







机器学习实战总结
正在整理中……
你看完这本书了么,一起复习一下吧
整本书建议结合中英文、源代码一起看
1KNN
knn的主要思想是计算与特征最近的已知数据,选取照频率最大的特征。
注意计算距离的时候用的dataset的格式,否则可能报错
在计算距离时为避免部分特征权重过大,故将每个特征都归一化
在手写数字的辨别系统中,将32*32的图像转化为了有1024特征的数组,在读取训练样本中使用了from os import listdir来读取众多的文件名然后批量处理计算得到最近的类型
主要用的函数有tile sum(axis=1) argsort get(label,0)+1 sorted listdir 另外在读取文本的时候用的是readlines 在把图像转化为向量时在循环内部用的是readline 可以体会下不同点噢
2决策树decision trees(ID3)
首先要了解概念,书里都有了就不敲了
什么是熵 shannon entropy
http://baike.baidu.com/link?url=j54qkVk75624IgzEO0wh4eKrg6D-VV2OtY7zJVvcQHwbEPPEUqr6-8fatj-CCpajPkL8NidbSSA7LqZDx6QWO_延伸阅读
http://dataunion.org/5107.html
《通信的数学理论》
http://zhidao.baidu.com/share/748d0309785ff11ce4085128050d5643.html
决策树分为两部分,第一部分是创立决策树字典,第二部分是绘制决策树,可以看成是递归的练习,好多递归调用/(ㄒoㄒ)/~~
2.1创立决策树字典
2.1.1 选取最佳特征
首先要理解上面关于香农熵的概念,之后据此选取最佳特征作为决策节点,大体思路是利用了循环嵌套,对于每个特征比较各个特征值作用下的熵,看那个增益最大,找特征值时用了set相当于MATLAB里面的unique
2.1.2创建字典
递归开始爆发了!
神奇之处就是创建了个keys值为字典的字典的字典的字典……
看下式
myTree = {bestFeatLabel:{}}
即:
先将特征为字典的keys
然后将特征的特征值作为新字典的特征,如果有不同的特征值就可能有多个新字典
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)递归啥时候结束呢,1全部分类相同时就不需要在分类了,2全部遍历完了所有的特征都考虑了,注意这个时候可能相同的特征不同的结果如四个特征值都为1111但是其分类却是nononoyes 此时一般选取多的返回
主要用的函数有:extend append count 列表推导 sorted
2.2绘制注解决策树
2.2.1 整体思路
将字典利用Python的annotate功能绘制成树状图。
2.2.2 具体实施
因为绘制每一个树枝用的方法相近,所以可以使用递归调用,绘制每个决策节点和叶子节点。
- 利用annatate时需要的带求参数有坐标及注解内容
坐标的选取很有技巧性,看下图:
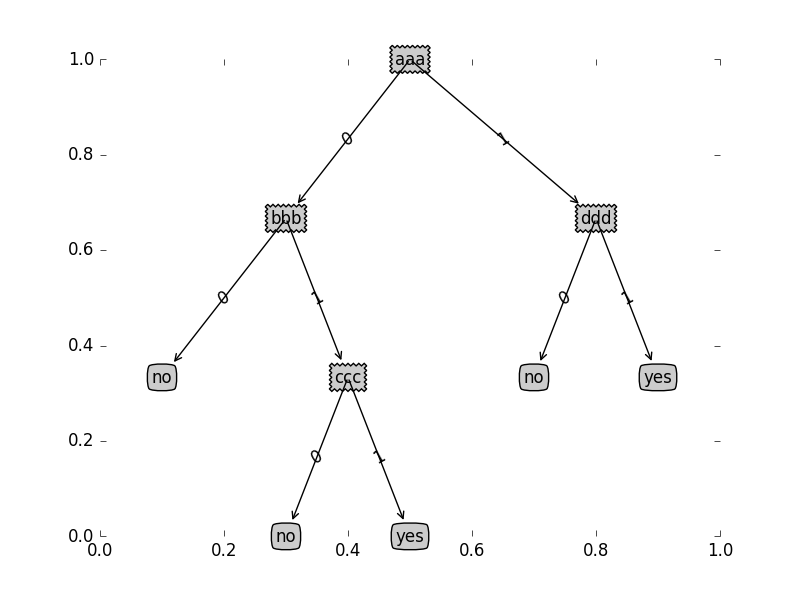
公式是咋来的呢,这里提示一下,看图中bbb的横坐标是如何定位的呢,首先所有的叶子节点 均匀分布的,
显然它应该处于它下属的三个叶子节点的中间,
而最左端的no节点如果能点位那么bbb也就可以定位了,
no距离最左边占了 12 个 1w ,
再来看ccc是如何定位的呢,
同样,其下属的no节点如与左边的no节点相差了一个 1w ,
也就是说除了第一个决策节点外,其他的决策节点都是根据最近的已经确定的叶子节点的横坐标的设置的,为了能递归将初始横坐标设置为 −12w 即可
关于注释的内容:
先来看下我们的决策树字典
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
若先画出第一个决策节点,那么我们发现每个中间特征值(0或者1)和特征都是这个字典的key而叶子节点为key的value(非dict)。
- 下面就要关注递归的结束条件
在递归计算坐标和annotate内容时都是看key的value是否是一个字典(注意此时所用的key),若是字典就画出决策节点和中间特征值
决策节点是字典的第一个key,而中间的特征值就是这个字典的key( 它的上一层),所以最外层的特征值是没有上层的key的用‘’代替。此处巧妙的地方需要自己慢慢体会哇
另外,叶子节点数量和书的深度也是用递归调用来完成的,具体原理与上面类似就不解释了
主要用的函数 annotate text isinstance figure clf show subpolt
2.3测试和储存
测试时主要用到了index函数用来选取label对应的特征值,获得树上的下级value,判断是否是字典,然后递归调用,直到不是字典返回value作为分类
储存和调用主要使用了pickle.dump pickle.load
如果上面理解了实例运用也就简单了
3朴素贝叶斯 Naive Bayes
首先这个算法的名字就很好简称NB哈哈
首先要了解条件概率
我们要做的就是通过这个算法在知道x的条件下计算
P(类别|x)
,因为这里得到的是概率,所以要计算出所有的类别,然后比较各类出现 概率,概率最大的我们就认为是合理的分类
为了方便表述,假设我们要求在x出现的时候类别为垃圾邮件的概率
如果有很多x,比如后面要说的垃圾邮件中有很多的字,这个算法中我们假设每个字都是相互独立的,彼此不认识,所以这个算法叫朴素贝叶斯。
如上文所说,我们计算 P(垃圾|x) 主要是为了和 P(不垃圾|x) 比较大小,在上面的公式中我们发现分母都是一样的因此比较的时候可以不用管,另外,如果要计算很多个x,他们的 P(x|垃圾) 就是 P(x|垃圾)=∏P(xi|垃圾) 如果每个概率都很小,那么成绩也就很小了,在Python容易近似为0,为了方便比较我们对分子求log
知道了这些下一步就是计算分子了:
以垃圾邮件分类为例:
首先应建立字库,也就是在这些邮件里都出现了那些字,然后统计每个字在垃圾邮件中出现的次数及在正常邮件中出现的次数储存在两个矩阵中,然后除以出现的总数就分别得到了每个字在垃圾邮件出现的概率和在正常邮件中的概率 {P(x|垃圾)和 {P(x|正常) 然后分别乘以垃圾的和正常的概率 {P(垃圾)和 {P(正常)(程序里因为是求log所以是求和)
这样就结束了,先把其中的得到概率的程序与接受文本的程序贴上
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)#0轴长度=邮件数目
numWords = len(trainMatrix[0])#字库长度
pAbusive = sum(trainCategory)/float(numTrainDocs)#stam概率
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]#字库在正常邮件中出现数量的矩阵(考虑出现次数)
p1Denom += sum(trainMatrix[i])#全部字库出现的总数量
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()变log方便变乘为加 而且避免在很多很小的数相乘时容易太接近零
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive def spamTest():
docList=[]; classList = []; fullText =[]
for i in range(1,26):#注意不包括26
wordList = textParse(open('email/spam/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary创建无重复字库
trainingSet = range(50); testSet=[] #create test set
for i in range(10):#0,1,2,……,9
randIndex = int(random.uniform(0,len(trainingSet)))#random.uniform的函数原型为:random.uniform(a, b),用于生成一
testSet.append(trainingSet[randIndex]) #个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a <b, 则 b <= n <= a。
del(trainingSet[randIndex]) #删除trainingset中的序号防止重复
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))#统计每篇文章中重复出现次数
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]#统计待测数在字库中出现的的次数
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print "classification error",docList[docIndex]
print 'the error rate is: ',float(errorCount)/len(testSet)
#return vocabList,fullText注意的是在书后面的例子中剔除了出现次数最多的若干单词,要合理好多,另外在其他书籍上的贝叶斯还加入了风险因子等信息。
另外在处理文本时用到了正则表达式
4logistic 回归 逻辑回归
首先,关于要理解关于参数
θ
是如何更新的,本文中用的是w,这里做简要的总结
logistic回归的中的每一个特征都遵循sigmoid函数
h(z)=11+e−z
其中
z=w0x0+w1x1+……+wnxn
为方便讨论 设
hw(x)=P(y=1|x;w)
其中y是类别,下面的例子中可以设当y=1时有病,将有病和没病时的概率写在一起可以写成下式
当有很多个x时,将所有的概率相乘,求对数,然后利用最大似然,对 wi 求导就得到了梯度公式:
知道梯度了 就可以利用批量梯度、随机梯度或者mini批量梯度来算了
文中的初始值设为了1
批量算法时的Python代码如下:
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #matrix mult 100*1(设datamatrix是100*3的矩阵,weights是3*1的矩阵)
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #用到了矩阵的乘积随机梯度时,可以不用matrix格式,因为每次只迭代一个
weights = weights + alpha * error * dataMatrix[randIndex]要注意这样算的时候datamatrix不可以是list噢,书的源程序logregres.py**使用时需要修改**
其实除了梯度上升法之外还可以用牛顿法,它的迭代次数要少,但是需要计算hessian矩阵
在文中第一个例子中是画出一条直线来将散点分类,而直线所在的位置就是使x1和x2满足sigmoid等于0.5的地方
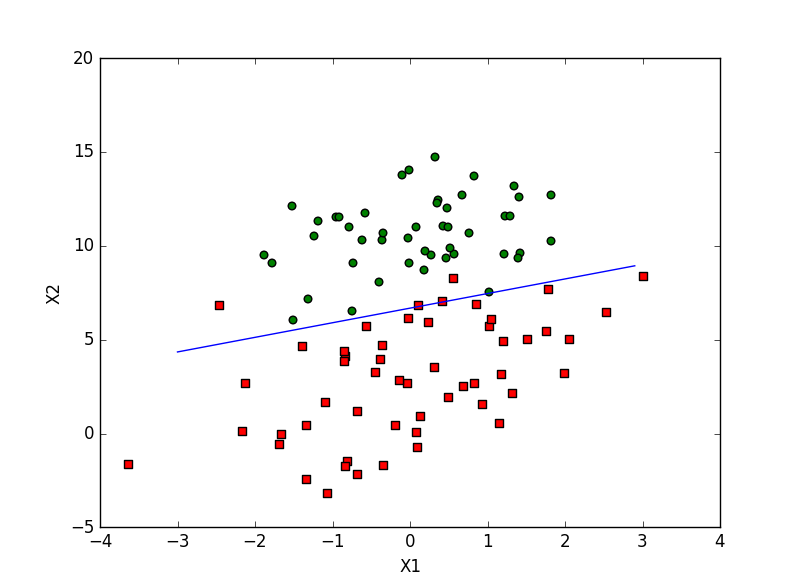
值得注意的是在使用批量梯度下降时因为权重开始时设为weights = ones((n,1)),所以划线时如果直接用weight[0]就会使y变为1l,60l的矩阵与x不同,绘图容易出错;量外图片上是迭代了500次的结果,如果迭代1000次效果会更好些
对于随机梯度上升,书里将alpha的值设为逐渐变小的值
本章中的预测马的疾病情况,有一点非常值得学习的就是如何处理非完整数据:将不完整的数据用0补充(在logistic回归中)
5支持向量机 SVM
这是比较难理解的一篇,需要理解关于拉格朗日乘子法、kkt、VCdimension、kernal等等、但是已有很多优秀的博文介绍了,
我之前的也写了个通俗版的,(正在写),主要走心,
http://blog.csdn.net/bea_tree/article/details/50432411
下面的博客就很好http://blog.csdn.net/alvine008/article/details/9097105
http://blog.csdn.net/v_july_v/article/details/7624837
这个比较复杂 ,后面有时间再补上
6 Adaboost 算法
这个算法的道理比较简单,就是将几个弱分类器组合成一个强分类器。主要要弄清楚加权错误率、分类器权重、样本权重之间的关系,同时要知道最终分类结果与每次每类结果之间的关系。
流程如下:
1. 初步设置所有样本的权重,取相同的值
2. 选择弱分类器
3. 计算弱分类器的加权错误率(错误的样本权重相加)
4. 根据权重计算分类器权重alpha(分类器分的好权重大)
5. 计算更新的样本权重(分类正确样本权重变小)
6. 计算各个带权重的分类器之和,建造一个总的分类器(不懂可以看下面的例子),看是否错误率为零,如果不为零,继续代入第二步计算,注意再次计算步骤2时的权重更新了,错误的样本被重视,更有可能被新的若分离器成功分类,与前面的分类器互补,它的分类样本是前面分类器的结果(这就话比较重要,理解了它就理解了adaboost),这也就决定了当分类器按照权重相加时错误率逐渐减小。
在李航博士http://blog.sina.com.cn/u/2060750830的《统计学习方法》中有关于误差的证明有兴趣的可以看一下
还是不太明白的话,让我们一起看个例子~
有5个数据
1、权重相同(0.2)
2、弱分类器分错了第一个,分类器权重alpha为0.69
3、第一个数据的权重变为0.5
4、第二次分类,如果选用第一次同样的分类器就会发现,此时分错的数据权重很大,导致所计算的加权错误率很大,所以,更改弱分类器,直到得到加权错误率最小的那个分类器。此时alpha为0.97.
!注意:此时得到的分类结果是什么呢?此时的分类结果是第一次的分类标签×0.69+第二次的分类标签×0.97,这样一来,假设第一个数据的标签为+1,那么两次的分类结果为sign(-1*0.69+1*0.97)=sign(0.28),那么现在第一个标签的结果就是正确的。但是同时,可能有第一次分类正确的标签,在第二次分类中出现了错误。
5、经过第二次分类后,第五个元素分类出现错误,于是第五个元素的权重变大,为0.5
6、进行第三次分类,此时每个元素的最终类别并不是最后一次分类的结果,而是三次分类的权重之和,假设第三个弱分类器的alpha 是0.89,那么最终的分类结果就是
0.69X1+0.97X2+0.89X3
.假设第五个元素的正确label为+1,那么经过两次分类,结果为0.69-0.97+0.89>0,此时分类结果正确。
从中可以看出,每次分类都是在前几次分类正确的前提下进行的,而且每次改进都是在将前几次分类错误改正的前提下,尽量的减少分类错误,这就保证了分类向着越来越正确的方向进行。
单层决策树
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
#d越大,error越大,alpha越小
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
#multiply点乘 若分类正确 expon就是-alpha
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEstdef adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify确定相应标签
aggClassEst += classifierArr[i]['alpha']*classEst#乘以全中后相加
print aggClassEst
return sign(aggClassEst)7 线性回归、局部加权回归、岭回归、逐步线性回归
- 首先关于线性回归,计算新型回归的中心就是计算线性回归中的参数 θ ,书中主要是利用求最小二乘法时矩阵的计算的结果normal equation,当然也可以用梯度下降法来计算。
- 局部加权线性回归LWLR的中心思想是给每个点一个权重,然后线性拟合, θ 是一系列数据相加得到的,我们在计算线性回归中时计算,将目标点附近的权重加大,离着目标点越远的点权重越小,这个可以利用像高斯分布一样的函数来计算。这样由于重点考虑了目标点周围的训练数据,得到的整体结果不再是线性的,而是一个非线性的,注意如果在选取范围的时候,选取的范围越窄其bias可能越小(与训练数据拟合越好),但是容易过拟合。
- 岭回归(Ridge regression)是在当特征数目比样本数目还多时,不能继续运用线性回归的公式,为了继续运用以前的公式就在X.TX后加入了一个lambdaI如下:
w=(XTX+λI)−1XTylambda怎么来呢:取一组测试数据,取与之拟合误差最小的 λ ,文中之处,在测试 λ 时用指数间隔的方式来选取,这样可以尽快的选取较小到较大的范围,看其预测误差。
- Lasso(拉锁) 。文中之处岭回归与计算最小二乘法时加入约束条件(所有系数平方之和小于lambda)的结果是相同的,拉锁就是替换了这个条件,变成了所有系数绝对值之和,引入了绝对值就使方程很复杂啦,文中没有具体介绍
- 向前逐步回归,本文中所说的逐步向前回归(Forward stagewise linear regression)只给出了与线性回归相当的算法,也就是只能预测线性关系明显的值。具体思路是这样的逐步改变参数wi使得计算值 y^ 与y的方差最小,其实也就是相当于一点点的试取w,最终会与线性回归得到的数差不多。如果把他变一下,变成“向前分步算法”,就可以拟合分线性了,这与前面的adaboost很像,都是先找一个误差最小的若拟合,然后权重相加,变成一个强拟合。简直是棒棒哒!
8树回归
经过前面的ID3决策树算法之后看这章应该会容易些
之前我们学习的ID3是每次选取最佳特征的所有可能只来切分,也就是说如果一个特征有10种取值就分10份这显然不太妥当,如果出现这种情况我们可以事先对特征进行处理,也可以利用下面的二元切分法,其中CART算法就是十分著名的一个。
CART可以用来分类也可以用来回归,分类的时候叶节点就是数据,分类的时候叶节点是连续性的模型。下面我们具体来看一下:
首先在选取最佳特征的时候的评选条件不同,在以前的ID3中我们使用时熵entropy的概念,这里我们改用了使得选取的特征之后的平方误差的总值来作为选择特征的标准的,选取误差最小的分类特征。(相似的还有基尼系数GINI)
选取最佳特征的流程如下:
1. 首先判断,剩余数据的label是否全部都一样,一样的话就不用分了,直接返回叶节点为none值为label。
2. 如果剩余的label不一样,用每个特征中的每个值分别切分,看剩余切分后的矩阵的平方误差的总值大小,小的作为最佳特征。
3. 看经过第二步之后的误差减小的是否明显,如果减小量比我们设置的阀值还小,那么就没必要切分了,再切也意义不大啦,直接返回叶节点为none值为label的均值
4. 如果切分之后剩余的数据集数目太少了,比如本来有几千个数据集,我们切到某一步之后就还剩下两个了,我们有时候会觉着 这两个放在一个分类里也行,就没必要切分了,直接返回叶节点为none值为label的均值
5. 如果剩余的数据可以继续切分,那就继续重复第一二步骤
上面5步,有几个细节:
切分函数
def binSplitDataSet(dataSet, feature, value):
mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:][0]#nonzero作用返回矩阵非零值坐标
mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:][0]
return mat0,mat1还有计算剩余标签种类代码
if len(set(dataSet[:,-1].T.tolist()[0])) == 1: #exit cond 1
# dataSet[:,-1].T.tolist()得到一行n列的列表,所以后面要加[0]
return None, leafType(dataSet)知道选取最佳切分点的代码后就要利用他来继续创建树了
这里的树的字典有4个key,切分特征,值,左分支,右分支
首先选择最佳切分点,将切分点的信息返回储存,将左右分支继续递归创建树。
剪树枝
创建好了树,可是有时候按照上面创建的树容易太复杂,比如过拟合,怎么办呢,这里给出的方法是剪树枝:
原料:一棵大树
工具:测试数据
步骤:
1. 对于剩下的树枝有没有测试数据集?没有的话就剪掉 直接以平均值代替
2. 这个树枝的字典里的左右是不是还是树枝?是的话就按照剪树枝的程序,从1开始递归
3. 如果左右分支都不是树枝了,那就看一下如果不合并时预测的误差和合并时的误差哪个小,按照小的来
模型树
这里不同的是左右分支的叶节点不再是一个点,而是一个函数,连续的函数,书上给的是前一张我们学习到的线性回归,这样就可以在不同条件下进行不同的拟合了。
注意,这里的特征矩阵有特色哦,有处理哦
X = mat(ones((m,n))); Y = mat(ones((m,1)))#create a copy of data with 1 in 0th postion
X[:,1:n] = dataSet[:,0:n-1]; Y = dataSet[:,-1]#and strip out Y x加了常数项没错 特征矩阵的第0列是常数项
与前面的离散型不同的是这里的节点用的是线性方程的系数,误差改成了拟合之后与原本真实值的误差平方和
……
聚类先跳过回来再补上
12 主成分分析 Principal Component Analysis
可以说很多时要候拿到数据要处理的第一步就是分析数据,简化数据
书中介绍了三种降维方法
1. PCA
2. Factor Analysis 因子分析
3. Independent Component Analysis ICA 独立成分分析
但是主要选择讲解了最常用的PCA
举一个简单地例子,比如我们的特征矩阵中有年龄与颜值两个数据,但是年龄和颜值可能还有相关性,比如随着年龄升高颜值可能会下降,我们主成分分析法就是找到另外的两个特征,其中一个可以包含大部分信息,另外一个特征包含的信息量比较少,前面说了假设颜值随着年龄的升高而下降,那我们就新建两个相互独立的特征,这两个特征是原来特征(年龄、颜值)的线性组合,当其中一个特征升高的时候,年龄会升高,颜值会下降,也就是这个特征包含了年龄和颜值的关系,信息量就大了这就是主要成分,另外一个特征是与之相互独立,完全没有关系的,其包含的信息就可能比较少一点。
一句话原来彼此关联的特征转化为彼此无关的新特征,并选取主要成分。
设新的特征向量为Y,原来的为X,那么我们可以用下面公式来表示
其中,我们的主成分就是包含信息量最大的Y,什么样的Y信息量大呢:如果一个变量方差大的时候,那么他的变化范围就会大,那么他包含的信息范围就大,也就是信息量大。所以我们要求最重要的新特征y,也就是求方差最大的y而当我们队X进行标准化处理之后可以简单的理解为X均值为0方差为1,此时协方差就等于相关系数,可推导如下式
因为Y各新特征不想关所以其协方差矩阵也就是方差矩阵为对称阵
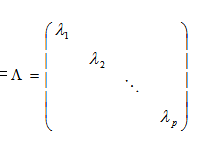
经过标准化处理后X’X也就是X的相关系数矩阵,设其为R,也就是
这篇文章讲的很具体,没看懂原理的可以看下面:
http://wenku.baidu.com/link?url=TmMJrYEt4kTV1iKEs_b95QlfJ7Iog7gc1T-TTitDzi1pL_TKZU_p_7A05ct2bPlIbYtpCB0Qclxri7sZpm7t5HhW51K5oHL-CGnC6M_zpVq
附上代码与注释,代码里面没有除以方差,直接用的协方差矩阵
def pca(dataMat, topNfeat=9999999):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)#若rowvar=0,说明传入的数据一行代表一个样本,若非0,说明传入的数据一列代表一个样本。
# 因为newData每一行代表一个样本,所以将rowvar设置为0。
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals) #sort, sort goes smallest to largest argsort得到的是序号
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions-1代表步长为-1也就是倒序
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals #y=cx,我们求的redeigvects是C的转置矩阵,x=yc'
return lowDDataMat, reconMat
附上打开csv文件的方法
http://blog.sina.com.cn/s/blog_67331d610102vno0.html
http://www.2cto.com/kf/201303/194320.html
http://blog.csdn.net/lixiang0522/article/details/7755059















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









