







背景:
尝试本地笔记本部署大语言模型,为今后工作中部署试点。
笔记本没有独立显卡,计划用轻量级大语言模型在CPU部署。
支持后期模型API调用(不单单是对话框UI方式),使用langchian通过API调用。
步骤:
- 安装运行ollama,下载模型并启用服务,提供API
- 安装langchain-ollama, 通过API调用lamma 3.2
Ollama 安装及大模型下载
1.1)安装ollama, 尝试过其它方式如(llama-cpp)后,感觉还是ollama方便;直接官网下载,https://ollama.com/download,目前windows也支持了
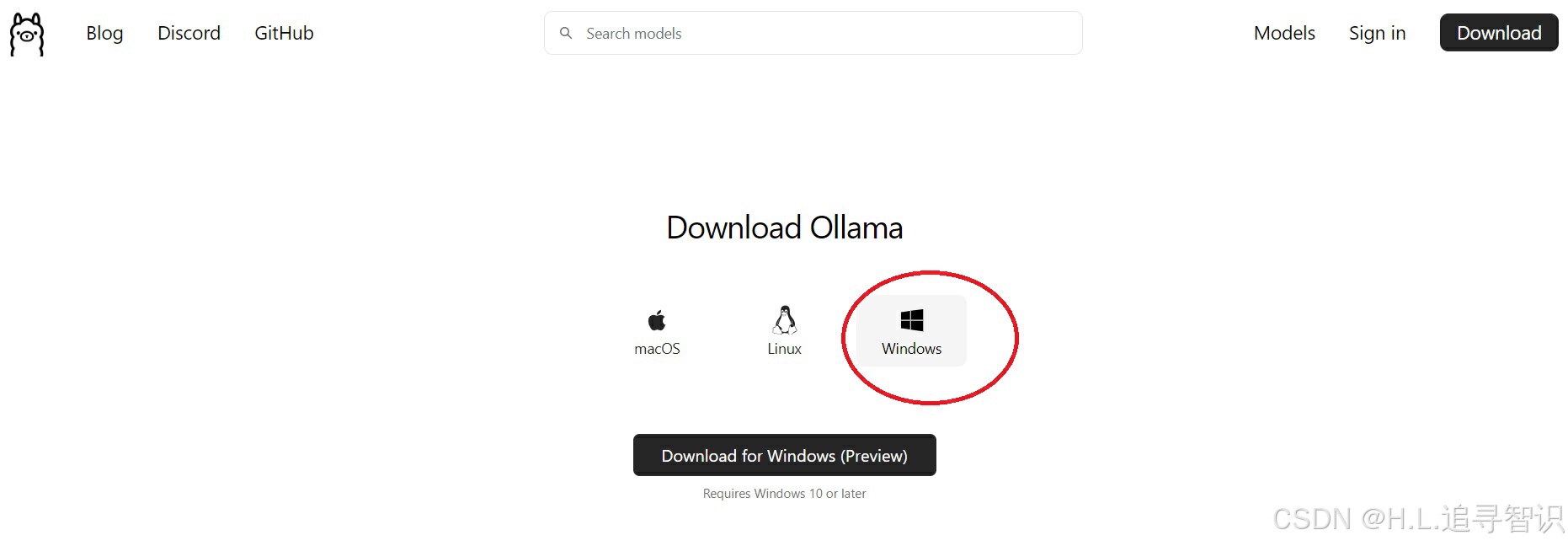
1.2)下载模型到指定路径
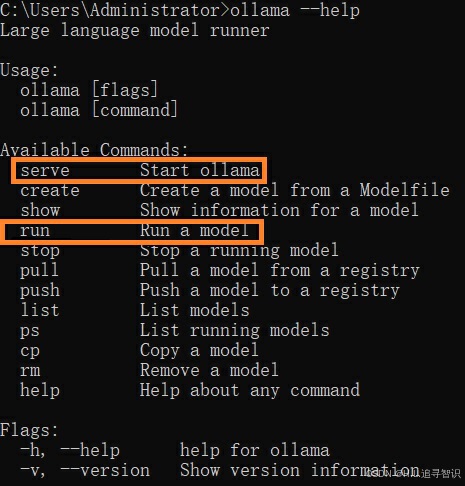
安装完ollama利用命令行窗口输入命令 “ollama --help”,检查一下安装。这里有两个接下来会用的命令。
- run 直接自动下载大语言模型(如果没有下载模型), 并在命令行开始交互;
- serve 开启断开提供服务 (API 模式),本文接下来用langchain对接
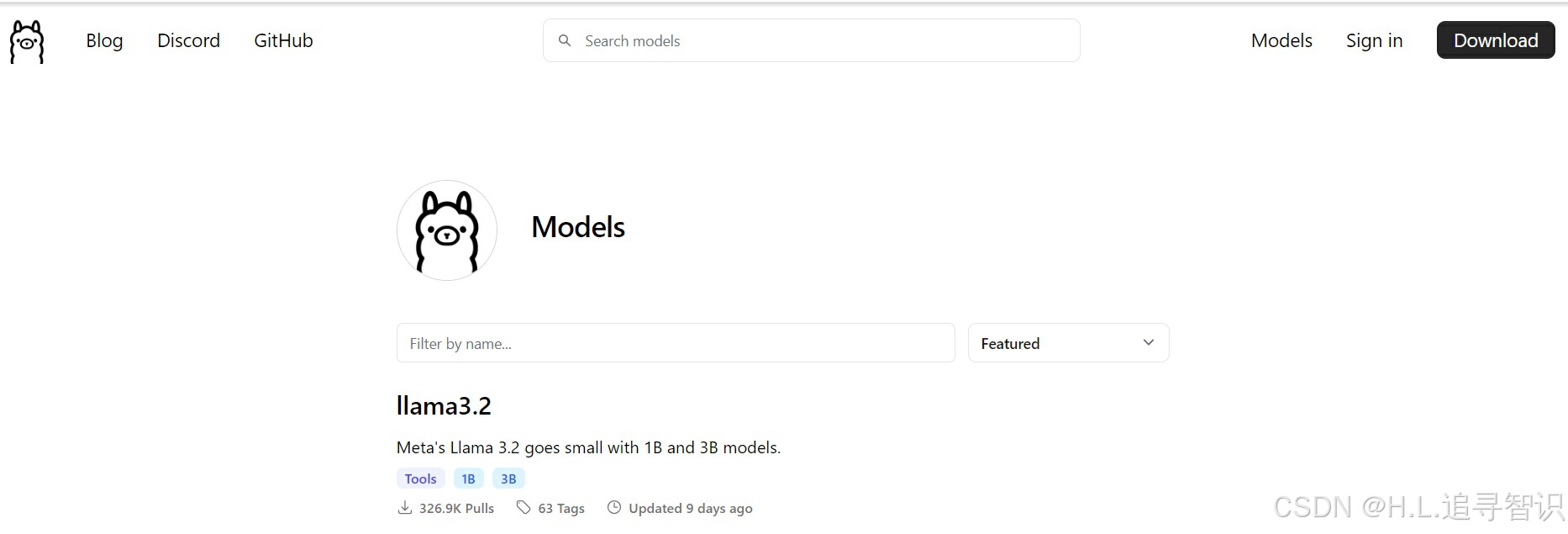
ollama支持的模型信息,也可以在官网上查找(https://ollama.com/library):
并且官网给出了细分模型自动下载(如果没有下载)并运行的命令提示。这里以 lamma3.2为例
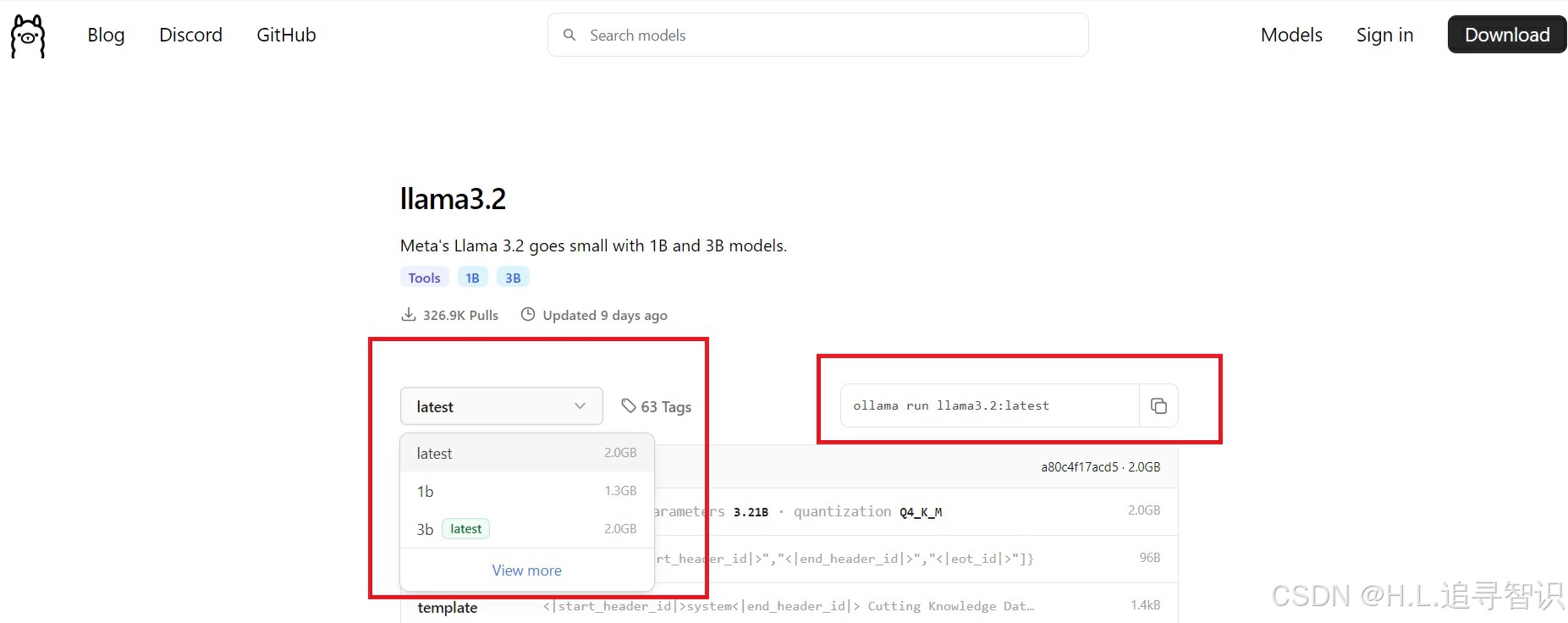
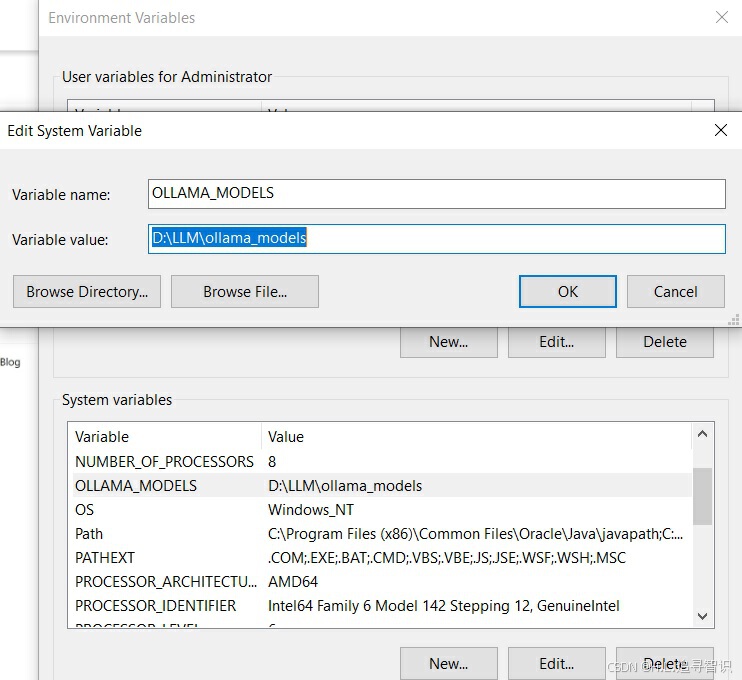
左边标红方框内,下拉框给出了不同版本的选项;右边标红方框内,自动给出相应的命令,复制粘贴到windows命令行中运行即可。第一次运行,下载模型需要一定时间。在下载模型前,如果不想占用C盘空间,先手动修改下载模型路径。在windows系统环境添加环境变量"OLLAMA_MODELS",变量值为指定路径。如下图。API地址也是类似修改方式,变量名OLLAMA_HOST
1.3) 模型下载并启用:
以llama3.2模型为例,通过命令"ollama run 3.2"下载(如果之前没有下载过),之后会自动运行命令行交互界面。
下载模型:
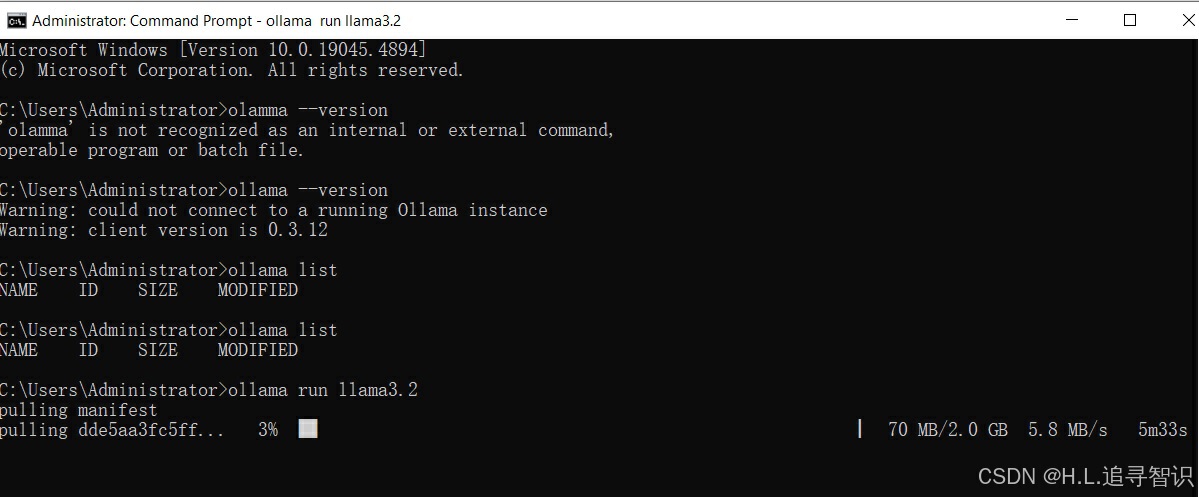
问了一个关于OpenAI的问题

即便无独立显卡的笔记本,流式反应也很快,回答质量也不错。
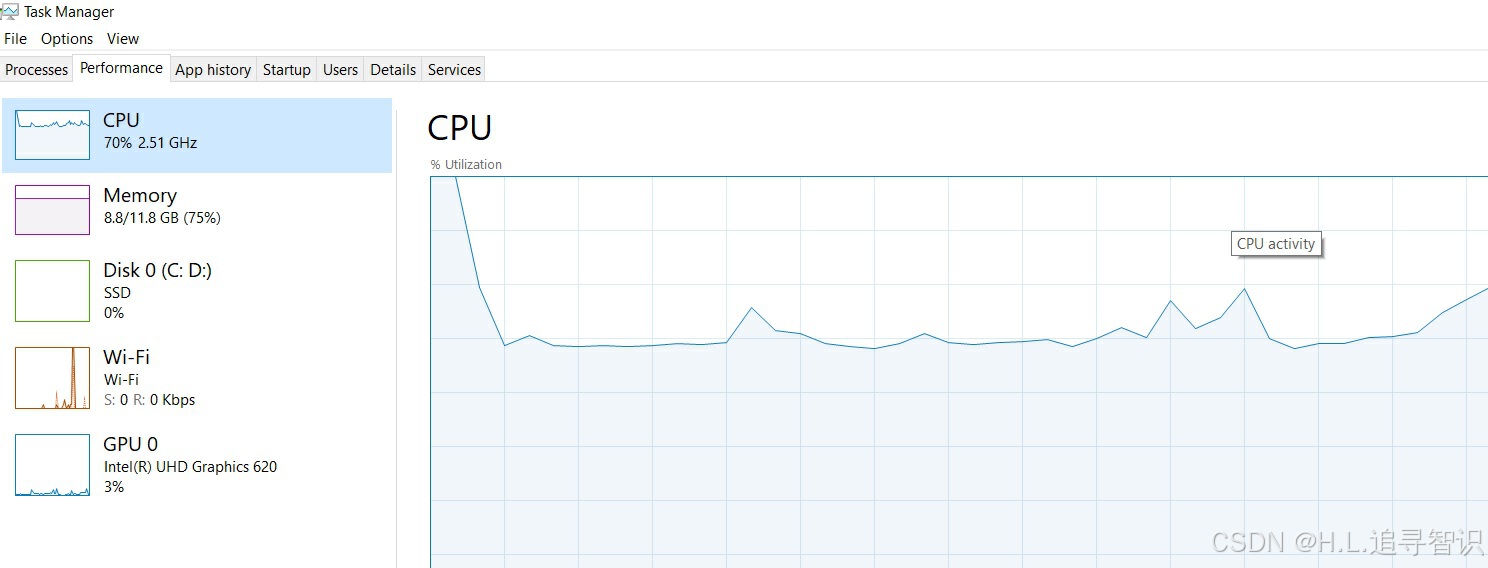
笔记本配置是没有独立显卡:
CPU: Intel(R) Core(TM) i5-8365U CPU @ 1.60GHz 1.90 GHz, 内存12G.运行时观察了一下performance, CPU在交互过程,瞬间飙升到100%后,稳定在70%左右。内存在8.8G(同时正常开了其它应用)。
1.4) Ollama serve 报错:
用快捷键“ctrl + D" 退出命令行模式,输入ollama serve尝试API服务。系统报错:

这时端口大概率是ollama已经在使用了, 执行allama run XX 时,同时也运行了。
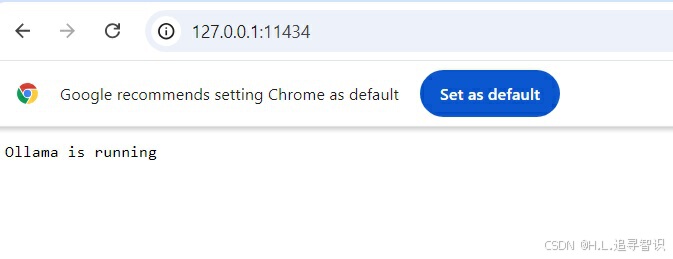
把报错的端口号用网页查看(http://127.0.0.1:11434/) ,可以看到Ollama is running.
可以直接忽视报错,API调用可用;或者可以关闭ollama应用,重新打开命令交互窗口,使用ollama serve.
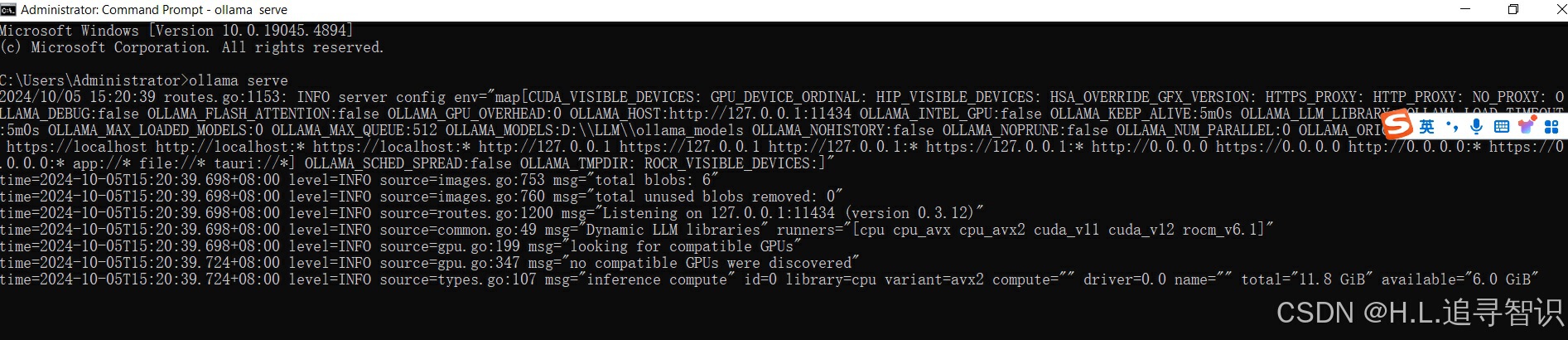
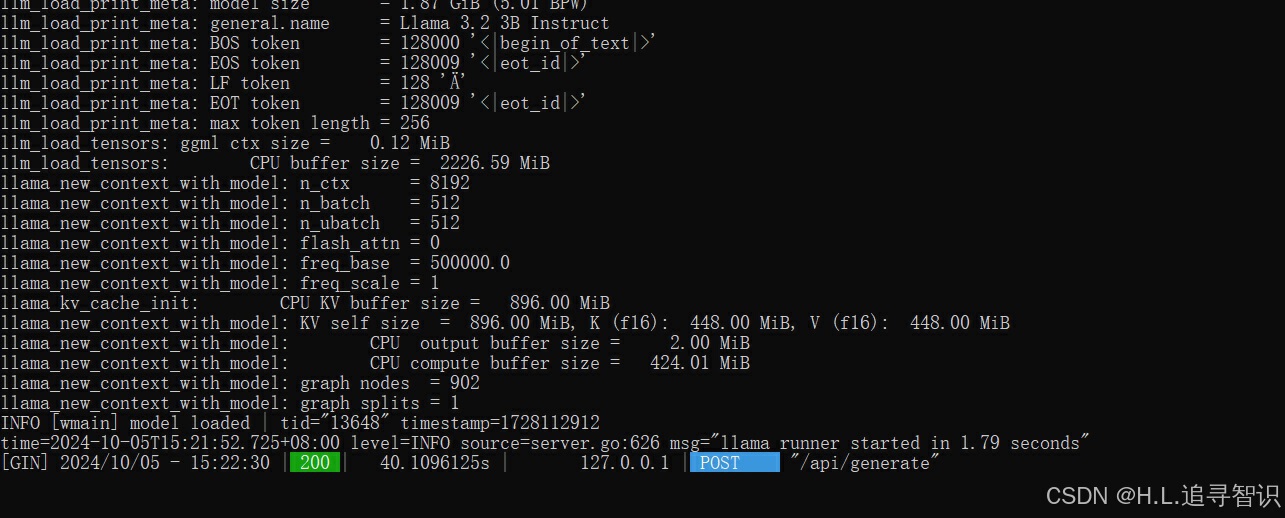
发现报错没有了,在serve的模式下,会显示调用过程的细节信息。比如图中post请求处理。
2. Langchain 调用ollama中的模型
这里以jupyter-lab 工具做一个简单API示例,需要先安装langchain_ollama。
langchain官网有各种大语言模型接口介绍,openAI, ollama等。其中有接口以及Langchain使用的讲解和示例,非常详细。更加负责的逻辑可以使用langgraph来定制AI agent. 网站(https://python.langchain.com/).
国内的模型可以套壳OpenAI, 例如智普,详见官网(智谱AI开放平台),这里把api_key换为本地模型的key, 模型地址换为本地接口地址即可。
from openai import OpenAI
client = OpenAI(
api_key="your api key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
) 对于电脑本地的langchain调用,ollama提供的模型服务地址为上文提到的默认地址(127.0.0.1:11434),无需密码,可以类似的配置模型如下:
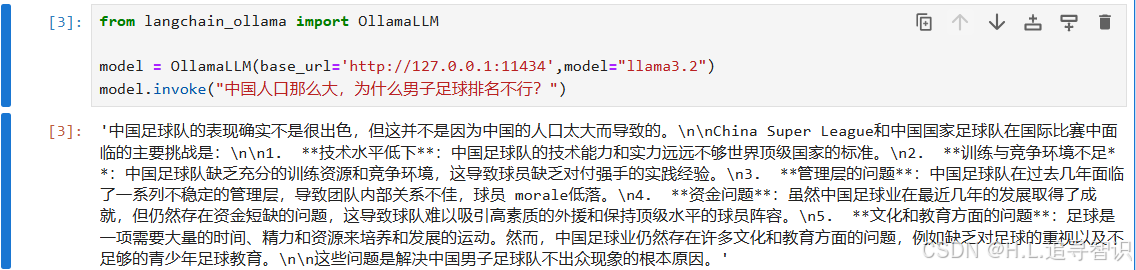
from langchain_ollama import OllamaLLM
model = OllamaLLM(base_url='http://127.0.0.1:11434',model="llama3.2")
model.invoke("中国人口那么大,为什么男子足球排名不行?")这里调用OllamaLLM类创建一个model实例,需要导入模型地址和模型名称。
invoke是langchain提供的runnable的一种调用方法,输入相关文字,大模型会对此文字回复。
API反应时间,相对与之前的命令行模式更长。成功完成API接口调用,本地试点任务完成。基于langchain的大模型应用,后期再做案例介绍。

















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









