








多模态大模型的训练技巧是当前人工智能领域的重要研究方向,其核心在于如何高效地整合和处理来自不同模态(如文本、图像、视频等)的数据,并通过优化模型结构和训练策略来提升模型的性能。以下是基于我搜索到的资料总结的多模态大模型训练技巧:
1. 训练流程与阶段
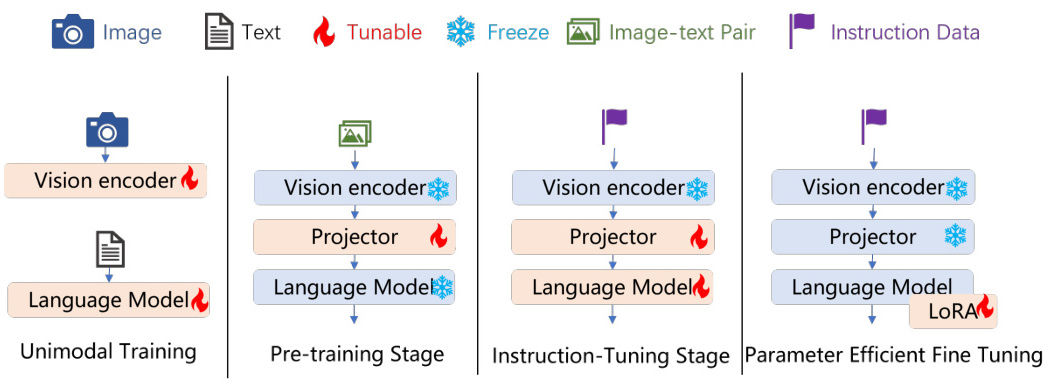
多模态大模型的训练通常分为多个阶段,包括单模态训练、预训练和指令调优等关键步骤:
-
单模态训练:分别对不同模态(如图像或文本)进行独立训练,以优化每个模态的编码器或解码器。
-
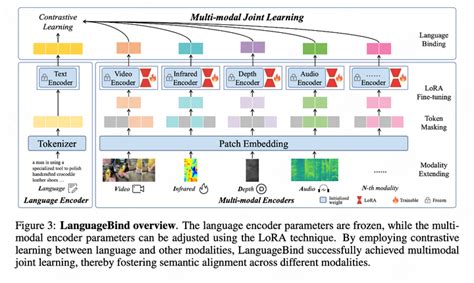
预训练:通过大规模数据集(如X-Text数据集)进行多模态联合训练,使模型能够处理多种模态输入并实现跨模态对齐。
-
指令调优:在预训练的基础上,通过指令数据进一步微调模型,使其更好地适应特定任务。
2. 训练方法
多模态大模型的训练方法主要包括以下几种:
- 联合训练:将不同模态的数据同时输入模型,使模型能够同时学习不同模态的特征。
- 级联训练:先对某一模态的数据进行训练,然后将训练结果传递给其他模态,逐步融合不同模态的特征。
- 迁移学习:在已有大规模预训练模型的基础上,针对特定任务进行微调,提高模型的效率和效果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











