






之前有试过边读论文边整理,后来发现逐个chapter翻译理解的效果不是很好。一方面和我自己的理论基础不够扎实有关,虽然不是在校研究生的身份,但是学什么事情都要重视基础重视理论呀;另一方面,如何概括一篇文章这种抽象的工作也是我不擅长的,所以才要硬着头皮来做来学习呀~
这是比较新的一篇文章,地址是https://arxiv.org/abs/1812.05914,标题是端对端的驾驶视频分割: 自动驾驶的车道检测。我自己的初衷是因为工作中的项目也是与车道线息息相关,如文章中绪论所讲,基本上自动驾驶需要进行的大多数判断,都是基于车道线的位置来考虑的,无论是偏移预警或者是转弯、超车,准确地获取车道线总是第一步。传统的方法例如聚类方法和边缘检测很难应对各种复杂的路况信息,所以就考虑使用Deeplearning的方法来寻找车道线。
作者提出了用 graph convolution network 中 spectrum domain 即空间域的思路来处理一张图片,我的理解就是把一张图片看成一个整体,也就是他所说的 global convolution network(也叫GCN),这样做的优点在于可以全局的理解一张图片中的内容,而不是传统CNN权值共享的卷积核那样子去历遍,确实是个不错的思路。另外老生常谈的在将图片给如网络之前进行了简单的预处理,先是用标定的方法找了内参矩阵和畸变系数,做了畸变矫正,以及颜色转换和梯度计算(梯度计算这个我比较困惑,后面看看作者有没有什么解释),还用了比较特别的梯度下降方案,这些后面再详细介绍。
网络结构
首先介绍模型的网络结构中的单元,按照文章的内容,主要有两种单元 GCN(global convolution network,后面凡是提到GCN都是指代这个,如果是图神经网络则会用英文全称加以区别) 和 BR(boundary refinement),前者主要是classification后者主要是localization。
这篇文章中的GCN是里用途的连接性结构(utilizes connectivity structure of graph)来作为邻域混合(neighborhood mixing)的过滤器,其结构可以由如下的式子表示
这个式子是图卷积神经网络graph convoluntion network中的空间域的一个表达式,具体关于图神经网络推荐看这个链接。上式中的是normalized graph adjacency matrix归一化图邻接矩阵,描述图中节点的邻接情况的;
是第l层的节点列向量逐行排列形成的矩阵,即输入;
是参数矩阵,也就是学习的主要内容,
表示非线性化。
但是实际上我们的输入也就是一张图片,而不是一个图结构,那么如何应用公式(1)呢?我对于图神经网络的理解,不同的,就类似于隐藏层,从最开始的输入即每个节点的特征值,逐层计算,考虑与附近其他节点的相互影响,最后得到一个新的特征向量。这种逐层考虑与附近节点的思想,也就是之所以还是卷积神经网络的原因。那么如果是一张图片,同样的也是用这种思路来做,但由于图片的特性终究不如图(graph)那么特别,所以还是回到了以前的方法。作者用这个graph convolution network似乎有种擦边球的意思哈哈跑题了。
每一个具体的 GCN block 如下图所示,可以看到作者为了提高模型训练的速度,使用了一个空间可分离卷积的操作,原本从输入是 w*h*c 的图片到 w*h*21,如果使用单个卷积核来实现卷积操作,卷积核的尺寸为k*k*c*21;但是如果拆分成两步,只需要使用一个 k*1*c*21 和一个 1*k*21*21,也可以达到一样的效果,可以大幅度地减少需要训练的参数数量。另外,通常为了达到 global 的目的,就要倾向于使用更大的卷积核,但是显然更大的卷积核就会带来更多的参数,这种分离的方法可以使得我们可以不担心参数数量爆炸,可以增大 k 的数值。然后如下图中,分成两条路径,改变一下顺序,然后再把结果相加(向量加法),这就实现了一个单元。从这个block的结构看下来,实际上就是保持输出和输入除了深度以外其他尺寸一致,这应该就是global的意思。补充一下,这个作者的配图中,如果是浅蓝色的convolution,没有特别强调的话就是没有使用激活函数的。

另外一种单元是 BR,结构很简单就是一个残差连接。目的也如它的名字,就是为了更好地修正分割时的边界。作者说为什么要引入这个 BR 的原因就是再做上采样时容易引入一些噪声使得边界不够准确,所以引入这个 block 来提高准确度。其中要注意到,这整个block输入和输出的形状是一样的,而 shortcut 中显示 3x3x21x21 是什么意思呢?因为要维持形状一致,所以卷积核是 3x3x21,深度一共是21.。

接下来就看一下网络的整体结构。可以看到,整个网络结构中除了刚才提到的 GCN 和 BR 两种 block 之外,还有 Down Sampler 降采样的单元,根据文献中的说法就是由卷积层和最大池化层组成的 block,而 Up Sampler 上采样单元还没看到组成的介绍,可能是由转置卷积或者是反池化层组成的。图中的我理解应该是矩阵加法,因为两个输入的形状和输出的形状都相同。

总的来说作者提出如此的网络结构,目的就是为了把 classification 和 localization 二者都给兼顾好,所以可以看到有连续的降采样提取特征,然后例如残差连接更好的传递信息、提高收敛速度等,都是为了完成好两个任务。
定义好了encoder-decoder网络结构,就还有两个任务:loss function 损失函数和 optimizer 优化器。
损失函数
作者的说法是:
In convolution neural network training, network weights are adjusted by loss function evaluation. As images vary from class to class, influence of each class to the loss is different. In each iteration, we calculate the weights based on current input batch.Weights are different in each iteration.
也就是说,对于不同的类别对于损失函数的贡献,应该是不同的。作者给出的权重函数如下:
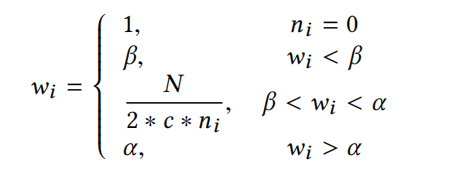
他的思想很简单,例如一张图片中,车道线的像素点肯定是少于车道或者是其他物体的,抽象点说就是这种类别的实例比较少。为了提高在样本总量中占比较少的样本的影响力,所以就赋给它较大的权重。而总数较多的,也就获得较低的权重。此外还有两个阈值上下限分别是 α 和 β,其含义在公式中很明显。
那么损失函数的形式如下,参数 w 应该是对应着 label 的。
优化器
文章中使用的是 Adam。然后一些小细节就是画ROI,然后数据增强,老生常谈。
结论
作者实现的环境是用显存接近12G 的 Tesla P100-PCIE,在 Linux 环境下,python3.5,tensorflow-gpu 1.10,keras-gpu 2.2.2。一些更详细的设置参数可以看论文的相应章节。
关于超参数的选择,作者是准备了一些组合,然后各迭代40次,选择其中表现最令人满意的组合。
不过作者说,在迭代了40次之后之后验证validation的损失不降反升,说明开始过拟合了,于是就终止了训练(?)。


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









