









1 简单回归
1.1 线性回归残差性质
线性回归想必大家都比较熟悉了, 其回归方程是
y^i=β^0+β^1xi
残差是:
ei=yi−y^i=yi−β^0−β^1xi.
残差有以下性质:
其残差为白噪声且与自变量没有关系
1.2 回归与相关性
回归与相关性有较大的关系,设相关系数为
r
,
可以看出线性回归将相关性联系起来
1.3 回归模型的评估
1.3.1 残差图绘制
绘制残差图能够清晰地看到那一段拟合的比较好,也能够看到异常点
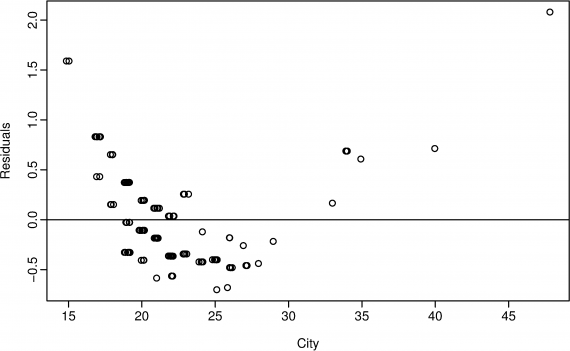
上图中可以看出 在开始小于20 大于35的地方拟合的不好
1.3.2 异常值观测
异常的检测方法很多,有监督,半监督,无监督等方法,有机会可以好好看下,本书中没有详细介绍。
1.3.3 拟合情况评价
评价线性拟合的拟合情况可以用决定系数
R2
来评价
其中观测值是y,带帽子的y是预测值
它的值越接近1越好,在0-1之间,。
但是:
并不是总是越大越好,如上面的图,在某一段会有拟合不充分的地方
简单的线性回归中
R2
等于相关系数的平方。
判定系数只是说明列入模型的所有解释变量对因变量的联合的影响程度,不说明模型中单个解释变量的影响程度。
对时间序列数据,判定系数达到0.9以上是很平常的;但是,对截面数据而言,能够有0.5就不错了。
还有一种方法叫做残差标准差,也叫Standard error of the regression回归标准差
主要到,这里除了n-2,而不是n-1,这是因为我们拟合了两个参数(斜率和截距)
1.4 预测
注意预测不单单是一个值,应该是一个区间,即数值+置信区间的波动范围
1.5 统计推断
可以使用假设检验来识别判断拟合的参数的正确性。
这里使用P值来表明在原假设成立时,发生的概率
统计学根据显著性检验方法所得到的P 值,一般以P < 0.05 为显著, P <0.01 为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05 或0.01。实际上,P 值不能赋予数据任何重要性,只能说明某事件发生的机率。
若X 服从正态分布和t 分布,其分布曲线是关于纵轴对称的,故其P 值可表示为P = P{| X| > C} 。
计算出P 值后,将给定的显著性水平α与P 值比较,就可作出检验的结论:如果α > P 值,则在显著性水平α下拒绝原假设。如果α ≤ P 值,则在显著性水平α下接受原假设。在实践中,当α = P 值时,也即统计量的值C 刚好等于临界值,为慎重起见,可增加样本容量,重新进行抽样检验。
具体推导公式本书未包含。可以查找其他资料学习。
1.6 非线性拟合
线性拟合不好的情况可以用非线性拟合,适当的将变量进行数值变化之后可以用线性变化的理论来拟合非线性的问题,如选用log-log模型
logyi=β0+β1logxi+εi.
1.7 时间序列回归
时间序列可以用前面讲到的判断法,但是往往效果不好,这里介绍了简单的时间序列的回归
yt=β0+β1t+εt.
它以时间t为自变量,当然回归之后还需要计算残差和ACF,如果ACF显示不是白噪声,说明有内在的联系为挖掘,它的预测精度可能不够。
伪回归
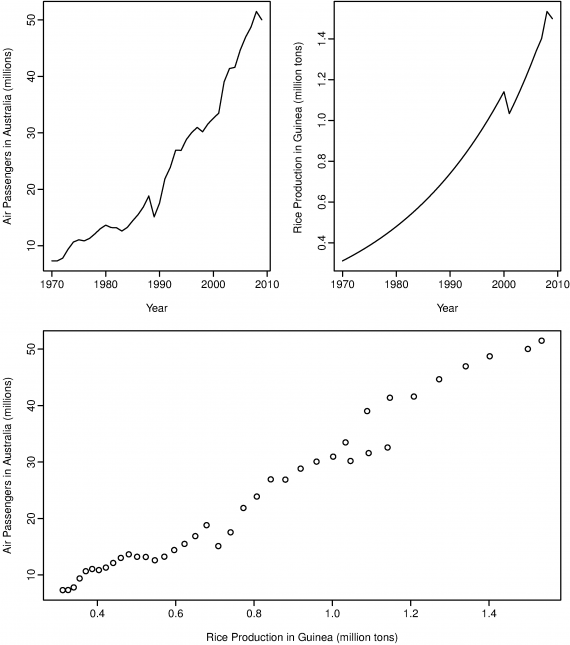
如图,几内亚的大米产量和澳大利亚的乘客数量看起来有相同的趋势,但实际上是没有关系的。如果直接用这样的数据来判断他们的关系久可能会造成伪回归。这常常是因为时间序列不稳定造成的。
2 多元回归
2.1 多元线性回归简介
他的一般公式如下:
其残差的性质如下:
1. 均值为0
2. 没有自相关性
3. 与自变量也没有相关性
确定系数依然是:
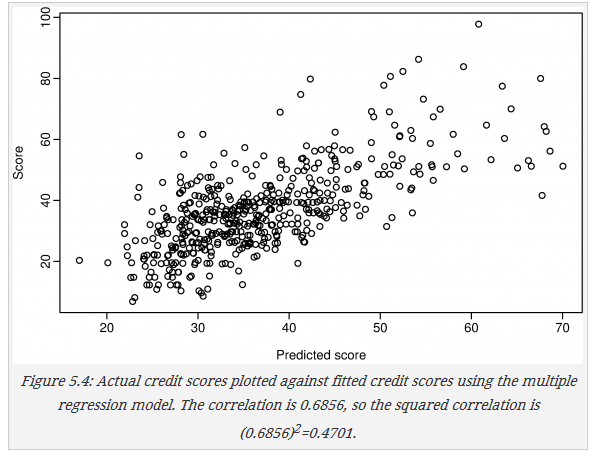
线性拟合可以用来做初步判断,如下图,将预测值与真实值画出,就可以发现在预测值小于35时,真实值一般都是低分者,所以可以用来做低分者的初步筛选。
2.2 Some useful predictors
2.2.1 Dummy variables 虚拟变量
使用方法:
1. 将yes,no等标记为 1,0
2. 将七天标记为1,000000;0100000;0010000等变量注意 变量数要比天数少1,否则会引起‘dummy variable trap’
3. 将异常值标记为一个新的变量
2.2.2 Tend 趋势
对于趋势的预测可使用线性或者二次,三次,,,等式不建议使用二次或者二次之上的表达式,得到的结果往往不好
推荐使用多个线性表达式相加,或者使用样条曲线
下面是多个线性相加的例子
总的模型是两式之和, x1,t 的系数为 β1 , x2,t 的系数为 β2 ,这样在 τ 之前的斜率为 β1 ,之后为 β1+β2
2.2.3 其他
其他几乎都是dummy 变量,根据世界情况设置特征,如看广告前一个月,二个月。三个月的销量,作为预测广告作用的特征。
2.3 Selecting predictors 特征选择
开始有两个不推荐的方法就不说了。
推荐的方法:
2.3.1 矫正后的 R2 : R¯2
之前的
R2
如下,越接近于1说明,拟合越好
但是,首先 R2 并没有比较性,有些0.2的其拟合型可能要比0.9的要好,其次其不包含自由度的影响,增加一个不相干的变量可能也会增加 R2 值,因此经过改进的 R2 来克服这些问题
k是参数的数量, R¯2 最大化的模型效果将最好
其等价于将下式最小化
其中
2.3.2 CV Cross-validation
Cross-validation 交叉验证是一个很好的方法,其方式也有很多,在此不再赘述
2.3.3 Akaike’s Information Criterion
其公式如下:
对于不同的软件其计算公式可能会有不同,但是效果相似,值越小越好
其缺点是如果N的值(样本数量)较小,可能会选择过多的特征,下式是改正(correct)之后的公式
2.3.4 Schwarz Bayesian Information Criterion
也叫作SBIC, BIC or SC,其计算公式如下:
同AIC都是越小越好,但是他对于参数k的惩罚更大。当N的值很大时,其效果等效于将v个样本留出的CV方法,其中 v=N[1−1/(log(N)−1)] 。
2.3.5 举例
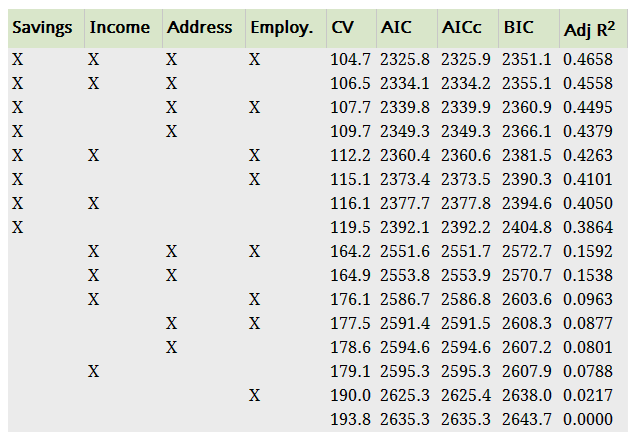
在看信用分数的时候用了四个特征,判断这个四个特征的选择情况供有2*2*2*2=16中情况,上图是16中情况的值,可以看出全部都选择时效果最好。
2.3.6 方法比较
样本数量大的时候选择的方法:CV, AIC or AICc
样本数量小的时候CV,AICc
R¯2
会选择太多的特征,不利于拟合
BIC往往会选择太少的特征,不利于拟合
2.3.7 逐步向后选择
如果特征数量太多,如何选择呢?如果还是比较每一个的重要性,会有太多的选择
这里的方法是:
1. 使用全部特征n个进行拟合
2. 去掉一个,使用n-1个看看效果
3. 重复第2步n-1次
4. 再去掉一个,使用n-2个看效果
5. 重复 直至其指标不在变好
虽然这样不一定得到最好的特征组合,但是往往都不错
2.4 残差诊断 ⋆⋆⋆⋆⋆
2.4.1 残差-特征散点图
还是信用分数的例子
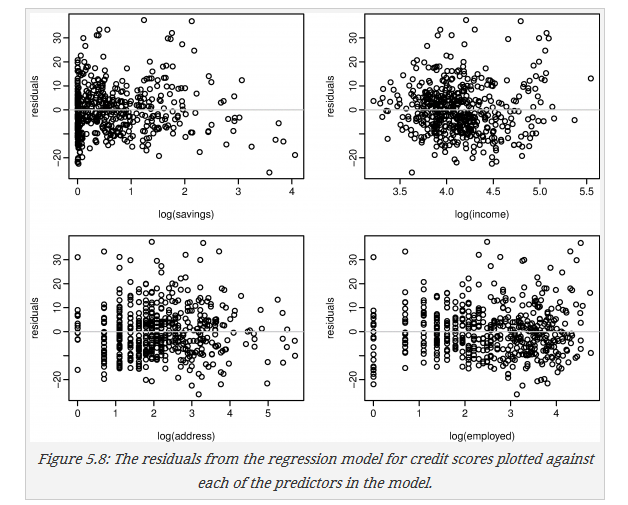
上图可以看出,在saving比较小时会有较大的残差,saving比较大时会倾向于预测一个较大的值以致于得到了负残差,这是需要改进的地方。
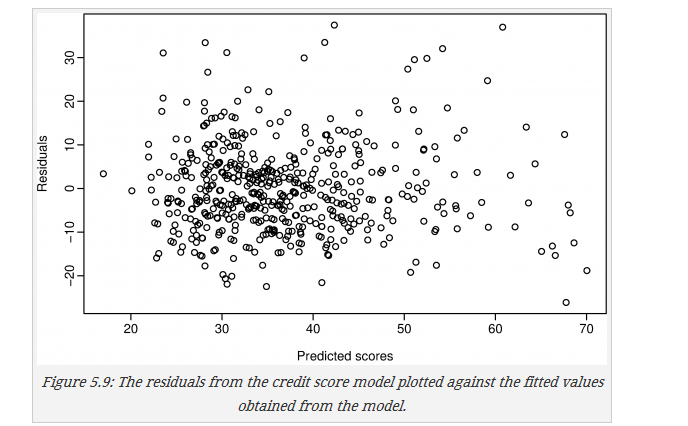
2.4.2 残差-预测散点图
还是上面的例子,没看出啥需要改进的地方
2.4.3 残差自相关
画出残差图和残差自相关
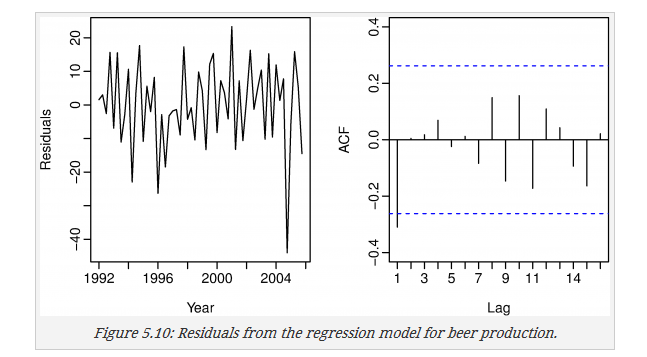
可以看出在2004年时有一个残差很大的地方,需要进一步的分析
ACF上可以看出一个地方的值较大,可以进一步改进
其他自相关测试
- Durbin-Watson test,如果没有自相关性其值应为2左右,如果有自相关性相应的P-value应该接近于0
dwtest(fit, alt="two.sided")
# It is recommended that the two-sided test always be used
# to check for negative as well as positive autocorrelation
结果为Durbin-Watson test
DW = 2.5951, p-value = 0.02764可以看出有一些自相关性
- Breusch-Godfrey test
用来检查高阶差分的自相关性
# Test for autocorrelations up to lag 5.
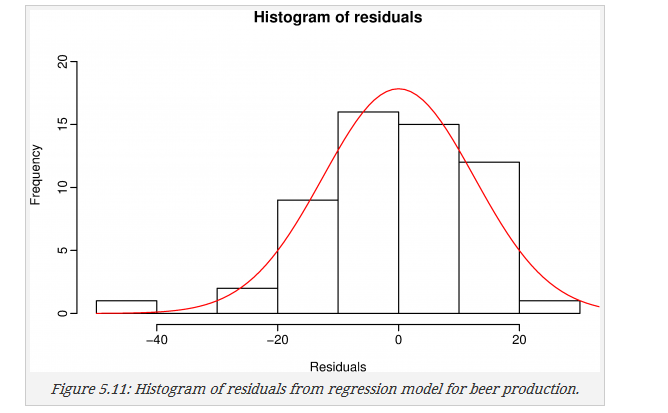
bgtest(fit,5)2.4.4 残差分布直方图
残差分布应该 接近于正态分布,上例的残差看起来稍微有点偏
2.5 矩阵形式
将线性回归的矩阵简单罗列如下:
设特征矩阵
则线性表达式为
最小二乘法得到的结果
剩余方差:
拟合:
其中H也被称为帽子矩阵
预测值:
方差:
95%的预测区间为
2.6 多重共线性
多重共线性是指一个或几个特征有着线性关系,比如上面的dummy variable trap,就是一个
它会带来的后果:
1. 如果线性关系非常确定,将可能无法求解
2. 如果有着较强的线性关系,其回归参数将难以确定,模型不精确
3. 回归参数的不确定性将增大
4. 如果所预测的特征值不在原有特征值的范围之内得到的结果是不准确的















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









