







论文标题:MATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices(MATCH:面向异构边缘设备的模型感知TVM基础编译)
作者信息:
- Mohamed Amine Hamdi, Francesco Daghero, Daniele Jahier Pagliari, Alessio Burrello:Politecnico di Torino, Italy(意大利都灵理工大学)
- Giuseppe Maria Sarda, Marian Verhelst, Josse Van Delm, Arne Symons:KU Leuven, Belgium(比利时鲁汶大学)
- Luca Benini:University of Bologna, Italy(意大利博洛尼亚大学)
- 论文通讯作者:Alessio Burrello
论文出处:arXiv:2410.08855v1 [cs.DC] 11 Oct 2024
主要内容: 本文介绍了MATCH,这是一个基于TVM(Tensor Virtual Machine)的新型编译框架,旨在简化深度神经网络(DNN)在异构边缘平台上的部署。MATCH通过可定制的基于模型的硬件抽象,实现了在不同微控制器单元(MCU)处理器和张量计算硬件加速器之间的灵活重定向。研究者们展示了MATCH在两个最先进的异构MCU上的性能:GAP9和DIANA。在MLPerf Tiny套件的四个DNN模型上,MATCH相比于原生TVM,将推理延迟降低了高达60.88倍。与为DIANA量身定制的工具链HTVM相比,MATCH仍然将延迟降低了16.94%。在GAP9上,使用相同的基准测试,MATCH通过利用DNN加速器和板上的八核集群,将延迟提高了2.15倍。
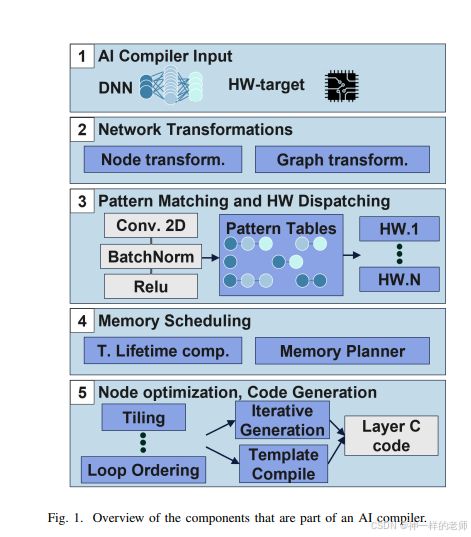
MATCH的核心贡献包括:
- 提出了MATCH,这是一个扩展了TVM编译流程的新编译器,通过DNN层调度的设计空间探索(DSE)工具。MATCH利用ZigZag,一个开源工具,识别出最优的时间映射,通过工作负载和目标硬件的抽象来实现。
- 为了利用硬件异构性,提出了一种模式匹配机制,利用ZigZag的建模将每个DNN操作符与最佳硬件模块匹配执行。
- 在两个不同的异构MCU上对MATCH进行了基准测试:GAP9和DIANA。MATCH在GAP9上平均减少了119.08倍的延迟,在DIANA上减少了83.18倍,相比于原生TVM解决方案。
- 在MLPerf Tiny基准测试的端到端DNN网络上,MATCH与最佳的SoC特定开源工具链相比,性能相当,在GAP9和DIANA上分别降低了2.15倍和16.94%的平均延迟。MATCH在两个平台上都超过了TVM,分别提高了67.83倍和60.88倍。
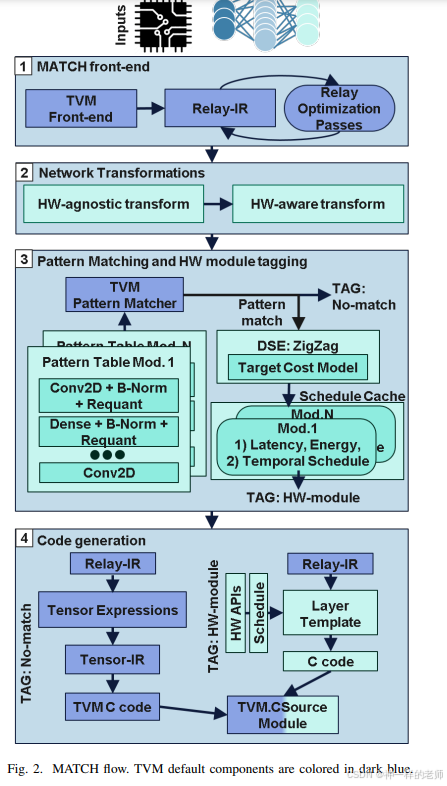
研究者们还讨论了MATCH的背景和相关工作,包括在软件和硬件方面的DNN优化,以及AI编译框架的使用,以生成针对特定硬件的目标代码。此外,还详细介绍了MATCH的核心组件,包括框架前端、网络转换、模式匹配和硬件感知调度以及代码生成。论文还展示了如何在MATCH中为新的SoC添加支持,并通过实验结果验证了MATCH的性能,并与现有的工具链进行了比较。
最后,研究者们总结了MATCH的主要贡献,并强调了其在新硬件上的快速部署能力,同时保持了与TVM生态系统的兼容性。MATCH的代码已在GitHub上开源。


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











