






目录
文章概览
本文改编自实验室最新综述论文《交通大模型综述》,该论文发表于《交通运输工程学报》(ISSN 1671-1637,CN 61-1369/U)。该期刊由教育部主管,长安大学主办,国务院学位委员会交通运输工程学科评议组、西南交通大学、东南大学共同协办。《交通运输工程学报》目前是中国科协《公路运输领域高质量科技期刊分级目录》T1级期刊、中国科协“中国科技期刊卓越行动计划”第一、二期入选期刊,被Ei Compendex、Scopus、Inspec等国外著名数据库收录,被《中国科学引文数据库》(CSCD核心库)、《中国科技论文与引文数据库》(CSTPCD)、北京大学《中文核心期刊要目总览》收录。在《中国科技期刊引证报告》中,该期刊在综合交通运输领域期刊中综合排名第1位。
文献来源:
肖建力,邱雪,张扬,等.交通大模型综述[J/OL].交通运输工程学报,1-26[2025-02-13].http://kns.cnki.net/kcms/detail/61.1369.U.20250211.1608.002.html.
论文下载地址:
(1)百度网盘下载
https://pan.baidu.com/s/1x6tx-DoM34uxZr91b_sabQ?pwd=b3jp
(2)知网下载
https://kns.cnki.net/kcms2/article/abstract?v=YBmesx2FU7kKxMSgfS8fK7b8DatblelTVaMdqSZBiScpjIIA1So2mejRPBC9vJw7MjKW9UT4jqE-0vW6ZjhTDGOBbe3eSHqD1R0Ee-ZnM5uKBTsli0b0X651gOUo4tqS0JohkM6zBUrCyS2DnH4kTmRYIVPxzt0JGi7SubJ-MoqZcPAVS2BEH6_Gm_PYxahe&uniplatform=NZKPT&language=CHS
1. 大模型
自20世纪50年代“人工智能”概念被提出,大模型技术发展始于萌芽阶段。1998年LeNet-5出现,推动了机器学习从浅层转向深度学习,由此为后续大模型发展奠定了基础。2006-2018年是大模型技术发展的探索时期,GAN以其独特的对抗性训练架构在多个领域展现了强大的性能。Transformer的提出,为大模型主体算法架构奠定了基础,BERT和GPT-1的提出标志着预训练大模型在自然语言处理领域的兴起。大模型通常含数千亿参数,通过在大规模文本数据集上进行预训练,可用于自然语言理解与生成等任务。2020年起多种大模型不断涌现,它具有涌现能力(如上下文学习、指令遵循、逐步推理)和扩展法则,可进行任务微调,还能调用外部工具用于弥补其性能的不足。大模型的发展历程具体如图1所示,其中包含典型模型的名称及其参数大小。
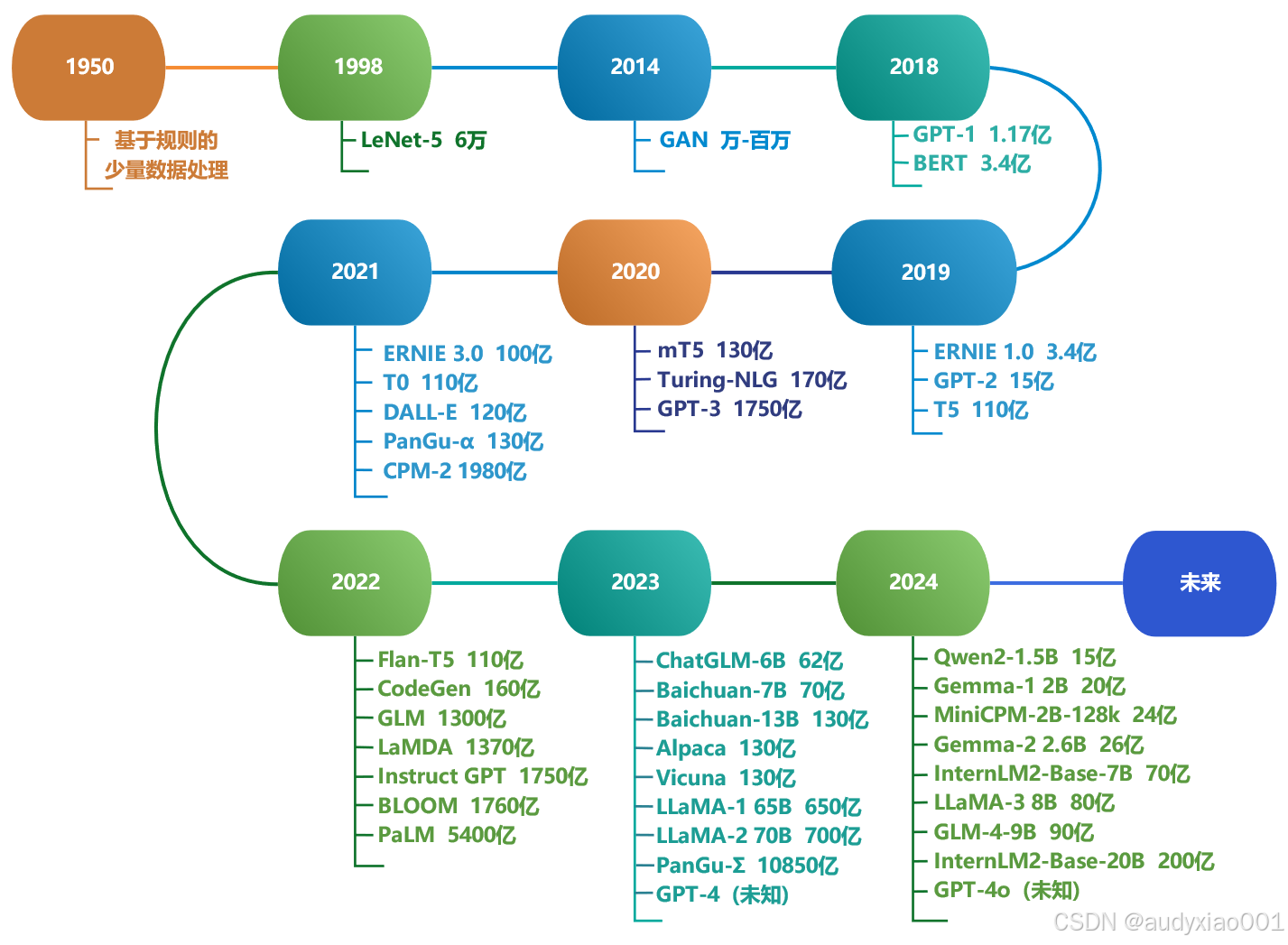
图1 大模型的发展历程
随着大模型在交通领域的认可度不断提高,相关研究人员已将其应用到自动驾驶系统和智能交通领域中。在自动驾驶系统中,通过集成数据,使车辆能够深入地感知真实世界的环境并做出相应的行为决策,从而提高驾驶的安全性和效率。在智能交通领域中也有相关的应用,可以使用大模型分析交通数据并预测未来交通状态,以便优化路线规划和改善交通管理;也可以使用大模型对驾驶行为进行学习,训练出能够识别潜在的危险行为并提供实时驾驶建议的新模型;还可以将大模型应用于车载助手系统,使驾驶人员能够通过语音与车辆进行交互,最终提高驾驶安全性和便利性。
交通数据往往存在多种形式,如文本、图片、视频、语音等。这就不得不介绍一下视觉大模型和多模态大模型了。视觉大模型和多模态大模型接收的数据形式不是单一的文本,还可以接收图片、视频、语音等其他形式的数据,随后能够生成文字、图片、视频等内容。在图2中详细介绍了多模态大模型的5种任务类型:图像描述、视觉推理、图像生成、图文检索和视觉问答,并分别通过示例直截了当地向读者展现出来。
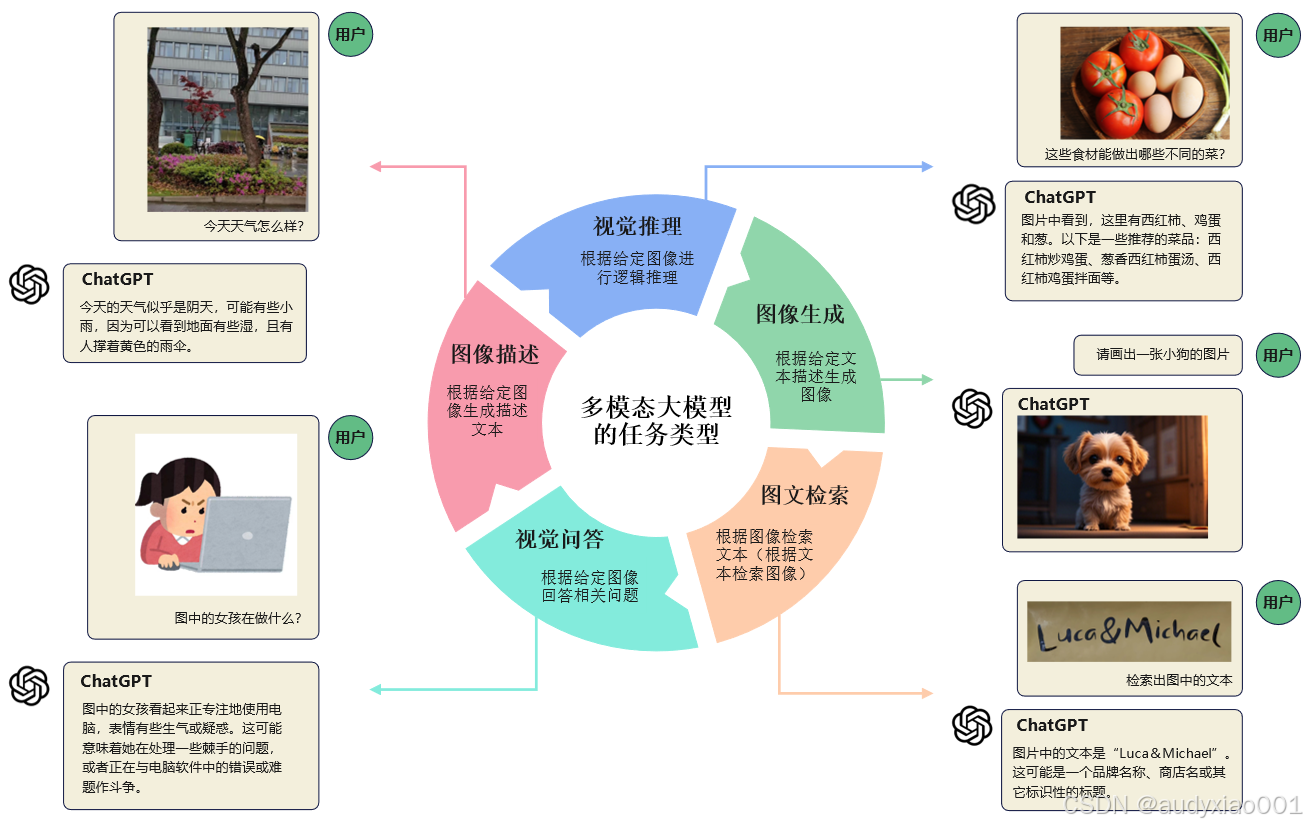
图2 多模态大模型的任务类型
论文中还介绍了多模态大模型的模型架构和训练方法,以MiniGPT4为例,如图3所示。MiniGPT4的模型架构主要包含三部分。首先是Vicuna模型,其被引入旨在降低模型训练成本,在MiniGPT4中承担着同时理解文本与图像数据输入,并生成符合指令文本描述的关键任务。其次为视觉编码器,它的作用是把原始视觉输入转化为高级且紧凑的特征表示,以助力模型完成如图像描述、视觉问答或跨模态检索等不同下游任务。该视觉编码器由ViT和图文对齐模块Q-Former组成,图像输入后,先经ViT初步编码提取特征向量,再由Q-Former将文本转为嵌入向量,通过训练实现图文嵌入对齐,其中Q-Former选用了在处理文本方面性能优越的预训练BERT模型。最后是线性投影层,鉴于视觉编码器与大模型之间存在差距,MiniGPT-4添加此可训练层,通过训练将视觉编码器的输出特征与Vicuna模型对齐,方便后续计算。
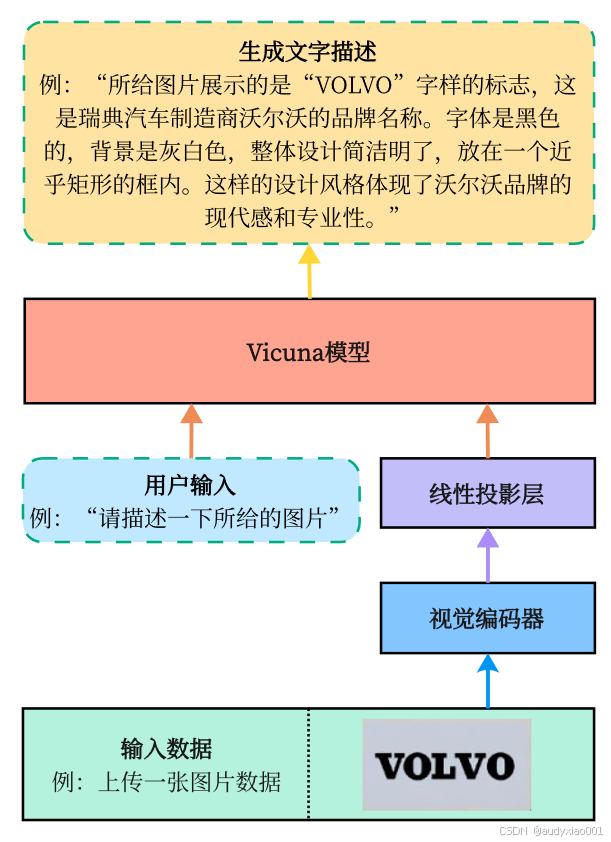
图3 MiniGPT-4的模型架构
MiniGPT-4的模型训练分为两个阶段。预训练阶段,模型在大量通用图像-文本数据集(如Conceptual Caption、SBU和LAION的组合数据集)上进行无监督预训练,借此学习基础视觉语言知识。完成首轮训练后,虽模型获得了丰富图像知识并能生成合理文本描述,但有时输出不符合用户要求。为此,研究者构建了高质量图像-文本数据集,构建时考虑使用提示策略使模型生成更全面文本描述,同时运用ChatGPT作为自动化文本质量评估者,对预训练生成的5000份图像-文本数据进行检查修正,最终保留3000对符合要求的数据用于下一阶段训练。微调阶段,模型在少量高质量图像-文本数据集上进行有监督微调,进一步提升第一阶段预训练模型的生成质量与综合表现,微调后MiniGPT-4能生成更流畅、自然的视觉问答反馈,展现出强大的视觉理解能力。
2. 交通大模型
TransGPT作为国内首个开源的交通大模型,在真实的交通应用场景中发挥关键作用。该模型具备多种功能,如交通状况预测、交通规划、交通安全教育、交通管理、事故报告与分析,以及自动驾驶系统支持等。TransGPT涵盖了广泛的交通领域知识,能服务于多个相关领域,如道路、桥梁、隧道、公路和水路运输等,展现其在各种交通场景中的适用性和灵活性。
模型训练中使用到的开源数据集分为:通用预训练数据集和交通领域数据集。实验中,研究者使用TransGPT-7B模型对交通情况预测、交通规划、交通安全教育、事故报告和分析等任务进行测评,结果显示TransGPT在交通领域中的任务表现优异,特别是在驾照考试、交通标志识别和交通工程等任务中表现,超过了多个基线模型。为了方便读者使用,表1中列出了TransGPT系列模型的下载链接。
表1 TransGPT模型的下载链接
| 模型 | 下载链接 |
| TransGPT-7B-v0 | |
| TransGPT-MM-6B-v0 | |
| TransGPT-MM-6B-v1 |
2023年3月百度发布文心一言,随后推出文心交通大模型,利用时空Transformer技术结合交通变化与道路拓扑,综合多因素构建大量交通学习任务,通过多目标、多任务预训练及对关键区域样本模型微调,增强了模型的通用性和泛化能力。在百度地图V18版本中,该模型让信控区域交通出行效率提升15%-30%,显著提升了用户导航体验,开启智慧出行新篇章。
为了解决城市感知场景中数据稀缺的挑战,香港大学在2024年3月与百度联合推出智慧城市大模型UrbanGPT,模型架构如图4所示。图4(a)为时空依赖编码器,通过多层级时间卷积网络捕捉时空数据的时间依赖性,各层代表不同时间维度抽象级别,门控机制调控层间信息流动以生成时空依赖特征表示;图4(b)中UrbanGPT采用创新指令调整方法训练,借助历史数据和词元引导模型生成预测词元,再经文本替换技术转化为实际数值预测结果,以此结合时空模式与指令性文本处理含具体数值的预测任务,从文本指令和时空信号中学习;图4(c)表明模型零样本预测时,可在一个城市训练后转移到未见过的城市测试,无需在测试城市额外训练,在跨城市泛化中性能卓越,通过多任务学习、参数训练与冻结实现高效知识迁移,凸显基于文本指令进行任务分配和预测的优势。实验结果证明:UrbanGPT模型的提出不仅提升了交通流量和相关事件的预测精度,还为城市交通管理和规划提供了强大的技术支持,但仍需进一步优化其计算开销和长时间依赖建模能力。
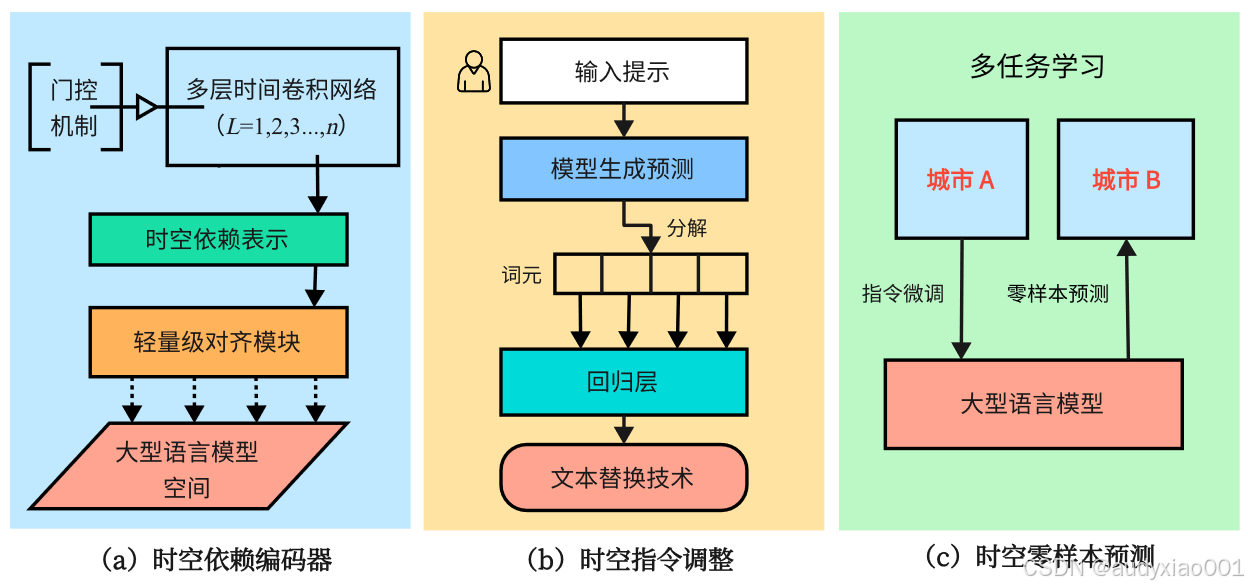
图4 UrbanGPT模型整体架构
为了处理并预测城市环境中的交通动态,如车流量、人流移动、交通事故的概率等。2024年2月提出了交通大模型UniST,这是一个用于城市时空预测的通用模型。图5(a)为时空预训练模块,模型先把大量城市时空数据处理为ST Tokens数据块,经块嵌入层编码成嵌入向量,再通过时空掩码模块的训练机制学习预测被遮蔽部分以提升对数据的理解与预测能力,随后嵌入数据块送入能捕获复杂时空关系的Transformer模块,最后由投影层将其处理后的向量转化为最终预测结果。图5(b)为预训练模型微调模块,多样时空数据输入后经嵌入层得到嵌入数据,此时提示网络的空间记忆池和时间记忆池产生提示信息,与嵌入数据一同输入Transformer模块,经投影层将处理后的向量转化为最终预测结果。微调过程中,部分参数冻结以保留预训练模块中学到的通用特征、避免过拟合并降低计算成本,部分参数微调使模型更好适应特定任务特征,提升预测性能。实验结果证明,UniST在通用性和跨域学习能力上展现了明显优势,特别是在零样本或小样本场景中,其迁移学习能力比传统模型更加高效。然而,较高的计算成本和时空数据的有限多样性仍然是其主要挑战。
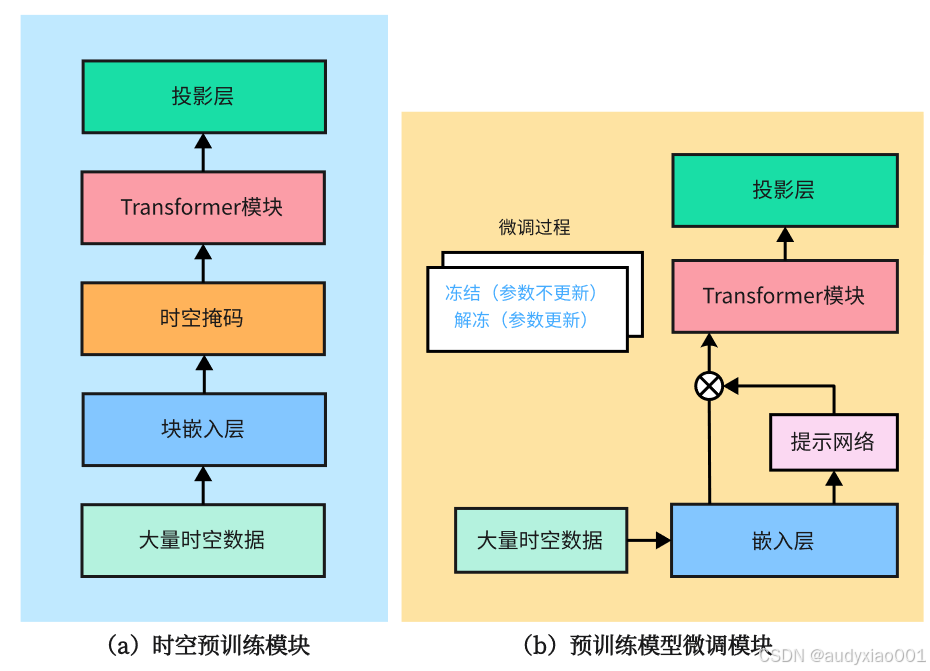
图5 UniST的模型架构
除此之外,论文中还介绍了其他交通大模型(详细见论文链接)以及交通领域内的常见数据集,这些数据集可以通过数据预处理技术,处理成适合大模型输入的格式,最终应用于大模型的预训练和微调阶段。表2展示了交通领域内的常见数据集。
表2 交通领域内的常见数据集
| 数据集 | 简介 | 链接 |
| nuScenes | 收集了波士顿和新加坡近1000个复杂的驾驶场景。数据集由140万张图像、39万次激光雷达扫描和140万个3D人工注释边界框组成。 | |
| Mapillary Vistas Dataset | 一个大规模街道级图像数据集,包含2.5万个高分辨率图像,有66个对象类别,另有37个类别特定于实例的标签。 | https://www.mapillary.com/dataset/vistas?pKey=xyW6a0ZmrJtjLw2iJ71Oqg&lat=20&lng=0&z=1.5 |
| ApolloCar3D | 包含5277个驾驶图像和超过6万的汽车实例,其中每辆汽车都配备了具有绝对模型尺寸和语义标记关键点的行业级3D CAD模型。 | |
| BBD1000K | 由10万个视频和各种注释组成,包括图像级别标记,对象边界框,可行驶区域,车道标记和全帧实例分割。该数据集具有地理,环境和天气多样性。 | |
| The SYNTHIA dataset | 由13个类别精确的像素级语义注释:天空,建筑,道路,人行道,围栏,植被,杆,汽车,标志,行人,骑自行车的人,车道标记。 | |
| KUL Belgium Traffic Sign Dataset | 包含数千个不同的交通标志,1万多个交通标志注释。使用8个高分辨率摄像头录制的4个视频序列安装在一辆面包车上,录制时间总计超过3个小时。 | |
| Bosch Small Traffic Lights Dataset | 包含13427个分辨率为1280x720像素的摄像机图像,并包含约2.4万个带注释的交通信号灯。其中注释包括交通信号灯的边界框以及每个交通信号灯的当前状态。 | Bosch Small Traffic Lights Dataset | Heidelberg Collaboratory for Image Processing (HCI) |
| GTSRB | 德国交通标志基准测试,其中有超过40个类别,一共超过5万张图像。 | |
| Tsinghua-Tencent 100K | 一个大型交通标志基准,有超过10万张图像,包含了3万个交通标志,这些图像涵盖了照明度和天气变换的差异。 | |
| MS COCO dataset | 一个大型的物体检测,分割数据集。以场景理解为目标,通过截取复杂的日常场景,然后进行精确分割并标定位置。图像包括91个类别,32.8万个影像和250万个标签。 | |
| UA-DETRAC | 一个多目标检测和多目标跟踪基准。其中超过14万个帧,标注了8250个车辆和121万个标记的对象边界框。 | Computer Vision and Machine Learning Lab (CVML) | University at Albany |
| BoxCars | 包括11.6万张车辆图像。这些图像由多个监控摄像头拍摄,且来自于多个观察点。 |
3. 交通领域的应用
在当前的交通行业中,“大模型”已成为一项关键技术,它在多个交通领域发挥着重要作用。本节将重点探讨大模型在交通管理和控制、交通安全和自动驾驶这3个领域的应用及其带来的革新。
1. 交通管理和控制
论文中对大模型在交通管理和控制领域的应用做出总结,并探讨各个大模型的优缺点。典型应用如图6所示。交通管理和控制领域涌现出多种创新模型。PromptGAT结合大模型推理与领域知识解决交通信号控制模拟与实际差异问题,却有计算复杂和依赖预训练模型的缺点;TrafficGPT融合ChatGPT与交通基础模型辅助交通决策,处理复杂任务能力强,但对大模型和提示设计依赖大;LLMLight利用大模型能力优化交通信号控制,高效且泛化性强,不过训练复杂、资源需求高;ST-LLM针对交通预测任务,通过独特机制提升预测精度,计算资源需求大但性能优越。
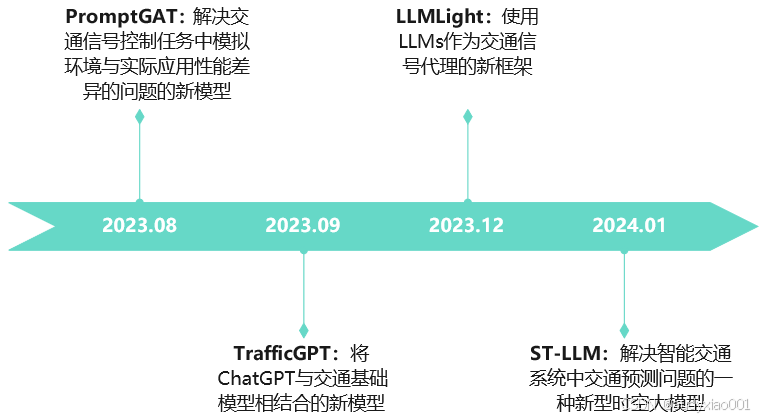
图6 大模型在交通管理和控制领域的应用
2. 交通安全
论文中对大模型在交通安全领域的应用做出总结,并且探讨各个大模型的优缺点,典型的应用如图7所示。在交通安全领域,也出现了多种创新模型和框架。TrafficSafetyGPT基于LLaMA,通过有监督学习微调,利用TrafficSafety-2K数据集训练,在交通安全知识问答上表现出色,处理专业术语和特定场景精准简洁,还提升了训练效率,但数据量有限,泛化能力受限;FMRAUPC结合图像到文本模型和大模型,从摩托车头盔全景摄像头视频中识别危险评估风险,适应性强,不过全景图像处理准确性较低;LLM-FUTC结合大模型和自动化解析工具识别事故报告未报告因素,在识别酒精相关事故上表现出色,优于ChatGPT和LLaMA-2,处理复杂语言输入高效,但对提示设计和生成参数敏感;AccidentGPT是首个引入综合场景理解的多模态大模型,基于V2X架构全面监测道路环境,整合多传感器和人机交互技术,在智能交通管理有强大应用潜力,不过依赖传感器和基础设施,在非联网或基础设施差的环境效果欠佳。
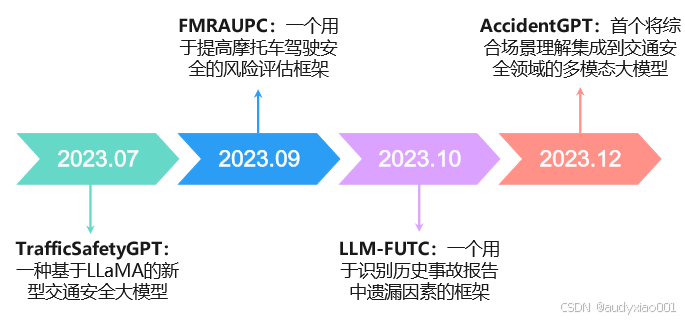
图7 大模型在交通安全领域的应用
3. 自动驾驶
论文中概述了自动驾驶领域大模型的最新进展,探讨了各个大模型的优缺点,典型的应用如图8所示。DriveDreamer基于真实驾驶场景,结合扩散模型与两阶段训练,在复杂自动驾驶任务中表现出色,能生成高质量驾驶视频,但计算复杂、依赖高质量数据且处理非结构化环境有局限。SurrealDriver基于大模型提升交通模拟驾驶行为真实性和多样性,构建“教练代理”培养类人驾驶风格,不过存在响应延迟和受模拟器环境限制问题。DiLu结合大模型推理与反思模块,应对自动驾驶数据集偏差等挑战,实现持续学习,但决策有延迟且可能出现“幻觉”。DriveGPT4基于多模态大模型实现端到端自动驾驶,多模态处理能力强,但实时性和可靠性面临挑战。GPT-Driver将GPT-3.5转化为自动驾驶运动规划器,采用提示—推理—微调策略,推理能力和精度突出,但推理时间长且对传感器数据支持不足。DriveWM是首个兼容现有端到端规划模型的世界驾驶模型,多视角视频生成能力卓越,处理分布外场景表现优异,但计算成本高。LaMPilot面向自动驾驶规划,将任务处理视为编程,通过行为原语生成代码执行任务,处理复杂任务灵活但存在碰撞率和推理时间长问题。LMDrive以语言为导向,实现端到端闭环自动驾驶,结合多模态输入,提升复杂场景安全性和适应性,但计算复杂度高、推理时间长。DriveMLM利用多模态大模型模拟行为规划模块,结合多模态数据实现闭环控制与解释说明,复杂场景表现优异,但计算复杂、处理长指令有延迟且泛化能力待优化。DriveLM基于图形视觉问答实现端到端自动驾驶,借助专门数据集在开放循环规划等任务中表现出色,但推理速度慢、缺乏闭环规划支持且处理传感器数据能力有限。
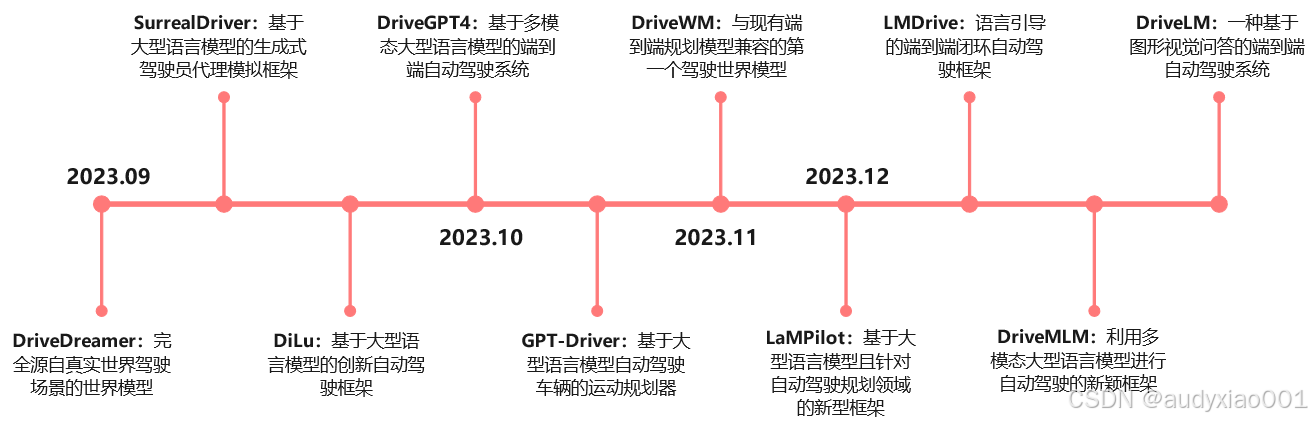
图8 大模型在自动驾驶领域的应用
4. 结语
1. 大模型在交通领域的应用正逐渐成为行业焦点。文章开篇介绍了大模型、视觉大模型和多模态大模型,分析它们处理不同数据时的特点优势,进而总结现有交通大模型,并展示其在交通管理控制、交通安全、自动驾驶等方面的关键应用,极大推动了交通领域发展。
2. 本文贡献突出,系统总结交通大模型应用,通过对比提出应用策略,还发现现有研究存在的关键问题,如稀疏数据下表现不佳、数据和计算资源需求大、实时性可靠性低、处理动态场景有响应延迟等。
3. 展望未来,研究需要关注提升大模型的可解释性、准确性和安全性。可以考虑引入可解释AI结构、优化训练和参数调整、强化隐私保护机制。研究重点一方面在于结合深度交通知识优化任务处理能力,另一方面是探索多模态学习和智能体协作,通过集成外部API来增强模型在复杂场景的适应性,推动智能交通管理更上一层楼。

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









