







Bag of features : 图像特征词典
摘要:
- 基础流程及原理
- 第一部分实验(书中数据集)
- 第二部分实验(自己的数据集)
基础流程
- 特征提取

- 学习“视觉词典”

这一步的流程是通过K-means算法找到聚类中心:
K-means聚类算法实现visual vocabulary/codebook的关键
其中,聚类算法获得的聚类中心作为codevector(视觉单词),一旦训练集准备的足够充分,训练出来的码本将具有灵活性。
K-means算法的基本流程:
1.初始化K个聚类中心
2.重复下述步骤直至算法收敛:
2.1. 对应每个特征,根据距离关键赋值给某个中心/类别
2.1. 对每个类别,根据其对应的特征集重新计算聚类中心
-
针对输入特征集,根据视觉词典进行量化
对于输入特征,量化的过程是将该特征映射到距离其最接近的codevector,并实现计数。
要注意选择码本的规模。若码本太少:视觉单词无法覆盖所有可能出现的情况;若太多了:计算量过大,并且容易过拟合。 -
把输入图像转化成视觉单词的频率直方图

-
图像检索
对于给定图像的直方图,在数据库查找k个最近的图像。
对于图像分类的问题,可以根据这k个临近图像的分类标签投票获得分类结果。
当训练数据足以表述所有图像的时候,检索或者分类的效果会比较好。 -
倒排表(Inverted file)
前面的方法是根据每张图像和码本的匹配程度来构建每张图的直方图,而倒排表存储的是符合各个视觉单词的图像集。这样数据库中的图片可以通过比较重叠部分来判断它和哪些图片存在关联。

所以图像检索的流程可以总结为以下这样的过程:
- 特征提取。
- 学习“视觉词典”。
- 针对输入特征集,根据视觉词典进行量化。
- 根据TF-IDF,把输入图像转化成视觉单词的直方图。
- 构造特征到图像的倒排表,通过倒排表快速索引相关图像。
- 根据索引结果进行直方图匹配。
第一部分实验
跑通代码
那么对上述过程进行实验:
提取特征值:
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])

生成视觉词典:
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
其中train()函数就是上文提到的,用k-means算法进行聚类,得到聚类中心,生成词汇表的过程。
#train()函数
def train(self,featurefiles,k=100,subsampling=10):
""" Train a vocabulary from features in files listed
in featurefiles using k-means with k number of words.
Subsampling of training data can be used for speedup. """
nbr_images = len(featurefiles)
# read the features from file
descr = []
descr.append(sift.read_features_from_file(featurefiles[0])[1])
descriptors = descr[0] #stack all features for k-means
for i in arange(1,nbr_images):
descr.append(sift.read_features_from_file(featurefiles[i])[1])
descriptors = vstack((descriptors,descr[i]))
# k-means: last number determines number of runs
self.voc,distortion = kmeans(descriptors[::subsampling,:],k,1)#K-means算法
self.nbr_words = self.voc.shape[0]
# go through all training images and project on vocabulary
imwords = zeros((nbr_images,self.nbr_words))
for i in range( nbr_images ):
imwords[i] = self.project(descr[i])
nbr_occurences = sum( (imwords > 0)*1 ,axis=0)
self.idf = log( (1.0*nbr_images) / (1.0*nbr_occurences+1) )
self.trainingdata = featurefiles
#生成单词的柱状图
def project(self,descriptors):
""" Project descriptors on the vocabulary
to create a histogram of words. """
# histogram of image words
imhist = zeros((self.nbr_words))
words,distance = vq(descriptors,self.voc)
for w in words:
imhist[w] += 1
return imhist
建立图片的数据库:
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
查询:
有两种方式
- 常规查询(使用欧式距离)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]


2. 用单应性进行拟合建立RANSAC模型
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]


两种方式在这一个实验集中得到的结果是完全相同的。
第二部分实验
为了测试这个算法的效果,我找了以下这样的一组图片。图片中的人都来自一些男团成员,有句话说的好,丑的人各有各的丑法(QAQ),但是长得好的都是相似的。所以在这些乍一眼看上去都有点相似的人中,该算法的区分效果如何呢?
这是测试图片(共108张,图片皆来自微博和Twitter):

先来个简单的,这里特征最明显的黄发小哥:

匹配结果:

1234678都是对的,第五张是错的。
两种匹配结果都是一样的。
再来个稍微难一点的:
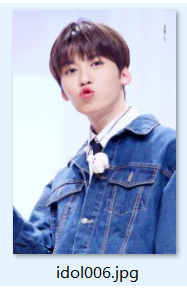
匹配结果:

1234张都是对的,第五张错误。
两种匹配都是一样的结果。
从上面的实验来看,算法还是完成了基本的匹配,但是在下面这个小哥的身上,算法遭遇了滑铁卢:
选了这张图:

匹配结果:

这里面总共有5个不一样的人,只有第五张和第八张是匹配正确的。
因为第一个黄发小哥的图片较多,训练的效果比较好。适逢他近日换了新的发色,那来测试一下如果头发颜色不同是否还能识别出同一个人:
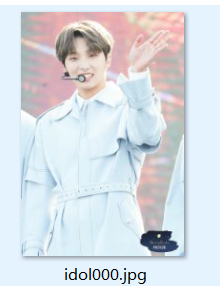
结果:

12358都是对的,其他几张错误。排在前几的匹配项都是准确的人。匹配错的人也是比较相似的。
总结的来说,我认为下面两种情况的照片匹配效果是最好的:
- 图片特征明显的,例如第一张黄发小哥。可以看见即使在第三次测试中那样乱七八糟的匹配结果中,也没有出现他的身影。后面换了发色也依旧能识别出。
- 图片数量较多的,例如前两张图片中的人,都是在数据集中出现次数较多的,训练的效果就好。而像其他人,在数据集中本来就出现的少,训练效果较差,所以有一点点相同的特征就会被匹配到同一类中。例如,仅仅是衣服颜色或者头发颜色相似。
训练效果的好坏直接影响整个算法的识别正确率。而影响训练效果的因素主要有图片的数量和图片特征的差距,对于第二组实验如果有更多的数据集,对于其他人的匹配效果肯定也是和前两位的效果差不多。
但是对于发型和脸型都较为相似的情况,区分起来还是有些难度的。也就是说算法中选择的码本,无法区分出人脸中相似的部分,有的时候可能都有黄色的皮肤和都有黑色的衣服,就把他们归为同一类处理了。
代码中提供了两种匹配的方式,一个是用欧氏距离,一个是用单应性拟合。但是在实验的所有的过程中这两种方式的结果都是一样的,所以也无法比较两种方式的优劣。















 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









