







这一篇文章为上一篇ResNets提供了更加可信服的论据
Authors
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
都是“老熟人”了就不介绍了
Abstract
上篇文章中(http://blog.csdn.net/bea_tree/article/details/51735788)因residual builing blocks而得以建设100多层的深度网络,这里有介绍了新的residual unit,使训练更容易, 并且improves generalization。
1 Introduction
Residual Units:
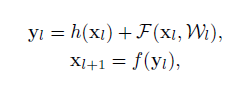
上篇文章中, h(xl)=xl,是输入,f是Relu,x(l+1)是输出。如果h(xl)和f(yl)都是identity mappings, 信息就会直接从shortcut直接传输。
为了明白skip connections的作用,文章进行了分析与实验,发现identity mapping h(xl)=xl可以取得最快的error reduction和lowest training loss(参与实验的有 scaling,gating, 1x1convolutions)。
这里使用ReLU和BN放置于weightlayer前,作为新的residual unit,如下图:
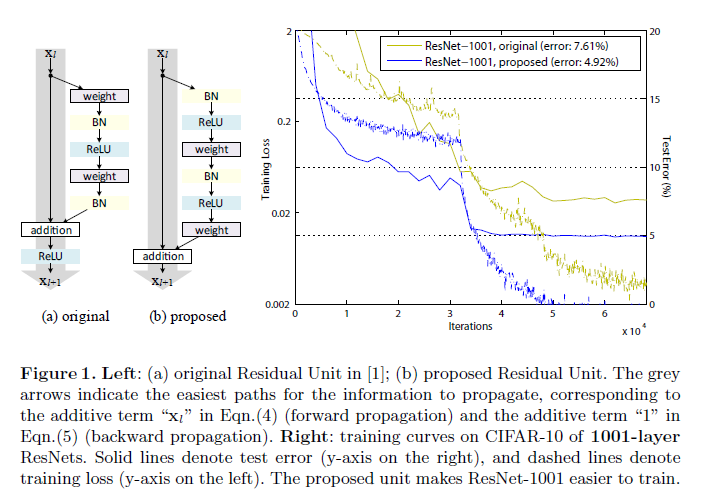
新的结构更容易训练也更容易泛化,使用它建立了1001层网络。
另外在上篇文章中200层网络就开始过拟合,这里对其进行改进。
2 Analysis of Deep Residual networks
如果 f 也是一个identity mapping,那么其结构可以写成这样:
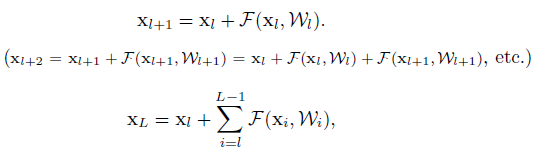
上式展现了ResNets两个特性:
1. 模型是以残差形式存在的
2. 这是以相加的形式存在而plain network是以矩阵相乘的形式存在的
上式的反向传播形式
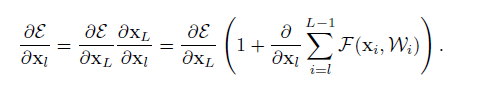
可见 ∂ε∂xl 分为两部分其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









