






十二、复现SOTA 模型:ResNet
大名鼎鼎的残差网络ResNet是深度学习中的一个里程碑式的模型,也深度学习中的一个重要概念,几乎各类视觉任务中都能见到它的身影。
不同于前面的经典模型,resnet一个深层网络,它是由来自Microsoft Research的4位学者何凯明、张翔宇、任少卿、孙剑共同提出的,论文是《Deep Residual Learning for Image Recognition》。
前面我们一直说深层网络的效果比浅层好。这也是业界的一个共识,所以大家都在试图加深网络。但是大家却发现:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当继续增加网络深度后,训练集的loss反而会增大。就是网络发生了退化现象degradation problem。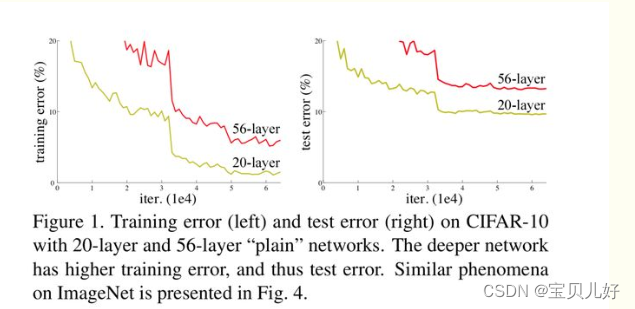
上图就是退化现象。注意这里是退化不是过拟合,过拟合是训练集的Loss很小,就是训练集效果很好,而测试集效果却不好,所以不是过拟合的问题。而且也不是梯度问题,前面我们讲梯度问题的时候说的是只要层数多了,梯度就会出现不平稳,并不是说随着迭代次数变多会越来越梯度会出现问题(当然也可能有这个问题,但是这里不是指这个,梯度问题我们在讲DNN时做过大量实验,如果有导致梯度消失或爆炸的因素存在,没训练两轮就出现了)。而退化是和迭代次数相关的。
并且这种退化现象是普遍存在的,这也是为什么VGG和googlenet为什么没有继续加深网络的原因,因为它们也都发现继续堆叠网络,网络就会出现退化现象。对于VGG来说就是16层和19层就是最有效的深度,再深效果就不行了。对于googlenet也一样,继续堆叠效果也不行,22层就是一个最好的深度。所以神经网络就一直没有在深度上出现突破。直到resnet的出现才打破了网络深度这一难题,让神经网络走向了深层。所以为什么说残差网络是深度学习的一个里程碑。
1、深层网络出现退化的原因
查阅很多资料后总结,大概有下面几个角度解释退化现象:
(1)现有的训练方法无法更好的拟合复杂函数
网络越深,也就是网络层数越多,那这个网络拟合的自然就是一个更多、更高维度的函数,那对于一个更多更高维的函数,现有的优化算法,就是我们前面讲的动量法、随机梯度下降、参数初始化、学习率调度、BN等优化算法,都是一些不加约束的放养式的训练,就是现有的训练方式是无法进行很好的训练(学习)这个多高维函数的。
(2)现有的梯度下降策略也很难找到最优解
按照常理更深层的网络结构的解空间是包括浅层的网络结构的解空间的,也就是说深层的网络结构能够得到更优的解,性能会比浅层网络更佳。但是实际上并非如此,原因可能是因为随机梯度下降的策略,往往解到的并不是全局最优解,而是局部最优解,由于深层网络的结构更加复杂,所以梯度下降算法得到局部最优解的可能性就会更大。
(3)冗余的网络不容易拟合恒等映射,尤其是存在relu的情况
在MobileNet V2的论文中提到,由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的,这也造成了许多不可逆的信息损失。我们试想一下,一个特征的一些有用的信息损失了,那他的表现还能做到持平吗?答案是显然的。举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这些冗余层为恒等映射,也就是经过这些层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
(4)网络越深,反向传播时,梯度就变得越来越混乱
神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。因为我们知道图像是具备局部相关性的,那其实可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。
总结上面的解释就是:
一是深度网络不好训练、不好收敛。也就是说,训练和优化一个很深的神经网络比创造一个很深的神经网络架构要难得多!网络更深,层数更多,需要训练的东西也就更多,各层的参数和数据在训练过程中需要相互协同,很容易出现这一轮拟合好的参数在下一轮反向传播时更新的“方向”可能发生完全相反的改变,就是这一轮叫你向0度方向走,下一轮又叫你往180度方向走...而且反反复复出现这种矛盾,这就使训练难度加大,而且无法收敛。也就是degradation problem不是网络结构本身的问题,而是现有的训练方式不够理想造成的。所以后面我们还需要继续讲一些优化算法。
二是多余的层其实是会造成不可逆的信息损失的,尤其是有relu层的时候。就是已经学到的信息,很可能在后面多余层的流动过程中反而给损失掉了,那效果自然不能更好。所以诞生了残差一族,后面顺着这个思路理理这个家族。
2、深度的意义?Deeper is better?
我们之前一直不厌其烦地重复强调,网络越深提取的特征就越好越丰富。人们把CNN提取的特征分为low/mid/high-level三个层次,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
浅层卷积网络提取的特征就是一些亮点、暗点、条纹等简单的点和线。 但是一个用于人脸识别的深层网络,随着层数的加深,人脸的轮廓和五官逐渐清晰了起来,就是提取了更丰富的有语义表达的深层特征,这些特征可以解决更复杂的问题。而且如果没有显著的深度,模型是无法整合不同层次的深度特征来解决更复杂问题。所以,人们不断尝试更深(>100层)的网络。
3、残差网络的思想和架构
下面我们从多个角度梳理一下resnet的思想和架构: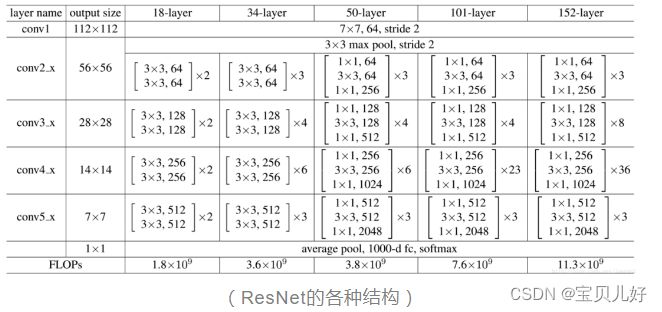
这张图是ResNet论文里列出的5种深度的残差网络,分别是18层、34层、50层、101层和152层。
我们先算算它的层,以ResNet34和ResNet101为例:
ResNet34:1+2x3+2x4+2x6+2x3+1=34层
ResNet101:1+9+12+69+9+1=101层
这里都算的只是卷积层和线性层的个数,可能是因为这两种层的参数训练是最主要的吧,所以行业惯例都只算这两种层。从层数上看,残差网络确实是第一个成功的的深度网络(100层以上),也是一个里程碑式的标志。
我们再确认一下网络的组成部分:
从上图我们可以看到所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,所以之后我们也会用这些符号指代网络的每个部分。其实其他论文都是这样称呼的。
最后我们再看看网络的计算量:ResNet34是36亿FLOPs。
下面我们再从另一张图看看残差网络的架构:
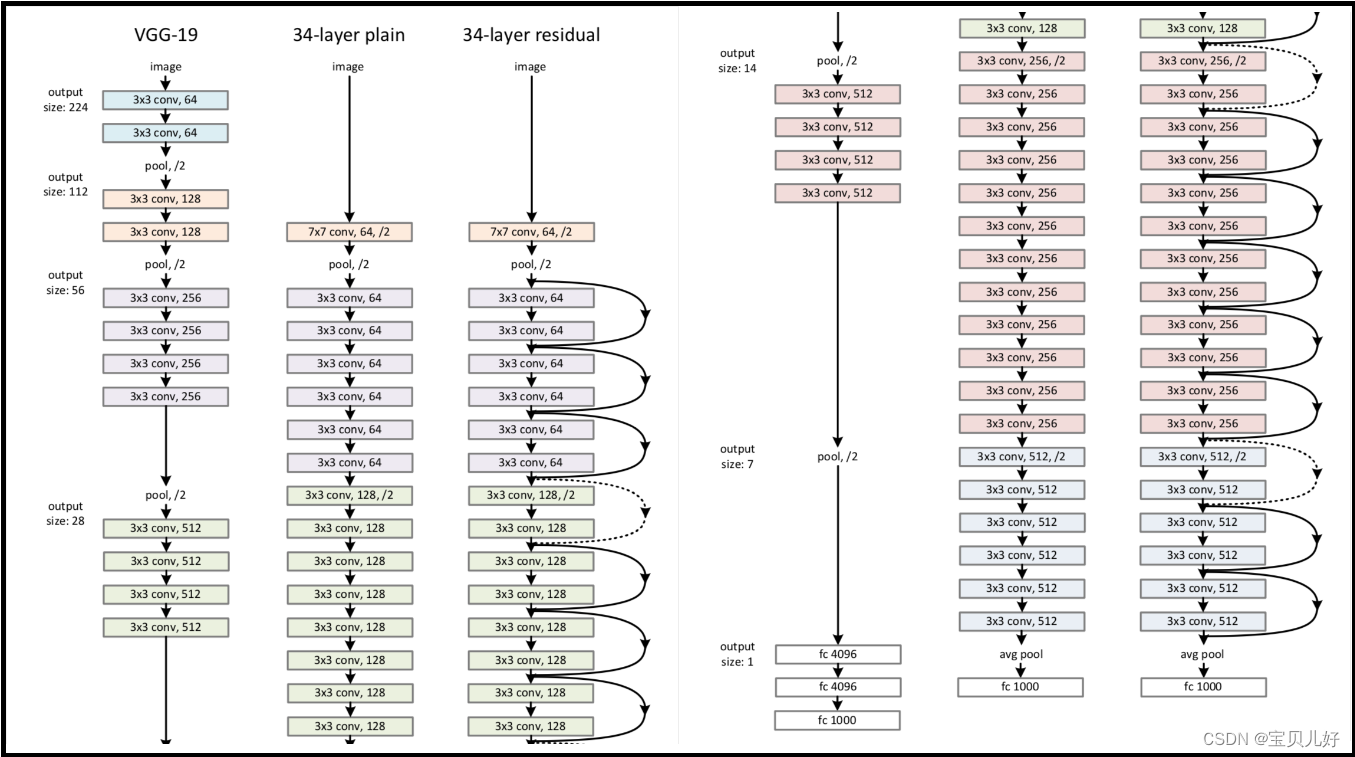
由于原图太长,所以我截图截成左右两部分了,其实它们是竖着串在一起的。
上图是对比三个网络,第一个是VGG,第二个是没有跳跃连接shortcut connection的一个34层的网络,第三个是ResNet34。
我们发现残差网络在架构上,它只是比普通网络(中间的34-layer plain)多了一些右边的弯弯的曲线连接,这些连接就是残差网络的特别之处:跳跃连接shortcut connection 这里先不继续深入讲什么是跳跃连接,这张图主要是让大家对残差网络的架构先有一个整体的认识。
那我们继续,我想大家首先想明白的概念应该是到底什么是残差?
残差在数理统计中是指:实际观察值与估计值(拟合值)之间的差。如果回归模型正确的话,我们可以将残差看作误差的观测值。意思就是,假设我们想要找一个x,使f(x)=b,那我先给x一个估计值x0,残差(residual)就是b-f(x0),同时,误差就是x-x0。即使x不知道,我们仍然可以计算残差,只是不能计算误差罢了。大概类比这个概念我们来继续理解残差网络。
我个人认为残差网络诞生的灵感应该是:假如输入是x,经过一个深层网络后,输出是H(x),正常的思路就是用深层网络来拟合y=H(x),但是现实很残酷,我根本很难拟合,效果比浅层还差呀,那我索性不拟合y=H(x)了,我换个思路,我能不能分而治之?那我就先把H(x)分成两部分试试,即H(x) = h(x,w) + F(x,w),也就是我拟合y = h(x,w) + F(x,w),就是我训练拟合这两部分,两部分一起训练拟合不就是googlenet的并联思路嘛,先不管了,我先试试看吧。
在ResnetV1的论文中介绍Residual Units的时候,他用的公式是下面这样的:
从公式(1)(2)处可见,它也是把H(x)分成了两部分进行训练的,就是一个并联架构嘛。但是他在实验的时候发现:把这个并联架构中的一条线路弄成短路,就是弄成恒等映射,网络似乎更容易训练了!就是弄成恒等映射,网络不退化了!就是随着迭代次数增加,loss不饱和了而是继续卡卡下降了,而且还是降得更低了!神奇呀,那我就干脆让线路h(x)直接短路好了,就是我们前面看到的跳跃连接。
这一跳跃不要紧,要紧的是它性质就发生了质的改变!我输入是x,我跳到下一个块还是x,我都没有变,那我们的网络在训练什么呢?就是我另外一条并联线路再干啥呢?突然意识到,哦,原来我另外一条线路在学习F(x,w),也就是在学习y-x,就是y-h(x,w),h(x,w)我让它短路了,就是恒等跳跃了,就是h(x,w)=x了,那就是学习y-x了。这不就是在拟合残差了嘛!也是!拟合y=H(x)难死我了,我拟合残差会不会更好呢?!反正有跳跃连接,我保底有了,残差块你能学多少是多少,哪怕只学了一点点我也是赚了呀。我想这就是残差网络的名字以及架构灵感的来源吧。
而且我这个网络还有一个优点就是:
比如我想把输入5映射到10输出,我不用拟合残差的思路时,比如我拟合的是H(x)=10,假如这个H(x)就是2x, 当我的输入从5变成6时,我的输出就变成12了,我的输入变化了1,输出变化了2,输入对输出的敏感性就是1/2=50%。
当我用拟合残差的思路时,我拟合的就是比如8+F(x)=10,就是8是我保底的拟合精度,那此时F(x)=2,假如这个F(x)就是0.4x, 当我的输入从5变成6时,我的输出就变成8+0.4x6=10.4了,就是我的输入变化了1,输出变化了0.4,输入对输出的敏感性就是1/0.4=250%。
所以残差网络的这种思想:去掉相同的主体部分,突出微小的变化,残差网络就类似一个差分放大器…所以效果更好。怎么老是扯到电路上,我也是服了自己了。我还看到有的人竟然能解读到泰勒公式,说往后相加的残差块就像是更高阶的多项式...anyway,人家成功了,膜拜者自然就是各种膜拜了。
说明:以上是我看相关资料后自己的说辞和理解,不一定正确哦,大家看看辅助理解而已,如果不对就请果断忽视吧。
同时要说明的是:对于模型的优点、思路、架构等的原理性的各种解释,其实并不是模型的重心,毕竟这些解释都是建立在实验事实之上,如果这样的模型并不理想,一切解释都是徒劳的,不过这些内容有助于我们对这一类网络的构想过程的理解。
也所以通过上述的一番思考后,残差网络的基本架构雏形就诞生了: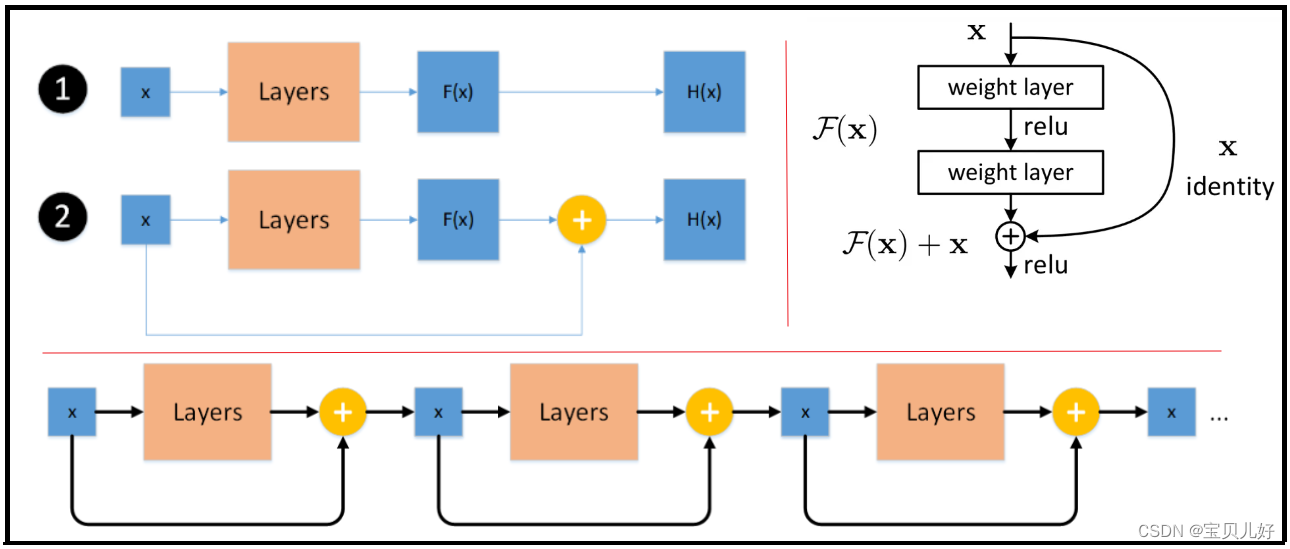
上图1是传统的拟合思路,2是残差块的拟合思路,就是加了一个跳跃连接shortcut connection。
2的具体架构就是右边的图示。右边就是一个残差块,输入是x,弯弯的曲线连接就是shortcut connetction, 图中的x identity就是identiye mapping恒等映射;图中的weight layer可以是卷积层也可以是线性层;图中的F(x)是residual mapping残差映射;relu上面的加号有的地方写的是addition,就是像素对像素的加和操作element-wise add,就是将恒等映射的结果和残差映射的结果点对点的加和。
上图最下面的架构就是整个残差网络的架构,就是多个残差块串联到一起组成一个很深的深层网络。如果你的恒等映射已经是最优输出了,那在损失函数的牵引下,残差映射将会被push为0,这样理论上这个深层网络就一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
所以,残差网络就是通过不断的添加上面说的残差块来增加网络深度的。而且残差网络还避开了难训练难收敛的难题,成为人们探索深度网络的起点。
网络的整体架构清晰了,下面开始继续讨论一些网络设计的细节问题:
(1)残差块的具体设计
ResNet论文中的残差块有两种形式:如下下图红线的左边,其中第一个架构称作buliding block,用于层数较少的ResNet18和ResNet34;第二个架构称作bottleneck,就是用1x1卷积层来降低参数数目,减少计算量,使得模型能进一步加深,所以ResNet50、ResNet101和ResNet152用的是bottleneck。1x1卷积层我们单独拿出来讲过,所以它的好处和应用场景我这里就不再最赘述了,此外3x3的卷积层就更没啥好讲的了。
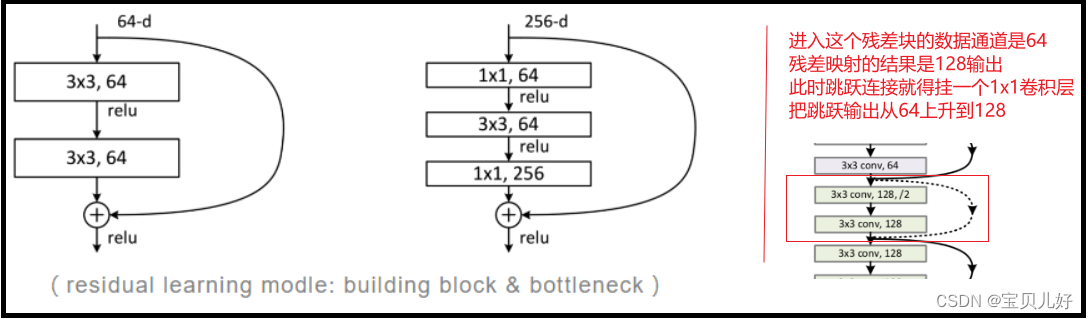
下面我们要重点讨论的是上图中最右边的图,就是残差块中的恒等映射,就是跳跃连接,就是旁边的弯弯的曲线连接,细心的同学会在上上图中发现多数都是实弯曲线,但还有3个虚弯曲线。现在给大家讲一下,虚线是因为那个残差块的输入和输出的通道数不一样,这样shortcut的恒等输出就没法和卷积层的输出进行point-wise add了,所以此时都默认shorchut线路上要再串联一个1x1卷积层,把shortcut链路上的通道调整到和残差块的输出通道一样的数量上,然后point-wise add。 所以你要自己复现残差网络架构的时候你一定得知道没有标出得要素,不然你的网络就跑不通。
4、残差一族的进化史
分析到这里,残差网络的进化链已经呼之欲出,所以在这里穿插讲一下resnet一族的进化史。公式难敲,所以我们直接截图:
A:它的意思就是说,任意一个残差块l都和它前面的所有L-1个块有残差特性。意思就是,任意一个残差块都会完整输出它前面所有残差块学习到的信息(因为跳跃连接就是恒等映射嘛),并且它自己学习的是在前辈(前面的所有残差块)的基础上的残差(因为残差块拟合的就是残差嘛,前辈已经拟合出来的信息它就不用拟合了,如果它自己实在你拟合不出啥信息,那它输出0就好了嘛)。
现在知道为什么短路了一下好训练了吧,至少不会瞎指挥了,一会儿让你往0度方向走,下一秒又让你往180度方向走。是不是和前面的退化原因吻合了。
B:它的意思是说,残差网络的第l个残差块的输出是x0+它前面所有残差块学到的残差信息的总合。就是+它前面所有残差块的残差映射结果的加和,就是都不带恒等映射结果的那个结果。就是说,如果要是那种plain network的话,那它第l层的输出就是它前面所有层的输出结果的连乘。而残差网络它的层的输出结果确实前面层的累加。 这说明残差网络的计算量要大大的小啊!虽然都100层了,其实计算量不大。
C和D:说明残差网络不容易梯度消失啊。虽然网络很深,层数很多,但还不易出现梯度消失问题。而对于20层以下的浅层网络,倒非常容易出现梯度消失现象,这我们在讲DNN的时候就大量的实验证明了,这里不赘述了。
上面就是残差一族V1代的详细架构和原理。V1一经问世,炼丹者们就发现这种残差结构确实简单好使,而且还能很方便地集成到各种其它网络架构中,同时也没有额外增加多少参数量。于是,为了更好地解决不同类型的任务,炼丹者们开启了魔性改造,其中比较有名的是进化版的ResNetv2、使用分组卷积(Group Convolution)的ResNeXt、加入了空间注意力(Channel Attention)机制的SE-ResNet和SE-ResNeXt、加入混合注意力(Spacial & Channel Attention)机制的Residual Attention Net等,构成了残差网络的庞大家族。
上图通过分析残差网络的正向和反向两个过程,我们发现,当残差块满足上面两个假设时,信息可以非常畅通的在高层和低层之间相互传导,说明这两个假设是让残差网络可以训练深度模型的充分条件。那么这两个假设是必要条件吗?于是ResNetv2进行了两个方向的实验:一是直连映射是否非得直连,就是跳跃映射是否可以继续优化?二是残差映射部分是否可以继续优化?
(1)ResNetv2做实验证明了在跳跃连接部分,还是直接映射最好

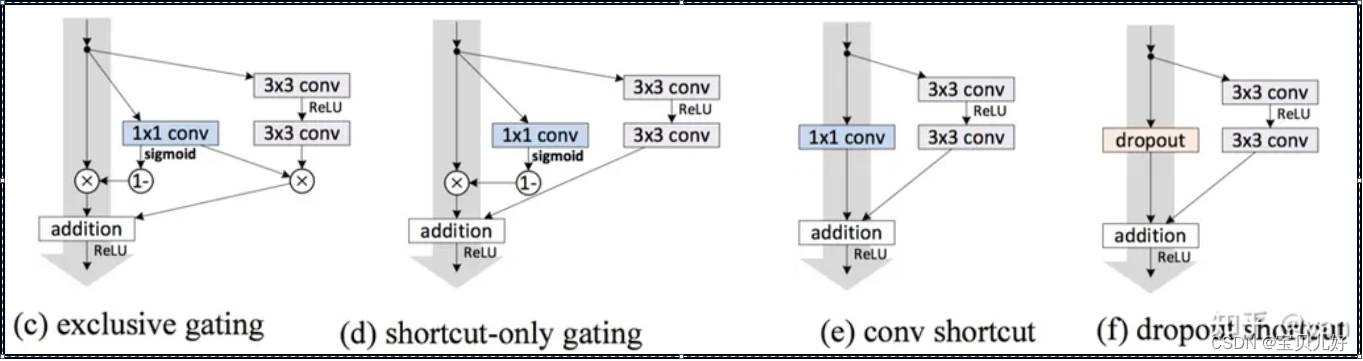
上图左边是从数学角度推理λ必须等1网络才能顺畅训练。但是在论文里,作者除了数学推导外,还做了6组实验,用实验的方法来验证。其中第一组就是用上图的resnetv1架构;第二组是用上图的(b)constant scaling,就是简单粗暴的乘以一个常数;第三组和第四组是(c)(d)LSTM中的门机制的架构;第五组是conv shortcut,就是串连一个1x1卷积层;最后一组是dropout随机沉默一些通道。这6组架构都在Cifar10数据集上进行实验,实验结果如下表:
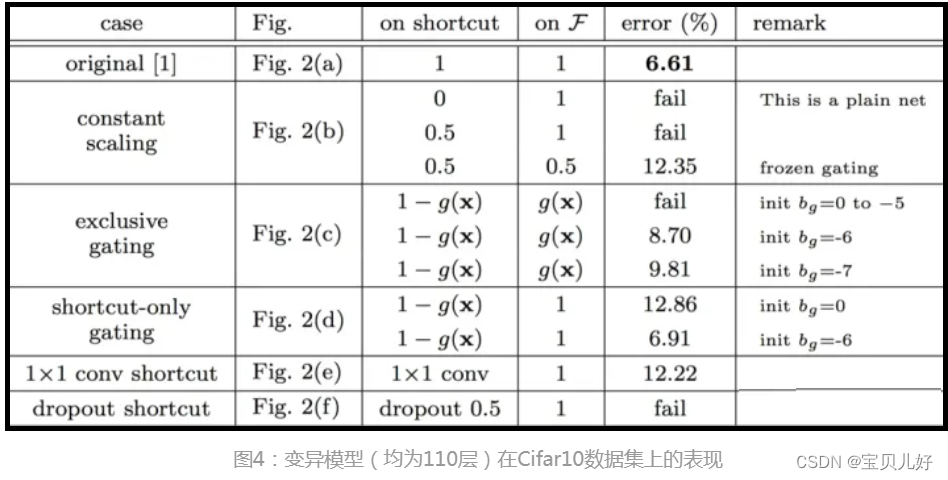
从实验结果中我们可以看出,在所有的变异架构中,依旧是直接映射的效果最好。看资料说shortcut连接被实验和研究了很久,比如上面的c和d这种带有门函数的shortcut一是它们是需要参数的,直连不需要任何参数,而且当门函数的shortcut关闭时,就退化成普通卷积网络了,就相当于没有学习残差了,所以直连可以保证网络一直学的就是残差。而dropout就相当于shortcut映射乘以了1-p,这和b是类似的效果,是会影响反向传播的,弄不好不是梯度消失就是梯度爆炸,也是影响训练的。至于e,直觉上感觉串联一个1X1卷积应该比直接shortcut有更强的表征能力,但是实验效果却不如直接映射,说明该问题更可能是优化问题而非模型容量问题。
那另一个问题又来了:既然一个残差块的输入和输出之间直连映射效果最好,那残差块与残差块之间也直连是最好的?我现在的V1架构中,最后还串一个relu,这样残差块中出来的结果就是非负的,经过多个残差块前向传播后,我的数据流就可能会是单调递增的呀,我们希望数据流动过程中是均匀的,这种递增的可不是什么好事。从另一个角度来看,后面串一个relu就相当于把H(x) = x + F(x)变成了H(x) = G(x + F(x)),我实质上是在拟合一个 G(x')了,和直接拟合H(x)本质无异,而不是我最开始的想法:只拟合残差。我的初心是拟合残差的,这里给跑偏了。
也就是因为传统的卷积层或全连接层在信息传递时,后面跟的激活函数都会或多或少的、不可逆的丢失一些信息。我现在的直连解决了不丢失信息的问题,此时我再串一个relu不是捣乱嘛。所以想到此,V2作者又开始做实验了:
最后作者给出的proposed架构就是进化了的ResNetv2。我们传统的常规操作是Conv->BN->ReLU,称为Post-Activation,V2的结构称为Pre-Activation,意思是BN层和激活层放在卷积层前面:BN->ReLU->Conv。
这种架构更容易优化:这个影响在训练1001层的resnet的时候特别明显,使用原始的结构,training error在训练之初下降的非常慢,因为如果相加上进行RELU激活对传递过来的负数信息是有影响的。而如果是等式,信息可以直接从一个单元传递到另一个单元,1001层的resnet loss下降的非常快。另外对于层数少一些的resnet比如164层,为relu似乎对性能的影响很小。
降低过拟合:将BN放入RELU的前面可以带来正则化的效果,降低过拟合,会得到更高的精度。
(2)ResNeXt告诉我们利用堆叠和split-transform-merge的思想可产生许多变形结构
ResNetV2的结构仍是堆叠式的,即一层层模块串行堆叠,借鉴GoogleNet的Inception块,在设计网络时使用split->transform->merge的策略能取得很好的效果,于是 ResNeXt将两者的思想融合到一起,于2017年出道。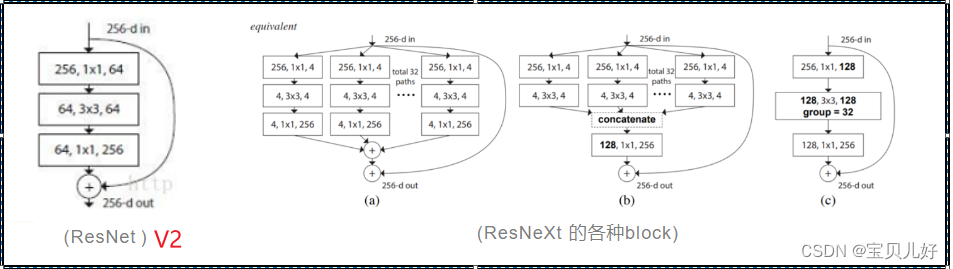
上图中(a)是ResNeXt使用的原始形式,将原输入分成(split)32个分支进行卷积变换(transform)后合成(merge)到一起,最后再加上shortcut构成残差模块。 每个分支先把输入通道数(上图是256d)压缩到(上图是4d),经transform后在merge前再恢复至原来的通道数256,使用(a)形式的 block 的 ResNeXt 称作 ResNext32x4d,即将输入分成32组,每组通道数压缩至4。
(b)是类似于GoogleNet和Inception-ResNet的等效形式,(c)是使用了分组卷积(Group Convolution)的等价形式。
通过实验证明,(c)性能最好(速度最快),而且结构最为简单,相比于ResNet几乎不需做太多改造,主要是将bottleneck中间那一层3x3卷积层改为使用分组卷积,通常 ResNeXt多使用的是(c)。
(3)继续融合:加入空间注意力(Channel Attention)机制的SE-ResNet和SE-ResNeXt
注意力(Attention)是SENet(Squeeze-And-Exitation Networks)的灵魂,指的是通道注意力(Channel-Wise Attention),就是给每个通道的feature map都分配不同的权重,但同一个通道的各像素权重是相同的。如下图的左图: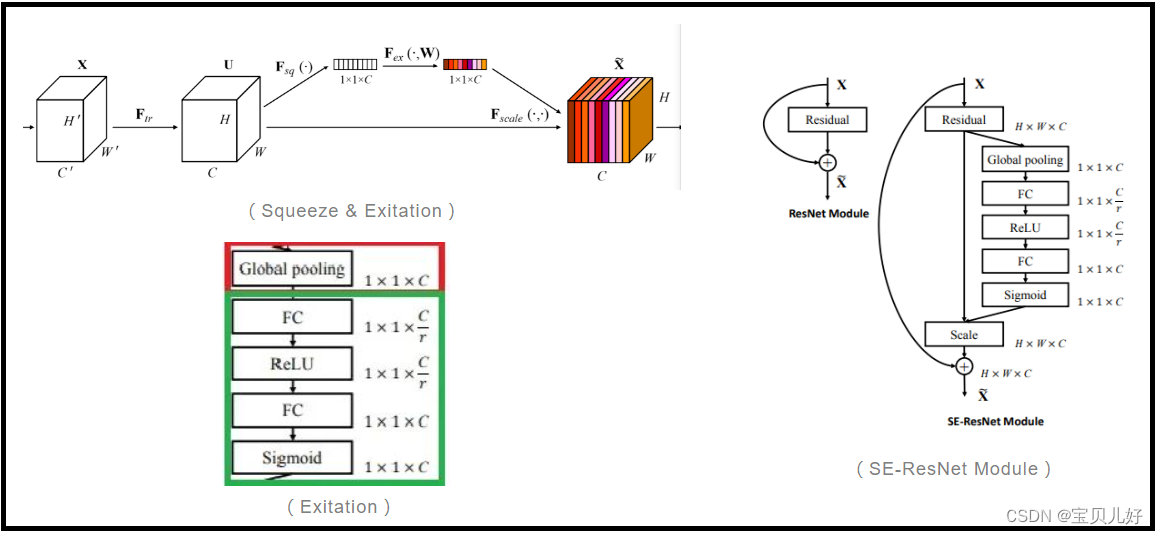
Squeeze是把feature map的尺寸(HxW)压缩至 1x1,可通过全局(平均/最大)池化完成;Exitation是通过数个FC学到每个通道的注意力因子,也可以理解为权重系数。 最后将各通道的注意力系数与对应通道的feature map相乘就结束了。
SE-ResNet和SE-ResNeXt中,SE block用在残差分支后,如上图右图所示。
残差一族的演化史不是本部分的重点,所以写到这里就不写了,因为扯得太远了,已经超出残差这个话题了。感兴趣的同学可以参考《无处不在的残差网络 (Residual Nets Family)》这篇文章,作者是深蓝AI,我就是参考的这篇文章。由于连接太长我就写了个文章名称,相信大家都能搜到的。
5、代码复现ResNetv1
我们这里复现的只是ResNetv1论文中的5种架构,我把架构图再贴一下: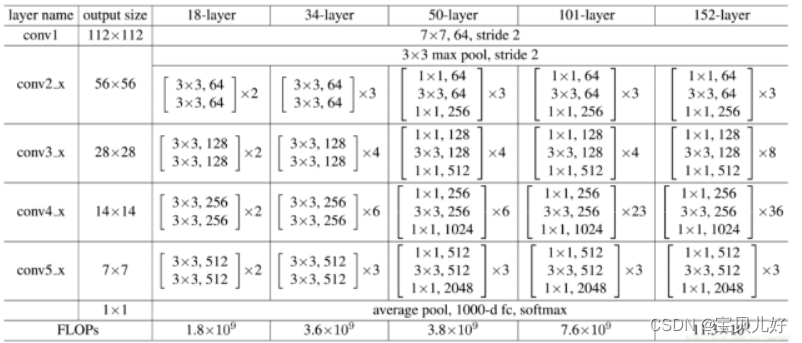
所以,本部分得和第4点的(1)处以上的内容衔接,就是我们还需要继续梳理残差网络的细节问题,也就是代码复现时需要注意的地方:
(1)ResNetv1有5种架构,浅层你可以一路顺着写下来,但是101层和152层的你会顺晕的,所以复现ResNetv1必须得把有的能复用的模型打包成函数或者类来调用。并且你打包的模块一定要足够灵活和通用,你往下看,它太多的细节了,你不灵活不通用,你得写多少个函数和类啊。
(2)ResNetv1的输入图像也是(224x224), 残差网络对特征图尺寸进行了5次折半后,特征图尺寸变成7X7,然后再用一个全局平均池化,然后拉平进入线性层,softmax输出。
(3)上图的conv1,conv2_x,conv3_x,conv4_x,conv5_x我们称为layer,你可以理解为大层的意思,论文里就是这么叫的。我们之前老说的残差块就是上图中方括号括住的部分,论文里称residual unit,你也可以叫残差单元。
在以往的网络中,我们对特征图尺寸折半,基本都用的是池化层,但残差网络中中,你看上图,每个大层之间没有池化层!所以残差网络对特征图尺寸折半是通过使用步长为2的卷积操作来实现的!所以残差网络的每一个layer中的第一个residual unit的第一个卷积层的步长都是2,因为只有步长是2才能将上一层输入进来的特征图尺寸减半。而残差网络的每一个layer中的除第一个卷积层外的其他卷积层的步长都是1
(4)一般情况下,每一个卷积层的后面都紧跟BN, BN后面再紧跟relu激活函数。这是V1版本的结构。但是每个残差块的最后一个卷积层都是只加BN,不要relu,因为BN是调整数据分布的,所以要放在两条线路加和之前。
(5)残差块中卷积层可以是2个串联(18层和34层)也可以是一个瓶颈架构(101层和152层)。所以残差块是两种架构。也就是残差映射是两种架构。
(6)对于ResNet18和ResNet34,有残差块的跳跃映射中:
如果是层内的跳跃,数据是原封不动的从残差块的输入传递到残差块的输出。然后point wise add,然后再relu输出。
如果是层间的跳跃,数据尺寸是要折半的,而且通道数还是double的,此时就要在跳跃线路中加一个卷积核是1x1、步长=2的卷积层,让跳跃连接的尺寸减半通道数double,并且后面还要紧跟一个BN,没有relu,才能和残差映射的输出进行point wise add,然后再relu输出。
(7)对于ResNet50和ResNet101和ResNet152,有残差块的跳跃映射中:
不管是层内的残差块之间的跳跃还是跨层间的残差块之间的跳跃,每个残差块的输入通道数和输出通道数都不一样! 所以跳跃连接线路必须全部都要挂一个1X1卷积核来调整通道数以便可以point wise add。而且处于跨层之间的跳跃,还得步长=2,调整通道的同时还得消减特征图尺寸。而且这个1X1卷积层后面也是只跟BN,不要relu。
(8)残差网络中的卷积层的参数初始化和其他网络一样,都是高斯分布下的随机数,也是pytorch中默认的方式。但是残差网络中的BN层的参数初始化和其它网络有点不一样:只要残差块中的最后一个卷积层后面跟的BN的γ和β初始化为0就可以了,因为最后一个卷积层后面BN的γ和β都为0,这个残差块里面的串联的线路的最后结果就肯定是0了,这也是我们想要的结果。我们就是想要残差映射线路的输出无限逼近0。这种初始化方式可以将残差网络的精度提升0.2-0.3%,在pytorch中也是用这种方式来初始化参数的。
import torch
import torch.nn as nn
from typing import Type, Union, List, Optional
from torchinfo import summarydef conv3x3(inf, outf, loc:Type[Union['first', 'middle', 'last']], **kwargs):
if loc == 'first': #conv3x3是每个大层的第一个卷积层
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=3, padding=1, stride=2, bias=False), nn.BatchNorm2d(outf), nn.ReLU(inplace=True))
if loc == 'middle': #conv3x3是每个大层的中间卷积层
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=3, padding=1, stride=1, bias=False), nn.BatchNorm2d(outf), nn.ReLU(inplace=True))
if loc == 'last': #conv3x3是每个大层的最后一个卷积层
bn = nn.BatchNorm2d(outf)
nn.init.constant_(bn.weight, 0)
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=3, padding=1, stride=1, bias=False), bn)def conv1x1(inf, outf, loc:Type[Union['first', 'middle', 'last', 'scm', 'scj']], **kwargs):
if loc == 'first': #conv1x1是每个大层的第一个卷积层
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=1, padding=0, stride=2, bias=False), nn.BatchNorm2d(outf), nn.ReLU(inplace=True))
if loc == 'middle': #conv1x1是每个大层的中间卷积层
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=1, padding=0, stride=1, bias=False), nn.BatchNorm2d(outf), nn.ReLU(inplace=True))
if loc == 'last': #conv1x1是每个大层的最后一个卷积层
bn = nn.BatchNorm2d(outf)
nn.init.constant_(bn.weight, 0)
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=1, padding=0, stride=1, bias=False), bn)
if loc == 'scm': #conv1x1是中间的跳跃连接
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=1, padding=0, stride=1, bias=False), nn.BatchNorm2d(outf))
if loc == 'scj': #conv1x1是跨层间的跳跃连接
return nn.Sequential(nn.Conv2d(inf, outf, kernel_size=1, padding=0, stride=2, bias=False), nn.BatchNorm2d(outf)) class ResidualUnit(nn.Module):
def __init__(self, inf, outf, restype:Type[Union['normU', 'bottleneckU']], resloc:Type[Union['first0','first', 'middle', 'last']]):
#restype=normU表示ResidualUnit残差块, restype=bottleneckU表示Bottleneck残差块
#resloc=first表示每层的第一个残差单元,resloc=middle表示中间残差单元,resloc=last表示每层的最后一个残差单元
super().__init__()
if restype == 'normU' and resloc == 'first0': #生成一个普通的残差单元,并且是第一层的第一个残差单元
self.flat=0
self.re = nn.Sequential(conv3x3(inf, outf, loc="middle"), conv3x3(outf, outf, loc="middle"))
if restype == 'normU' and resloc == 'first': #生成一个普通的残差单元,并且是每层的第一个残差单元
self.flat=1
self.re = nn.Sequential(conv3x3(inf, outf, loc="first"), conv3x3(outf, outf, loc="middle"))
self.sc = conv1x1(inf, outf, loc="scj")
if restype == 'normU' and resloc == 'middle': #生成一个普通的残差单元,并且是每层的中间残差单元
self.flat=0
self.re = nn.Sequential(conv3x3(outf, outf, loc="middle"), conv3x3(outf, outf, loc="middle"))
if restype == 'normU' and resloc == 'last': #生成一个普通的残差单元,并且是每层的最后一个残差单元
self.flat=0
self.re = nn.Sequential(conv3x3(outf, outf, loc="middle"), conv3x3(outf, outf, loc="last"))
if restype == 'bottleneckU' and resloc == 'first0': #生成一个瓶颈结构的残差单元,并且是第一层的第一个残差单元
self.flat=1
self.re = nn.Sequential(conv1x1(inf, outf, loc="middle"), conv3x3(outf, outf, loc="middle"), conv1x1(outf,4*outf, loc="middle"))
self.sc = conv1x1(inf, 4*outf, loc='scm')
if restype == 'bottleneckU' and resloc == 'first': #生成一个瓶颈结构的残差单元,并且是每层的第一个残差单元
self.flat=1
self.re = nn.Sequential(conv1x1(inf, outf, loc="first"), conv3x3(outf, outf, loc="middle"), conv1x1(outf,4*outf, loc="middle"))
self.sc = conv1x1(inf, 4*outf, loc='scj')
if restype == 'bottleneckU' and resloc == 'middle': #生成一个瓶颈结构的残差单元,并且是每层的中间残差单元
self.flat=0
self.re = nn.Sequential(conv1x1(4*outf, outf, loc="middle"), conv3x3(outf, outf, loc="middle"), conv1x1(outf,4*outf, loc="middle"))
if restype == 'bottleneckU' and resloc == 'last': #生成一个瓶颈结构的残差单元,并且是每层的最后一个残差单元
self.flat=0
self.re = nn.Sequential(conv1x1(4*outf, outf, loc="middle"), conv3x3(outf, outf, loc="middle"), conv1x1(outf,4*outf, loc="last"))
def forward(self, x):
if self.flat==0:
x1 = self.re(x)
out = torch.relu(x+x1)
if self.flat == 1:
x1 = self.re(x)
x2 = self.sc(x)
out = torch.relu(x1+x2)
return outclass makelayer(nn.Module):
def __init__(self, inf, outf, numres, layertype:Type[Union['normL0', 'normL', 'bottleneckL0', 'bottleneckL']]):
super().__init__()
temp=[]
if layertype=='normL0' and numres==2:
self.layer = nn.Sequential(ResidualUnit(inf,outf,restype='normU', resloc='first0'), ResidualUnit(inf,outf,restype='normU', resloc='last'))
if layertype=='normL0' and numres==3:
self.layer = nn.Sequential(ResidualUnit(inf,outf,restype='normU', resloc='first0'),
ResidualUnit(inf,outf,restype='normU', resloc='middle'),
ResidualUnit(inf,outf,restype='normU', resloc='last'))
if layertype=='normL' and numres==2:
self.layer = nn.Sequential(ResidualUnit(inf,outf,restype='normU', resloc='first'), ResidualUnit(inf,outf,restype='normU', resloc='last'))
if layertype=='normL' and numres>2:
temp.append(ResidualUnit(inf,outf,restype='normU', resloc='first'))
for i in range(numres-2):
temp.append(ResidualUnit(inf,outf,restype='normU', resloc='middle'))
temp.append(ResidualUnit(inf,outf,restype='normU', resloc='last'))
self.layer = nn.Sequential(*temp)
if layertype=='bottleneckL0':
self.layer = nn.Sequential(ResidualUnit(inf,outf,restype='bottleneckU', resloc='first0'),
ResidualUnit(inf,outf,restype='bottleneckU', resloc='middle'),
ResidualUnit(inf,outf,restype='bottleneckU', resloc='last'))
if layertype=='bottleneckL':
temp.append(ResidualUnit(inf,outf,restype='bottleneckU', resloc='first'))
for i in range(numres-2):
temp.append(ResidualUnit(inf,outf,restype='bottleneckU', resloc='middle'))
temp.append(ResidualUnit(inf,outf,restype='bottleneckU', resloc='last'))
self.layer = nn.Sequential(*temp)
def forward(self, x):
x = self.layer(x)
return xdata = torch.ones(1, 3, 224, 224)
class ResNet(nn.Module):
def __init__(self, modeltype:Type[Union["ResidualNet", "BottleneckNet"]], layers:List[int], num_classes:int):
super().__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False), #(224+6-7)/2 +1 =112.5=112 向下取整 torch.Size([1, 64, 112, 112])
nn.BatchNorm2d(64), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)) #torch.Size([1, 64, 56, 56]) #(112-3)/2 +1=55.5=56 向上取整
if modeltype == "ResidualNet":
self.conv2_x = makelayer(64, 64, numres=layers[0], layertype='normL0')
self.conv3_x = makelayer(64, 128, numres=layers[1], layertype='normL')
self.conv4_x = makelayer(128, 256, numres=layers[2], layertype='normL')
self.conv5_x = makelayer(256, 512, numres=layers[3], layertype='normL')
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512, num_classes)
if modeltype == "BottleneckNet":
self.conv2_x = makelayer(64, 64, numres=layers[0], layertype='bottleneckL0')
self.conv3_x = makelayer(256, 128, numres=layers[1], layertype='bottleneckL')
self.conv4_x = makelayer(512, 256, numres=layers[2], layertype='bottleneckL')
self.conv5_x = makelayer(1024, 512, numres=layers[3], layertype='bottleneckL')
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.avgpool(x)
x = self.fc(torch.flatten(x,1))
return xres101 = ResNet('BottleneckNet', [3, 4, 23, 3], 1000)
summary(res101, (1, 3, 224, 224), device='cpu', depth=1) 
6、写在最后:为什么残差网络的性能这么好?
目前公认的推广性能最好的两个分类网络就是残差网络和Inception V4。
那残差网络的性能为什么这么好?一种典型的解释就是:残差网络可以看作是一种集成模型!集成模型就很强大了,分类效果就很强了。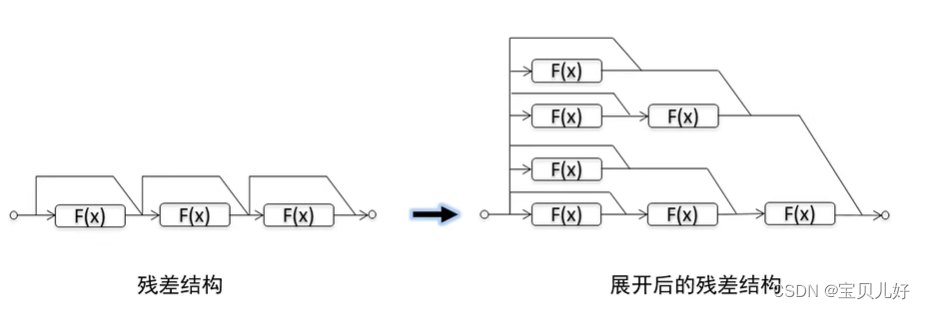
可见残差网络可以看作是上图右边的多个子网络的集成。虽然你只训练了一个残差网络,其实你是同时训练了7个子网络,进行投票分类,自然很强大。而且也正是这种集成的效果,你如果把残差网络中间某层失活,残差网络照样可以分类,而串联的架构就不行。也所以后来的大名鼎鼎的DenseNet也是在这个思想对残差网络进行改进而诞生的。
残差网络效果非常好,所以我们只要拿它进行微调就可以使用了。你把残差网络吃透了,在某些特殊应用环境下,还有面向有限存储资源的SqueezeNet以及面向有限计算资源的MobileNet和ShuffleNet等这些简化网络,你也会很快就理解了。















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









