







摘要:DeepSeek的量化版、蒸馏版和满血版在参数规模、性能表现和适用场景上各有特点。满血版拥有6710亿参数,推理能力强,适合高端科研和复杂任务;蒸馏版参数规模较小,适合资源受限环境,响应速度快;量化版通过量化技术进一步压缩模型大小,推理速度快,适合移动端和边缘设备。用户应根据需求、硬件资源和预算选择适合的版本。

一、引言
在当今人工智能飞速发展的时代,大模型如雨后春笋般不断涌现,而 DeepSeek 无疑是其中备受瞩目的一颗新星。自其诞生以来,便在 AI 领域掀起了一阵热潮,以其独特的优势和创新的技术,吸引了无数开发者和企业的关注。
随着 DeepSeek 的广泛应用,其量化版、蒸馏版和满血版也逐渐进入人们的视野。这三个版本各具特色,适用于不同的场景和需求,它们之间的区别也成为了众多开发者和 AI 爱好者热议的话题。那么,这三个版本究竟有何不同?在性能、应用场景等方面又各自有着怎样的表现呢?接下来,就让我们一起深入探讨一下 DeepSeek 量化版、蒸馏版和满血版的区别。

二、DeepSeek 版本总览
DeepSeek 自问世以来,便在不断的探索与创新中持续发展,其系列版本也在逐步完善和丰富。从最初版本的基础功能搭建,到后续不同版本针对不同场景和性能需求的优化升级,DeepSeek 始终致力于为用户提供更优质、更高效的 AI 服务。
在 DeepSeek 的众多版本中,量化版、蒸馏版和满血版备受关注。这三个版本在参数规模、性能表现以及适用场景等方面存在着显著的差异。
满血版拥有最为庞大的参数规模,这使得它在复杂推理任务中表现得游刃有余。无论是高深的数学问题,还是复杂的编程逻辑,亦或是需要深度分析的长文本,满血版都能凭借其强大的参数优势,给出精准且详细的解答。其上下文理解能力极强,能够深入挖掘文本中的含义,为用户提供高质量的服务。
蒸馏版则是在保证一定性能的前提下,对参数规模进行了合理的压缩。它通过知识蒸馏技术,将满血版中的关键知识提取出来,形成一个相对轻量级的模型。虽然在推理能力上略逊于满血版,但蒸馏版在资源受限的环境中却有着出色的表现,能够快速响应用户的请求,满足实时性要求较高的场景。
量化版的核心在于量化技术的应用。它通过降低权重精度,进一步减小了模型的大小,使得模型在内存受限的设备上也能轻松运行。同时,量化版在推理速度上也有着明显的优势,能够快速处理任务,但其在精度方面可能会有所牺牲,尤其是在处理复杂任务时。
三、参数规模差异
(一)满血版:参数巨无霸
满血版 DeepSeek-R1 堪称参数规模上的巨无霸,拥有高达 6710 亿的参数 。这些海量的参数就如同一个庞大的知识储备库,使得模型能够学习到极其丰富和复杂的语言模式、语义信息以及世界知识。在处理复杂任务时,它可以凭借这些参数对各种信息进行深度的分析和理解。
以科学研究领域为例,在处理一篇关于量子物理的复杂论文时,满血版能够快速理解其中晦涩的专业术语、复杂的理论推导以及各种实验数据之间的关系,从而准确地总结论文的核心观点和研究成果。在自然语言生成任务中,无论是创作一篇结构严谨、内容丰富的学术论文,还是构思一个情节跌宕起伏、人物形象鲜明的小说故事,满血版都能轻松应对,展现出强大的语言生成能力。
(二)蒸馏版:参数灵活多样
蒸馏版的参数规模则相对灵活多样,从 1.5B 到 32B 不等,具体的参数数量取决于蒸馏的程度 。蒸馏技术的核心目的是将大模型(教师模型)的知识和能力传递给小模型(学生模型),使小模型在保持较小规模和较低计算成本的同时,尽可能获取大模型的性能,提高模型的泛化能力。
由于参数规模较小,蒸馏版在推理能力上自然略逊于满血版。但在一些资源受限的环境中,如小型企业的服务器或者嵌入式设备中,蒸馏版却能发挥出其独特的优势。在小型企业的客户服务场景中,使用蒸馏版模型搭建的智能客服系统可以快速响应用户的咨询,解答常见问题,提高客户服务的效率,同时又不会对企业的硬件资源造成过大的压力。
(三)量化版:参数与蒸馏版相似
量化版的参数规模和蒸馏版类似,但其独特之处在于通过量化技术进一步压缩了模型大小 。量化技术的原理是降低权重精度,例如将模型参数从 32 位浮点数(FP32)转换为 8 位整数(INT8)。这样一来,模型所占用的存储空间大幅减小,同时在一些支持定点运算的硬件上,推理速度也能得到显著提升。
在移动端设备上,如手机或平板电脑,由于设备的内存和计算资源有限,量化版模型可以轻松部署,实现诸如智能语音助手、图像识别等功能。在智能语音助手应用中,量化版模型能够快速识别用户的语音指令,并给出相应的回答,满足用户在移动场景下的实时交互需求。但这种压缩也并非毫无代价,量化版在精度方面可能会有所牺牲,尤其是在处理复杂任务时,其表现可能不如未量化的版本。
以下是关于 DeepSeek 三大版本(量化版、蒸馏版和满血版)的相关文章推荐:
1. DeepSeek 各版本说明与优缺点分析
-
文章链接:DeepSeek 各版本说明与优缺点分析
-
内容简介:该文章详细介绍了 DeepSeek-V3 和 DeepSeek-R1 系列的不同版本,包括参数规模、模型架构、性能表现以及优缺点分析。文章还提供了各版本在不同测试集上的表现数据,帮助读者更好地理解各版本的特点和适用场景。
2. DeepSeek-R1 不同版本的主要区别以及各个蒸馏版本的优缺点
-
内容简介:该文章深入剖析了 DeepSeek-R1 系列的不同版本,包括 1.5B、7B、8B、14B、32B、70B 和 671B 等版本的主要区别、优缺点以及适用场景。文章还提供了各版本在不同任务上的性能表现数据,帮助读者选择合适的版本。
3. DeepSeek-V3 和 DeepSeek-R1 的区别
-
内容简介:该文章对比了 DeepSeek-V3 和 DeepSeek-R1 的应用场景、部署方式、开源生态以及社区影响。文章还详细介绍了两者的模型架构、参数规模和性能表现,帮助读者更好地理解两者的区别和适用场景。
4. DeepSeek-R1 的量化版、蒸馏版和满血版区别
-
内容简介:该文章详细介绍了 DeepSeek-R1 的量化版、蒸馏版和满血版的特点、性能表现以及适用场景。文章还提供了各版本的参数规模、部署成本和响应速度的对比表,帮助读者更好地选择适合自己的版本。
5. DeepSeek 本地部署——蒸馏版、量化版和满血版实测效果对比
-
内容简介:该文章介绍了 DeepSeek 的三种不同类型模型(满血版、1.58 bit 量化版和蒸馏版)的本地部署过程和实测效果对比。文章还提供了各版本的硬件需求、部署步骤以及实际应用中的效果评测,帮助读者更好地了解各版本的性能和适用场景。
希望这些文章能帮助你更好地了解 DeepSeek 的三大版本及其特点。
四、性能表现大比拼
(一)满血版:复杂任务的王者
满血版 DeepSeek 凭借其庞大的参数规模和强大的模型架构,在复杂任务处理上展现出了无与伦比的实力。在数学推理任务中,面对诸如高等数学中的复杂微积分计算、数论问题等,满血版能够深入分析问题的本质,通过复杂的逻辑推理和知识运用,给出准确且详细的解答过程。它可以清晰地阐述每一步的推理依据,帮助用户理解问题的解决思路。
在编程领域,当需要开发一个大型软件项目,涉及到多种编程语言的协同工作、复杂的算法设计以及对各种框架的运用时,满血版能够快速理解项目需求,生成高质量的代码框架和详细的代码实现方案。它还能对代码进行优化建议,提高代码的执行效率和可读性。
(二)蒸馏版:资源受限下的强者
蒸馏版虽然在参数规模上小于满血版,但其在资源受限的环境中却有着出色的表现。在小型企业的智能客服场景中,由于企业的服务器资源有限,无法承载大型模型的运行,但又需要一个能够快速响应用户咨询的智能客服系统。此时,蒸馏版模型凭借其较小的模型体积和较快的推理速度,能够轻松部署在企业的服务器上,实时解答用户的常见问题,如产品信息咨询、售后服务问题等,大大提高了客户服务的效率。
在智能家居设备中,由于设备的计算资源和内存空间都非常有限,蒸馏版模型可以在这些设备上高效运行,实现语音控制、设备状态监测等功能。用户通过语音指令控制智能灯光的开关、调节智能空调的温度等操作,蒸馏版模型都能迅速响应并执行相应的操作,为用户提供便捷的智能家居体验。
(三)量化版:速度与精度的平衡
量化版通过量化技术,在推理速度上有着明显的优势。在移动端的图像识别应用中,当用户使用手机拍摄照片进行物体识别时,量化版模型能够在短时间内对图像进行分析和识别,快速返回识别结果,告知用户照片中的物体是什么。这使得用户能够在移动场景下快速获取所需信息,提高了应用的实用性。
在智能安防监控系统中,需要对大量的视频图像进行实时分析,检测异常行为和识别人员身份。量化版模型可以快速处理这些视频流数据,及时发现异常情况并发出警报。但由于量化技术降低了权重精度,在一些对精度要求极高的场景中,如医学影像分析、金融风险评估等,量化版模型可能会因为精度不足而出现一些偏差,需要进一步的优化和验证。
五、适用场景大剖析

(一)满血版:高端科研与企业需求
满血版 DeepSeek 凭借其强大的性能和无与伦比的推理能力,在科学研究、高级数据分析、自然语言生成等需要高度精确性和复杂推理的任务中表现出色,是对性能要求极高的企业和开发者的首选。
在科学研究领域,无论是医学领域对复杂疾病的发病机制研究、药物研发中的分子结构分析,还是物理学中对宇宙奥秘的探索、数学中对复杂理论的证明,满血版都能提供强大的计算和推理支持。在医学研究中,它可以对大量的医学数据进行深度分析,挖掘疾病与基因、环境等因素之间的潜在关系,为疾病的诊断和治疗提供新的思路和方法。在物理学研究中,面对复杂的物理模型和海量的实验数据,满血版能够快速进行模拟和计算,帮助科学家验证理论假设,推动科学的进步。
对于大型企业来说,满血版在处理复杂的业务场景时也具有不可替代的优势。在金融领域,它可以对全球金融市场的海量数据进行实时分析,预测市场趋势,评估投资风险,为企业的投资决策提供精准的支持。在企业的战略规划中,满血版可以对市场竞争态势、行业发展趋势、企业内部资源等多方面的信息进行综合分析,制定出科学合理的战略规划,助力企业在激烈的市场竞争中取得优势。
(二)蒸馏版:小型企业与实时响应场景
蒸馏版由于其参数规模较小,易于部署,适合在低计算资源环境中运行,因此在小型企业或嵌入式设备中的 AI 应用开发以及实时响应场景中有着广泛的应用。
对于小型企业来说,由于资金和技术资源有限,无法承担大规模的计算设备和复杂的模型部署。蒸馏版模型正好满足了他们的需求,它可以在小型企业的普通服务器上轻松运行,实现诸如智能客服、办公自动化等功能。在智能客服场景中,蒸馏版模型能够快速响应用户的咨询,解答常见问题,提高客户服务的效率,同时又不会对企业的硬件资源造成过大的压力。在办公自动化方面,它可以帮助企业实现文档处理、数据整理等工作的自动化,提高办公效率,降低人力成本。
在嵌入式设备中,如智能家居设备、智能穿戴设备等,由于设备的计算资源和内存空间都非常有限,蒸馏版模型的优势更加明显。在智能家居设备中,它可以实现语音控制、设备状态监测等功能。用户通过语音指令控制智能灯光的开关、调节智能空调的温度等操作,蒸馏版模型都能迅速响应并执行相应的操作,为用户提供便捷的智能家居体验。在智能穿戴设备中,它可以实时监测用户的健康数据,如心率、血压、睡眠质量等,并根据数据分析提供健康建议,为用户的健康管理提供支持。
(三)量化版:移动端与边缘设备的选择
量化版通过量化技术进一步压缩了模型大小,使其在移动端或边缘设备上的 AI 应用中具有独特的优势,适用于对模型大小和运行效率有严格要求的场景。
在移动端设备上,如手机、平板电脑等,由于设备的内存和计算资源有限,量化版模型可以轻松部署,实现各种智能应用。在智能语音助手应用中,量化版模型能够快速识别用户的语音指令,并给出相应的回答,满足用户在移动场景下的实时交互需求。在图像识别应用中,它可以快速对拍摄的照片进行分析和识别,实现图像分类、目标检测等功能,为用户提供便捷的图像服务。
在边缘设备上,如智能摄像头、工业机器人等,量化版模型也有着广泛的应用。在智能摄像头中,它可以实时对视频图像进行分析,检测异常行为、识别人员身份等,实现智能安防监控。在工业机器人中,它可以根据实时采集的数据进行快速决策和控制,提高生产效率和产品质量。由于量化版模型的推理速度快、能耗低,能够满足边缘设备对实时性和低功耗的要求,因此在边缘计算领域具有广阔的应用前景。
六、如何判断版本
(一)复杂问题测试法
在判断 DeepSeek 的版本时,复杂问题测试法是一种行之有效的方式。我们可以向模型提出需要大量推理能力的问题,比如八字排盘、复杂逻辑题等。以一道复杂的逻辑推理题为例:“在一个神秘的岛屿上,住着三个部落,分别是真话部落、假话部落和随机部落。真话部落的人总是说真话,假话部落的人总是说假话,随机部落的人有时说真话有时说假话。你遇到了三个人 A、B、C,A 说:‘B 是真话部落的。’B 说:‘C 是假话部落的。’C 说:‘A 是随机部落的。’请判断 A、B、C 分别来自哪个部落。”
满血版由于其强大的参数规模和卓越的推理能力,通常会有更长的思考时间,它会对问题进行深入的分析,逐步拆解问题的逻辑结构。它可能会先假设 A 来自不同的部落,然后根据各个部落的特点,对 B 和 C 的话语进行推理验证,最终给出详细的推理过程和准确的答案。而蒸馏版和量化版由于参数规模和推理能力的限制,可能无法像满血版那样全面、深入地分析问题,给出的答案可能不够准确或者推理过程不够完整。
(二)上下文长度测试法
上下文长度测试法也是判断版本的重要方法。我们可以输入较长的文本,观察模型是否能够完整记住上下文内容。例如,输入一篇包含多个人物、情节复杂的短篇小说,然后向模型提问关于小说中某个细节的问题,比如 “小说中在第二章出现的那个神秘人物后来怎么样了?”
满血版的上下文长度通常优于蒸馏版和量化版,它能够记住较长文本中的关键信息,并根据这些信息准确回答问题。它可以在大量的文本内容中准确找到与问题相关的部分,进行分析和解答。而蒸馏版和量化版由于模型大小和性能的限制,可能无法完整记住较长的上下文内容,在回答问题时可能会出现信息遗漏或者错误的情况,比如回答 “没有找到相关内容” 或者给出与小说情节不符的答案。
(三)输出质量对比法
输出质量对比法是一种直观的判断方法。我们可以对比相同问题在不同版本下的回答质量。比如提出问题 “如何制定一个全面的企业数字化转型战略?”
满血版的答案通常更准确、更全面。它会从多个维度进行分析,包括企业的现状评估、技术选型、组织架构调整、人才培养等方面,给出详细且具有可操作性的建议。它的语言表达也更加流畅、逻辑更加严谨,能够清晰地阐述各个要点之间的关系。而蒸馏版和量化版的回答可能会相对简略,在某些关键问题上的分析不够深入,或者在语言表达上存在一些瑕疵,比如表述不够清晰、逻辑不够连贯等。通过对比输出质量,我们可以较为直观地判断出模型的版本。
七、经典代码案例
以下是三个与 DeepSeek 相关的经典代码案例及其解释:
1. DeepSeek API 调用的 Java 示例
代码示例:java
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.ArrayList;
import java.util.List;
import com.google.gson.Gson;
public class DeepSeekClient {
private static String API_KEY;
private static String API_URL;
static {
Properties properties = new Properties();
try {
InputStream is = DeepSeekClient.class.getResourceAsStream("/config.properties");
properties.load(is);
API_KEY = properties.getProperty("key");
API_URL = properties.getProperty("url");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static String sendRequest(ChatRequest requestBody) {
HttpClient client = HttpClient.newHttpClient();
Gson gson = new Gson();
String requestBodyJson = gson.toJson(requestBody);
try {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(API_URL))
.header("Content-Type", "application/json")
.header("Authorization", "Bearer " + API_KEY)
.POST(BodyPublishers.ofString(requestBodyJson))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() == 200) {
ChatResponse chatResponse = gson.fromJson(response.body(), ChatResponse.class);
return chatResponse.getChoices().get(0).getMessage().getContent();
} else {
return "请求失败,状态码: " + response.statusCode() + ", 响应: " + response.body();
}
} catch (Exception e) {
e.printStackTrace();
return "请求异常: " + e.getMessage();
}
}
public static void ask(String content) {
List<Message> messages = new ArrayList<>();
messages.add(new Message("user", content));
ChatRequest requestBody = new ChatRequest(
"deepseek-chat",
messages,
0.7,
1000
);
System.out.println(">>>正在提交问题...");
long startTime = System.currentTimeMillis();
String response = sendRequest(requestBody);
long endTime = System.currentTimeMillis();
System.out.println("思考用时:" + (endTime - startTime) / 1000 + "秒");
System.out.println(response);
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String input = "";
System.out.println("*** 我是 DeepSeek ,很高兴见到您 ****");
while (true) {
System.out.println("---请说您问题:---");
String question = scanner.next();
if ("bye".equals(question)) {
break;
}
ask(question);
System.out.println();
}
System.out.println("拜拜,欢迎下次使用!");
}
}代码解释:
-
配置文件加载:通过
config.properties文件加载 API 密钥和 URL。 -
请求体构建:使用
ChatRequest类构建请求体,包含模型名称、消息列表、温度参数和最大 token 数。 -
发送请求:使用
HttpClient发送 POST 请求到 DeepSeek API,并处理响应。 -
多轮对话:通过循环接收用户输入,构建消息列表,实现多轮对话功能。
2. DeepSeek API 调用的 Python 示例
代码示例:Python
import requests
import json
API_ENDPOINT = "https://api.deepseek.com/v1/chat/completions"
API_KEY = "your_api_key" # 替换为你自己的 API 密钥
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
messages = []
while True:
user_input = input("你:")
if user_input.lower() == "退出":
break
messages.append({"role": "user", "content": user_input})
data = {
"messages": messages
}
response = requests.post(API_ENDPOINT, headers=headers, data=json.dumps(data))
if response.status_code == 200:
result = response.json()
reply = result["choices"][0]["message"]["content"]
messages.append({"role": "assistant", "content": reply})
print("DeepSeek:", reply)
else:
print(f"请求失败,状态码:{response.status_code},错误信息:{response.text}")代码解释:
-
初始化消息列表:使用
messages列表存储对话历史。 -
循环处理用户输入:通过
while循环不断接收用户输入,直到用户输入“退出”为止。 -
发送请求:使用
requests.post方法发送 POST 请求,包含用户输入的消息列表。 -
处理响应:如果请求成功,提取 DeepSeek 的回复并打印;否则,打印错误信息。
3. 动态规划解决 0/1 背包问题
代码示例:cpp
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> weight = {2, 3, 4, 5};
vector<int> value = {3, 4, 5, 6};
int bagweight = 8;
int n = weight.size();
vector<vector<int>> dp(n + 1, vector<int>(bagweight + 1, 0));
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= bagweight; j++) {
if (j < weight[i - 1]) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i - 1]] + value[i - 1]);
}
}
}
cout << "最大价值为: " << dp[n][bagweight] << endl;
return 0;
}代码解释:
-
初始化与遍历:定义物品重量
weight、物品价值value和背包容量bagweight,并初始化二维动态规划数组dp。 -
外层循环:遍历每个物品。
-
内层循环:遍历背包容量从 0 到
bagweight。 -
状态转移方程:如果当前容量小于物品重量,则不放入该物品;否则,选择放入或不放入该物品,取最大价值。
-
输出结果:最终
dp[n][bagweight]即为最大价值。
4. postman调用DeepSeek官方API
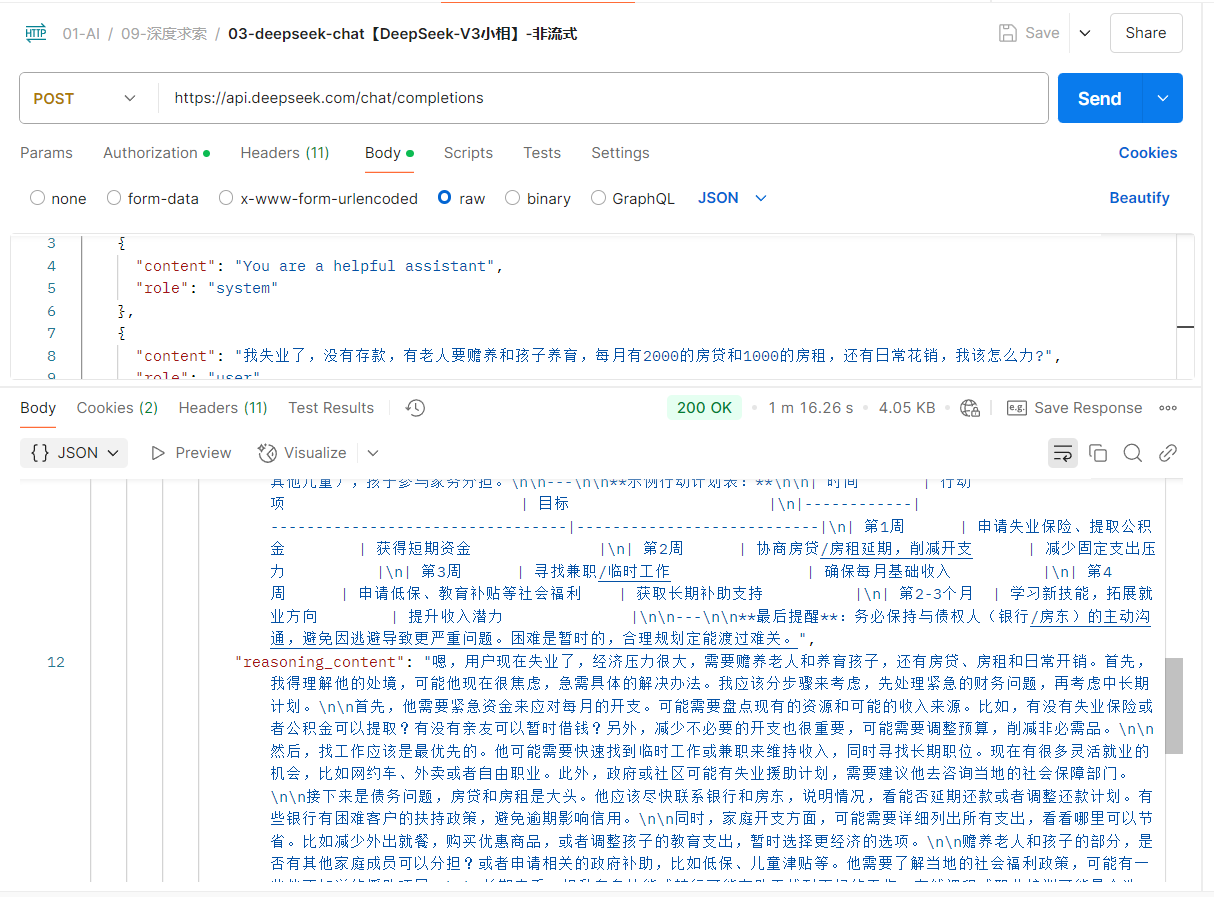
请求地址(post):
https://api.deepseek.com/chat/completions请求验证:Authorization Bearer Token
Token=**************,具体值到DeepSeek官方渠道下申请,地址:DeepSeek
请求参数(Body raw JSON):
{
"messages": [
{
"content": "You are a helpful assistant",
"role": "system"
},
{
"content": "我失业了,没有存款,有老人要赡养和孩子养育,每月有2000的房贷和1000的房租,还有日常花销,我该怎么力?",
"role": "user"
}
],
"model": "deepseek-reasoner",
"frequency_penalty": 0,
"max_tokens": 2048,
"presence_penalty": 0,
"response_format": {
"type": "text"
},
"stop": null,
"stream": false,
"stream_options": null,
"temperature": 1,
"top_p": 1,
"tools": null,
"tool_choice": "none",
"logprobs": false,
"top_logprobs": null
}返回结果:
{
"id": "d7c6de85-51c4-41fb-b09d-1fb7644a53f2",
"object": "chat.completion",
"created": 1740482973,
"model": "deepseek-reasoner",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "面对失业带来的经济压力,确实需要冷静应对并采取分步骤的措施。以下是针对你情况的详细建议,分为紧急应对、开源节流、资源利用和长期规划四个部分:\n\n---\n\n### **一、紧急应对措施(1个月内)**\n1. **盘点现有资金与负债** \n - 列出所有存款、可变现资产(如闲置物品)、每月固定支出(房贷2000+房租1000+日常开销),明确资金缺口。\n - 优先确保家庭基本生活费和房贷/房租,避免信用记录受损。\n\n2. **申请失业保险与公积金** \n - 若曾缴纳社保,立即办理失业登记,领取失业保险金(各地标准不同,通常为当地最低工资的70%-90%)。\n - 提取住房公积金(失业或生活困难时可申请,需咨询当地公积金中心)。\n\n3. **协商延期还款** \n - **房贷**:联系银行说明情况,申请延期还贷(多数银行提供3-6个月宽限期,需提交失业证明)。\n - **房租**:与房东沟通,请求短期减免或分期支付,提供失业证明增加说服力。\n\n4. **寻求亲友支援** \n - 短期借款缓解燃眉之急,明确还款计划以维护信任。\n\n---\n\n### **二、开源:增加收入来源(1-3个月)**\n1. **快速就业与兼职** \n - 优先寻找可快速上岗的工作:快递、外卖、网约车、小时工等(日结或周结工资)。\n - 利用技能接零活:如设计、写作、翻译(平台:猪八戒网、Upwork)、家教等。\n\n2. **申请政府与社会援助** \n - **低保**:若家庭人均收入低于当地标准,申请最低生活保障。\n - **专项补贴**:如老人高龄津贴、儿童营养补贴、教育补助(咨询社区街道办)。\n - **公益性岗位**:政府为困难群体提供的托底就业岗位(如社区服务)。\n\n3. **灵活利用资源创收** \n - 出租闲置房间或车位(若可行)。\n - 通过二手平台(闲鱼、转转)出售闲置物品。\n\n---\n\n### **三、节流:削减非必要支出**\n1. **精简家庭开支** \n - **饮食**:减少外食,选择平价超市、社区团购,关注折扣商品。\n - **日用**:暂停非必需消费(如订阅服务、娱乐支出),改用平价替代品。\n - **教育**:与学校沟通暂缓兴趣班费用,利用免费教育资源(国家中小学智慧教育平台)。\n\n2. **调整还款计划** \n - 与银行协商降低房贷利率或转为“只还利息”模式,减少月供压力。\n\n---\n\n### **四、中长期规划(3-6个月)**\n1. **提升就业竞争力** \n - 学习免费技能课程(网易云课堂、Coursera),关注紧缺行业(如养老护理、电商运营)。\n - 考取短期证书(如电工、育婴师),拓宽就业选择。\n\n2. **探索可持续收入模式** \n - 结合兴趣与市场需求,尝试副业(如自媒体、社区团购团长)。\n - 若老人能协助照料孩子,可考虑夫妻双方轮流工作+兼职。\n\n3. **建立应急储备金** \n - 未来收入恢复后,优先存储3-6个月生活费,防范风险。\n\n---\n\n### **五、心理与家庭支持**\n- **情绪管理**:与家人坦诚沟通压力,避免焦虑影响决策;寻求公益心理咨询(如社区服务热线)。\n- **家庭协作**:动员有能力的老人参与简单创收(如手工活、看护其他儿童),孩子参与家务分担。\n\n---\n\n**示例行动计划表:**\n\n| 时间 | 行动项 | 目标 |\n|------------|---------------------------------|---------------------------|\n| 第1周 | 申请失业保险、提取公积金 | 获得短期资金 |\n| 第2周 | 协商房贷/房租延期,削减开支 | 减少固定支出压力 |\n| 第3周 | 寻找兼职/临时工作 | 确保每月基础收入 |\n| 第4周 | 申请低保、教育补贴等社会福利 | 获取长期补助支持 |\n| 第2-3个月 | 学习新技能,拓展就业方向 | 提升收入潜力 |\n\n---\n\n**最后提醒**:务必保持与债权人(银行/房东)的主动沟通,避免因逃避导致更严重问题。困难是暂时的,合理规划定能渡过难关。",
"reasoning_content": "嗯,用户现在失业了,经济压力很大,需要赡养老人和养育孩子,还有房贷、房租和日常开销。首先,我得理解他的处境,可能他现在很焦虑,急需具体的解决办法。我应该分步骤来考虑,先处理紧急的财务问题,再考虑中长期计划。\n\n首先,他需要紧急资金来应对每月的开支。可能需要盘点现有的资源和可能的收入来源。比如,有没有失业保险或者公积金可以提取?有没有亲友可以暂时借钱?另外,减少不必要的开支也很重要,可能需要调整预算,削减非必需品。\n\n然后,找工作应该是最优先的。他可能需要快速找到临时工作或兼职来维持收入,同时寻找长期职位。现在有很多灵活就业的机会,比如网约车、外卖或者自由职业。此外,政府或社区可能有失业援助计划,需要建议他去咨询当地的社会保障部门。\n\n接下来是债务问题,房贷和房租是大头。他应该尽快联系银行和房东,说明情况,看能否延期还款或者调整还款计划。有些银行有困难客户的扶持政策,避免逾期影响信用。\n\n同时,家庭开支方面,可能需要详细列出所有支出,看看哪里可以节省。比如减少外出就餐,购买优惠商品,或者调整孩子的教育支出,暂时选择更经济的选项。\n\n赡养老人和孩子的部分,是否有其他家庭成员可以分担?或者申请相关的政府补助,比如低保、儿童津贴等。他需要了解当地的社会福利政策,可能有一些他不知道的援助项目。\n\n长期来看,提升自身技能或转行可能有助于找到更好的工作。在线课程或职业培训可能是个选择,但短期内可能无法解决经济压力,所以需要结合短期和长期的策略。\n\n另外,心理压力也不能忽视,失业带来的焦虑可能影响决策,建议他保持积极心态,寻求家人或朋友的支持,必要时找心理咨询服务。\n\n可能还有其他方面需要考虑,比如变卖闲置物品,或者利用自己的特长赚取额外收入。总之,需要综合多方面的资源和策略来应对当前的危机。"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 47,
"completion_tokens": 1373,
"total_tokens": 1420,
"prompt_tokens_details": {
"cached_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 399
},
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 47
},
"system_fingerprint": "fp_5417b77867_prod0225"
}
八、总结与展望
(一)总结展望
DeepSeek 的量化版、蒸馏版和满血版在参数规模、性能表现和适用场景上各有千秋。满血版凭借庞大参数和强大性能,成为高端科研和大型企业复杂任务的首选;蒸馏版以其灵活的参数规模和在资源受限环境中的出色表现,满足了小型企业和实时响应场景的需求;量化版则通过量化技术实现了模型大小和推理速度的优化,在移动端和边缘设备上展现出独特优势。
在实际应用中,用户应根据自身的需求、硬件资源和预算等因素,综合考虑选择最适合的版本。如果是进行复杂的科研项目或对精度要求极高的企业级应用,满血版无疑是最佳选择;若在资源有限的环境中追求快速响应,蒸馏版则更为合适;而对于移动端和边缘设备的应用,量化版则能提供高效的解决方案。
随着人工智能技术的不断发展,我们有理由期待 DeepSeek 在未来能够推出更多创新的版本,进一步提升性能、降低成本,为更多领域和用户带来更加优质、高效的 AI 服务。相信在不久的将来,DeepSeek 将在人工智能的舞台上绽放出更加耀眼的光芒,推动整个行业迈向新的高度。
(二)总结对比表
| 版本 | 参数规模 | 性能表现 | 适用场景 | 部署成本 | 响应速度 |
|---|---|---|---|---|---|
| 满血版 | 6710亿参数 | 复杂推理能力强,支持详细思考过程 | 科研、高级数据分析、自然语言生成 | 高 | 较慢 |
| 蒸馏版 | 1.5B~32B | 推理能力适中,无详细思考过程 | 小型企业、实时交互场景 | 中 | 快 |
| 量化版 | 压缩后的小模型 | 推理速度快,精度略有下降 | 移动端、边缘设备 | 低 | 很快 |

感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对[Windows+docker本地部署DeepSeek-R1]有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[Windows+docker本地部署DeepSeek-R1]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝您拥有美好的一天!

博主还写了本文相关文章,欢迎大家批评指正:
一、技术解析篇(共3篇)
1、深度揭秘DeepSeek:核心技术架构剖析与未来展望(1/18)
2、DeepSeek模型:从压缩到实战,性能飞升全攻略(2/18)
3、解锁DeepSeek多模态:从原理到实战全解析(3/18)
二、实战应用篇(共4篇)
1、DeepSeek与PyTorch携手:开启工业缺陷检测新时代(4/18)
2、DeepSeek赋能智能客服:技术革新与体验升级(5/18)
3、DeepSeek金融风控实战:反欺诈模型的进阶之路(6/18)
4、DeepSeek开启游戏AI开发新纪元:实战攻略与创新应用(7/18)
三、行业解决方案篇(共3篇)
1、DeepSeek医疗影像诊断:从数据到模型的落地密码(8/18)
2、DeepSeek 智慧城市应用:交通流量预测(9/18)
3、DeepSeek:开启AIGC全链路内容创作新时代(10/18)
预知下节如何,请等待下次更新,正在加鞭快马撰写中......
四、工具链与生态篇(共3篇)
1、DeepSeek Studio:开启可视化AI开发新时代(11/18)
2、《DeepSeek Model Zoo:预训练模型选型指南》
3、《DeepSeek与Kubernetes:大规模训练集群管理》
五、进阶优化篇(共3篇)
1、《DeepSeek模型蒸馏黑科技:精度无损压缩50%》
2、《DeepSeek+ONNX:跨平台部署终极方案》
3、《DeepSeek超参优化实战:AutoML调参全解析》
六、趋势与展望篇(共2篇)
1、《DeepSeek技术演进:从大模型到AGI的路径探索》
2、《DeepSeek开发者生态:从使用到贡献的成长之路》
七、拓展知识
2、DeepSeek开启程序员副业增收新通道,财富密码大公开!
3、手把手教你在Windows+docker本地部署DeepSeek-R1
6、AI新势力!蓝耘DeepSeek满血版登场,500万tokens免费开薅
7、DeepSeek三大版本大揭秘:量化、蒸馏、满血,谁才是你的菜?


















 6825
6825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











