







《FACTS About Building Retrieval Augmented Generation-based Chatbots》是2024年7月英伟达的团队发表的基于RAG的聊天机器人构建的文章。
这篇论文在待读列表很长时间了,一直没有读,看题目以为FACTS是总结的一些事实经验,阅读过才发现FACTS是论文定义的RAG-based chatbots的五个维度:freshness (F), architectures(A), cost economics of LLMs ©, testing (T), security (S)的缩写。
论文说在英伟达内部用RAG和LLM构建三个chatbot,如论文表1所示。基于这些chatbot构建经验总结了一套方法论。

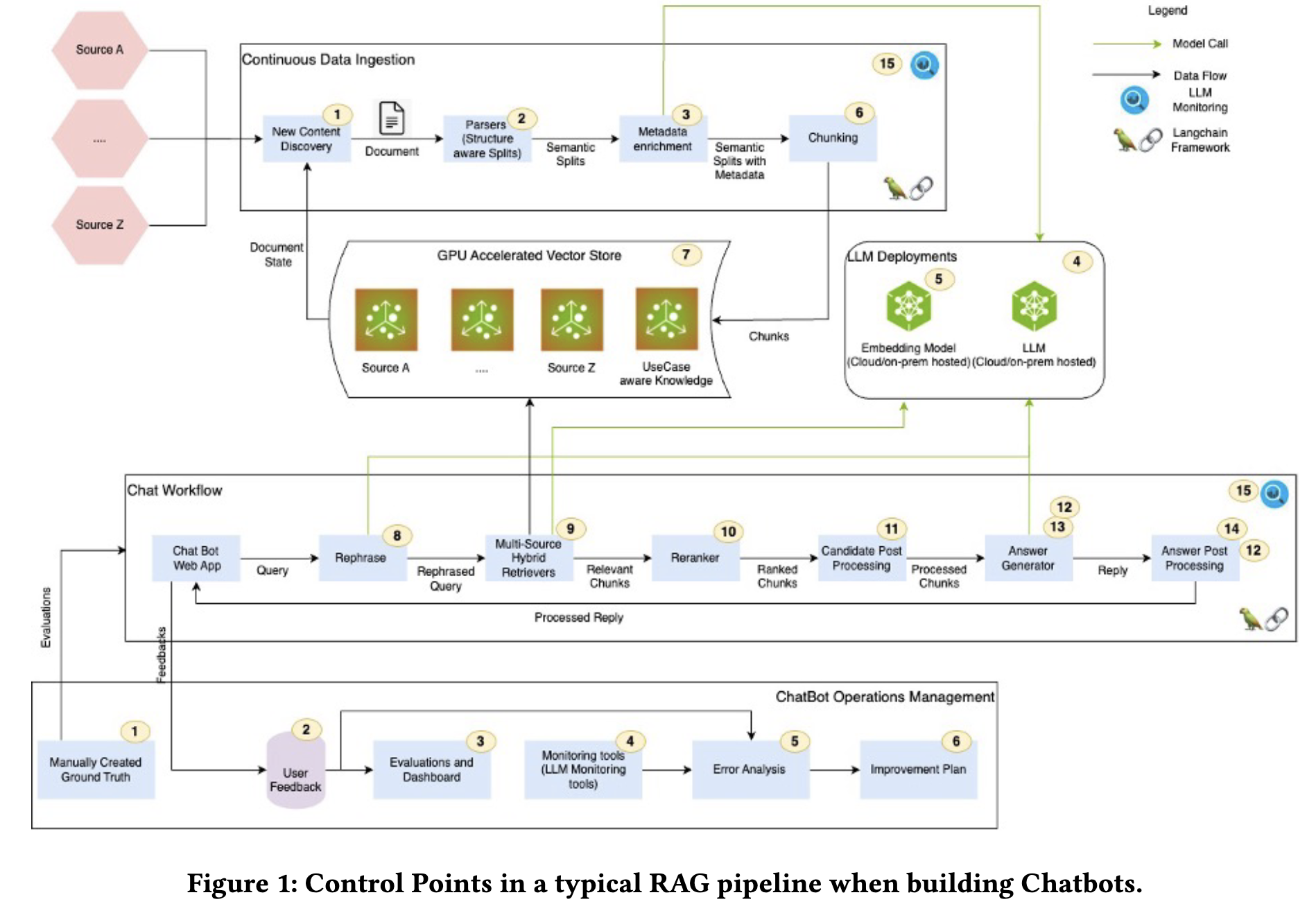
这两年RAG很火,但是构建好一个基于RAG的聊天机器人并不是件易事,要考虑RAG流程的工程化、微调LLM、prompt engineering、保证召回知识的相关性和准确性、文件访问控制、生成精确的回复并包括参考资料以及保护个人敏感信息等等。因此论文总结了如论文图1和图4所示的15个RAG流程中的控制点(吐槽一下论文中所有的图片都不够清晰)。

为了避免在公司内部重复地开发一些构建chatbot需要的功能如安全、护栏等,开发了如论文图7所示可插拔架构的模块化平台NVbot。平台支持domain-specific, enterprise-wide, copilot三种不同的chatbot变体。

一些论文提到的细节:
- 为了提高检索相关度:进行了Metadata增强、查询改写、使用grid-search方法来寻找合适chunk大小、测试不同的chunk rerank策略等;使用混合搜索(Lexical search+向量搜索)。
- 对于一些复杂问题,比如“compare the revenue of NVIDIA from Q1 through Q4 of FY2024 and provide an analytical commentary on the key contributing factors that led to the changes in revenues during this time”,要使用agent或multi-agent架构才能回答出来,论文使用了如图2所示的将一个问题拆成多个问题的agent方式。

- 微调Llama3-70B后在保持可接受的延迟下可得到挺不错的答案质量

- Unstructured.io等专门从PDF中提取结构化内容的工具有助于解析和分块非结构文化。如果文档的结构固定比如SEC相关的文档,使用section-level的分割,用section title和subheading来分割并将它们加入到chunk的上下文有助于提升检索相关性。
- 使用RAGOps/LLMOps监控工具来监控RAG流程,使用如Ragas等评估框架。
- 用内部LLM Gateway来统一管理使用的商用LLM API,可以简化LLM使用、订阅和数据跟踪的安全审计。
- 包含安全测试、prompt修改测试、反馈回路等用来测试chatbot的手段。
- chatbots的数据访问有Access Control Lists (ACLs),用Nemo Guardrail对输入和输出进行处理。
总结:这篇论文介绍了基于RAG的chatbot的五个维度,论文按照这五个维度列举了一些经验,可以对照看看有哪些自己在开发过程中没有考虑过的点,不过总体来讲论文在详细实现上讨论的不够多。

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









