







 本文探讨了神经网络深度增加导致的退化现象,焦点在于ResNet如何通过恒等映射和残差模块避免这一问题。通过介绍身份映射和ResNet结构,展示了如何构建深层网络并提升性能。提及了VGG和ResNet的区别,以及bottleneck结构的应用。
本文探讨了神经网络深度增加导致的退化现象,焦点在于ResNet如何通过恒等映射和残差模块避免这一问题。通过介绍身份映射和ResNet结构,展示了如何构建深层网络并提升性能。提及了VGG和ResNet的区别,以及bottleneck结构的应用。
神经网络退化(degradation) 现象的提出

上面的图片指示的是在 CIFAR-10 这个小型的数据集上,56 层的神经网络的表现比不过 20 层的神经网络。也就是层数加深,网络却反而退化了。
堆叠网络的缺点:
1.网络难以收敛,梯度消失/爆炸在一开始就阻碍网络的收敛。
(传统解决办法:通过标准初始化和中间标准化层在很大程度上解决。这使得数十层的网络能通过具有反向传播的随机梯度下降(SGD)开始收敛。)
2.当更深层次的网络能够开始收敛时,一个退化问题就暴露出来了:随着网络深度的增加,精确度趋于饱和(这可能并不奇怪),然后迅速退化。
如何构建更深层的网络?
一个解决方案是:
在一个常规的比较浅的模型上添加新的层,而新的层是基于 identity mapping 的。identity mapping :恒等变换,也就是输入与输出是相等的映射关系。
通俗来讲,就是在一个浅层的网络模型上进行改造,然后将新的模型与原来的浅层模型相比较,这里有个底线就是,改造后的模型至少不应该比原来的模型表现要差。因为新加的层可以让它的结果为 0,这样它就等同于原来的模型了。这个假设是 ResNet 的出发点。
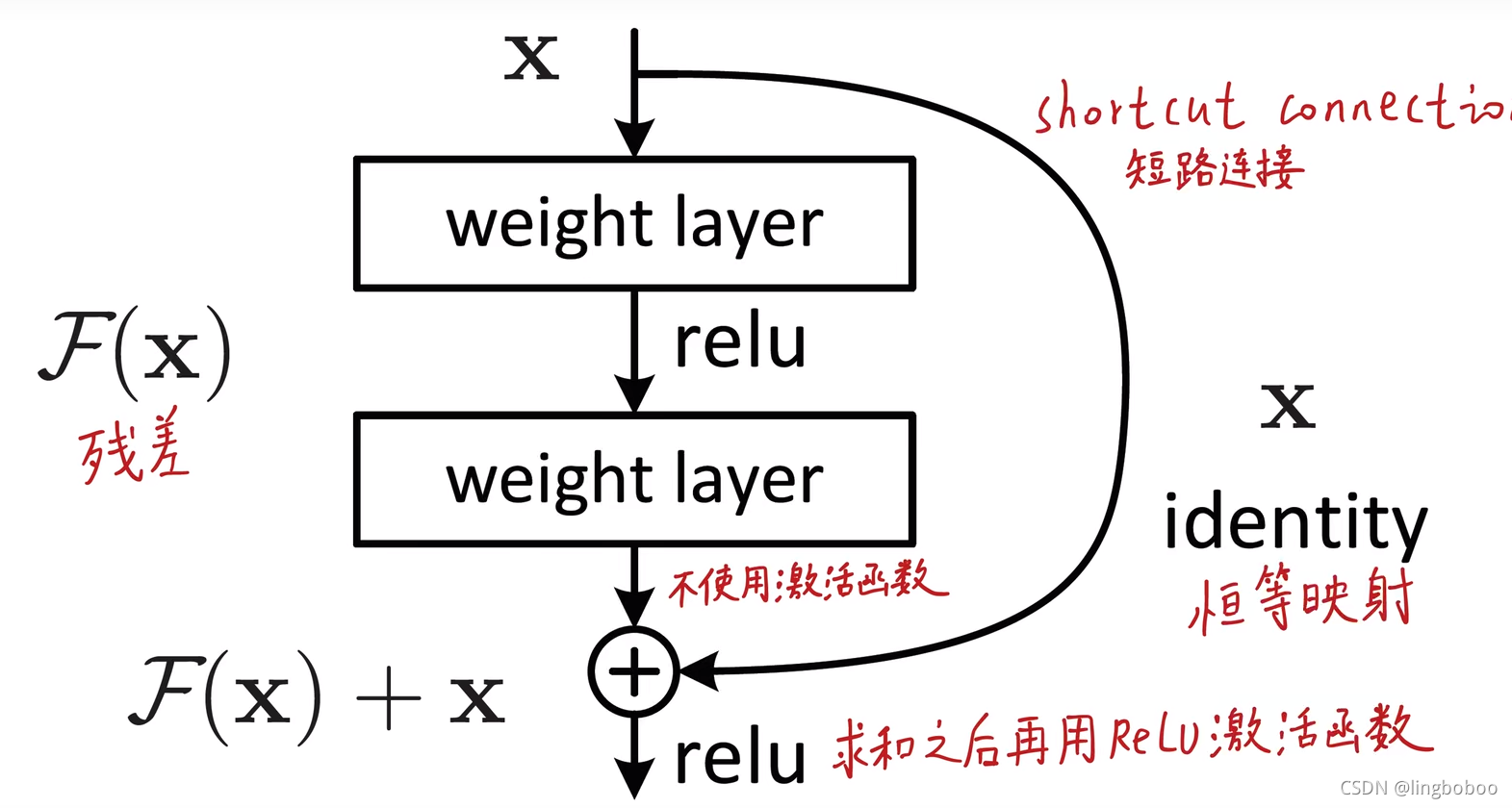
ResNet将输入分为两条路:
右边:恒等映射,不对输入做任何处理,直接传给输出
左边:两层神经网络,不去拟合原始的底层分布,直接拟合残差(保证这个神经网络至少不会比什么都不加时更差,大不了为0,这时输出等于输入)
最后将左边和右边相加(逐元素求和)
ResNet是将很多个残差模块堆叠

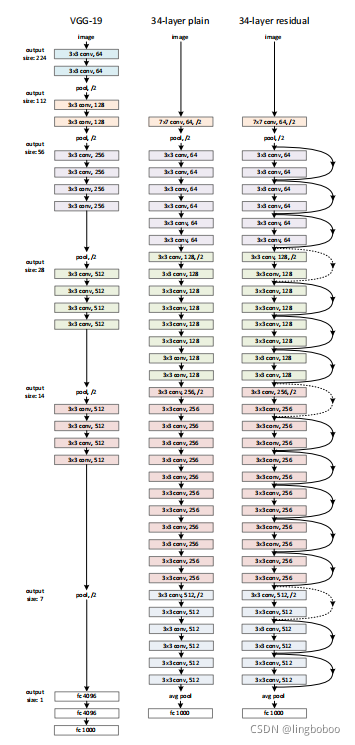
VGG里使用池化进行下采样,ResNet使用步长为2的卷积来下采样(右图中虚线),使得残差分支和恒等映射分支的数据大小一致
VGG的最后是全连接层,产生了大量的参数(1亿左右),ResNet使用全局平均池化代替全连接,大大减少了参数和计算量
VGG19的所有卷积都是3*3的卷积
当输入和输出维度一致时, identity shortcuts分支可以直接运用
维度不一致(右图中虚线处)时,匹配维度的方式:
1.shortcut仍然执行恒等映射,为增加维度填充额外的零项,此方案不产生额外参数
2.对shortcut分支做1*1的卷积进行升维
B站论文详解
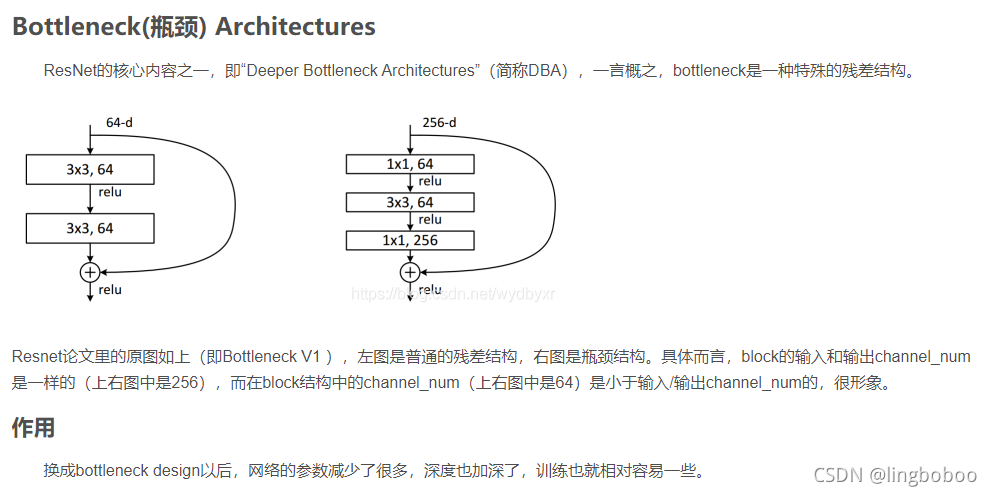
bottleneck
bottleneck算是原残差分支的进阶版,更关注对通道数的缩放处理,输入和输出都是高维的,1*1卷积先降维再升维。这个结构在Inception模块也用到了。
补充
ResNet没有使用dropout,因为dropout和batch normalization不适合同时存在,关于这个现象,有专门的论文从方差偏移的现象去解释
weight decay L2正则化,论文设置为0.0001; momentum 动量0.9
fully-convolutional form 不是指全卷积,指的是多尺度裁剪和特征融合,把多尺度的结果进行汇总融合

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









