







 本文详细介绍了MobileNetV2的结构特点,包括倒残差结构和线性瓶颈层,并提供了PyTorch实现代码。此外,文章还探讨了MobileNetV2在CenterNet目标检测任务中的应用效果。
本文详细介绍了MobileNetV2的结构特点,包括倒残差结构和线性瓶颈层,并提供了PyTorch实现代码。此外,文章还探讨了MobileNetV2在CenterNet目标检测任务中的应用效果。
本文参考:
轻量级网络——MobileNetV2_Clichong的博客-CSDN博客_mobilenetv2
1、MobileNetV2介绍
MobileNetV1主要是提出了可分离卷积的概念,大大减少了模型的参数个数,从而缩小了计算量。但是在CenterNet算法中作为BackBone效果并不佳,模型收敛效果不好导致目标检测的准确率不高。
MobileNetV2在MobileNetV1的DW和PW的基础上进行了优化,使得准确率更高,作为CenterNet算法的BackBone效果也可以。它的两个亮点是:
- Inverted Residuals:倒残差结构
- Linear Bottlenecks:结构的最后一层采用线性层
2、MobileNetV2的结构
(1)倒残差结构
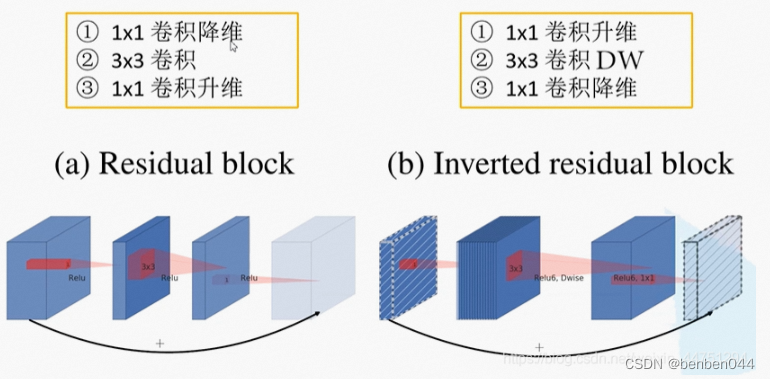
ResNet网络:残差结构是先用1*1卷积降维 再升维 的操作,所以两头大中间小。
MobileNetV2中,残差结构是先用1*1卷积升维 再降维 的操作,所以两头小中间大。
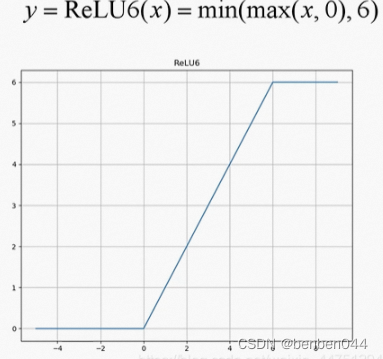
在MobileNetV2中采用了新的激活函数:ReLU6,它的定义如下:
(2)线性Bottlenecks
针对倒残差结构最后一层的卷积层,采用了线性的激活函数(f(x)=x,可以认为没有激活函数),而不是使用ReLU6激活函数。
原因解释:

ReLU激活函数对于低维的信息可能会造成比较大的损失,而对于高维的特征信息造成的损失很小。而且由于倒残差结构是两头小中间大,所以输出的是一个低维的特征信息。所以使用一个线性的激活函数避免特征损失。
低维解释:低维针对的是channel,低维意味着[batch, channel, height, width]中的height和width还较大。
(3)整体结构
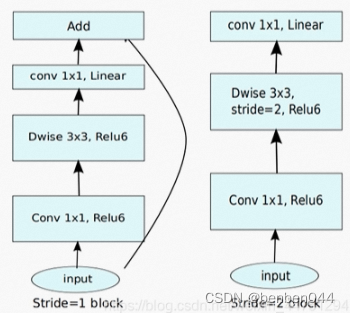
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut链接。
3、MobileNetV2的pytorch实现
import torch
import torch.nn as nn
import torchvision
# 分类个数
num_class = 5
# DW卷积
def Conv3x3BNReLU(in_channels, out_channels, stride, groups):
return nn.Sequential(
# stride=2,wh减半; stride=1,wh不变
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1, groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# PW卷积
def Conv1x1BNReLU(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# PW卷积(Linear)没有使用激活函数
def Conv1x1BN(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
class InvertedResidual(nn.Module):
# t为扩展因子
def __init__(self, in_channels, out_channels, expansion_factor, stride):
super(InvertedResidual, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
mid_channels = (in_channels * expansion_factor)
# 先1*1卷积升维,再1*1卷积降维
self.bottleneck = nn.Sequential(
# 升维操作
Conv1x1BNReLU(in_channels, mid_channels),
# DW卷积,降低参数量
Conv3x3BNReLU(mid_channels, mid_channels, stride, groups=mid_channels),
# 降维操作
Conv1x1BN(mid_channels, out_channels)
)
# stride=1才有shortcut,此方法让原本不相同的channels相同
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
out = self.bottleneck(x)
out = (out + self.shortcut(x)) if self.stride == 1 else out
return out
class MobileNetV2(nn.Module):
def make_layer(self, in_channels, out_channels, stride, factor, block_num):
layers = []
layers.append(InvertedResidual(in_channels, out_channels, factor, stride))
for i in range(block_num):
layers.append(InvertedResidual(out_channels, out_channels, factor, 1))
return nn.Sequential(*layers)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def __init__(self, num_classes=num_class, t=6):
super(MobileNetV2, self).__init__()
self.first_conv = Conv3x3BNReLU(3, 32, 2, groups=1)
# 32 -> 16 stride=1 wh不变
self.layer1 = self.make_layer(in_channels=32, out_channels=16, stride=1, factor=1, block_num=1)
# 16 -> 24 stride=2 wh减半
self.layer2 = self.make_layer(in_channels=16, out_channels=24, stride=2, factor=t, block_num=2)
# 24 -> 32 stride=2 wh减半
self.layer3 = self.make_layer(in_channels=24, out_channels=32, stride=2, factor=t, block_num=3)
# 32 -> 64 stride=2 wh减半
self.layer4 = self.make_layer(in_channels=32, out_channels=64, stride=2, factor=t, block_num=4)
# 64 -> 96 stride=1 wh不变
self.layer5 = self.make_layer(in_channels=64, out_channels=96, stride=1, factor=t, block_num=3)
# 96 -> 160 stride=2 wh减半
self.layer6 = self.make_layer(in_channels=96, out_channels=160, stride=2, factor=t, block_num=3)
# 160 -> 320 stride=1 wh不变
self.layer7 = self.make_layer(in_channels=160, out_channels=320, stride=1, factor=t, block_num=1)
# 320 -> 1280 单纯的升维操作
self.last_conv = Conv1x1BNReLU(320, 1280)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.dropout = nn.Dropout2d(p=0.2)
self.linear = nn.Linear(in_features=1280, out_features=num_classes)
self.init_params()
def forward(self, x):
x = self.first_conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.last_conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.linear(x)
return x
if __name__ == '__main__':
model = MobileNetV2()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)4、MobileNetV2作为CenterNet的BackBone
import torch
import torch.nn as nn
# DW卷积
def Conv3x3BNReLU(in_channels, out_channels, stride, groups):
return nn.Sequential(
# stride=2,wh减半; stride=1,wh不变
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1, groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# PW卷积
def Conv1x1BNReLU(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# PW卷积(Linear)没有使用激活函数
def Conv1x1BN(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
class InvertedResidual(nn.Module):
# t为扩展因子
def __init__(self, in_channels, out_channels, expansion_factor, stride):
super(InvertedResidual, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
mid_channels = (in_channels * expansion_factor)
# 先1*1卷积升维,再1*1卷积降维
self.bottleneck = nn.Sequential(
# 升维操作
Conv1x1BNReLU(in_channels, mid_channels),
# DW卷积,降低参数量
Conv3x3BNReLU(mid_channels, mid_channels, stride, groups=mid_channels),
# 降维操作
Conv1x1BN(mid_channels, out_channels)
)
# stride=1才有shortcut,此方法让原本不相同的channels相同
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
out = self.bottleneck(x)
out = (out + self.shortcut(x)) if self.stride == 1 else out
return out
class MobileNetV2(nn.Module):
def make_layer(self, in_channels, out_channels, stride, factor, block_num):
layers = []
layers.append(InvertedResidual(in_channels, out_channels, factor, stride))
for i in range(block_num):
layers.append(InvertedResidual(out_channels, out_channels, factor, 1))
return nn.Sequential(*layers)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def __init__(self, heads, t=6):
super(MobileNetV2, self).__init__()
num_classes = heads['hm']
self.first_conv = Conv3x3BNReLU(3, 32, 2, groups=1)
# 32 -> 16 stride=1 wh不变
self.layer1 = self.make_layer(in_channels=32, out_channels=16, stride=1, factor=1, block_num=1)
# 16 -> 24 stride=2 wh减半
self.layer2 = self.make_layer(in_channels=16, out_channels=24, stride=2, factor=t, block_num=2)
# 24 -> 32 stride=2 wh减半
self.layer3 = self.make_layer(in_channels=24, out_channels=32, stride=2, factor=t, block_num=3)
# 32 -> 64 stride=2 wh减半
self.layer4 = self.make_layer(in_channels=32, out_channels=64, stride=2, factor=t, block_num=4)
# 64 -> 96 stride=1 wh不变
self.layer5 = self.make_layer(in_channels=64, out_channels=96, stride=1, factor=t, block_num=3)
# 96 -> 160 stride=2 wh减半
self.layer6 = self.make_layer(in_channels=96, out_channels=160, stride=2, factor=t, block_num=3)
# 160 -> 320 stride=1 wh不变
self.layer7 = self.make_layer(in_channels=160, out_channels=320, stride=1, factor=t, block_num=1)
# 320 -> 1280 单纯的升维操作
self.last_conv = Conv1x1BNReLU(320, 1280)
self.init_params()
self.hm = nn.Conv2d(20, num_classes, kernel_size=1)
self.wh = nn.Conv2d(20, 2, kernel_size=1)
self.reg = nn.Conv2d(20, 2, kernel_size=1)
def forward(self, x):
x = self.first_conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.last_conv(x)
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
return [z]
if __name__ == '__main__':
heads = {'hm': 10, 'wh': 2, 'reg': 2}
model = MobileNetV2(heads)
input = torch.randn(1, 3, 512, 512)
out = model(input)
print(out.shape)5、MobileNetV2在CenterNet目标检测落地情况
(1)训练情况
训练loss,mobilenetV1在batch_size=16时最少达到4.0左右,而mobileNetV2在batch_size=16时最少达到0.5以下。与DLASeg的效果基本接近。
(2)目标检测效果

检测效果也与DLASeg基本接近
(3)模型参数量
DLASeg为2000W个左右
MobileNetV1为320W个左右
MobileNetV2为430W个左右,总模型大小为17M
(4)CPU运行时间
DLASeg为1.2s
MobileNetV1为250ms
MobileNetV2为600ms

















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









