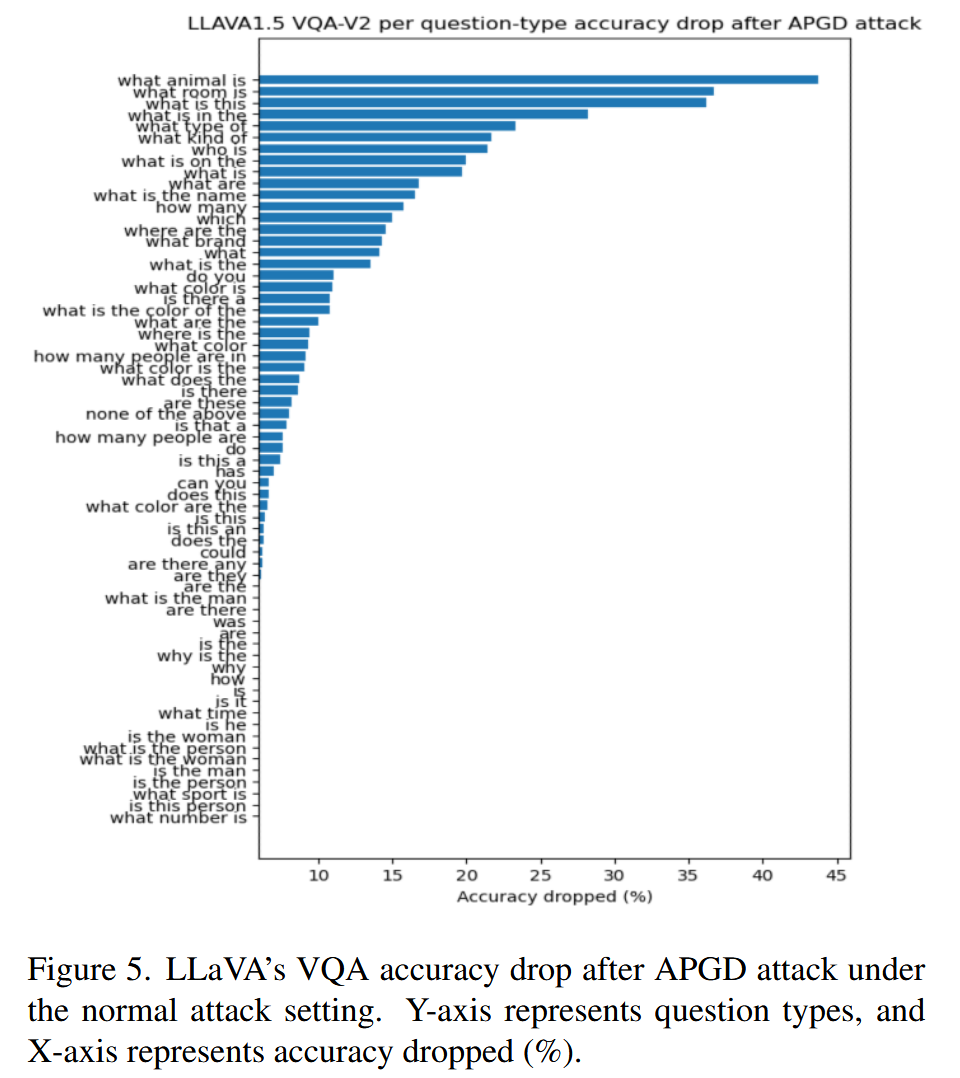
图5. 在正常攻击设置下,经过自适应投影梯度下降(APGD)攻击后,LLaVA在视觉问答(VQA)任务中的准确率下降情况。纵轴表示问题类型,横轴表示准确率下降的百分比(%)。
添加上下文可提高语言模型的鲁棒性-Adding Context Improves LMM Robustness
这部分主要研究添加上下文对LMMs鲁棒性的影响,通过在图像分类任务中添加上下文信息进行实验,发现添加上下文可显著提升LMMs在对抗攻击下的准确率,具体内容如下:
- 实验设计:利用图像分类任务来研究上下文对LMMs鲁棒性的影响。首先让LLaVA为每个类别生成一个通用的一句话描述,然后将与正确对象对应的描述插入到向LMMs查询图像主要对象的提示中,其他条件保持不变。
- 实验结果:从表4数据可知,添加简短的上下文句子后,三个LMM模型在遭受攻击后的准确率均大幅提升。例如,BLIP2/InstructBLIP在PGD/APGD攻击下,准确率下降幅度从平均60%降至仅20%。不过,添加上下文后的准确率仍未达到攻击前的水平。
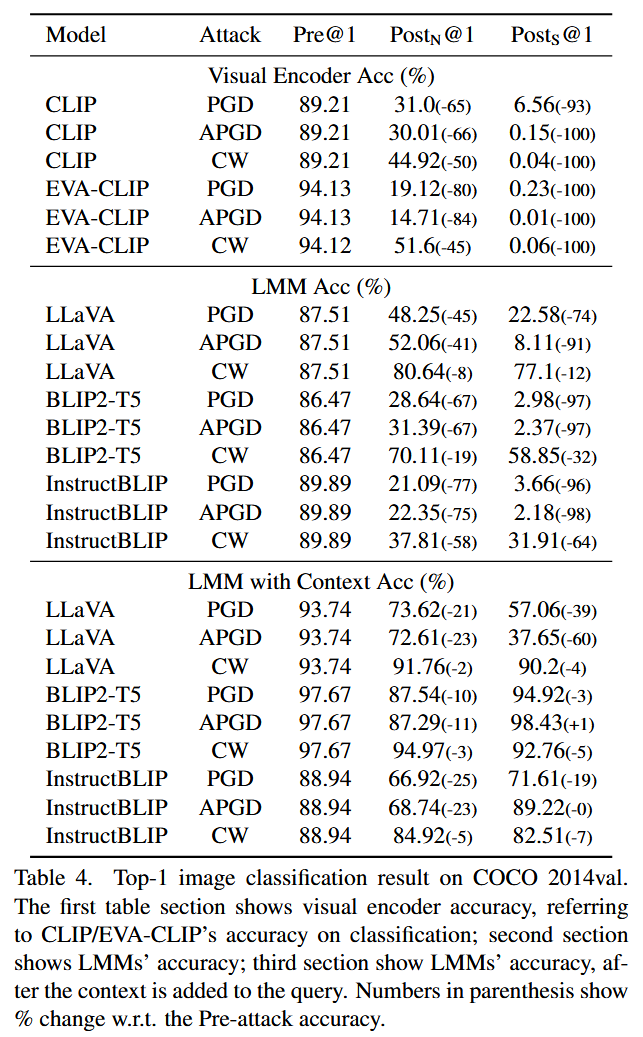
表4. COCO 2014验证集上的Top-1图像分类结果。表格的第一部分展示了视觉编码器的准确率,即CLIP/EVA-CLIP在分类任务上的准确率;第二部分展示了大型多模态模型(LMMs)的准确率;第三部分展示了在查询中添加上下文后大型多模态模型(LMMs)的准确率。括号中的数字表示相对于攻击前准确率的变化百分比。 - 结果分析:这表明提供额外上下文对抗对抗输入是有效的,可能是帮助LLMs从受损的视觉输入中恢复对象属性,并与正确对象匹配。在识别图像中目标对象(如非法物体检测)的任务中,即使图像可能被故意操纵或为对抗样本,添加上下文也很有用。此外,还观察到在PGD和APGD攻击下,BLIP2-T5和InstructBLIP的强设置攻击后(Posts)准确率高于正常设置,在APGD攻击下甚至高于攻击前。推测是因为APGD-S对EVA-CLIP攻击效果过强(攻击后分类准确率仅0.01%),使得BLIP2-T5和InstructBLIP仅依赖对象描述生成答案,忽略了对抗视觉输入,从而产生幻觉将对象描述作为答案。而LLaVA未出现这种情况,可能是由于LLaVA和BLIP融合两种模态的方式不同,LLaVA将视觉输入作为独立于文本令牌的单独令牌,而BLIP利用Q-former将两种模态混合,可能导致文本信号在融合中占主导,从而掩盖了视觉输入信号。
现实世界应用:上下文增强图像分类-Towards Real-World Application: ContextAugmented Image Classification
这部分主要介绍了一种针对实际应用的上下文增强图像分类方法——查询分解,通过实验验证其能提升模型在对抗攻击下的鲁棒性,具体内容如下:
- 方法提出:在实际应用中,正确的上下文通常未知。但在封闭世界图像分类(即对象类别列表固定)的场景下,研究者提出将每个问题分解为多个存在性问题的方法,即查询分解。每个存在性问题用于查询一个对象类别的存在情况,并附上相应对象的上下文,最后从LLM的最终投影头中选择置信度最高的对象作为分类结果。
- 方法优势:这种方法虽看似简单直接,但具有内在的并行处理优势,能同时对多个查询进行处理,提高了效率,为实际应用提供了可行的起点。
- 实验验证:研究者使用COCO 2014val和Imagenet 2012 val数据集进行实验。在实验中,对于每张图像,随机选择20个对象类并确保包含正确的对象类。结果显示,使用查询分解并添加上下文(“LMM Query Decomp”)后,模型在对抗攻击下的鲁棒性有显著提升。与未添加上下文和查询分解的情况(“LMM plain Acc”)相比,COCO数据集上攻击后的准确率下降幅度大多减少了10%,Imagenet数据集上减少了20%。而且,在ImageNet分类任务中,使用查询分解方法后,模型的性能得到了极大提升,通过对比“LMM Query Decomp”和“LMM Plain Acc”的预攻击性能可明显看出。
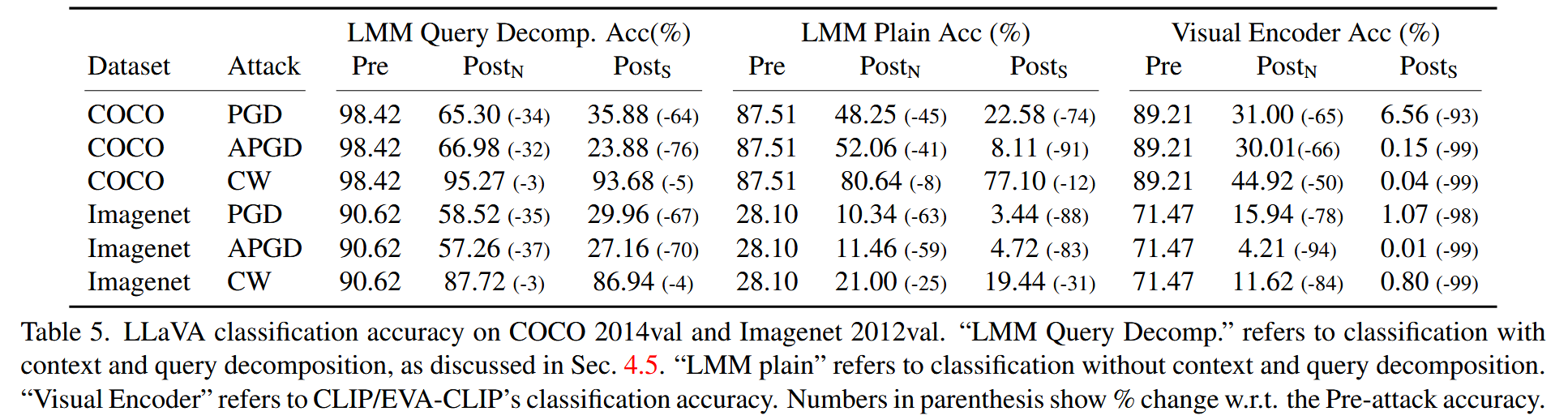
表5. LLaVA在COCO 2014验证集和ImageNet 2012验证集上的分类准确率。“LMM查询分解”是指如第4.5节所讨论的,结合上下文和查询分解进行的分类。“LMM普通模式”是指不使用上下文和查询分解的分类。“视觉编码器”是指CLIP/EVA-CLIP的分类准确率。括号中的数字表示相对于攻击前准确率的变化百分比。
结论-Conclusion
这部分主要总结了研究成果,指出当前LMMs在视觉对抗攻击下的脆弱性、现有攻击策略的局限性,强调添加上下文和新方法的作用,为后续研究指明方向,具体内容如下:
- LMMs的脆弱性:通过系统评估,研究发现LMMs对视觉对抗攻击较为脆弱,即便对抗样本仅针对视觉模型生成,也会对其性能产生显著影响。
- 攻击策略的局限性:传统针对特定任务的对抗样本生成技术,对当前LMMs并非普遍有效。当查询和攻击目标不匹配时,LMMs表现出一定“鲁棒性”,这表明需要进一步研究新的对抗攻击策略,特别是在零样本推理的背景下。
- 上下文和新方法的作用:研究发现添加上下文能提升LMMs的视觉鲁棒性。基于此提出的查询分解策略,即将问题分解为多个与相应上下文相关的存在性问题,在COCO和ImageNet分类任务中显著提高了模型的鲁棒性。
- 未来研究方向:该研究揭示了LMMs鲁棒性此前未被充分探索的方面,为未来增强多模态系统在对抗环境中的韧性奠定了基础,后续研究可围绕新的对抗攻击策略以及进一步提升LMMs在对抗环境中的性能展开。


















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











