







文章:Extracting semantics of individual places from movement data by analyzing temporal patterns of visits
作者:Gennady Andrienko, Natalia Andrienko, Georg Fuchs等.
来源:Proceedings of The First ACM SIGSPATIAL International Workshop on Computational Models of Place (COMP’13). 2013.
利用可视分析可以提取个人地点的语义,但是这对于大规模数据不可行,本文提出利用时态签名(temporal signature,用来刻画个人访问POI的时间分布)来解决该问题,对所有提取出的stop,提取其访问的时间模式, 对于语义已知的地点,利用时间序列聚类的方法发现与其相似的其它地点,然后将已知的语义赋给这些地点,达到大规模提取语义地点的目的。
step1:利用郑宇的方法提取stop
step2:对每个人的对stop进行密度聚类,发现cluster。
这些cluster代表潜在的POI,然后对其进行缓冲区构建。
step3:对每个cluster,计算下列时态聚集特征:
这些特征构成了“时态签名”,这里假设:
1,可以从时态签名里面推断POI的语义特征
2,时态签名相似的POI,其语义也相似。
可视分析主要包含两个视图:map view和time graph。
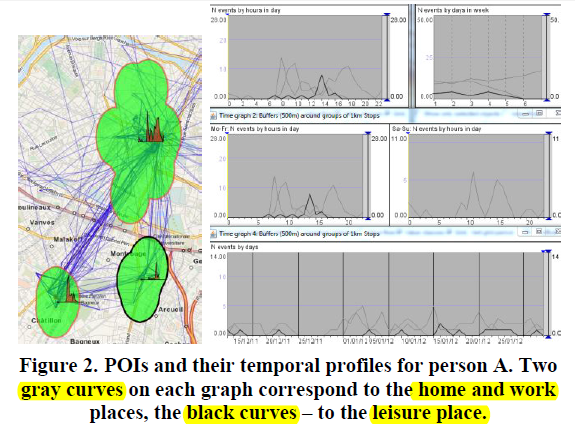
下图为利用手机通话数据分析某个人的语义地点:
左图最上面的cluster为home,左下的cluster为work,黑色的cluster在工作日的下午访问,有可能为休闲或者体育活动场所。右图为各个time graph。
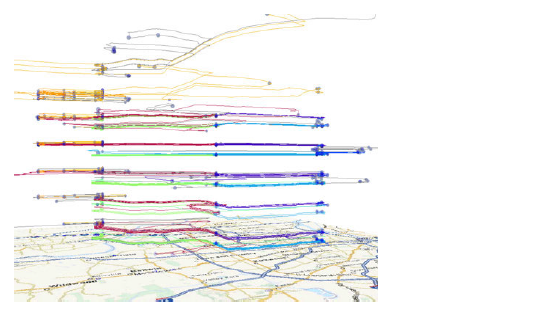
下图为利用GPS轨迹数据分析某个人的语义地点,其中是一周和一天的时间分布(经过了time transform),其中点表示stop。
分析者选择一个已有语义的地点,然后利用距离公式计算它与其它所有地方的距离。
利用动态交互式过滤,并在time graphs中选择一小部分足够相似的时间序列,然后将这些时间序列对应地点的语义赋值为已有的语义。
下图的三行分别为三个不同语义地点的时间签名。
对于复杂的地方,可能还需要去查看相应的地理位置,当前,还不支持从work到home中途接小孩放学这种复杂的地点。
本文还探索了利用LBSN的文本来推断地点的方法,但是一些单词(“home”, “work”,“education”, “shopping”)的时间分布没有明显的模式,只有其中一部分单词有,例如“local transport”,“restaurant”, “sports”等。因此,对一些地点,这些单词只能是增加了推断证据。当前,还没有找到一种好的结合时态和文本的方法。
作者:Gennady Andrienko, Natalia Andrienko, Georg Fuchs等.
来源:Proceedings of The First ACM SIGSPATIAL International Workshop on Computational Models of Place (COMP’13). 2013.
利用可视分析可以提取个人地点的语义,但是这对于大规模数据不可行,本文提出利用时态签名(temporal signature,用来刻画个人访问POI的时间分布)来解决该问题,对所有提取出的stop,提取其访问的时间模式, 对于语义已知的地点,利用时间序列聚类的方法发现与其相似的其它地点,然后将已知的语义赋给这些地点,达到大规模提取语义地点的目的。
step1:利用郑宇的方法提取stop
step2:对每个人的对stop进行密度聚类,发现cluster。
这些cluster代表潜在的POI,然后对其进行缓冲区构建。
step3:对每个cluster,计算下列时态聚集特征:

这些特征构成了“时态签名”,这里假设:
1,可以从时态签名里面推断POI的语义特征
2,时态签名相似的POI,其语义也相似。
可视分析主要包含两个视图:map view和time graph。
下图为利用手机通话数据分析某个人的语义地点:
左图最上面的cluster为home,左下的cluster为work,黑色的cluster在工作日的下午访问,有可能为休闲或者体育活动场所。右图为各个time graph。
下图为利用GPS轨迹数据分析某个人的语义地点,其中是一周和一天的时间分布(经过了time transform),其中点表示stop。
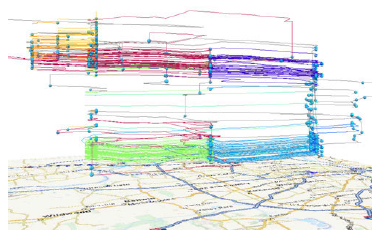
分析者选择一个已有语义的地点,然后利用距离公式计算它与其它所有地方的距离。
利用动态交互式过滤,并在time graphs中选择一小部分足够相似的时间序列,然后将这些时间序列对应地点的语义赋值为已有的语义。
下图的三行分别为三个不同语义地点的时间签名。
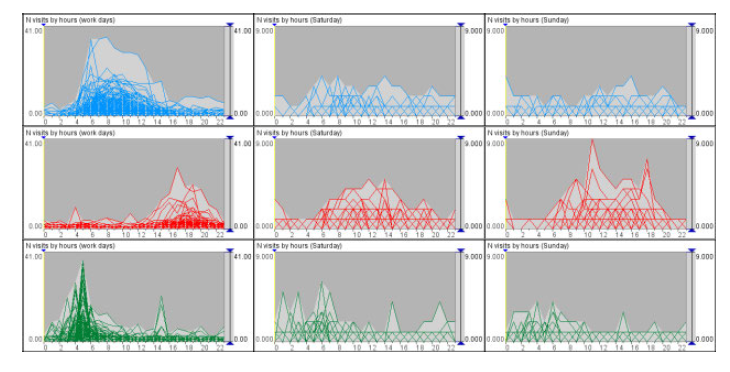
对于复杂的地方,可能还需要去查看相应的地理位置,当前,还不支持从work到home中途接小孩放学这种复杂的地点。
本文还探索了利用LBSN的文本来推断地点的方法,但是一些单词(“home”, “work”,“education”, “shopping”)的时间分布没有明显的模式,只有其中一部分单词有,例如“local transport”,“restaurant”, “sports”等。因此,对一些地点,这些单词只能是增加了推断证据。当前,还没有找到一种好的结合时态和文本的方法。















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









