






系统化的学习大模型,除了知道大模型是什么,也得知道大模型是如何训练的,对大模型的实际应用有更加定量的认知,该文章也算是一篇分布式训练的学习过程总结,作为循序渐进学习分布式训练的总结。
类似之前写过的LLM文章,本文也建议读者先定性有个宏观认知,然后再细化到某个概念定量了解,遇到不太清楚的概念深度递归去学习。

为什么需要分布式训练?
主要有两点:
- 对小模型而言训练速度更快
- 对大模型而言,其所需内存太大,单机装不下
分布式训练的加速
这个就很直观了,对于一些单卡可以装载的模型我们可以通过多个卡数据并行的方法训练,然后把一轮数据算出来的梯度求和更新参数进行下一轮的梯度下降
这个范式比较经典的例子就是Parameter Server,后续的章节会定量的介绍
大模型的内存开销
我们来定量的算一算大模型需要的内存空间
比如一个 1.5𝐵 参数的GPT-2模型,我们用 Ψ 代表这个参数量的数量,那么在FP16的精度(单个参数大小 16𝑏 ,或者 2𝐵 )下模型本身达到了 2Ψ𝐵
如果是推理,那么模型的加载确实只需要这些参数,推理过程中再算上输入embedding占用的额外参数便是需要的所有内存
但如果是训练,那么就麻烦了,我们用DeepSpeed论文中Adam Optimizer+混合精度训练(如果不知道Adam和混合精度是什么建议自行了解下)作为例子。模型在训练过程中需要储存自身的参数和梯度(注意这里还不是Adam最后算出来的参数更新量,只是根据loss反向传播得到的原始梯度),这便需要 2Ψ+2Ψ 的内存,同时混合精度fp32训练时,Adam需要一份fp32大小的模型拷贝,momentum和variance去储存模型的优化器状态,这需要 4Ψ+4Ψ+4Ψ ,最终我们需要 16Ψ𝐵 的内存用于训练,即对于一个3GB的GPT-2模型,我们训练时需要24GB的内存,对比一张V100的显存为32GB
不难看出,一个GPT-2模型的训练就能吃光V100的显存了,对于175B的GPT-3的训练,哪怕是目前的H100(显存188GB)也无法单卡装载。因此对于这类大模型只能通过张量并行等方式训练,比如后面会介绍的Megatron和DeepSpeed。
我会怎么展开接下来的内容
我会先介绍一下分布式的一些必要前置知识,然后我会根据分布式训练随着大模型需求的演进路线展开后续的内容:
- Data Parallelism:模型一台设备装得下,所以同一个模型同时用多份数据分开来训练
- Pipeline Parallelism:模型装不下了,模型的一层或多层一台设备装得下,所以同一个模型按层拆分开训练
- Tensor Parallelism:模型的一层都装不下了,所以同一个模型层内拆分开训练
- DeepSpeed:可以算作目前大参数大模型分布式训练的终极方法,因此单独提出来了
分布式的一些必要前置
Map Reduce
这个是分布式架构的鼻祖级神文,我推荐每个想要了解分布式的人都定性的读一遍这个文章,MapReduce架构可以说是分布式架构的鼻祖,别说分布式训练了,哪怕大数据和k8s等分布式架构上都有它的影子,强烈推荐阅读原文
论文和随便找了篇中文定性的介绍(如果英文阅读很吃力的话可以看这个)
本节需要了解:
- 定性掌握Map Reduce原理
通信原语
通信原语就是分布式训练用到的数据交换方式的原子操作
定义和Pytorch代码实现可以直接看这个,还有其他一些NCCL的操作可以看这个,每个通信原语其实只是定义了一个数据的分发or合并方式,其CPU和GPU上的实现需要深入到MPI和NCCL,这个就不做展开了。定性了解每个通信原语是干什么,如何在Pytorch里使用这些原语即可
后面的很多内容也会用到这些通信原语的定义,所以这个也需要好好定性的去了解
本节需要了解:
- 定性了解各个通信原语的定义
- 最好能用Pytorch上手使用一下这几个通信原语
训练流程
先定量了解下模型训练时的大概流程
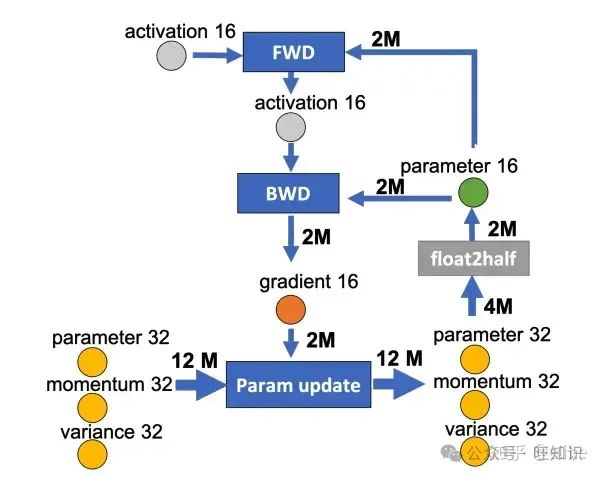
fwd and bwd
还是以混合精度的的Adam为图例,假设数据为fp16和fp32:
- 正向传播时(FWD),上一层fp16的激活值和fp16的参数参与了计算,得到这一层的fp16激活值
- 反向传播时(BWD),本层的激活值和参数参与计算,得到fp16的梯度
- 参数更新时,fp16的梯度以及fp32的参数副本,momentum和variance参与计算,最终算出更新后的fp32参数、momentum和variance,然后将fp32的参数转化为fp16进行本层的参数更新
本节需要了解:
- 混合精度下Adam优化器的参数更新流程
- 定量了解混合精度下Adam优化器在各个流程的数据消耗
Re-materialization
论文和解读,建议直接看代码
其实re-materialization这个叫法是在后文的GPipe论文内提到的,这里直接拿来用了。提到该技术的论文其实比较早了,文章提出了几种节省训练时内存的方法,但我们只需要了解gradient checkpoint是啥和这玩意是如何让梯度的内存实现平方根级别内存优化的即可
本节需要了解:
- 定性了解gradient checkpoint是如何实现的
- 最好能定量推导gradient checkoutpoint为什么能把训练内存节省到平方根级别
数据并行(Data Parallelism)
数据并行是比较早期的模型训练方法,在CPU训练或单张GPU能装载下模型的场景下,我们可以用数据并行的思路加速模型的收敛,这是一种很直观的分布式模型加速方案
其实数据并行主要就是Ring All Reduce(无master节点)和Parameter Server(有master节点),其他的方案(如Spark MLlib)原理上都大同小异,因此本章只介绍这俩
Ring All-reduce
原理建议直接看这个文章,代码可以参考这个,其实Ring All-reduce在Pytorch里的实现就是DistributedDataParallel,Ring All-reduce本身流程也是reduce-scatter+all-gather的组合
Ring All-reduce其实是数据并行训练中一轮迭代完成后的参数同步流程,比如下图的例子,模型有 Ψ 参数量,并且被四台机器分为了四块,每台机器的出入带宽都为 𝛽 :
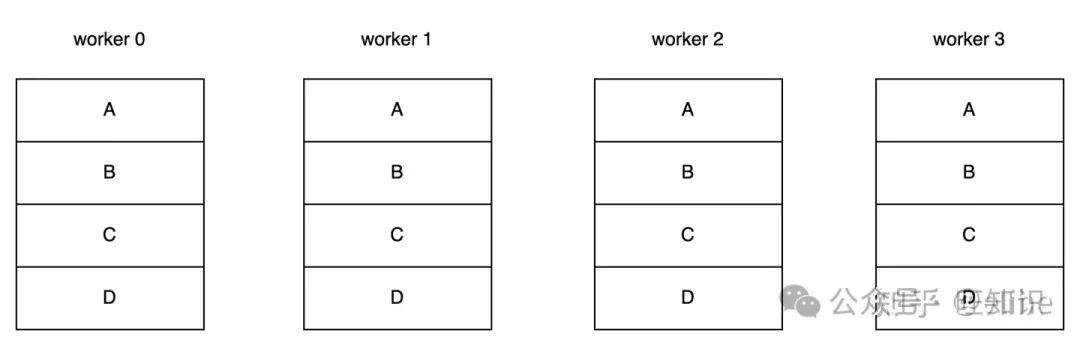
all reduce machines
如果要实现一次All Reduce,最直观的就是把0、1、2节点的参数同步到3,等待3计算完成后再把参数反向同步回0、1、2,该方法的时间约为 6Ψ𝛽 。
但如果是Ring All-reduce,时间可以为 2(𝑁−1)Ψ𝑁𝛽 ,时延有明显的削减
不过,不管哪种其实单台机器的出入数据量是差不多的(少了大概 Ψ𝑁 ),只是通过环状算法将出入带宽利用率拉到最大实现加速
本节需要了解:
- Ring All-reduce的原理
- 定量的计算Ring All-reduce的传输时延
- 尝试用Pytorch写一个Ring All-reduce的代码
Parameter Server
论文,随便找了篇中文解读
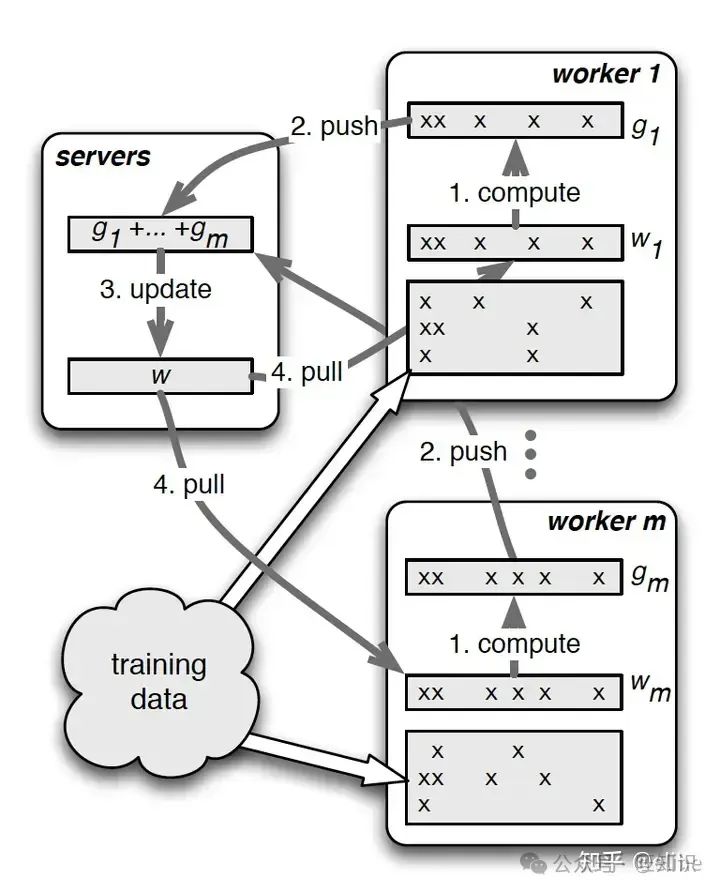
parameter server
简单来说PS设计了一套分布式训练框架,将训练拆分为一个master节点和多个worker节点,其中worker节点每轮迭代执行:从master pull参数 -> 加载训练数据 -> 计算梯度训练 -> push梯度到master -> 等待master完成一次全worker同步
但是这种简单的"同步阻断"训练会导致同步时间占比较大,反而降低了计算效率,因此基于上面的流程又有了"异步非阻断式"训练过程,即每个worker用本地模型参数完成了多次梯度的计算后再重新pull模型参数,虽然直观上感觉这样会造成梯度下降变慢,但是经过论文的测试发现梯度下降速度没想象的影响那么大,具体的测试数据在论文中都有提到
同时如果模型数据过多,master节点就会有单点依赖,所以PS架构支持用哈希环的方法拆分master节点,使每个master节点只负责一部分模型参数的储存,降低单点网络问题带来的影响
本节需要了解:
- 定性知道PS架构的原理
- PS的同步阻断和异步非阻断式训练的流程区别,他们在计算和同步等待上的耗时占比分别是多少?
- master节点是如何解决网络单点问题的?
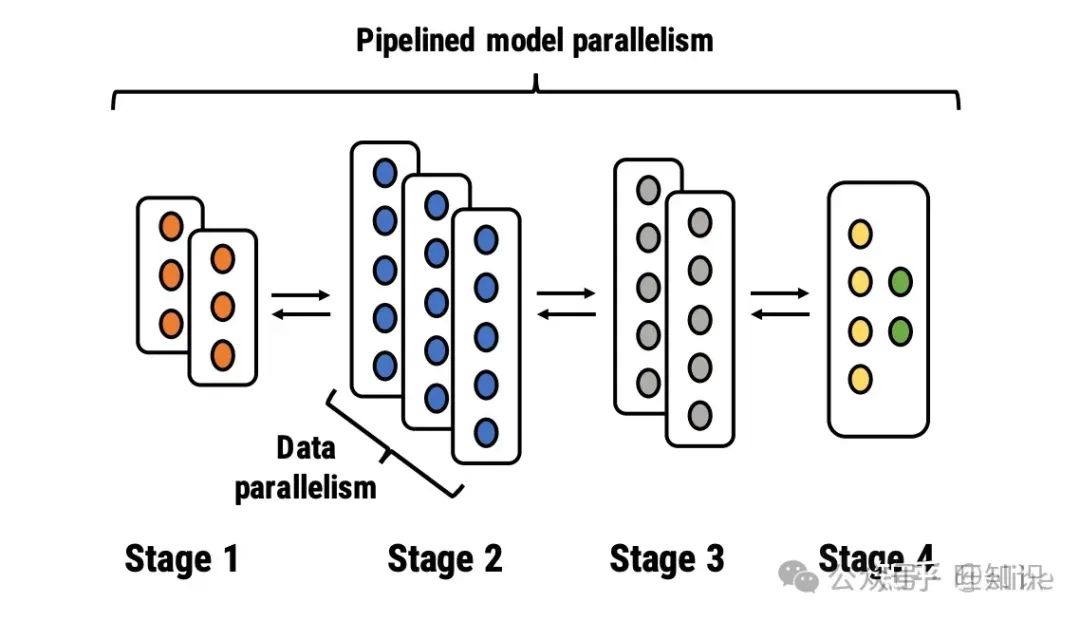
管线并行(Pipeline Parallelism)
随着模型越来越大,一张卡变得装不下模型。为了训练单卡无法装载的模型,我们可以将模型按层切分到多个机器上,管线并行就是干这么个事
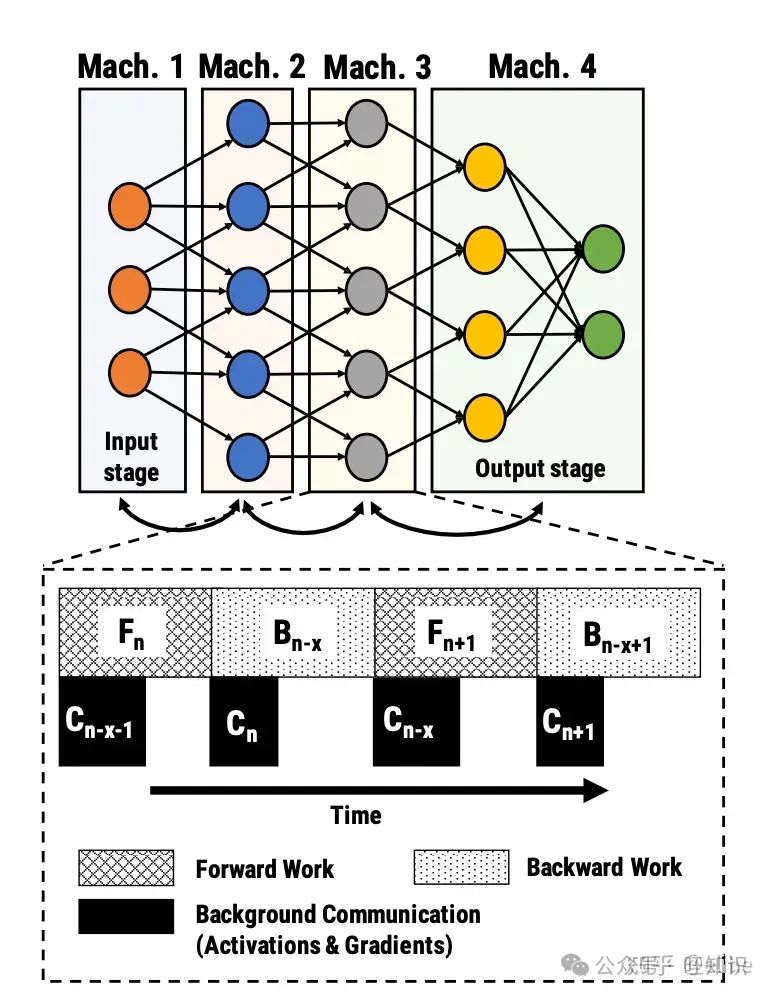
这是最初级的模型拆分多卡的方案,该方案将模型根据层拆分到不同机器上,但该方法的训练效率也是大打折扣的,,每一张卡在大部分时间下都是空闲的。因此我们可以认为,管线并行主要是为了解决下图的问题:
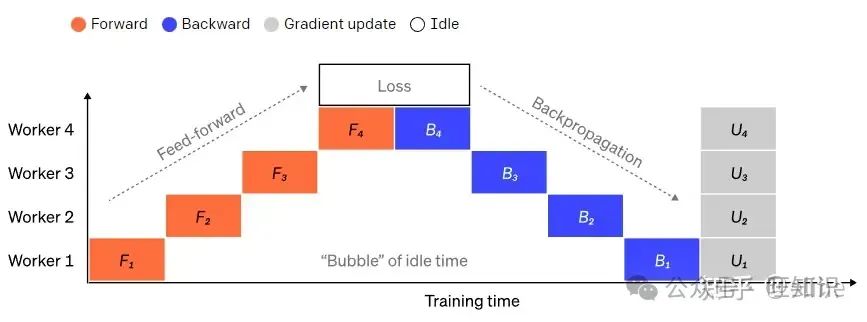
pipeline
本章会选择PipeDream和GPipe两个最知名的Pipeline并行方式进行展开
PipeDream
论文和中文解读
PipeDream也是将模型根据层拆分到多个机器上,训练时,允许机器在反向传播第一个批次数据的梯度前执行第二个甚至更多后续批次的数据计算,从而实现了pipeline并行。这个方法虽然会造成梯度收敛不稳定,但我们可以通过限制反向传播前最多执行多少批次来控制梯度的不确定性
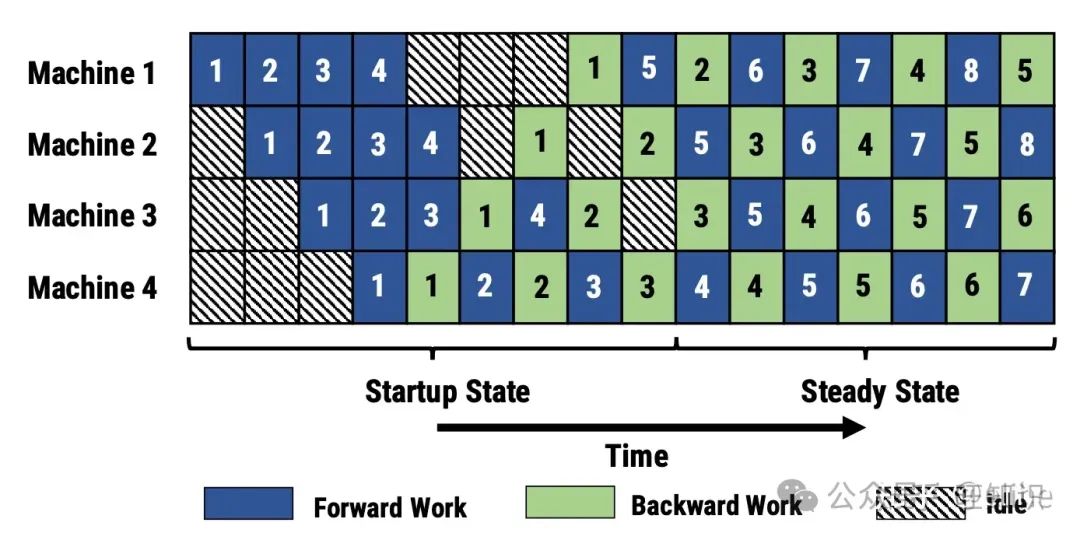
同时,PipeDream还将Data Parallelism结合了起来,模型的每一层都可以用数据并行的方式训练
同时,梯度下降的时候,机器需要用保存好的参数备份来计算梯度(即不会用当前最新的参数来计算梯度):假如我们始终用最新的参数来计算梯度,那么对于图中的机器1,3号任务计算梯度时其实使用的是2号任务梯度更新之后的参数,而实际上3号任务正向传播时用到的是原始参数,因此这会带来大量误差
通过保存参数备份,我们可以实现近似于Data Parallelism的效果,但当然这也会倍率放大模型的内存占用,具体倍率和备份的参数量有关
本节需要了解:
- PipeDream是如何提升机器利用率从而加速训练的?
- PipeDream为什么会放大模型的内存占用?
GPipe
论文和中文解读
GPipe其实和PipeDream类似,将模型拆分到不同的设备上,通过管线并行的方式,多批次数据为一组更新模型参数。
GPipe是通过将一个batch的数据拆分为micro-batch实现,并且每一个batch完成后会等待全局同步梯度;同时,GPipe用到了前文提到的Re-materialization技术,用时间换来了显存的降低。因此总体而言GPipe速度比PipeDream慢,但是显存方面占用更少,且收敛更稳定
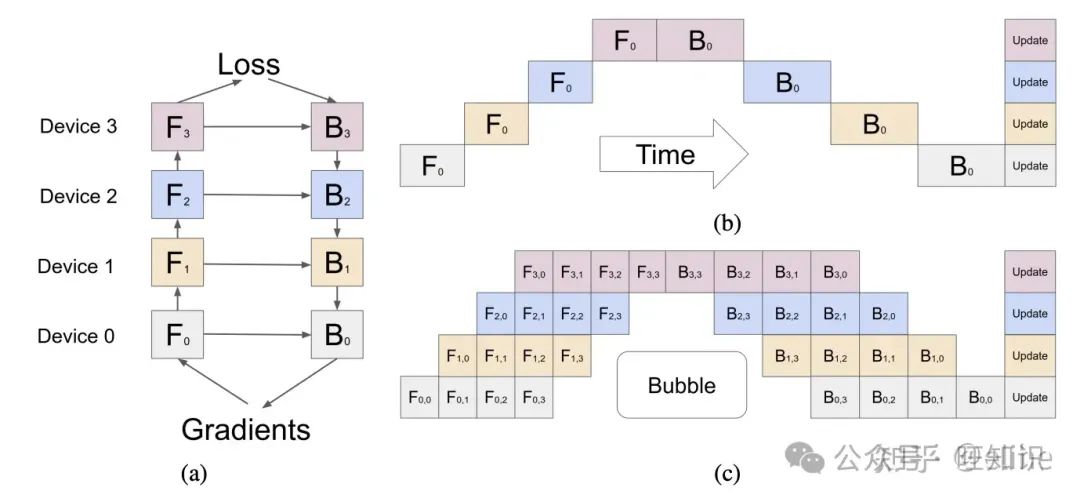
本节需要了解:
- GPipe和PipeDream的区别是什么?
张量并行(Tensor Parallelism)
管线并行其实主要还集中在多层神经网络架构的训练上,但是对于Transformer架构的模型(如BERT,GPT等),MultiHead Attention Layer和MLP的计算量翻了几倍,如果继续按管线切分模型的话可能单层参数都无法被显存装载,因此我们也需要横着把同一层的模型切分开来,这便是张量并行
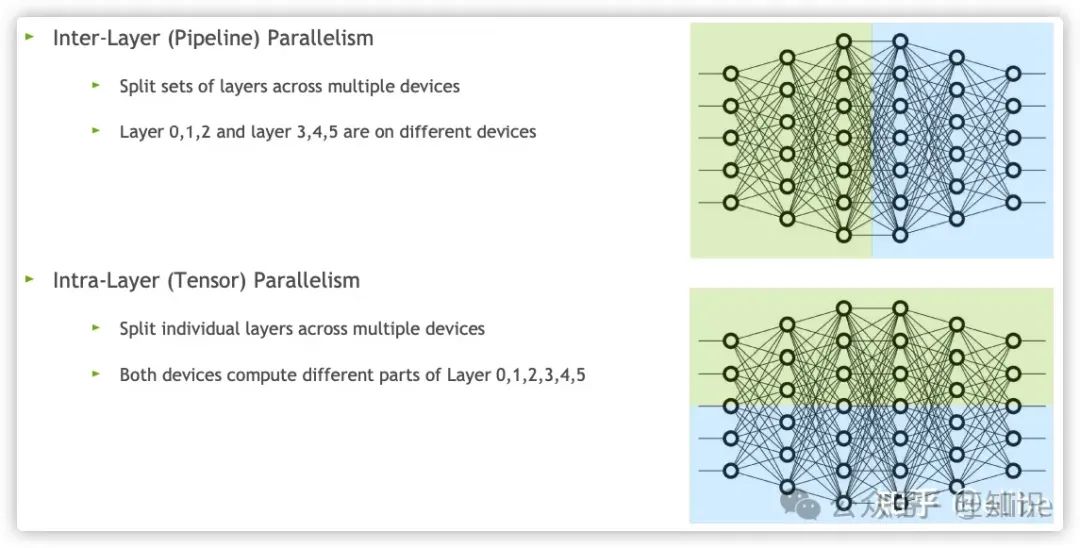
其中最有名的也就是Megatron和Deepspeed了,本章也会详细介绍这两个方法的原理
Megatron
论文,中文解读可以看目前个人认为全网最详细的系列,官方代码在这里
其实Megatron的原理就下面的公式:
-
横切map:
-
- 𝑓𝑜𝑟𝑤𝑎𝑟𝑑:[𝑋1,𝑋2]=𝑋,split操作
- 𝑏𝑎𝑐𝑘𝑤𝑎𝑟𝑑:∂𝐿∂𝑋=[∂𝐿∂𝑋1,∂𝐿∂𝑋2] ,all-gather操作
-
横切reduce:
-
- 𝑓𝑜𝑟𝑤𝑎𝑟𝑑:𝑌=𝑌1+𝑌2 ,all-reduce操作
- 𝑏𝑎𝑐𝑘𝑤𝑎𝑟𝑑:∂𝐿∂𝑌𝑖=∂𝐿∂𝑌 ,identity操作
-
纵切map:
-
- 𝑓𝑜𝑟𝑤𝑎𝑟𝑑:𝑋 ,identity操作
- 𝑏𝑎𝑐𝑘𝑤𝑎𝑟𝑑:∂𝐿∂𝑋=∂𝐿∂𝑋1+∂𝐿∂𝑋2,all-reduce操作
-
纵切reduce:
-
- 𝑓𝑜𝑟𝑤𝑎𝑟𝑑:𝑌=[𝑌1,𝑌2] ,all-gather操作
- 𝑏𝑎𝑐𝑘𝑤𝑎𝑟𝑑:[∂𝐿∂𝑌1,∂𝐿∂𝑌2]=∂𝐿∂𝑌,split操作
不过要注意下,实际的横切和纵切是分为map和reduce两步操作的,所以前向和后向的传播对于横切和纵切也有两步。根据这些,我们可以将Transformer的MLP和Multi Head Attention通过上面两种矩阵切分形式组合为下面的计算流程:
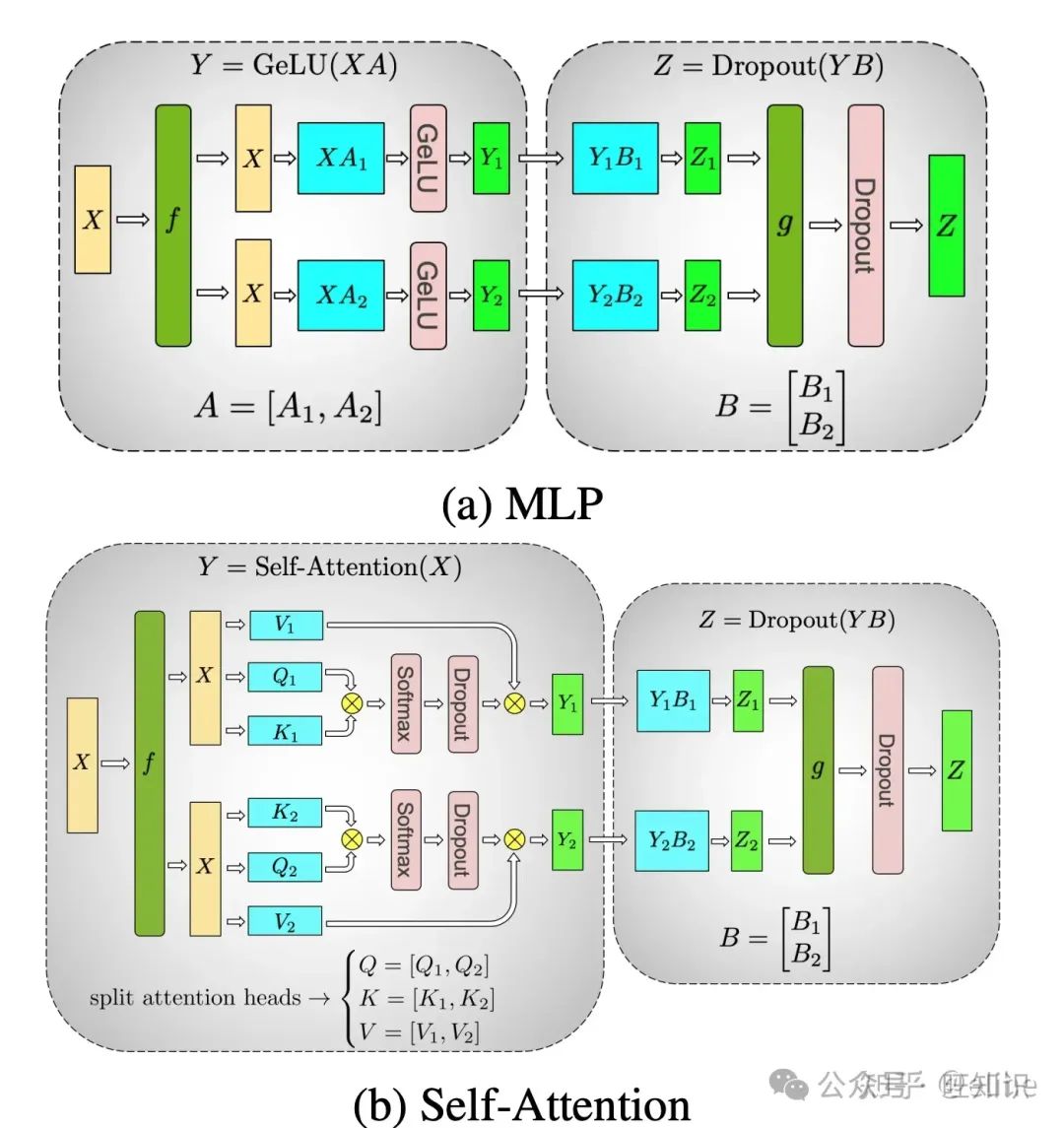
其中Multi Head Attention甚至不需要切分 𝑄,𝐾,𝑉 三个矩阵,因为Transformer本身设计就是多个,每个head都可以放到一个GPU上计算
Megatron多用于训练BERT、GPT和T5等几十B的大参数模型,算大模型分布式训练的一个早期张量并行方法,后来随着大模型进一步变大到了几百B,DeepSpeed的ZeRO逐渐变为了主流
本节需要了解:
- Megatron是如何做到把矩阵相乘拆分到不同GPU上计算的?
- 横切和纵切的正向传播和反向传播的公式?
- MLP计算时是如何结合应用纵切和横切的?
- Multi Head Attention计算时是如何结合应用纵切和横切的?
DeepSpeed
PS:这里我把DeepSpeed单独提了出来,因为融合了数据并行、管线并行和内存节省等方法,因此可以看做上面很多方法的整合
随着GPT-3把LLM的参数量推到了175B,训练所需参数大小更是到达了万亿规模,Megatron面对如此大规模的参数也变得无能为力,而DeepSpeed的ZeRO方法问世则很好的解决了这个问题
ZeRO-DP
论文和中文解读
ZeRO-DP简单来说就是想办法在数据并行的管线上把模型的参数分配到不同的显卡上,而不用所有显卡都装载所有参数
该论文把训练期间的内存消耗归结为三类:
- OS:优化器状态(如Adam的momentum和variance)
- G:梯度
- P:模型参数
如前文”大模型内存开销“小节有提到,混合精度下的Adam三种消耗占比大约为 12Ψ , 2Ψ 和 2Ψ 。同样的,ZeRO-DP根据显存优化粒度也分为 𝑃𝑜𝑠 , 𝑃𝑔 , 𝑃𝑝 三种
接下来我们介绍三种优化方案,其中 𝑁 是机器数量, Ψ 是模型参数量, 𝜃𝑜𝑠 、 𝜃𝑔 、 𝜃𝑝 分别代表优化器状态、梯度和模型参数, 𝛽 为单台机器的出入带宽
𝑃𝑜𝑠
𝑃𝑜𝑠 会让每台设备上都有完整的 𝜃𝑔 和 𝜃𝑝 ,但是只保留 1𝑁 的 𝜃𝑜𝑠 ,训练时也只更新这部分状态对应的参数,每轮训练完成后进行reduce-scatter将所有机器上所有参数的梯度合并到负责的机器上去,然后再用all-gather将每台机器计算出的参数分发给全局,因此参数同步时间为 2(𝑁−1)Ψ𝑁𝛽
其具体流程和数据并行类似,因此这里就不画图了
𝑃𝑔
该方法的假设在于每台设备只能训练部分参数,所以单台设备上其他参数的梯度其实不需要保存。
每台设备有完整的 𝜃𝑝 ,但是只保留 1𝑁 的 𝜃𝑜𝑠 、 𝜃𝑔 。反向传播时每经过一层参数就开启一轮reduce-scatter将梯度整合到一个节点,计算出下一层梯度后删除前一层梯度。参数同步时间为 2(𝑁−1)Ψ𝑁𝛽 ,和数据并行一致
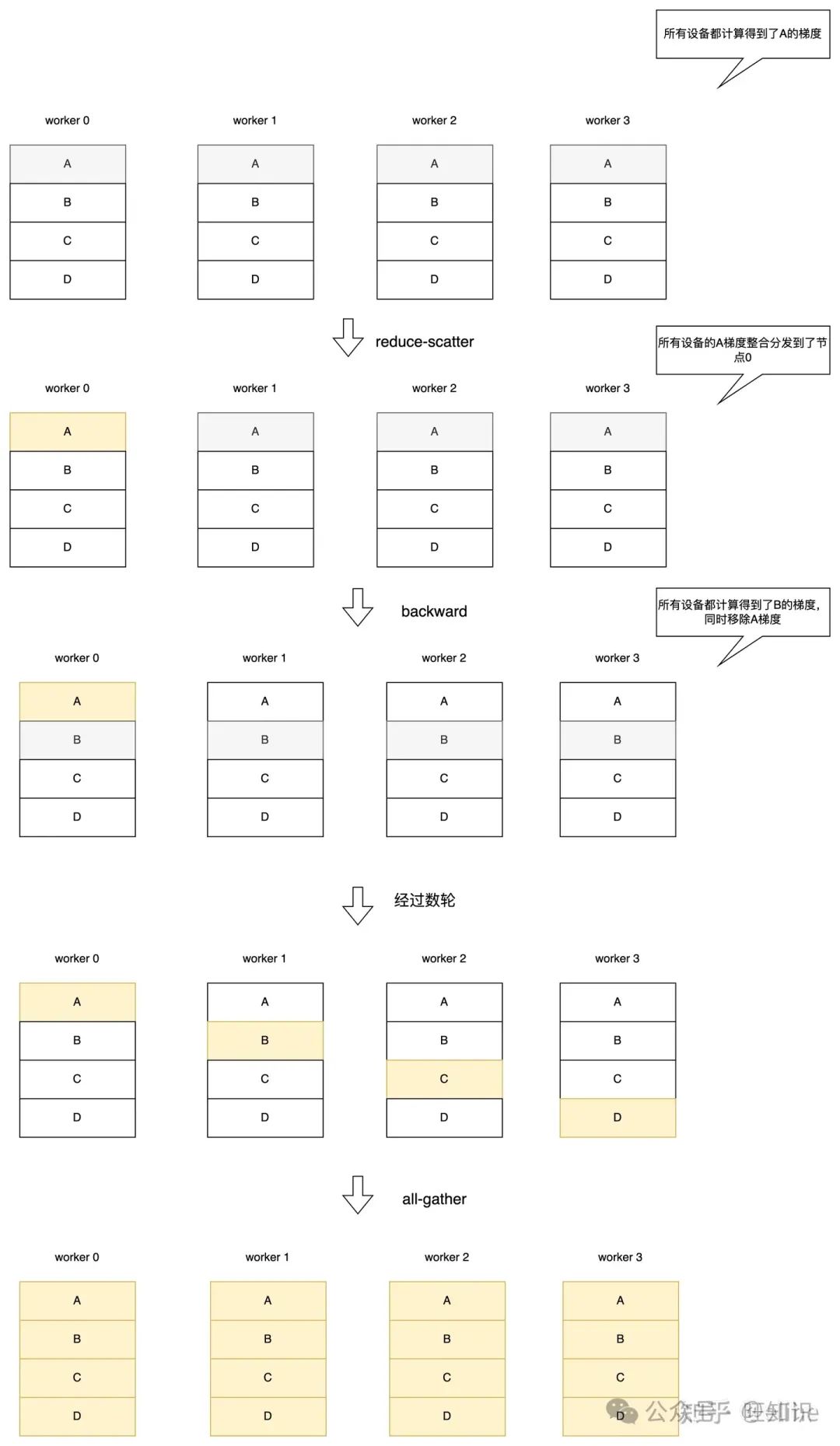
𝑃𝑝
简单来说就是在 𝑃𝑔 的基础上每一轮加上一次broadcast,把模型参数分发到各个设备上,因此时延相较前两个有显著提升,具体就不画图了,参数同步时间为因为 3(𝑁−1)Ψ𝑁𝛽 ,约为正常数据并行的1.5倍
上述三个级别的内存优化效率如下图所示:
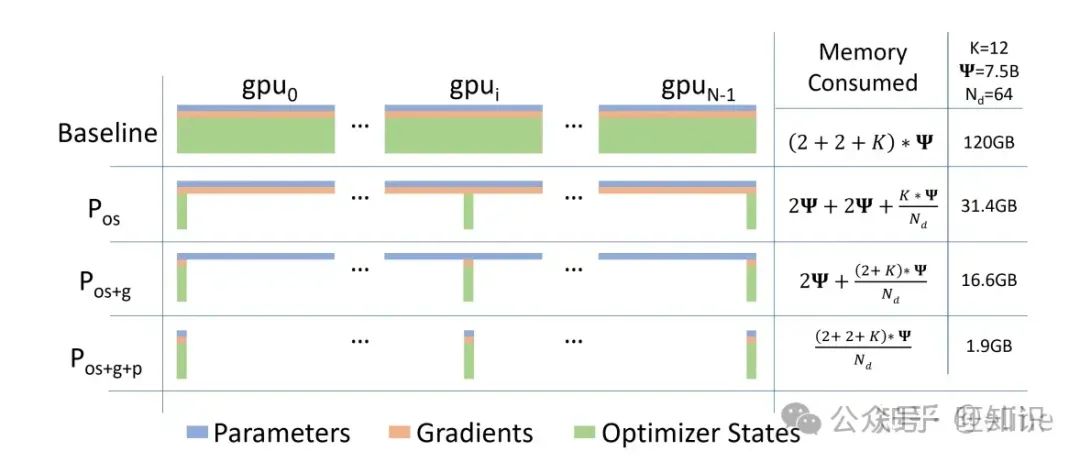
该方法能有效地降低单卡的内存,可以看到120GB的单卡所需训练内存最大可以压缩到1.9GB
本节需要了解:
- ZeRO-DP的三种方法分别是什么?是通过什么原理实现的内存节约?
- ZeRO-DP的三种方法的通讯时间分别为多少?
ZeRO-R
ZeRO-R和ZeRO-DP在同一个论文里出现(中文解读也是同一篇),我理解是一些单节点显存节约方法
𝑃𝑎
该方法使用类似Re-materilization的方法,在正向传播时设置激活值的存档,反向传播时用存档重新计算激活值,不过该方法更进一步地把激活值拆分到了不同机器上,每次计算时先进行一轮all-gather操作合并激活值,甚至论文中还提到可以把激活值存档放到CPU上去,用额外的通信成本降低激活值的显存开销
𝐶𝐵
这个就偏向显存管理了,对于矩阵计算申请的临时显存而言,由于显存管理策略申请的显存可能远大于实际使用到的显存(例如伙伴算法会申请2幂次方显存大小),该方法便是解决这种显存浪费导致的模型无法装载问题,它设置了一个静态的缓冲区大小,使更多的显存可以拿来装载模型,当然这也会带来一定的显存分配延迟(比如静态的缓冲区满了要等待释放)
𝑀𝐷
该方法也偏向显存管理,其目的就是降低显存的碎片,简单来说就是预先分配好激活值和梯度的显存块,并及时化显存整理,降低显存碎片的问题来使大块的张量可以得到分配,当然,这也会带来时间成本(毕竟显存整理也需要时间)
本节需要了解:
- 定性了解ZeRO-R三个方法的原理
ZeRO-Offload
论文和中文解读
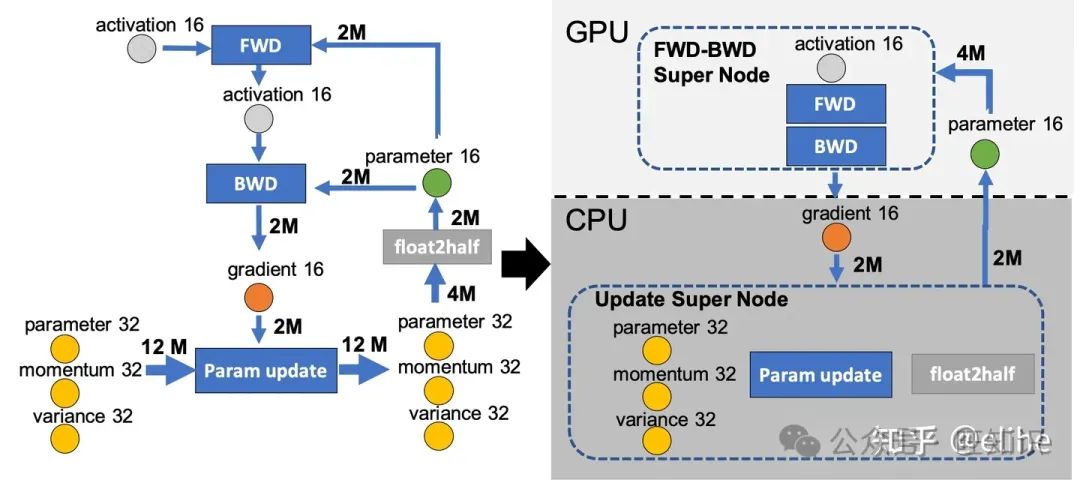
ZeRO-Offload的核心思路就是让CPU和内存也参与到训练中去,回顾一下前文用到的训练流程的图,ZeRO-Offload就是把这个流程用上图的方式把fp32参数的更新和float2half操作拆分到了CPU和内存上计算,而前向和后向传播依然由GPU负责
那么,在单卡场景下,流程大概如下图所示:
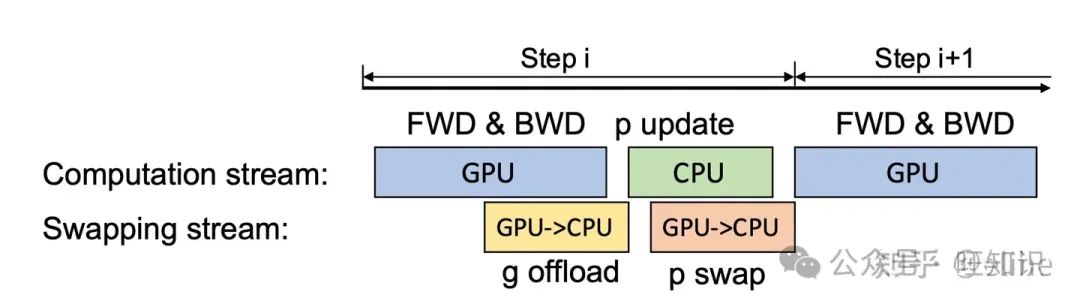
GPU在计算时异步的把已经计算好的参数传递给CPU,同样的,CPU也会异步的传递计算好的参数给GPU。多卡场景其实也一样,每张卡把自己负责的参数传递给CPU计算即可,甚至由于每个CPU负责的数据变少了,CPU的时延也大大的降低了
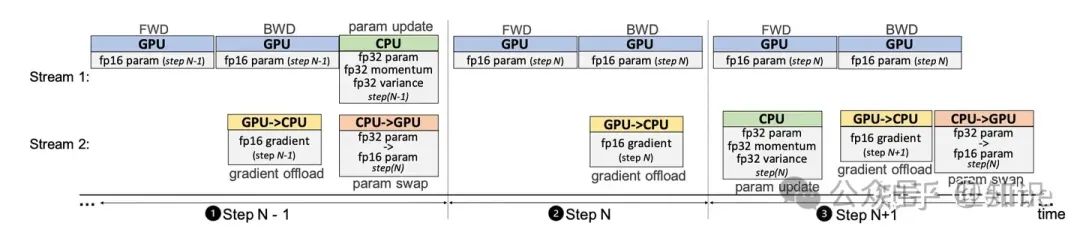
同时,文章进一步提出了One-Step Delayed,在模型后期得到了充分的收敛后,CPU的参数计算和更新可以放到下一轮迭代期间完成。当然,这会带来振荡的收敛,但是同时也大幅度的稀释了CPU计算的时间,论文中有证明在模型训练的后期开启该方案是可行的,虽然会带来一定的振荡,但总体不会对训练的收敛效果产生影响
本节需要了解:
- 定性地知道单卡和多卡场景下ZeRO-Offload如何将训练流程拆分到CPU的
- 定量的了解ZeRO-Offload降低显存消耗的比例
- 定性地了解One-Step Delayed机制和它带来的影响
ZeRO-Infinity
论文和中文解读,代码就是DeepSpeed开源项目
ZeRO-Infinity结合了ZeRO系列的论文,直接把分布式训练的方案推到一个目前来说接近终点的位置,改论文探讨的模型大小甚至直接到达了Trillion参数量级别(1 Trillion=1000 Billion),因此有很多之前不用考虑的场景在这里都涉及到了。强烈推荐自行阅读论文或者解读,下面本文简单介绍下该论文的思路
显存评估
作者先对显存进行了评估。对于超大的模型,它们的参数量如下图所示(注意模型参数量的单位为Trillions):
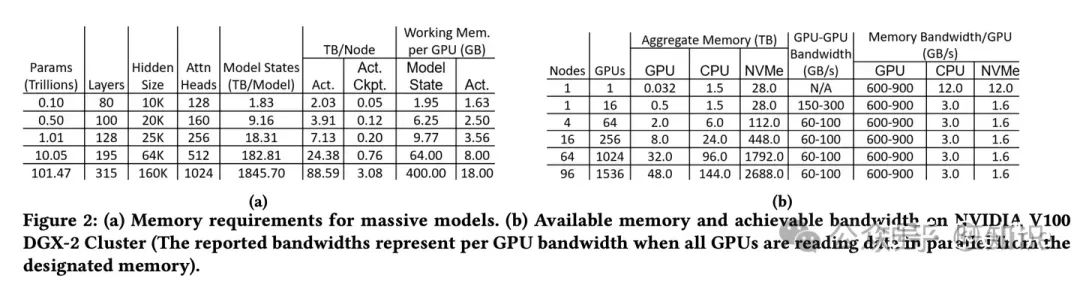
这种规模的模型很明显是没办法交给GPU去装载的,自然而然会用到CPU和NVME,其中(a)图内的Working Mem per GPU就是把所有的模型状态offload到CPU或者NVME后GPU所需要的工作显存,其中Model State就是计算FWD和BWD所需显存,Act.是激活层重新计算(就是激活层ckpt,或者本文提到的re-materilization)所需要的显存
带宽评估
然后作者又对带宽的需求进行了评估,作者推导了效率的表达式,并结合测试给出了不同带宽和超参数情况下的效率对比,这里直接给个论文结论,具体推导可以看论文或解读
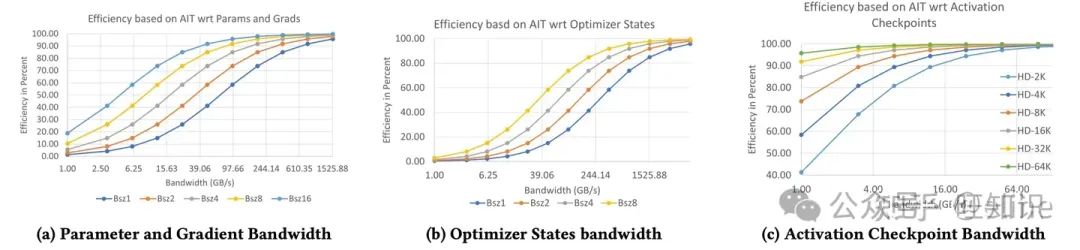
依赖这个结论,我们可以根据需要的效率推导所需的带宽约为多少
设计
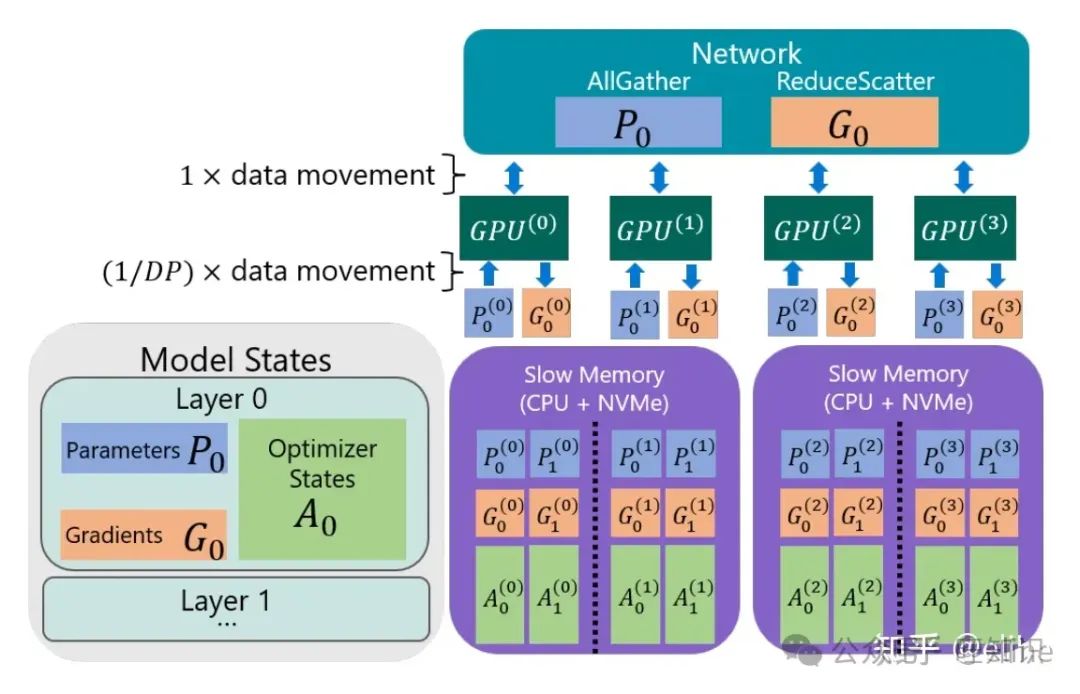
ZeRO-Infinity的设计分为几个关键点,这里定性展开下,定量建议看论文或解读
解决超大规模的设计(Design for Unprecedented Scale)
- Infinity offload engine for model states:用到了ZeRO-DP的 𝑃𝑝 模式,把模型状态都进行了分区,并且所有模型参数存储都放到了CPU或者NVME上
- CPU Offload for activations:激活值的ckpt也放到了CPU内存中
- Memory-centric tiling for working memory:可以简单理解为把大张量的计算拆分成多个较小的线性算子序列,用时间换空间的方式防止显存不够用
解决训练效率的设计(Design for Excellent Training Efficiency)
- Efficiency w.r.t Parameter and Gradients:提出一种基于带宽的划分策略来提高参数和梯度的传递效率,并允许通过PCIe的重叠通信
- Efficiency w.r.t Optimizer States:其实就是基于ZeRO-Offload的优化器状态参数传递策略,CPU一边计算参数一边并行传递给GPU,不过在这里用NVME offload时需要经过一次NVME
- Efficiency w.r.t Activations:也是基于ZeRO-Offload的激活值传递策略,每个GPU通过PCIe并行写数据到CPU,可以超过80%的效率,很显然如果减少激活值ckpt的频率的话也能提升该效率(代价就是增加激活值重算的时间)
解决易用性的设计(Design for Ease of Use)
其实就是基于PyTorch在代码层封装好了各种算子操作(如reduce-scatter和all-gather等),不需要用户自行再写相关的代码了
- automated data movement:自动在FWD和BWD后触发收集和分区的相关操作,把数据同步到CPU或者NVME
- automated model partitioning during initialization:初始化时自动分区模型和参数
然后论文后续对上述提到的所有设计进行了原理展开,最后给出了效果和结论,具体的原理本文就不讲了,希望读者能结合梳理出来的脉络通读一下论文,然后再结合论文的原理阅读DeepSpeed的源码
本节需要了解:
- 定性的了解ZeRO-Infinity做了哪些事
- 了解ZeRO-Infinity每个设计所需方法的原理(如Bandwidth-Centric Partitioning,Overlap Centric Design等论文第六章和第七章内容)
- 最好能结合了解到的原理读一读DeepSpeed的开源代码
3D Parallelism
可以参考这个
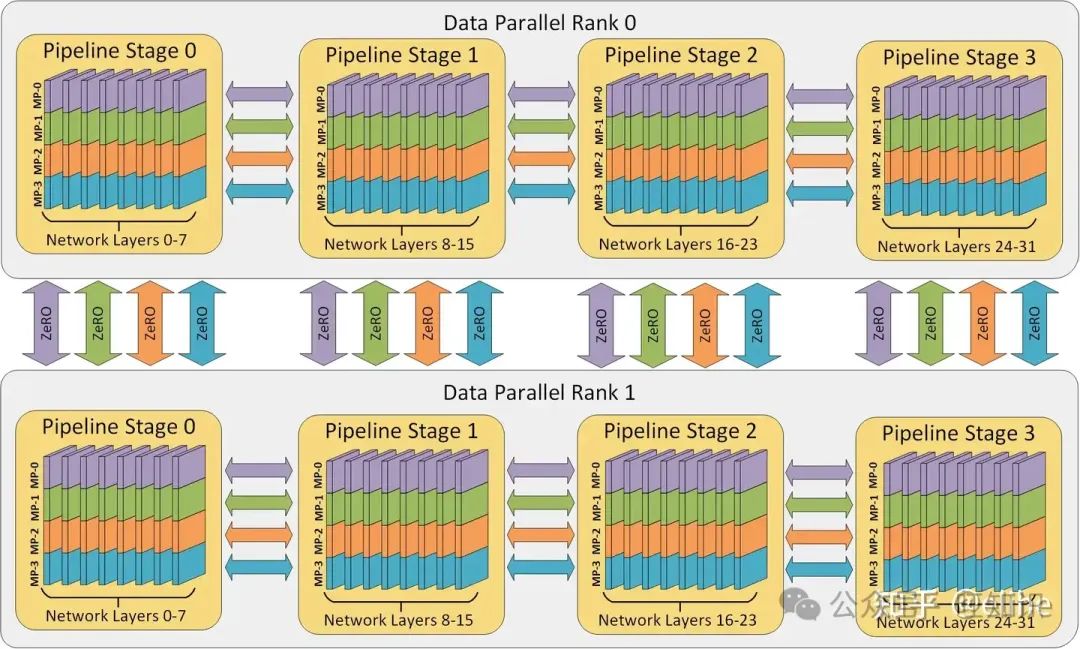
该方法可以说是把模型并行、管线并行和数据并行结合到了一起,几乎可以用于训练目前所有规模的模型。该方法首先把模型按照层拆分为不同的Pipeline Stage,每个Pipeline Stage内的张量可以用多个设备装载,然后一个完整的Pipeline作为一个Data Parrallel,和其他的完整Pipeline用Zero进行数据并行训练
本章需要了解:
- 3D Parallelism是如何结合模型并行、管线并行和数据并行的
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









